{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicIk4yuw.jpg', '推荐 人中狼 的文章《有经验的C语言程序常说的“内存对齐”,原因究竟是什么?》','https://www.xiaopingtou.net/article-104125.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
在C语言程序开发中,有时有经验的程序员会提起“内存对齐”一词,事实上,这也是C语言中结构体的 size 不等于它所有成员 size 之和的原因(C语言中的结构体的size,并不等于它所有成员size之和,为什么?),那么,C语言程序为什么要“内存对齐”呢?

C语言程序为什么要“内存对齐”呢?
为什么要“内存对齐”?
C语言编译器在处理代码时,常常会将一些变量的内存对齐,这其实主要是因为底层处理器的限制。对于多数处理器而言,每次访问的数据并不是越少越好:例如,有的处理器每次访问 4 个字节数据,要比访问 1 个字节数据效率高得多。
针对这样的情况,一些C语言编译器会将代码中的变量地址对齐,目的就是让处理器能够更加高效的访问这些变量。甚至有些严格的处理器或者系统,在处理未进行内存对齐的数据时,根本无法正常运行(bus error 等)。

为什么要“内存对齐”?
因此,对于C语言程序中的一些数据而言,进行“内存对齐”至少有以下几点好处:
程序的执行效率提高
现代处理器一般都有多个级别的高速缓存,处理器访问这些高速缓存里的数据的效率要比访问内存里的数据效率高得多(就像处理器访问内存里的数据,比访问磁盘里的数据效率高得多一样。)。
就像上面介绍以的一样,一般来说,CPU 总是以字大小(32 位处理器上常常为 4 个字节)访问数据,所以如果数据没有内存对齐,CPU 访问这些数据时,可能就需要执行更多次的读取操作才行。在这样的机器上,读取 2 个字节数据往往比读取 4 个字节数据慢得多。

CPU 总是以字大小访问数据
假设在C语言程序开发中,我们在内存里定义了下面这样的数据结构:
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}在 32 位处理器上,上述数据结构可能会被按照下图这样排列(即所谓的“内存对齐”):
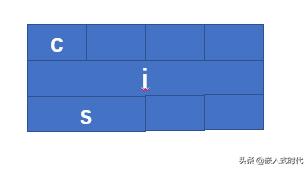
上述数据结构可能会被按照这样排列
此时,处理器访问结构体 mystruct 的任意一个成员都只需一次访问。如果没有内存对齐,mystruct 的各个成员在内存中紧密排列,如下图:

在内存中紧密排列
此时,如果处理器需要从 0x05 处读取 16 位数据,处理器将不得不从 0x04 处读取一个字(这里等于 4 字节),然后左移一个字节,将结果放入 16 位寄存器中。
如果处理器需要从 0x01 处读取 32 位数据,效率就降低至少 2 倍了:处理器不得不从 0x00 处读取一个字,并且左移一个字节,然后从 0x04 处再读取一个字,并且右移 3 个字节,最终使用 OR 位运算将两次读取结果拼接,才能达成目的。

访问范围提高
访问范围提高
对于任意给定的地址空间,如果体系架构可以确定 2 个 LSB 总是 0(例如 32 位机器),那么它可以访问 4 倍多的内存(2 个位能够表示 4 个不同状态)。从一个地址中去掉 2 个 LSB,将得到 4 字节的内存对齐,或者说“跨距”,因为地址每增加一,它就有效的增加 bit 2,而不是 bit 0。(鉴于低 2 位总是 00)
这甚至会影响系统的物理设计:如果地址总线的需要少 2 位,CPU 上的管脚就可以少 2 个。
原子性的保障
前面提到 CPU 每次访问数据的宽度是一个字,如果C语言程序中的数据总是内存对齐的,那么 CPU 访问数据总是原子性的,这对于许多无锁数据结构和其他并发需求的正确操作至关重要。
小结
事实上,本节只是粗浅讨论,处理器的内存系统比这里描述的要复杂得多,涉及的内容也要复杂得多。不过,我们至少已经知道,在C语言程序中坚持内存对齐还是有很多好处的。