{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 nt52241930 的文章《Python实战项目——售电公司客户用电匹配方案》','https://www.xiaopingtou.net/article-52301.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
项目简介:
售电公司服务于用户和电厂两个主体,用户向售电公司上报一年各个月份的用电需求量,各个电厂给出售电公司各个月份的电量供应量及报价,已知电量越大,价格越高。作为中间服务商,售电公司为了追求利润最大化,需要将用户的需求电量与电厂的供应电量进行匹配,要求用Python实现匹配出各个月满足用户需求的最低价的电量及对应的电厂。 数据集:用户需求电量表: [月份、用户需求电量]
电厂供电量表: [月份、电厂1、电厂2、电厂3、电厂4] 思路分析:
首先我们看一下数据集长什么样:
用户提供的电量表:

以及电厂给出的电量表:
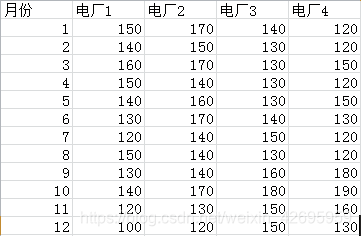
通过分析,我们了解到,我们需要实现将用户每个月份的电量与4个电厂对应月份的电量进行比较,在4个值中,选择大于用户电量且最小的那一个值,总共12个月的话,还可以用循环语句去循环。好像并不复杂,我们动手试一试: 首先导入Excel数据集到python中,用到xlrd模块,提取用户需求电量数据,用列表存储,代码如下:
#读取文件
import xlrd
#用户需求电量
data = xlrd.open_workbook(r'C:Userswww12Desktop数据.xlsx')
sheet1=data.sheet_by_name('用户需求电量') #提取用户需求电量工作表
col_1 = sheet1.col(1) #提取工作表的第二列
col_1.pop(0) #删除第一行表头——'用户需求电量'
need=[]
for x in col_1: #提取该列的数值,x的格式为‘xlrd.sheet.Cell’
a=x.value
need.append(a)
print(need) #输出列表
结果如下:
print(need)
[100.0, 150.0, 120.0, 130.0, 140.0, 160.0, 170.0, 100.0, 150.0, 160.0, 140.0, 120.0]
然后提取电厂数据,用列表存储,然后创建字典格式:
#电厂电量
sheet2=data.sheet_by_name('电厂供电量')
#提取第一家电厂的电量数据
t_1= sheet2.col(1)
t_1.pop(0)
t1=[]
for x in t_1:
t1.append(x.value)
#重复操作,提取第二家电厂的电量数据
t_2= sheet2.col(2)
t_2.pop(0)
t2=[]
for x in t_2:
t2.append(x.value)
#提取第三家电厂的电量数据
t_3= sheet2.col(3)
t_3.pop(0)
t3=[]
for x in t_3:
t3.append(x.value)
#提取第四家电厂的电量数据
t_4= sheet2.col(4)
t_4.pop(0)
t4=[]
for x in t_4:
t4.append(x.value)
print(t1,t2,t3,t4)
得到4个电厂每个月的供电量,结果如下:
print(t1,t2,t3,t4)
[150.0, 140.0, 160.0, 150.0, 140.0, 160.0, 130.0, 160.0, 140.0, 140.0, 170.0, 140.0]
[170.0, 150.0, 170.0, 140.0, 160.0, 170.0, 140.0, 140.0, 160.0, 130.0, 160.0, 170.0]
[140.0, 130.0, 130.0, 130.0, 130.0, 140.0, 150.0, 130.0, 130.0, 150.0, 180.0, 140.0]
[120.0, 120.0, 150.0, 120.0, 150.0, 130.0, 120.0, 120.0, 120.0, 170.0, 140.0, 120.0]
我们将它转换为字典格式:
#创建字典存放电厂数据
k=['m1','m2','m3','m4','m5','m6','m7','m8','m9','m10','m11','m12']
p1=dict(zip(k,t1))
p2=dict(zip(k,t2))
p3=dict(zip(k,t3))
p4=dict(zip(k,t4))
pp=[p1,p2,p3,p4]
print(p1,p2,p3,p4)
结果如下:
print(p1,p2,p3,p4)
{'m1': 150.0, 'm2': 140.0, 'm3': 160.0, 'm4': 150.0, 'm5': 140.0, 'm6': 160.0, 'm7': 130.0, 'm8': 160.0, 'm9': 140.0, 'm10': 140.0, 'm11': 170.0, 'm12': 140.0}
{'m1': 170.0, 'm2': 150.0, 'm3': 170.0, 'm4': 140.0, 'm5': 160.0, 'm6': 170.0, 'm7': 170.0, 'm8': 140.0, 'm9': 160.0, 'm10': 130.0, 'm11': 160.0, 'm12': 170.0}
{'m1': 140.0, 'm2': 130.0, 'm3': 130.0, 'm4': 130.0, 'm5': 130.0, 'm6': 140.0, 'm7': 150.0, 'm8': 130.0, 'm9': 130.0, 'm10': 150.0, 'm11': 180.0, 'm12': 140.0}
{'m1': 120.0, 'm2': 120.0, 'm3': 150.0, 'm4': 120.0, 'm5': 150.0, 'm6': 130.0, 'm7': 120.0, 'm8': 120.0, 'm9': 120.0, 'm10': 170.0, 'm11': 140.0, 'm12': 120.0}
我们在将用户每个月的用电量,拿出来和对应月份的电厂供电量去横向比较的时候,我们需要把4家电厂每个月的供电量的数据抽取出来,存放到新的列表里,怎么实现呢?
p1,p2,p3,p4每个字典都有12个键值对,用来存放每个月的供电量,我们可以对字典进行切片操作,将每个月的供电量切分出来,再加一个while循环语句,这样就可以对12个月份依次进行切片。需要对4个电厂都执行,所以再加一个for循环,将结果中每个月份分门归类,我们建立12个空列表,结果存放在12个空列表中,这样就得到了每个月四家电厂的供电量。代码如下:
#字典切片,得到每个月各个电厂的电量
def dict_slice(ori_dict, start, end): #定义字典切片函数,三个参数的含义:字典、开始、结束
slice_dict = {k: ori_dict[k] for k in list(ori_dict.keys())[start:end]}
return slice_dict
#批量添加各月份电量
mp1=[]
mp2=[]
mp3=[]
mp4=[]
mp5=[]
mp6=[]
mp7=[]
mp8=[]
mp9=[]
mp10=[]
mp11=[]
mp12=[]
mps=[mp1,mp2,mp3,mp4,mp5,mp6,mp7,mp8,mp9,mp10,mp11,mp12]
#对字典进行切分和重装
n=0 #循环变量n
while n<=11: #一直进行到12月份
for x in pp:
mps[n].append(dict_slice(x,n,n+1))
print(mps[n])
n=n+1
这样就得到了12个mp1,mp2…这样的列表,分别包含了各个月份4家电厂的电量。运行结果如下:
[{'m1': 150.0}, {'m1': 170.0}, {'m1': 140.0}, {'m1': 120.0}]
[{'m2': 140.0}, {'m2': 150.0}, {'m2': 130.0}, {'m2': 120.0}]
[{'m3': 160.0}, {'m3': 170.0}, {'m3': 130.0}, {'m3': 150.0}]
[{'m4': 150.0}, {'m4': 140.0}, {'m4': 130.0}, {'m4': 120.0}]
[{'m5': 140.0}, {'m5': 160.0}, {'m5': 130.0}, {'m5': 150.0}]
[{'m6': 160.0}, {'m6': 170.0}, {'m6': 140.0}, {'m6': 130.0}]
[{'m7': 130.0}, {'m7': 140.0}, {'m7': 150.0}, {'m7': 120.0}]
[{'m8': 160.0}, {'m8': 140.0}, {'m8': 130.0}, {'m8': 120.0}]
[{'m9': 140.0}, {'m9': 160.0}, {'m9': 130.0}, {'m9': 120.0}]
[{'m10': 140.0}, {'m10': 130.0}, {'m10': 150.0}, {'m10': 170.0}]
[{'m11': 170.0}, {'m11': 160.0}, {'m11': 180.0}, {'m11': 140.0}]
[{'m12': 140.0}, {'m12': 170.0}, {'m12': 140.0}, {'m12': 120.0}]
这样一月份的用户电量就可以直接和mp1里面的4个值进行比较,以此类推,得到12个月份的匹配结果,所以这里还需要用到循环语句。
然后我们需要注意的是mp1长什么样,mp1并不单纯是一个列表,原字典切片结果返回的是字典,所以mp1里是4个字典,我们要读取字典里的值。然后以第一个月的用电量为例,返回匹配的供电量以及对应的电厂编号,这里用到一个for循环:
读取mp1里所有字典的值:
k=[item[values]for item in mp1 for values in item]
#以第一月份为例,将用户需求电量与电厂电量进行匹配
n1=[]
for x in k: #与mp1中的4个值依次进行比较
if need[0]<=x:
n1.append(x)
#输出目标电量及对应的电厂编号
a=min(n1)
print(min(n1))
print(n1.index(a)+1)
返回结果:
120.0
4
可以看到,结果返回的正是我们期望得到的数据,但是我们希望能够加一个循环,逐个将12个月份依次进行比较,这样就可以直接返回一整年的匹配结果,改进代码如下:
#定义函数——读取字典值
def get_values(x):
k=[item[values]for item in x for values in item]
return k
#循环执行匹配操作
n=0
while n<=11:
k=get_values(mps[n])
for x in k:
if need[n]<=x:
a.append(x)
print(min(a))
print(a.index(min(a))+1)
a=[]
n=n+1
输出结果如下:
120.0
4
150.0
1
130.0
3
130.0
3
140.0
1
160.0
1
170.0
1
120.0
4
160.0
1
170.0
1
140.0
4
120.0
4
到这里就算完成了。
总结:值得我们注意的是用到的三个嵌套循环,还有字典切片,以及读取列表中字典的键值这几个操作。因为每一个月的用电量都需要依次和每一家电厂对应的供电量进行比较,所以两张表之间是有层次对应联系的,我们为了实现批量操作和代码更简洁高效,会考虑使用多个循环嵌套起来,并执行相应的操作,这也是Python语言的特点。