{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 gungunchang 的文章《XGBoost 与 Boosted Tree》','https://www.xiaopingtou.net/article-56968.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
1. 前言
作为一个非常有效的机器学习方法,Boosted Tree是数据挖掘和机器学习中最常用的算法之一。因为它效果好,对于输入要求不敏感,往往是从统计学家到数据科学家必备的工具之一,它同时也是kaggle比赛冠军选手最常用的工具。最后,因为它的效果好,计算复杂度不高,也在工业界中有大量的应用。 2. Boosted Tree的若干同义词
说到这里可能有人会问,为什么我没有听过这个名字。这是因为Boosted Tree有各种马甲,比如GBDT, GBRT(gradient boosted regression tree),MART1 ,LambdaMART也是一种boosted tree的变种。网上有很多介绍Boosted tree的资料,不过大部分都是基于Friedman的最早一篇文章Greedy Function Approximation: A Gradient Boosting Machine的翻译。个人觉得这不是最好最一般地介绍boosted tree的方式。而网上除了这个角度之外的介绍并不多。这篇文章是我个人对于boosted tree和gradient boosting 类算法的总结,其中很多材料来自于我TA UW机器学习时的一份讲义2 。
3. 有监督学习算法的逻辑组成
要讲boosted tree,要先从有监督学习讲起。在有监督学习里面有几个逻辑上的重要组成部件3 ,初略地分可以分为:模型,参数 和 目标函数。
i. 模型和参数
模型指给定输入xi 如何去预测输出 yi 。我们比较常见的模型如线性模型(包括线性回归和logistic regression)采用了线性叠加的方式进行预测y^i=∑jwjxij 。其实这里的预测y 可以有不同的解释,比如我们可以用它来作为回归目标的输出,或者进行sigmoid 变换得到概率,或者作为排序的指标等。而一个线性模型根据y 的解释不同(以及设计对应的目标函数)用到回归,分类或排序等场景。参数指我们需要学习的东西,在线性模型中,参数指我们的线性系数w 。
ii. 目标函数:损失 + 正则
模型和参数本身指定了给定输入我们如何做预测,但是没有告诉我们如何去寻找一个比较好的参数,这个时候就需要目标函数登场了。一般的目标函数包含下面两项

常见的误差函数有L=∑nil(yi,y^i) 比如平方误差l(yi,y^i)=(yi−y^i)2 ,logistic误差函数l(yi,y^i)=yiln(1+e−y^i)+(1−yi)ln(1+ey^i) 等。而对于线性模型常见的正则化项有L2 正则和L1 正则。这样目标函数的设计来自于统计学习里面的一个重要概念叫做Bias-variance tradeoff4 。比较感性的理解,Bias可以理解为假设我们有无限多数据的时候,可以训练出最好的模型所拿到的误差。而Variance是因为我们只有有限数据,其中随机性带来的误差。目标中误差函数鼓励我们的模型尽量去拟合训练数据,这样相对来说最后的模型会有比较少的 bias。而正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定。
iii. 优化算法
讲了这么多有监督学习的基本概念,为什么要讲这些呢? 是因为这几部分包含了机器学习的主要成分,也是机器学习工具设计中划分模块比较有效的办法。其实这几部分之外,还有一个优化算法,就是给定目标函数之后怎么学的问题。之所以我没有讲优化算法,是因为这是大家往往比较熟悉的“机器学习的部分”。而有时候我们往往只知道“优化算法”,而没有仔细考虑目标函数的设计的问题,比较常见的例子如决策树的学习,大家知道的算法是每一步去优化gini entropy,然后剪枝,但是没有考虑到后面的目标是什么。 4. Boosted Tree
i. 基学习器:分类和回归树(CART)
话题回到boosted tree,我们也是从这几个方面开始讲,首先讲模型。Boosted tree 最基本的组成部分叫做回归树(regression tree),也叫做CART5 。
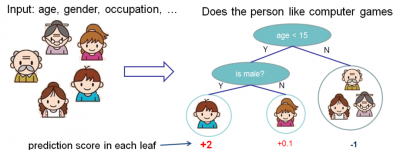
上面就是一个CART的例子。CART会把输入根据输入的属性分配到各个叶子节点,而每个叶子节点上面都会对应一个实数分数。上面的例子是一个预测一个人是否会喜欢电脑游戏的 CART,你可以把叶子的分数理解为有多可能这个人喜欢电脑游戏。有人可能会问它和decision tree的关系,其实我们可以简单地把它理解为decision tree的一个扩展。从简单的类标到分数之后,我们可以做很多事情,如概率预测,排序。 ii. Tree Ensemble
一个CART往往过于简单无法有效地预测,因此一个更加强力的模型叫做tree ensemble。

在上面的例子中,我们用两棵树来进行预测。我们对于每个样本的预测结果就是每棵树预测分数的和。到这里,我们的模型就介绍完毕了。现在问题来了,我们常见的随机森林和boosted tree和tree ensemble有什么关系呢?如果你仔细的思考,你会发现RF和boosted tree的模型都是tree ensemble,只是构造(学习)模型参数的方法不同。第二个问题:在这个模型中的“参数”是什么。在tree ensemble中,参数对应了树的结构,以及每个叶子节点上面的预测分数。
最后一个问题当然是如何学习这些参数。在这一部分,答案可能千奇百怪,但是最标准的答案始终是一个:定义合理的目标函数,然后去尝试优化这个目标函数。在这里我要多说一句,因为决策树学习往往充满了heuristic(启发式)。 如先优化吉尼系数,然后再剪枝啦,限制最大深度,等等。其实这些heuristic的背后往往隐含了一个目标函数,而理解目标函数本身也有利于我们设计学习算法,这个会在后面具体展开。
对于tree ensemble,我们可以比较严格的把我们的模型写成是:
y^i=∑k=1Kfk(xi),fk∈F
其中每个f 是一个在函数空间6 (F )里面的函数,而F 对应了所有regression tree的集合。我们设计的目标函数也需要遵循前面的主要原则,包含两部分
Obj(Θ)=∑inl(yi,y^i)+∑k
作为一个非常有效的机器学习方法,Boosted Tree是数据挖掘和机器学习中最常用的算法之一。因为它效果好,对于输入要求不敏感,往往是从统计学家到数据科学家必备的工具之一,它同时也是kaggle比赛冠军选手最常用的工具。最后,因为它的效果好,计算复杂度不高,也在工业界中有大量的应用。 2. Boosted Tree的若干同义词
说到这里可能有人会问,为什么我没有听过这个名字。这是因为Boosted Tree有各种马甲,比如GBDT, GBRT(gradient boosted regression tree),MART
要讲boosted tree,要先从有监督学习讲起。在有监督学习里面有几个逻辑上的重要组成部件
i. 模型和参数
模型指给定输入
ii. 目标函数:损失 + 正则
模型和参数本身指定了给定输入我们如何做预测,但是没有告诉我们如何去寻找一个比较好的参数,这个时候就需要目标函数登场了。一般的目标函数包含下面两项
常见的误差函数有
iii. 优化算法
讲了这么多有监督学习的基本概念,为什么要讲这些呢? 是因为这几部分包含了机器学习的主要成分,也是机器学习工具设计中划分模块比较有效的办法。其实这几部分之外,还有一个优化算法,就是给定目标函数之后怎么学的问题。之所以我没有讲优化算法,是因为这是大家往往比较熟悉的“机器学习的部分”。而有时候我们往往只知道“优化算法”,而没有仔细考虑目标函数的设计的问题,比较常见的例子如决策树的学习,大家知道的算法是每一步去优化gini entropy,然后剪枝,但是没有考虑到后面的目标是什么。 4. Boosted Tree
i. 基学习器:分类和回归树(CART)
话题回到boosted tree,我们也是从这几个方面开始讲,首先讲模型。Boosted tree 最基本的组成部分叫做回归树(regression tree),也叫做CART
上面就是一个CART的例子。CART会把输入根据输入的属性分配到各个叶子节点,而每个叶子节点上面都会对应一个实数分数。上面的例子是一个预测一个人是否会喜欢电脑游戏的 CART,你可以把叶子的分数理解为有多可能这个人喜欢电脑游戏。有人可能会问它和decision tree的关系,其实我们可以简单地把它理解为decision tree的一个扩展。从简单的类标到分数之后,我们可以做很多事情,如概率预测,排序。 ii. Tree Ensemble
一个CART往往过于简单无法有效地预测,因此一个更加强力的模型叫做tree ensemble。
在上面的例子中,我们用两棵树来进行预测。我们对于每个样本的预测结果就是每棵树预测分数的和。到这里,我们的模型就介绍完毕了。现在问题来了,我们常见的随机森林和boosted tree和tree ensemble有什么关系呢?如果你仔细的思考,你会发现RF和boosted tree的模型都是tree ensemble,只是构造(学习)模型参数的方法不同。第二个问题:在这个模型中的“参数”是什么。在tree ensemble中,参数对应了树的结构,以及每个叶子节点上面的预测分数。
最后一个问题当然是如何学习这些参数。在这一部分,答案可能千奇百怪,但是最标准的答案始终是一个:定义合理的目标函数,然后去尝试优化这个目标函数。在这里我要多说一句,因为决策树学习往往充满了heuristic(启发式)。 如先优化吉尼系数,然后再剪枝啦,限制最大深度,等等。其实这些heuristic的背后往往隐含了一个目标函数,而理解目标函数本身也有利于我们设计学习算法,这个会在后面具体展开。
对于tree ensemble,我们可以比较严格的把我们的模型写成是:
其中每个