{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 曾小开 的文章《【基础1】文本分析-词频与余弦相似度》','https://www.xiaopingtou.net/article-57095.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
通过计算两段文本的相似度,我们可以:

本文会具体介绍如何计算文本的夹角余弦相似度,包括两部分:
在扯到文本之前,这个要先介绍一下。 余弦定理告诉我们(不记得的翻看书本):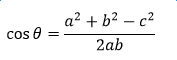
然而对于两个向量a、b的夹角余弦呢?
它的公式为:
分子就是2个向量的内积,分母是两个向量的模长乘积。
用两个向量的坐标即可计算出来,简单了解一下这个推导: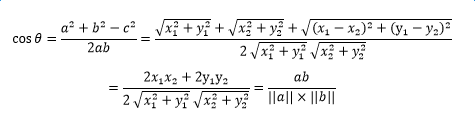
这是两个二维向量,如果是两个n维向量的夹角余弦相似度,只要记得,分子依然是向量内积,分母是两个向量模长乘积。 知道了向量的夹角余弦相似度计算方法,现在只要想办法将文本变成向量就可以了。
2. 词频与词频向量 文本是由词组成的,我们一般通过计算词频来构造文本向量——词频向量。 比如有一句话:
这里有2个问题值得提一下: (1)当两个词频向量进行比较的时候,维度会扩大。 比如刚刚例子中,彼此没有出现的“吗”、“吧”两个维度会加进来,保证比较的两段文本维度统一。那么问题来了,如果两段很长的文本进行比较(比如上万字的文章),岂不是维度要扩增很多倍?而且矩阵会非常稀疏,就是很多取值都是0,计算开销大且效率低,怎么办? 因此需要寻求一种有效的特征降维方法,能够在不损伤核心信息的情况下降低向量空间的维数,比如TF-IDF算法。这就是后面会介绍的。 (2)英文文本的比较 与中文不同的是,英文不需要分词,因为英文天然就是由一个一个词组组成的。 I Love Shushuojun → I/ Love/ Shushuojun
转载自:https://mp.weixin.qq.com/s/dohbdkQvHIGnAWR_uPZPuA
- 对垃圾文本(比如小广告)进行批量屏蔽;
- 对大量重复信息(比如新闻)进行删减;
- 对感兴趣的相似文章进行推荐,等等。
-
将两段文本变成两个可爱的小向量;
-
计算这两个向量的夹角余弦cos(θ):
- 夹角余弦为1,也即夹角为0°,两个小向量无缝合体,则相似度100%
- 夹角余弦为0,也即夹角为180°,小向量可怜的两两不相见,则相似度为0%
本文会具体介绍如何计算文本的夹角余弦相似度,包括两部分:
- 向量的夹角余弦如何计算
- 如何构造文本向量:词频与词频向量
在扯到文本之前,这个要先介绍一下。 余弦定理告诉我们(不记得的翻看书本):
然而对于两个向量a、b的夹角余弦呢?
它的公式为:
分子就是2个向量的内积,分母是两个向量的模长乘积。
用两个向量的坐标即可计算出来,简单了解一下这个推导:
这是两个二维向量,如果是两个n维向量的夹角余弦相似度,只要记得,分子依然是向量内积,分母是两个向量模长乘积。 知道了向量的夹角余弦相似度计算方法,现在只要想办法将文本变成向量就可以了。
2. 词频与词频向量 文本是由词组成的,我们一般通过计算词频来构造文本向量——词频向量。 比如有一句话:
我是数说君,我爱你们,你们爱我吗?这段文本是由几个词组成的:
我/ 是/ 数说君 我/ 爱/ 你们 你们/ 爱/ 我/ 吗其中“我”出现了3次,“是”出现一次......依次计算,我们就可以构造如下词频向量:
我3, 是1, 数说君1, 爱2, 你们2, 吗1 → (3,1,1,2,2,1)这就是一个6维向量了。 需要注意的是,如果这时候有另一段文本需要跟它比较,比如就是:
我是数说君,我爱你们,你们爱我吧?这时候我们应该这样分词:
我3, 是1, 数说君1, 爱2, 你们2, 吗0, 吧1 → (3,1,1,2,2,0,1)这里“吗”这个维度也需要加上,相应的,别忘了第一句话中也要加上“吧”这个维度:
我3, 是1, 数说君1, 爱2, 你们2, 吗1, 吧0 → (3,1,1,2,2,1,0)这就是两个7维向量了,现在可以将这两个文本向量进行夹角余弦的相似度比较,带入上面的公式: 两个向量内积=3*3+1+1+2*2+2*2=19 两个向量模长乘积=sqrt(9+1+1+4+4+1)*sqrt(9+1+1+4+4+1)=20 两个向量夹角余弦相似度=19/20=95% 所以这两段文本的相似度为95%。
这里有2个问题值得提一下: (1)当两个词频向量进行比较的时候,维度会扩大。 比如刚刚例子中,彼此没有出现的“吗”、“吧”两个维度会加进来,保证比较的两段文本维度统一。那么问题来了,如果两段很长的文本进行比较(比如上万字的文章),岂不是维度要扩增很多倍?而且矩阵会非常稀疏,就是很多取值都是0,计算开销大且效率低,怎么办? 因此需要寻求一种有效的特征降维方法,能够在不损伤核心信息的情况下降低向量空间的维数,比如TF-IDF算法。这就是后面会介绍的。 (2)英文文本的比较 与中文不同的是,英文不需要分词,因为英文天然就是由一个一个词组组成的。 I Love Shushuojun → I/ Love/ Shushuojun
转载自:https://mp.weixin.qq.com/s/dohbdkQvHIGnAWR_uPZPuA