{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 TheSun 的文章《R绘制Nomogram图》','https://www.xiaopingtou.net/article-52402.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
Nomogram,中文常称为诺莫图或者列线图,简单的说是将Logistic回归或Cox回归的结果进行可视化呈现。它根据所有自变量回归系数的大小来制定评分标准,给每个自变量的每种取值水平一个评分,对每个患者,就可计算得到一个总分,再通过得分与结局发生概率之间的转换函数来计算每个患者的结局时间发生的概率。
下图显示的logisitc回归的诺曼图。比如想知道年龄70岁的男性的患病风险,只需要将age=70岁向points轴投射,则points≈70;同理sex=male时,points≈65。两者相加则Total points=135;将此数值在Total points轴上向Risk概率轴投射,则可知风险大概为0.83左右。

对于Cox回归,则可以简便地获得不同预测变量单独或组合情况下的中位生存时间或预测的生存概率。 下图显示的中位生存时间的诺曼图,比如想看60岁女性的中位生存时间,同样,首先找到60岁女性对应的总点数,约为116分,对应的中位生存时间约为550天
同理,可以通过下面生存概率的诺曼图,找到60岁女性的1年及2年的生存概率分别约为65%和40%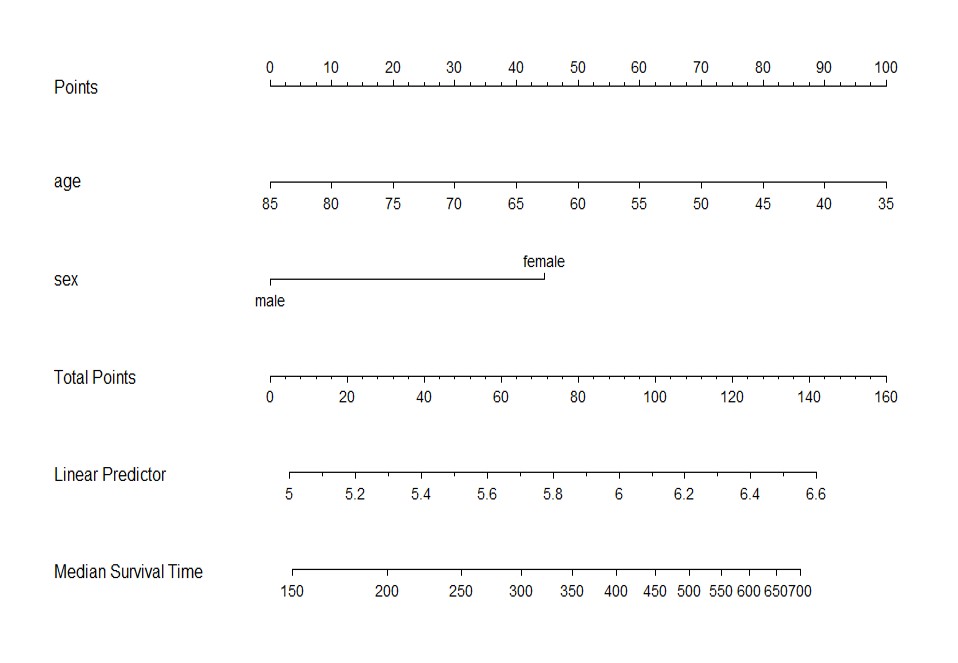
从上可以看到,诺曼图相当于一个预测工具,预测效果的好坏则可以通过C-index(意义上等价于AUC,由于算法的不同,两者结果略有差异)和下面的校正曲线来评价: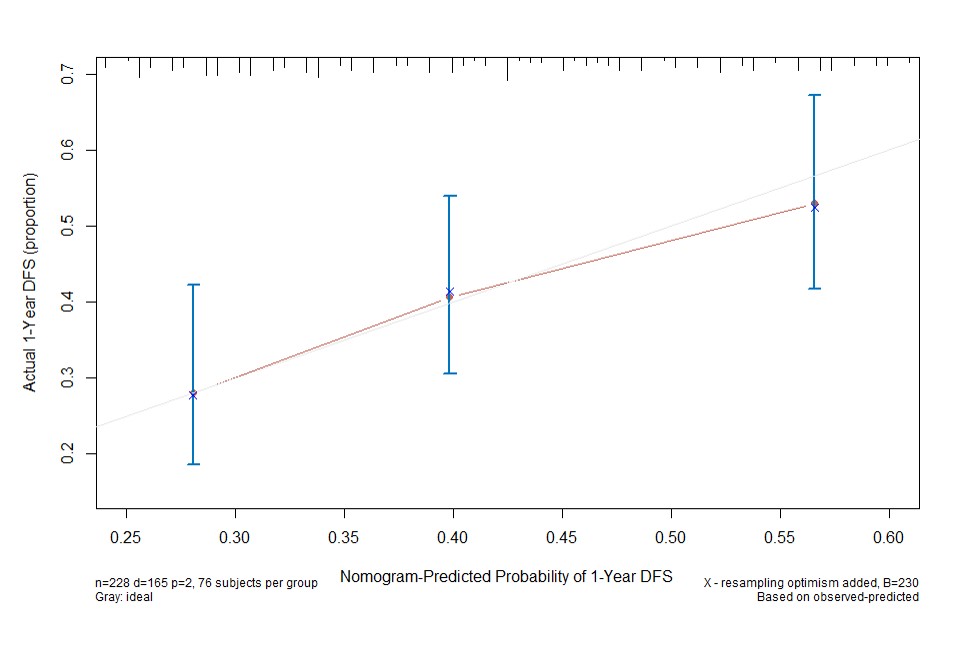
以下是绘制上述图形的R编码及详细说明,为了方便重复,所以采用程序包自带的数据库:
转载自:http://bbs.pinggu.org/thread-4115525-1-1.html 其他链接: http://www.dxy.cn/bbs/thread/27318323#27318323
下图显示的logisitc回归的诺曼图。比如想知道年龄70岁的男性的患病风险,只需要将age=70岁向points轴投射,则points≈70;同理sex=male时,points≈65。两者相加则Total points=135;将此数值在Total points轴上向Risk概率轴投射,则可知风险大概为0.83左右。
对于Cox回归,则可以简便地获得不同预测变量单独或组合情况下的中位生存时间或预测的生存概率。 下图显示的中位生存时间的诺曼图,比如想看60岁女性的中位生存时间,同样,首先找到60岁女性对应的总点数,约为116分,对应的中位生存时间约为550天
同理,可以通过下面生存概率的诺曼图,找到60岁女性的1年及2年的生存概率分别约为65%和40%
从上可以看到,诺曼图相当于一个预测工具,预测效果的好坏则可以通过C-index(意义上等价于AUC,由于算法的不同,两者结果略有差异)和下面的校正曲线来评价:
以下是绘制上述图形的R编码及详细说明,为了方便重复,所以采用程序包自带的数据库:
## 绘制nomogram图
## 第一步 读取rms程序包及辅助程序包
library(Hmisc); library(grid); library(lattice);library(Formula); library(ggplot2)
library(rms)
## 第二步 读取数据,以survival程序包的lung数据来进行演示
## 列举survival程序包中的数据集
library(survival)
data(package = "survival")
## 读取lung数据集
data(lung)
## 显示lung数据集的前6行结果
head(lung)
## 显示lung数据集的变量说明
help(lung)
## 添加变量标签以便后续说明
lung$sex <-
factor(lung$sex,
levels = c(1,2),
labels = c("male", "female"))
## 第三步 按照nomogram要求“打包”数据,绘制nomogram的关键步骤,??datadist查看详细说明
dd=datadist(lung)
options(datadist="dd")
## 第四步 构建模型
## 构建logisitc回归模型
f1 <- lrm(status~ age + sex, data = lung)
## 绘制logisitc回归的风险预测值的nomogram图
nom <- nomogram(f1, fun= function(x)1/(1+exp(-x)), # or fun=plogis
lp=F, funlabel="Risk")
plot(nom)
## 构建COX比例风险模型
f2 <- psm(Surv(time,status) ~ age+sex, data = lung, dist='lognormal')
med <- Quantile(f2) # 计算中位生存时间
surv <- Survival(f2) # 构建生存概率函数
## 绘制COX回归中位生存时间的Nomogram图
nom <- nomogram(f2, fun=function(x) med(lp=x),
funlabel="Median Survival Time")
plot(nom)
## 绘制COX回归生存概率的Nomogram图
## 注意lung数据的time是以”天“为单位
nom <- nomogram(f2, fun=list(function(x) surv(365, x),
function(x) surv(730, x)),
funlabel=c("1-year Survival Probability",
"2-year Survival Probability"))
plot(nom, xfrac=.6)
## 评价COX回归的预测效果
## 第一步 计算c-index
rcorrcens(Surv(time,status) ~ predict(f2), data = lung)
## 第二步 绘制校正曲线
## 参数说明:
## 1、绘制校正曲线前需要在模型函数中添加参数x=T, y=T,详细参考帮助
## 2、u需要与之前模型中定义好的time.inc一致,即365或730;
## 3、m要根据样本量来确定,由于标准曲线一般将所有样本分为3组(在图中显示3个点)
## 而m代表每组的样本量数,因此m*3应该等于或近似等于样本量;
## 4、b代表最大再抽样的样本量
## 重新调整模型函数f2,也即添加x=T, y=T
f2 <- psm(Surv(time,status) ~ age+sex, data = lung, x=T, y=T, dist='lognormal')
## 构建校正曲线
cal1 <- calibrate(f2, cmethod='KM', method="boot", u=365, m=76, B=228)
## 绘制校正曲线,??rms::calibrate查看详细参数说明
par(mar=c(8,5,3,2),cex = 1.0)
plot(cal1,lwd=2,lty=1,
errbar.col=c(rgb(0,118,192,maxColorValue=255)),
xlim=c(0.25,0.6),ylim=c(0.15,0.70),
xlab="Nomogram-Predicted Probability of 1-Year DFS",
ylab="Actual 1-Year DFS (proportion)",
col=c(rgb(192,98,83,maxColorValue=255)))
## rms::nomogram的完整示例详见rms程序包的帮助文件
## rms程序包的帮助文件下载网址:https://cran.r-project.org/web/packages/rms/rms.pdf
## 代表性参考文献1:http://jco.ascopubs.org/content/26/8/1364.long
## 代表性参考文献2:http://jco.ascopubs.org/content/31/9/1188.long转载自:http://bbs.pinggu.org/thread-4115525-1-1.html 其他链接: http://www.dxy.cn/bbs/thread/27318323#27318323