{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 hekun559 的文章《实例:电力窃漏电用户自动识别-神经网络和决策树》','https://www.xiaopingtou.net/article-53545.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
1、数据划分
R语言实现:
将专家样本划分为测试样本和训练样本,随机选取20%为测试样本,剩下来的作为训练样本。


 2、建模-CART决策树
R语言实现:
2、建模-CART决策树
R语言实现:


 3、模型比较
对于训练样本traindata,神经网络和CART决策树的分类准确率均达到90%。
利用测试样本对模型进一步评价,采用ROC曲线进行评估,一个优秀的分类器所对应的ROC曲线应该是尽量靠近左上角。
R语言实现:
3、模型比较
对于训练样本traindata,神经网络和CART决策树的分类准确率均达到90%。
利用测试样本对模型进一步评价,采用ROC曲线进行评估,一个优秀的分类器所对应的ROC曲线应该是尽量靠近左上角。
R语言实现:

 Python实现:
Python实现:
data = read.csv(file="model.csv")
colnames(data) = c("time","userid","ele_ind","loss_ind","alarm_ind","class") #数据命名
head(data)
输出结果:
set.seed(1234) #设置随机种子
ind = sample(2,nrow(data),replace = TRUE,prob = c(0.8,0.2)) #定义序列ind,随机抽取1和2,1的个数占80%,2的个数占20%
traindata = data[ind==1,] #训练样本
testdata = data[ind==2,] #测试样本
write.csv(traindata,"traindata.csv",row.names = FALSE)
write.csv(testdata,"testdata.csv",row.names = FALSE) # 保存到当期工作目录下
Python实现:
import pandas as pd
from random import shuffle #导入随机函数shuffle,用来打乱数据
data = pd.read_excel("model.xls")
data = data.as_matrix() #将表格转换为矩阵
shuffle(data)
p = 0.8
train = data[:int(len(data)*p),:] #训练集
test = data[int(len(data)*p):,:] #测试集
2、建模-神经网络
R语言实现:
traindata =transform(traindata,class = as.factor(class)) #将class列转换成因子类型
library(nnet)
nnet.model = nnet(class~ele_ind+loss_ind+alarm_ind,traindata,size=10,decay=0.05) #设定神经网络的输入节点为ele_ind,loss_ind,alarm_ind,输出节点为class,数据为traindata,隐层节点数为10,权值的衰减参数为0.05
confusion = table(traindata$class,predict(nnet.model,traindata,type="class")) #建立混淆矩阵
confusion
accuracy = sum(diag(confusion))*100/sum(confusion) #计算分类准确率
accuracy
输出如下:
output_nnet.traindata = cbind(traindata,predict(nnet.model,traindata,type="class"))
colnames(output_nnet.traindata) = c(colnames(traindata),"OUTPUT")
write.csv(output_nnet.traindata,"output_nnet.traindata.csv",row.names = FALSE) #保存输出结果
save(nnet.model,file="nnet.model.RData") #保存神经网络模型
Python实现:
from keras.models import Sequential
from keras.layers.core import Dense,Activation
net = Sequential() #建立模型
net.add(Dense(input_dim=3,output_dim=10))
net.add(Activation('relu')) #用relu函数作为激活函数,大幅提高准确度
net.add(Dense(input_dim=10,output_dim=1))
net.add(Activation('sigmoid')) #由于是0-1输出,用sigmoid函数作为激活函数
net.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
#编译模型。由于二元分类,损失函数为binary_crossentropy。
#另外常用的损失函数还有mean_squared_error、categorical_crossentropy等
#求解方法用adam,还有sgd、rmsprop可选
net.fit(train[:,:3],train[:,3],nb_epoch=1000,batch_size=1) #训练模型,学习一千次
net.save_weights("net.model")
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #分类预测
#keras中,用predict给出预测概率,predict_classes给出预测类别,而且两者的结果都是n * 1维数组
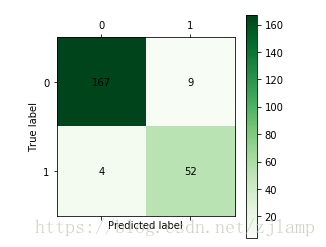
def cm_plot(y, yp): #混淆矩阵可视化函数
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配 {MOD}风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜 {MOD}标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
cm_plot(train[:,3],predict_result).show()
输出结果如下:
2、建模-CART决策树
R语言实现:
traindata =transform(traindata,class = as.factor(class)) #将class列转换成因子类型
library(tree)
tree.model = tree(class~ele_ind+loss_ind+alarm_ind,traindata) #建立CART决策树
plot(tree.model)
text(tree.model) #画决策树图
confusion = table(traindata$class,predict(tree.model,traindata,type="class")) #建立混淆矩阵
confusion
accuracy = sum(diag(confusion))*100/sum(confusion) #计算分类准确率
accuracy
输出如下:
output_tree.traindata = cbind(traindata,predict(tree.model,traindata,type="class"))
colnames(output_tree.traindata) = c(colnames(traindata),"OUTPUT")
write.csv(output_tree.traindata,"output_tree.traindata.csv",row.names = FALSE) #保存输出结果
save(tree.model,file="tree.model.RData") #保存CART决策树模型
Python实现:
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3],train[:,3]) #训练模型
from sklearn.externals import joblib
joblib.dump(tree,'tree.pkl') #保存模型
def cm_plot(y, yp): #混淆矩阵可视化函数
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配 {MOD}风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜 {MOD}标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
cm_plot(train[:,3],tree.predict(train[:,:3])).show()
输出结果如下:
3、模型比较
对于训练样本traindata,神经网络和CART决策树的分类准确率均达到90%。
利用测试样本对模型进一步评价,采用ROC曲线进行评估,一个优秀的分类器所对应的ROC曲线应该是尽量靠近左上角。
R语言实现:
library(ROCR)
nnet.pred = prediction(predict(nnet.model,testdata),testdata$class)
nnet.perf = performance(nnet.pred,"tpr","fpr")
plot(nnet.perf) #画出神经网络模型的ROC曲线
结果如图:
tree.pred = prediction(predict(tree.model,testdata)[,2],testdata$class) #决策树模型预测时,生成(0,1)两列,取第二列
nnet.perf = performance(nnet.pred,"tpr","fpr")
plot(nnet.perf) #画出CART决策树的ROC曲线
结果如图:
Python实现:
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
predict_result = net.predict_classes(test[:,:3]).reshape(len(test)) #预测测试集
fpr,tpr,thresholds = roc_curve(test[:,3],predict_result,pos_label=1)
plt.plot(fpr,tpr,linewidth=2,label="ROC of LM") #作ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
fpr,tpr,thresholds = roc_curve(test[:,3],tree.predict_proba(test[:,:3])[:,1],pos_label=1)
plt.plot(fpr,tpr,linewidth=2,label="ROC of CART") #作ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
对比发现,神经网络的ROC曲线更靠近左上角,说明神经网络模型的分类性能更好。
下一步工作是研究错、漏判的记录,优化模型的特征,提高识别的准确率。