{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 qq_24890953 的文章《电力窃漏电用户自动识别(SPSS Modeler)》','https://www.xiaopingtou.net/article-54888.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
据统计,全国每年因窃电造成的损失都在200亿元左右;被查获的窃电案件不足总窃电案件的30%。而传统的用电检查及反偷查漏工作主要依靠突击检查的手段来打击窃电行为;存在先天性的缺陷和不足。
现有的电力计量自动化系统能够采集到各相电流、电压、功率因数等用电负荷数据以及用电异常等终端报警信息。异常告警信息和现场稽查来查找出窃漏电用户,并录入系统。若能通过这些数据信息提取出窃漏电用户的关键特征,构建窃漏电用户的识别模型,就能自动检查判断用户是否存在窃漏电行为。
我们使用2009年1月1日到2014年12月31日所有窃漏电用户和正常用户的用电量、告警及线损数据,以及该用户是否窃漏电的标志,共291条记录,数据详见“建模数据.csv”。其 中:
电量趋势下降指标:统计日期前后五天内,当天用电量低于前一天用电量的天数。
线损指标:统计日期后五天线损率的平均值和前五天线损率的平均值,若前者比后者的增长率超过了1%,则指标为1,否则为0。
告警类指标:与窃漏电相关的所有告警次数总和。
目标:构建窃漏电用户识别模型,能够应用窃漏电用户识别模型实现用户诊断。
具体要求:
1、 进行数据审核,查看数据基本情况,绘制各变量分布图;
2、 数据预处理阶段完成数据类型转换、异常值查找与处理、数据变换(将线损指标记录值内的1转换为“上升”,0转换为“下降”);
3、 模型构建过程需要首先将数据分为测试数据和训练数据,可构建决策树模型、神经网络模型或其他分类预测模型;
4、 构建模型后完成模型评估,详细分析预测结果,并对结果加以解释;
5、 使用模型对新用户数据“诊断数据.csv”进行窃漏电诊断识别。
[实验步骤]
1、进行数据审核,查看数据基本情况,绘制各变量分布图;
通过变量文件添加数据文件
 绘制各变量分布图
绘制各变量分布图
 2、 数据预处理阶段完成数据类型转换、异常值查找与处理、数据变换(将线损指标记录值内的1转换为“上升”,0转换为“下降”);
数据类型转换:将一个类型节点加到目前的流程中,点击“读取值”,将“线损指标”的测量设置为“分类”,其它不变。
2、 数据预处理阶段完成数据类型转换、异常值查找与处理、数据变换(将线损指标记录值内的1转换为“上升”,0转换为“下降”);
数据类型转换:将一个类型节点加到目前的流程中,点击“读取值”,将“线损指标”的测量设置为“分类”,其它不变。
 异常值查找与处理:在类型节点的后加入选择节点,在选择框的模式项选择“丢弃”,点击选择框的表达式构建器,建立表达式。
异常值查找与处理:在类型节点的后加入选择节点,在选择框的模式项选择“丢弃”,点击选择框的表达式构建器,建立表达式。


 在选择节点后加入数据审核节点,质量选项,在离群值和极值一栏选择输入四分位距的上/下四位数范围。
在选择节点后加入数据审核节点,质量选项,在离群值和极值一栏选择输入四分位距的上/下四位数范围。
 运行结果:
运行结果:
 质量选项,对于离群值和极值,单击操作下的具有离群值和极值的变量。在下拉菜单中选择强制,之后点击生成选项的离群值与极值节点,
质量选项,对于离群值和极值,单击操作下的具有离群值和极值的变量。在下拉菜单中选择强制,之后点击生成选项的离群值与极值节点,
 将超节点链接到数据流中,如下图所示,并重新链接数据审核节点。
将超节点链接到数据流中,如下图所示,并重新链接数据审核节点。
 通过选择节点的数据流就没有空值,离群值和极值也被处理掉,
通过选择节点的数据流就没有空值,离群值和极值也被处理掉,
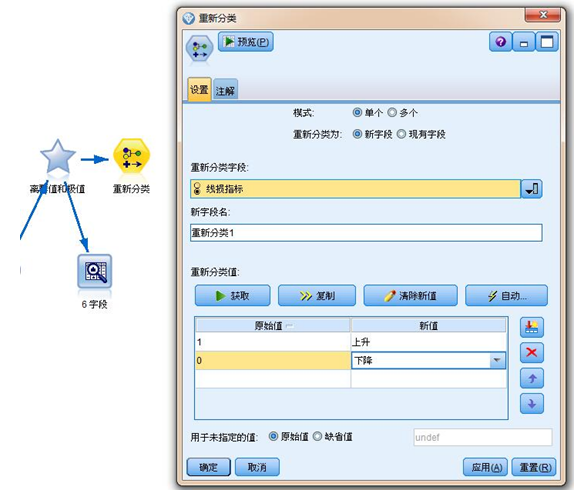
 将字段栏中的“重新分类”节点加入数据流中,双击重新分类节点,在”重新分类字段“选项下拉菜单中选择线损指标,在重新分类为选择现有字段,点击获取按钮,将线损指标记录值内的1转换为“上升”,0转换为“下降”。
将字段栏中的“重新分类”节点加入数据流中,双击重新分类节点,在”重新分类字段“选项下拉菜单中选择线损指标,在重新分类为选择现有字段,点击获取按钮,将线损指标记录值内的1转换为“上升”,0转换为“下降”。
 3、 模型构建过程需要首先将数据分为测试数据和训练数据,可构建决策树模型、神经网络模型或其他分类预测模型;
在重新分类节点后面加入一个过滤器节点,将认为影响判定结果无关的ID删除,
3、 模型构建过程需要首先将数据分为测试数据和训练数据,可构建决策树模型、神经网络模型或其他分类预测模型;
在重新分类节点后面加入一个过滤器节点,将认为影响判定结果无关的ID删除,
 建立一个分区节点,将80%数据作为训练,20%数据作为测试,
建立一个分区节点,将80%数据作为训练,20%数据作为测试,
 建立一个决策树模型 一个c5.0节点与类型节点相连,选择是否窃漏电做判定目标,其余做输出,
建立一个决策树模型 一个c5.0节点与类型节点相连,选择是否窃漏电做判定目标,其余做输出,
 点击右上角模型,,所有变量的重要性比较接近,其中是否窃漏电的重要性比较突出,说明这这个属性在区分用户是否存在窃电的过程中占有比较重要的角 {MOD}。
点击右上角模型,,所有变量的重要性比较接近,其中是否窃漏电的重要性比较突出,说明这这个属性在区分用户是否存在窃电的过程中占有比较重要的角 {MOD}。
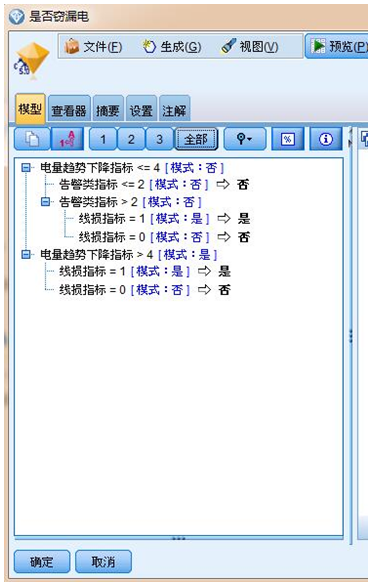
 模型结果下的模型,点击全部,可以看到以规则形式展示的决策树模型。
模型结果下的模型,点击全部,可以看到以规则形式展示的决策树模型。
 4、 构建模型后完成模型评估,详细分析预测结果,并对结果加以解释;
4、 构建模型后完成模型评估,详细分析预测结果,并对结果加以解释;
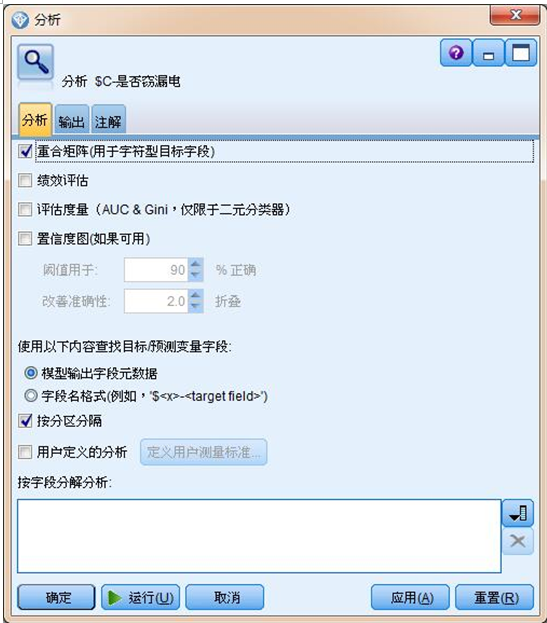 将模型与输出栏目下的分析节点连接,执行节点显示观测值与预测值的匹配程度如何的信息,在节点的参数设置页面勾选重合矩阵,
分析结果:
将模型与输出栏目下的分析节点连接,执行节点显示观测值与预测值的匹配程度如何的信息,在节点的参数设置页面勾选重合矩阵,
分析结果:
 所有流程:
所有流程:
 5、 使用模型对新用户数据“诊断数据.csv”进行窃漏电诊断识别。
将新数据集直接添加到原始数据流的起始阶段,并在最终的模型后加入一个表格,
5、 使用模型对新用户数据“诊断数据.csv”进行窃漏电诊断识别。
将新数据集直接添加到原始数据流的起始阶段,并在最终的模型后加入一个表格,
 运行表格:
运行表格:
绘制各变量分布图
2、 数据预处理阶段完成数据类型转换、异常值查找与处理、数据变换(将线损指标记录值内的1转换为“上升”,0转换为“下降”);
数据类型转换:将一个类型节点加到目前的流程中,点击“读取值”,将“线损指标”的测量设置为“分类”,其它不变。
异常值查找与处理:在类型节点的后加入选择节点,在选择框的模式项选择“丢弃”,点击选择框的表达式构建器,建立表达式。
在选择节点后加入数据审核节点,质量选项,在离群值和极值一栏选择输入四分位距的上/下四位数范围。
运行结果:
质量选项,对于离群值和极值,单击操作下的具有离群值和极值的变量。在下拉菜单中选择强制,之后点击生成选项的离群值与极值节点,
将超节点链接到数据流中,如下图所示,并重新链接数据审核节点。
通过选择节点的数据流就没有空值,离群值和极值也被处理掉,
将字段栏中的“重新分类”节点加入数据流中,双击重新分类节点,在”重新分类字段“选项下拉菜单中选择线损指标,在重新分类为选择现有字段,点击获取按钮,将线损指标记录值内的1转换为“上升”,0转换为“下降”。
3、 模型构建过程需要首先将数据分为测试数据和训练数据,可构建决策树模型、神经网络模型或其他分类预测模型;
在重新分类节点后面加入一个过滤器节点,将认为影响判定结果无关的ID删除,
建立一个分区节点,将80%数据作为训练,20%数据作为测试,
建立一个决策树模型 一个c5.0节点与类型节点相连,选择是否窃漏电做判定目标,其余做输出,
点击右上角模型,,所有变量的重要性比较接近,其中是否窃漏电的重要性比较突出,说明这这个属性在区分用户是否存在窃电的过程中占有比较重要的角 {MOD}。
模型结果下的模型,点击全部,可以看到以规则形式展示的决策树模型。
4、 构建模型后完成模型评估,详细分析预测结果,并对结果加以解释;
将模型与输出栏目下的分析节点连接,执行节点显示观测值与预测值的匹配程度如何的信息,在节点的参数设置页面勾选重合矩阵,
分析结果:
所有流程:
5、 使用模型对新用户数据“诊断数据.csv”进行窃漏电诊断识别。
将新数据集直接添加到原始数据流的起始阶段,并在最终的模型后加入一个表格,
运行表格: