{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn/data/attach/logo/logo.png', '推荐 Reloaded 的问题《会是替代st m7的未来之选嘛,RISC-V gap8与cortex m7性能测试比较》','https://www.xiaopingtou.net/q-160452.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
本帖最后由 reloaded 于 2019-6-17 22:37 编辑
很多年前,st的m3因为atmel缺货而走上了主流,今天,由于某某站的缘故,以及ai市场大大举入侵嵌入式,我们开始把目光投向risc-v,他会是第二个stm32嘛
参考https://greenwaves-technologies. ... m-m7-embedded-cnns/
图片刷不出来可以打开网页,有。
不知道从何时开始,低端arm控制器和mpu也开始炫起了ML大法,各种NN都开始port到上面来。且不说性能如何,至少有这个玩意会比别家多一些噱头。。arm公司也不闲着,他
已经准备了下一代arm v8.1m架构,给mcu加入了neon协处理器,类似于矩阵计算阵列的多核mini版本,提供NN算法的加速。同时彻底降低了主控单元的计算负载。
而这一点,也是riscv们提前开始占领的高地。现在我们已经看到有厂家制造了一颗8核心加1主控的低端ai加速用的riscv单片机。
它依旧是单片机。主控250mhz,协处理器175mhz。
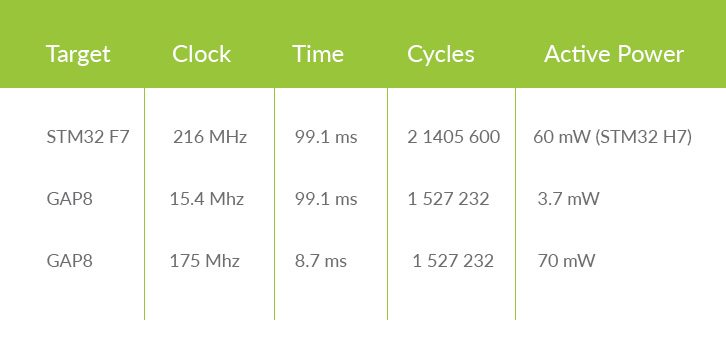
作为评测对比,它用gap8和运行在217mhz的stm32h7进行了对比
同一套CNN算法,stm32h7 99ms
gap8(175mhz)9ms
功耗方面 stm32h7 60mw 不得不说这个功耗还是很不错的。
gap8 70mw
并且risc v芯片的全功率运行时候电压是1v,比stm32的3.3v要低很多
只看数学计算性能,riscv是最高频率工作下的stm32h7的五倍。
功耗它俩在同一水平线。(几乎)同频率的话。
设计原理在:
Why is GAP8 using so few cycles? Well firstly we’re running on 8 cores and GAP8‘s extremely efficient architecture for parallelization is giving us a speed-up factor of somewhere between 7 and 8 times. Secondly the optimized DSP/SIMD instructions in GAP8 are giving fine grained parallelization on the convolution operations. Finally our fine grained control over memory movement is giving us a real benefit in the amount of cycles used to load and store weights, input and output data from the CNN graph nodes. All of these factors allow us to achieve the same execution time for the inference of 99.1ms at a clock speed of 15.4Mhz. This, in turn, allows us to run the cores at 1V leading to a power consumption during the operation of 3.7mW. Here we are really benefiting from the shared instruction cache in the cluster which decreases the cost of running the 8 cores by fetching instructions only once.
The last row in the table shows GAP8 executing the CNN at full clock speed. Here the cluster is working at 1.2V and its maximum clock speed of 175 Mhz. We are able to complete the inference in 8.7ms. A performance increase of 11 times versus the M7 core at a power level that is reasonably similar of 70mW. The energy consumed is obviously less than the M7 since it is over a shorter period but from an energy perspective the GAP8 is less efficient at this operation point.
更早一点的测评数据汇总在 https://greenwaves-technologies.com/gap8-cnn-benchmarks/
按照它们官方的说法,今年年中还会进行产品的第二次升级,把频率做到协处理器超200mhz,做到传统arm m7性能的五到八倍。以期和很快就会出样品的次时代arm mcu
集成NEON多核的AI单片机进行抗衡。
但是有个坏消息,这家公司的样品居然是四十欧一片。晕倒了。。
这种针对ai优化的mcu产品是有市场需求的。他可以作为camera的辅助检测。也可以做超低端的face recognition 大概做个婴儿动作检测比较合适。
由于我国的特殊市场需求非常之大,我依旧看好这类监控和识图类芯片的前景。
PS 目前所有的risc-v产品都没有以太网的IP,特别是低端控制器里的。所以要用的时候只能用wifi替代网络扩展。
甚至连usb 3也没有。这个问题不大。usb数量上也不占任何优势。riscv的唯一优势就是它更像是一款普通人能开发升级的fpga。
超低端的那种。破解起来初期成本较大。国内的合肥某手表公司已经量产了一款,还有一个做智能锁的芯片厂也量产了一款
他们都不需要以太网接口。
如果你要用以太网接口的有线接口,不要看了!!!!!!!!!!!!!!!!!!!!!!!!
PSS 最大的dsp厂家是TEXAS INSTRUMENTS,和ADI, 都是美国的。美国美国你懂得
很多年前,st的m3因为atmel缺货而走上了主流,今天,由于某某站的缘故,以及ai市场大大举入侵嵌入式,我们开始把目光投向risc-v,他会是第二个stm32嘛
参考https://greenwaves-technologies. ... m-m7-embedded-cnns/
图片刷不出来可以打开网页,有。
不知道从何时开始,低端arm控制器和mpu也开始炫起了ML大法,各种NN都开始port到上面来。且不说性能如何,至少有这个玩意会比别家多一些噱头。。arm公司也不闲着,他
已经准备了下一代arm v8.1m架构,给mcu加入了neon协处理器,类似于矩阵计算阵列的多核mini版本,提供NN算法的加速。同时彻底降低了主控单元的计算负载。
而这一点,也是riscv们提前开始占领的高地。现在我们已经看到有厂家制造了一颗8核心加1主控的低端ai加速用的riscv单片机。
它依旧是单片机。主控250mhz,协处理器175mhz。
作为评测对比,它用gap8和运行在217mhz的stm32h7进行了对比
同一套CNN算法,stm32h7 99ms
gap8(175mhz)9ms
功耗方面 stm32h7 60mw 不得不说这个功耗还是很不错的。
gap8 70mw
并且risc v芯片的全功率运行时候电压是1v,比stm32的3.3v要低很多
只看数学计算性能,riscv是最高频率工作下的stm32h7的五倍。
功耗它俩在同一水平线。(几乎)同频率的话。
设计原理在:
Why is GAP8 using so few cycles? Well firstly we’re running on 8 cores and GAP8‘s extremely efficient architecture for parallelization is giving us a speed-up factor of somewhere between 7 and 8 times. Secondly the optimized DSP/SIMD instructions in GAP8 are giving fine grained parallelization on the convolution operations. Finally our fine grained control over memory movement is giving us a real benefit in the amount of cycles used to load and store weights, input and output data from the CNN graph nodes. All of these factors allow us to achieve the same execution time for the inference of 99.1ms at a clock speed of 15.4Mhz. This, in turn, allows us to run the cores at 1V leading to a power consumption during the operation of 3.7mW. Here we are really benefiting from the shared instruction cache in the cluster which decreases the cost of running the 8 cores by fetching instructions only once.
The last row in the table shows GAP8 executing the CNN at full clock speed. Here the cluster is working at 1.2V and its maximum clock speed of 175 Mhz. We are able to complete the inference in 8.7ms. A performance increase of 11 times versus the M7 core at a power level that is reasonably similar of 70mW. The energy consumed is obviously less than the M7 since it is over a shorter period but from an energy perspective the GAP8 is less efficient at this operation point.
更早一点的测评数据汇总在 https://greenwaves-technologies.com/gap8-cnn-benchmarks/
按照它们官方的说法,今年年中还会进行产品的第二次升级,把频率做到协处理器超200mhz,做到传统arm m7性能的五到八倍。以期和很快就会出样品的次时代arm mcu
集成NEON多核的AI单片机进行抗衡。
但是有个坏消息,这家公司的样品居然是四十欧一片。晕倒了。。
这种针对ai优化的mcu产品是有市场需求的。他可以作为camera的辅助检测。也可以做超低端的face recognition 大概做个婴儿动作检测比较合适。
由于我国的特殊市场需求非常之大,我依旧看好这类监控和识图类芯片的前景。
PS 目前所有的risc-v产品都没有以太网的IP,特别是低端控制器里的。所以要用的时候只能用wifi替代网络扩展。
甚至连usb 3也没有。这个问题不大。usb数量上也不占任何优势。riscv的唯一优势就是它更像是一款普通人能开发升级的fpga。
超低端的那种。破解起来初期成本较大。国内的合肥某手表公司已经量产了一款,还有一个做智能锁的芯片厂也量产了一款
他们都不需要以太网接口。
如果你要用以太网接口的有线接口,不要看了!!!!!!!!!!!!!!!!!!!!!!!!
PSS 最大的dsp厂家是TEXAS INSTRUMENTS,和ADI, 都是美国的。美国美国你懂得
友情提示: 此问题已得到解决,问题已经关闭,关闭后问题禁止继续编辑,回答。
按它这种比法,我拿个8051核挂个纯硬件算法IP,难道可以得出8051的强大?
要比两个核心的效率、功耗,第一是硬件平台要相同,同样的功艺,同样的频率,同样的电压。第二是跑同样的算法,只利用核心,和外设/协处理器无关。
一周热门 更多>