{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 yujinjing13 的文章《TensorFlow和Caffe、MXNet、Keras等其他深度学习框架的对比》','https://www.xiaopingtou.net/article-57176.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
Google近日发布了TensorFlow 1.0候选版,这第一个稳定版将是深度学习框架发展中的里程碑的一步。自TensorFlow于2015年底正式开源,距今已有一年多,这期间TensorFlow不断给人以惊喜。在这一年多时间,TensorFlow已从初入深度学习框架大战的新星,成为了几近垄断的行业事实标准。本文节选自《TensorFlow实战》第二章。
主流深度学习框架对比
深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、Theano、DeepLearning4、Lasagne、Neon,等等。然而TensorFlow却杀出重围,在关注度和用户数上都占据绝对优势,大有一统江湖之势。表2-1所示为各个开源框架在GitHub上的数据统计(数据统计于2017年1月3日),可以看到TensorFlow在star数量、fork数量、contributor数量这三个数据上都完胜其他对手。究其原因,主要是Google在业界的号召力确实强大,之前也有许多成功的开源项目,以及Google强大的人工智能研发水平,都让大家对Google的深度学习框架充满信心,以至于TensorFlow在2015年11月刚开源的第一个月就积累了10000+的star。其次,TensorFlow确实在很多方面拥有优异的表现,比如设计神经网络结构的代码的简洁度,分布式深度学习算法的执行效率,还有部署的便利性,都是其得以胜出的亮点。如果一直关注着TensorFlow的开发进度,就会发现基本上每星期TensorFlow都会有1万行以上的代码更新,多则数万行。产品本身优异的质量、快速的迭代更新、活跃的社区和积极的反馈,形成了良性循环,可以想见TensorFlow未来将继续在各种深度学习框架中独占鳌头。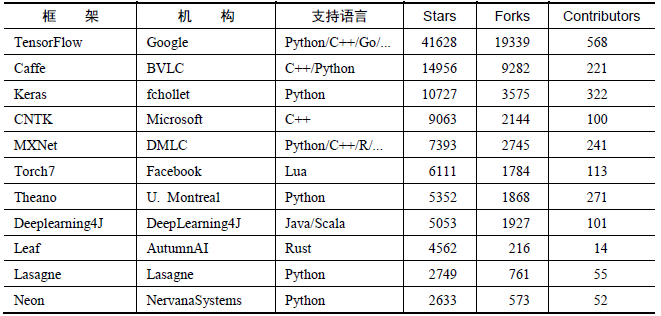
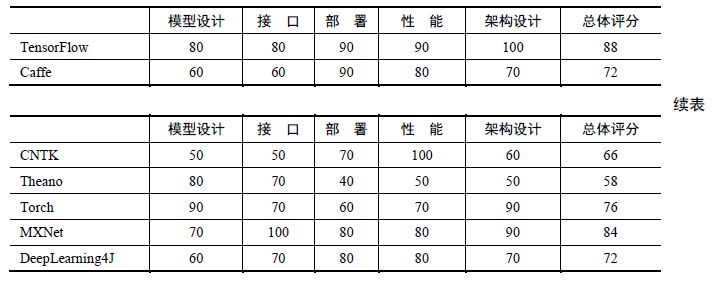
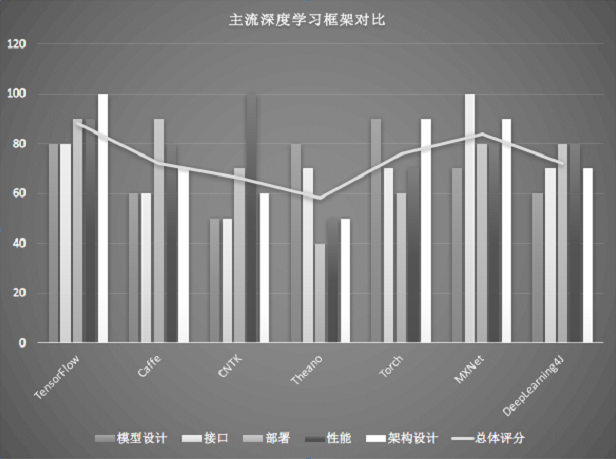
各深度学习框架简介
在本节,我们先来看看目前各流行框架的异同,以及各自的特点和优势。TensorFlow
TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA代码。它和Theano一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和Caffe一样是用C++编写的,使用C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python则会比较消耗资源,并且执行效率不高)。除了核心代码的C++接口,TensorFlow还有官方的Python、Go和Java接口,是通过SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用C++部署模型。SWIG支持给C/C++代码提供各种语言的接口,因此其他脚本语言的接口未来也可以通过SWIG方便地添加。不过使用Python时有一个影响效率的问题是,每一个mini-batch要从Python中feed到网络中,这个过程在mini-batch的数据量很小或者运算时间很短时,可能会带来影响比较大的延迟。现在TensorFlow还有非官方的Julia、Node.js、R的接口支持,地址如下。Julia: github.com/malmaud/TensorFlow.jlNode.js: github.com/node-tensorflow/node-tensorflow
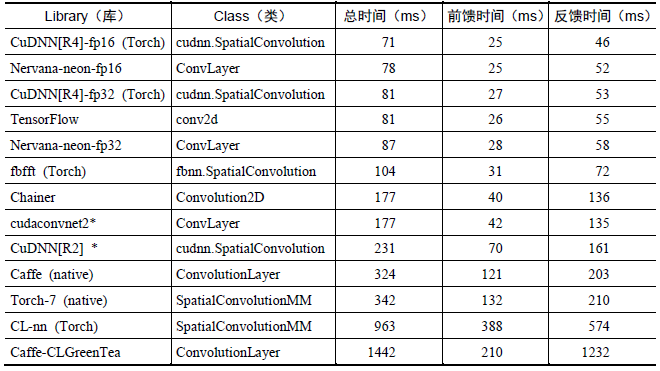
R: github.com/rstudio/tensorflowTensorFlow也有内置的TF.Learn和TF.Slim等上层组件可以帮助快速地设计新网络,并且兼容Scikit-learn estimator接口,可以方便地实现evaluate、grid search、cross validation等功能。同时TensorFlow不只局限于神经网络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。事实上,只要可以将计算表示成计算图的形式,就可以使用TensorFlow。用户可以写内层循环代码控制计算图分支的计算,TensorFlow会自动将相关的分支转为子图并执行迭代运算。TensorFlow也可以将计算图中的各个节点分配到不同的设备执行,充分利用硬件资源。定义新的节点只需要写一个Python函数,如果没有对应的底层运算核,那么可能需要写C++或者CUDA代码实现运算操作。在数据并行模式上,TensorFlow和Parameter Server很像,但TensorFlow有独立的Variable node,不像其他框架有一个全局统一的参数服务器,因此参数同步更自由。TensorFlow和Spark的核心都是一个数据计算的流式图,Spark面向的是大规模的数据,支持SQL等操作,而TensorFlow主要面向内存足以装载模型参数的环境,这样可以最大化计算效率。TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。相比于Theano,TensorFlow还有一个优势就是它极快的编译速度,在定义新网络结构时,Theano通常需要长时间的编译,因此尝试新模型需要比较大的代价,而TensorFlow完全没有这个问题。TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时一旦TensorFlow广泛地被工业界使用,将产生良性循环,成为深度学习领域的事实标准。除了支持常见的网络结构[卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurent Neural Network,RNN)]外,TensorFlow还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。TensorFlow此前不支持symbolic loop,需要使用Python循环而无法进行图编译优化,但最近新加入的XLA已经开始支持JIT和AOT,另外它使用bucketing trick也可以比较高效地实现循环神经网络。TensorFlow的一个薄弱地方可能在于计算图必须构建为静态图,这让很多计算变得难以实现,尤其是序列预测中经常使用的beam search。TensorFlow的用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU(最近也开始通过OpenCL支持AMD的GPU,但没有CUDA成熟),支持Linux和Mac,最近在0.12版本中也开始尝试支持Windows。在工业生产环境中,硬件设备有些是最新款的,有些是用了几年的老机型,来源可能比较复杂,TensorFlow的异构性让它能够全面地支持各种硬件和操作系统。同时,其在CPU上的矩阵运算库使用了Eigen而不是BLAS库,能够基于ARM架构编译和优化,因此在移动设备(Android和iOS)上表现得很好。TensorFlow在最开始发布时只支持单机,而且只支持CUDA 6.5和cuDNN v2,并且没有官方和其他深度学习框架的对比结果。在2015年年底,许多其他框架做了各种性能对比评测,每次TensorFlow都会作为较差的对照组出现。那个时期的TensorFlow真的不快,性能上仅和普遍认为很慢的Theano比肩,在各个框架中可以算是垫底。但是凭借Google强大的开发实力,很快支持了新版的cuDNN(目前支持cuDNN v5.1),在单GPU上的性能追上了其他框架。表2-3所示为https://github.com/soumith/convnet-benchmarks给出的各个框架在AlexNet上单GPU的性能评测。
Caffe
官方网址:caffe.berkeleyvision.org/GitHub:github.com/BVLC/caffeCaffe全称为Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目),目前由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。Caffe的创始人是加州大学伯克利的Ph.D.贾扬清,他同时也是TensorFlow的作者之一,曾工作于MSRA、NEC和Google Brain,目前就职于Facebook FAIR实验室。Caffe的主要优势包括如下几点。
- 容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。
- 训练速度快,能够训练state-of-the-art的模型与大规模的数据。
- 组件模块化,可以方便地拓展到新的模型和学习任务上。
Theano
官方网址:http://www.deeplearning.net/software/theano/GitHub:github.com/Theano/TheanoTheano诞生于2008年,由蒙特利尔大学Lisa Lab团队开发并维护,是一个高性能的符号计算及深度学习库。因其出现时间早,可以算是这类库的始祖之一,也一度被认为是深度学习研究和应用的重要标准之一。Theano的核心是一个数学表达式的编译器,专门为处理大规模神经网络训练的计算而设计。它可以将用户定义的各种计算编译为高效的底层代码,并链接各种可以加速的库,比如BLAS、CUDA等。Theano允许用户定义、优化和评估包含多维数组的数学表达式,它支持将计算装载到GPU(Theano在GPU上性能不错,但是CPU上较差)。与Scikit-learn一样,Theano也很好地整合了NumPy,对GPU的透明让Theano可以较为方便地进行神经网络设计,而不必直接写CUDA代码。Theano的主要优势如下。
- 集成NumPy,可以直接使用NumPy的ndarray,API接口学习成本低。
- 计算稳定性好,比如可以精准地计算输出值很小的函数(像log(1+x))。
- 动态地生成C或者CUDA代码,用以编译成高效的机器代码。
Torch
官方网址:http://torch.ch/GitHub:github.com/torch/torch7Torch给自己的定位是LuaJIT上的一个高效的科学计算库,支持大量的机器学习算法,同时以GPU上的计算优先。Torch的历史非常悠久,但真正得到发扬光大是在Facebook开源了其深度学习的组件之后,此后包括Google、Twitter、NYU、IDIAP、Purdue等组织都大量使用Torch。Torch的目标是让设计科学计算算法变得便捷,它包含了大量的机器学习、计算机视觉、信号处理、并行运算、图像、视频、音频、网络处理的库,同时和Caffe类似,Torch拥有大量的训练好的深度学习模型。它可以支持设计非常复杂的神经网络的拓扑图结构,再并行化到CPU和GPU上,在Torch上设计新的Layer是相对简单的。它和TensorFlow一样使用了底层C++加上层脚本语言调用的方式,只不过Torch使用的是Lua。Lua的性能是非常优秀的(该语言经常被用来开发游戏),常见的代码可以通过透明的JIT优化达到C的性能的80%;在便利性上,Lua的语法也非常简单易读,拥有漂亮和统一的结构,易于掌握,比写C/C++简洁很多;同时,Lua拥有一个非常直接的调用C程序的接口,可以简便地使用大量基于C的库,因为底层核心是C写的,因此也可以方便地移植到各种环境。Lua支持Linux、Mac,还支持各种嵌入式系统(iOS、Android、FPGA等),只不过运行时还是必须有LuaJIT的环境,所以工业生产环境的使用相对较少,没有Caffe和TensorFlow那么多。为什么不简单地使用Python而是使用LuaJIT呢?官方给出了以下几点理由。
- LuaJIT的通用计算性能远胜于Python,而且可以直接在LuaJIT中操作C的pointers。
- Torch的框架,包含Lua是自洽的,而完全基于Python的程序对不同平台、系统移植性较差,依赖的外部库较多。
- LuaJIT的FFI拓展接口非常易学,可以方便地链接其他库到Torch中。Torch中还专门设计了N-Dimension array type的对象Tensor,Torch中的Tensor是一块内存的视图,同时一块内存可能有许多视图(Tensor)指向它,这样的设计同时兼顾了性能(直接面向内存)和便利性。同时,Torch还提供了不少相关的库,包括线性代数、卷积、傅里叶变换、绘图和统计等,如图2-5所示。

Lasagne
官网网址:http://lasagne.readthedocs.io/GitHub:github.com/Lasagne/LasagneLasagne是一个基于Theano的轻量级的神经网络库。它支持前馈神经网络,比如卷积网络、循环神经网络、LSTM等,以及它们的组合;支持许多优化方法,比如Nesterov momentum、RMSprop、ADAM等;它是Theano的上层封装,但又不像Keras那样进行了重度的封装,Keras隐藏了Theano中所有的方法和对象,而Lasagne则是借用了Theano中很多的类,算是介于基础的Theano和高度抽象的Keras之间的一个轻度封装,简化了操作同时支持比较底层的操作。Lasagne设计的六个原则是简洁、透明、模块化、实用、聚焦和专注。
Keras
官方网址:keras.ioGitHub:github.com/fchollet/kerasKeras是一个崇尚极简、高度模块化的神经网络库,使用Python实现,并可以同时运行在TensorFlow和Theano上。它旨在让用户进行最快速的原型实验,让想法变为结果的这个过程最短。Theano和TensorFlow的计算图支持更通用的计算,而Keras则专精于深度学习。Theano和TensorFlow更像是深度学习领域的NumPy,而Keras则是这个领域的Scikit-learn。它提供了目前为止最方便的API,用户只需要将高级的模块拼在一起,就可以设计神经网络,它大大降低了编程开销(code overhead)和阅读别人代码时的理解开销(cognitive overhead)。它同时支持卷积网络和循环网络,支持级联的模型或任意的图结构的模型(可以让某些数据跳过某些Layer和后面的Layer对接,使得创建Inception等复杂网络变得容易),从CPU上计算切换到GPU加速无须任何代码的改动。因为底层使用Theano或TensorFlow,用Keras训练模型相比于前两者基本没有什么性能损耗(还可以享受前两者持续开发带来的性能提升),只是简化了编程的复杂度,节约了尝试新网络结构的时间。可以说模型越复杂,使用Keras的收益就越大,尤其是在高度依赖权值共享、多模型组合、多任务学习等模型上,Keras表现得非常突出。Keras所有的模块都是简洁、易懂、完全可配置、可随意插拔的,并且基本上没有任何使用限制,神经网络、损失函数、优化器、初始化方法、激活函数和正则化等模块都是可以自由组合的。Keras也包括绝大部分state-of-the-art的Trick,包括Adam、RMSProp、Batch Normalization、PReLU、ELU、LeakyReLU等。同时,新的模块也很容易添加,这让Keras非常适合最前沿的研究。Keras中的模型也都是在Python中定义的,不像Caffe、CNTK等需要额外的文件来定义模型,这样就可以通过编程的方式调试模型结构和各种超参数。在Keras中,只需要几行代码就能实现一个MLP,或者十几行代码实现一个AlexNet,这在其他深度学习框架中基本是不可能完成的任务。Keras最大的问题可能是目前无法直接使用多GPU,所以对大规模的数据处理速度没有其他支持多GPU和分布式的框架快。Keras的编程模型设计和Torch很像,但是相比Torch,Keras构建在Python上,有一套完整的科学计算工具链,而Torch的编程语言Lua并没有这样一条科学计算工具链。无论从社区人数,还是活跃度来看,Keras目前的增长速度都已经远远超过了Torch。
MXNet
官网网址:mxnet.ioGitHub:github.com/dmlc/mxnetMXNet是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植的、灵活的深度学习库,它让用户可以混合使用符号编程模式和指令式编程模式来最大化效率和灵活性,目前已经是AWS官方推荐的深度学习框架。MXNet的很多作者都是中国人,其最大的贡献组织为百度,同时很多作者来自cxxnet、minerva和purine2等深度学习项目,可谓博采众家之长。它是各个框架中率先支持多GPU和分布式的,同时其分布式性能也非常高。MXNet的核心是一个动态的依赖调度器,支持自动将计算任务并行化到多个GPU或分布式集群(支持AWS、Azure、Yarn等)。它上层的计算图优化算法可以让符号计算执行得非常快,而且节约内存,开启mirror模式会更加省内存,甚至可以在某些小内存GPU上训练其他框架因显存不够而训练不了的深度学习模型,也可以在移动设备(Android、iOS)上运行基于深度学习的图像识别等任务。此外,MXNet的一个很大的优点是支持非常多的语言封装,比如C++、Python、R、Julia、Scala、Go、MATLAB和JavaScript等,可谓非常全面,基本主流的脚本语言全部都支持了。在MXNet中构建一个网络需要的时间可能比Keras、Torch这类高度封装的框架要长,但是比直接用Theano等要快。MXNet的各级系统架构(下面为硬件及操作系统底层,逐层向上为越来越抽象的接口)如图2-6所示。
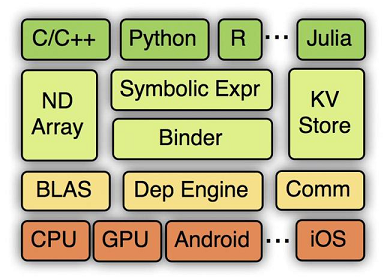
DIGITS
官方网址:developer.nvidia.com/digitsGitHub: github.com/NVIDIA/DIGITSDIGITS(Deep Learning GPU Training System)不是一个标准的深度学习库,它可以算是一个Caffe的高级封装(或者Caffe的Web版培训系统)。因为封装得非常重,以至于你不需要(也不能)在DIGITS中写代码,即可实现一个深度学习的图片识别模型。在Caffe中,定义模型结构、预处理数据、进行训练并监控训练过程是相对比较烦琐的,DIGITS把所有这些操作都简化为在浏览器中执行。它可以算作Caffe在图片分类上的一个漂亮的用户可视化界面(GUI),计算机视觉的研究者或者工程师可以非常方便地设计深度学习模型、测试准确率,以及调试各种超参数。同时使用它也可以生成数据和训练结果的可视化统计报表,甚至是网络的可视化结构图。训练好的Caffe模型可以被DIGITS直接使用,上传图片到服务器或者输入url即可对图片进行分类。
CNTK
官方网址:cntk.aiGitHub:github.com/Microsoft/CNTKCNTK(Computational Network Toolkit)是微软研究院(MSR)开源的深度学习框架。它最早由start the deep learning craze的演讲人创建,目前已经发展成一个通用的、跨平台的深度学习系统,在语音识别领域的使用尤其广泛。CNTK通过一个有向图将神经网络描述为一系列的运算操作,这个有向图中子节点代表输入或网络参数,其他节点代表各种矩阵运算。CNTK支持各种前馈网络,包括MLP、CNN、RNN、LSTM、Sequence-to-Sequence模型等,也支持自动求解梯度。CNTK有丰富的细粒度的神经网络组件,使得用户不需要写底层的C++或CUDA,就能通过组合这些组件设计新的复杂的Layer。CNTK拥有产品级的代码质量,支持多机、多GPU的分布式训练。CNTK设计是性能导向的,在CPU、单GPU、多GPU,以及GPU集群上都有非常优异的表现。同时微软最近推出的1-bit compression技术大大降低了通信代价,让大规模并行训练拥有了很高的效率。CNTK同时宣称拥有很高的灵活度,它和Caffe一样通过配置文件定义网络结构,再通过命令行程序执行训练,支持构建任意的计算图,支持AdaGrad、RmsProp等优化方法。它的另一个重要特性就是拓展性,CNTK除了内置的大量运算核,还允许用户定义他们自己的计算节点,支持高度的定制化。CNTK在2016年9月发布了对强化学习的支持,同时,除了通过写配置文件的方式定义网络结构,CNTK还将支持其他语言的绑定,包括Python、C++和C#,这样用户就可以用编程的方式设计网络结构。CNTK与Caffe一样也基于C++并且跨平台,大部分情况下,它的部署非常简单。PC上支持Linux、Mac和Windows,但是它目前不支持ARM架构,限制了其在移动设备上的发挥。图2-7所示为CNTK目前的总体架构图。
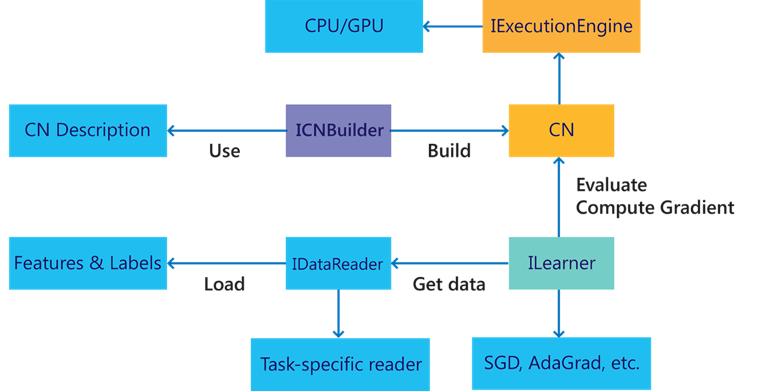
Deeplearning4J
官方网址:http://deeplearning4j.org/GitHub: github.com/deeplearning4j/deeplearning4jDeeplearning4J(简称DL4J)是一个基于Java和Scala的开源的分布式深度学习库,由Skymind于2014年6月发布,其核心目标是创建一个即插即用的解决方案原型。埃森哲、雪弗兰、博斯咨询和IBM等都是DL4J的客户。DL4J拥有一个多用途的n-dimensional array的类,可以方便地对数据进行各种操作;拥有多种后端计算核心,用以支持CPU及GPU加速,在图像识别等训练任务上的性能与Caffe相当;可以与Hadoop及Spark自动整合,同时可以方便地在现有集群(包括但不限于AWS,Azure等)上进行扩展,同时DL4J的并行化是根据集群的节点和连接自动优化,不像其他深度学习库那样可能需要用户手动调整。DL4J选择Java作为其主要语言的原因是,目前基于Java的分布式计算、云计算、大数据的生态非常庞大。用户可能拥有大量的基于Hadoop和Spark的集群,因此在这类集群上搭建深度学习平台的需求便很容易被DL4J满足。同时JVM的生态圈内还有数不胜数的Library的支持,而DL4J也创建了ND4J,可以说是JVM中的NumPy,支持大规模的矩阵运算。此外,DL4J还有商业版的支持,付费用户在出现问题时可以通过电话咨询寻求支持。
Chainer
官方网址:chainer.orgGitHub:github.com/pfnet/chainerChainer是由日本公司Preferred Networks于2015年6月发布的深度学习框架。Chainer对自己的特性描述如下。
- Powerful:支持CUDA计算,只需要几行代码就可以使用GPU加速,同时只需少许改动就可以运行在多GPU上。
- Flexible:支持多种前馈神经网络,包括卷积网络、循环网络、递归网络,支持运行中动态定义的网络(Define-by-Run)。
- Intuitive:前馈计算可以引入Python的各种控制流,同时反向传播时不受干扰,简化了调试错误的难度。
Leaf
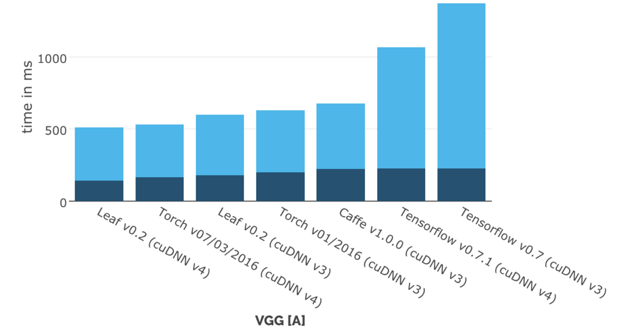
官方网址:autumnai.com/leaf/bookGitHub:github.com/autumnai/leafLeaf是一个基于Rust语言的直观的跨平台的深度学习乃至机器智能框架,它拥有一个清晰的架构,除了同属Autumn AI的底层计算库Collenchyma,Leaf没有其他依赖库。它易于维护和使用,并且拥有非常高的性能。Leaf自身宣传的特点是为Hackers定制的,这里的Hackers是指希望用最短的时间和最少的精力实现机器学习算法的技术极客。它的可移植性非常好,可以运行在CPU、GPU和FPGA等设备上,可以支持有任何操作系统的PC、服务器,甚至是没有操作系统的嵌入式设备,并且同时支持OpenCL和CUDA。Leaf是Autumn AI计划的一个重要组件,后者的目标是让人工智能算法的效率提高100倍。凭借其优秀的设计,Leaf可以用来创建各种独立的模块,比如深度强化学习、可视化监控、网络部署、自动化预处理和大规模产品部署等。Leaf拥有最简单的API,希望可以最简化用户需要掌握的技术栈。虽然才刚诞生不久,Leaf就已经跻身最快的深度学习框架之一了。图2-9所示为Leaf官网公布的各个框架在单GPU上训练VGG网络的计算时间(越小越好)的对比(这是和早期的TensorFlow对比,最新版的TensorFlow性能已经非常好了)。
DSSTNE
GitHub:github.com/amznlabs/amazon-dsstne DSSTNE(Deep Scalable Sparse Tensor Network Engine)是亚马逊开源的稀疏神经网络框架,在训练非常稀疏的数据时具有很大的优势。DSSTNE目前只支持全连接的神经网络,不支持卷积网络等。和Caffe类似,它也是通过写一个JSON类型的文件定义模型结构,但是支持非常大的Layer(输入和输出节点都非常多);在激活函数、初始化方式及优化器方面基本都支持了state-of-the-art的方法,比较全面;支持大规模分布式的GPU训练,不像其他框架一样主要依赖数据并行,DSSTNE支持自动的模型并行(使用数据并行需要在训练速度和模型准确度上做一定的trade-off,模型并行没有这个问题)。在处理特征非常多(上亿维)的稀疏训练数据时(经常在推荐、广告、自然语言处理任务中出现),即使一个简单的3个隐层的MLP(Multi-Layer Perceptron)也会变成一个有非常多参数的模型(可能高达上万亿)。以传统的稠密矩阵的方式训练方法很难处理这么多的模型参数,更不必提超大规模的数据量,而DSSTNE有整套的针对稀疏数据的优化,率先实现了对超大稀疏数据训练的支持,同时在性能上做了非常大的改进。在DSSTNE官方公布的测试中,DSSTNE在MovieLens的稀疏数据上,在单M40 GPU上取得了比TensorFlow快14.8倍的性能提升(注意是和老版的TensorFlow比较),如图2-10所示。一方面是因为DSSTNE对稀疏数据的优化;另一方面是TensorFlow在数据传输到GPU上时花费了大量时间,而DSSTNE则优化了数据在GPU内的保留;同时DSSTNE还拥有自动模型并行功能,而TensorFlow中则需要手动优化,没有自动支持。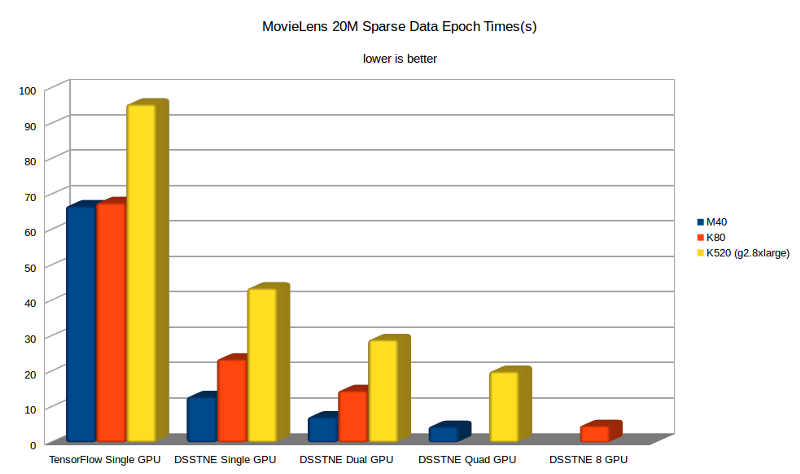
作者:黄文坚,PPmoney大数据算法总监;唐源,美国Uptake数据科学家。
《TensorFlow实战》是国内首本由Google TensorFlow团队官方推荐的教程,两位作者也均是TensorFlow开发者,其中唐源是TensorFlow开发团队的committer。本书结合了大量实例代码,深入浅出地介绍了如何使用TensorFlow创建各种深度学习模型,是初学者入门的最佳书籍。订购链接:https://item.jd.com/12125568.html


SDCC 2017·上海站将于2017年3月17-19日登陆申城,三大技术峰会24位嘉宾,汇聚国内一线的互联网公司大牛,畅谈运维、数据库和架构的热门话题和技术热点,精益运维发起人&优维科技CEO王津银、MongoDB 大中华区首席架构师唐建法和华为软件API开放平台架构师李林锋等亲临现场。3月5日前门票八折优惠中,5人以上团购立减400元,详情点击注册参会