{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 ws19000928 的文章《【腾讯模考】题目解答》','https://www.xiaopingtou.net/article-55891.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
1. 特征向量与特征值
定义:设成立,则称这样的数
题目:解答:

2. 神经网络的梯度弥散问题
题目:10层的NN训练,反向传播过程中,前三层权值不变,4-6层变化非常慢,这是()现象? 解答:梯度弥散。 梯度弥散的问题很大程度上是来源于激活函数的“饱和”。因为在后向传播的过程中仍然需要计算激活函数的导数,所以一旦卷积核的输出落入函数的饱和区,它的梯度将变得非常小。 随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。这样一来,深层模型也就变成了前几层相对固定,只能改变最后几层的浅层模型。 扩展:什么是梯度爆炸?
http://blog.csdn.net/cppjava_/article/details/68941436
3. 切比雪夫不等式
切比雪夫不等式定理:
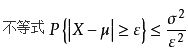 或
或 。
。
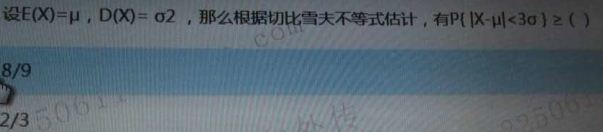 答案:1/9
答案:1/9
4. 无偏估计
 参数的样本估计值的期望值等于参数的真实值。估计量的数学期望等于被估计参数,则称此为无偏估计。
这么说吧:同一个总体,一次抽样什么幺蛾子都有可能出现。但是只要你肯一直坚持不懈的抽样下去,每次的样本均值的均值,还等于总体均值——就是无偏的。
上述参考自:https://www.zhihu.com/question/22983179
一次取平均数就说这是总体的平均值的做法就是:偏差估计。题目中抽了一次样,不属于无偏估计。
参数的样本估计值的期望值等于参数的真实值。估计量的数学期望等于被估计参数,则称此为无偏估计。
这么说吧:同一个总体,一次抽样什么幺蛾子都有可能出现。但是只要你肯一直坚持不懈的抽样下去,每次的样本均值的均值,还等于总体均值——就是无偏的。
上述参考自:https://www.zhihu.com/question/22983179
一次取平均数就说这是总体的平均值的做法就是:偏差估计。题目中抽了一次样,不属于无偏估计。
5. 统计学问题:儿童智力提升
不太明白解题思路,在知乎上提问: https://www.zhihu.com/question/646507256. 卡方分布
问题: 解答:
设X1服从自由度为m的χ2分布,X2服从自由度为n的χ2分布,且X1、X2相互独立,则称变量F=(X1/m) / (X2/n)所服从的分布为F分布,其中第一自由度为m,第二自由度为n.
解答:
设X1服从自由度为m的χ2分布,X2服从自由度为n的χ2分布,且X1、X2相互独立,则称变量F=(X1/m) / (X2/n)所服从的分布为F分布,其中第一自由度为m,第二自由度为n.
 所以两者相等。
所以两者相等。
7. 假设检验
题目: 此题涉及t检验和显著性检验的概念。
应选C。落在范围之外,可认为有显著不同。
此题涉及t检验和显著性检验的概念。
应选C。落在范围之外,可认为有显著不同。

8. 计算行列式的值
 参考:《工程数学-线性代数》P12 例7
做法:先化成上三角形行列式,对角线乘积为值。
参考:《工程数学-线性代数》P12 例7
做法:先化成上三角形行列式,对角线乘积为值。
9. 显著性检验
参见显著性检验的概念题目:假定如果假设检验支持我们做出认为某种制造工艺可以降低汽车百公里耗油量的结论,则该新型工艺将正式投入使用。
(1)如果目前制作工艺的汽车百公里耗油为10升,建立合适的原假设和备择假设。
(2)在这种情况下,发生第一类错误和第二类错误的结果是什么?