{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 一纸荒年 的文章《判别式与生成式模型的区别》','https://www.xiaopingtou.net/article-57660.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
判别式模型与生成式模型的区别
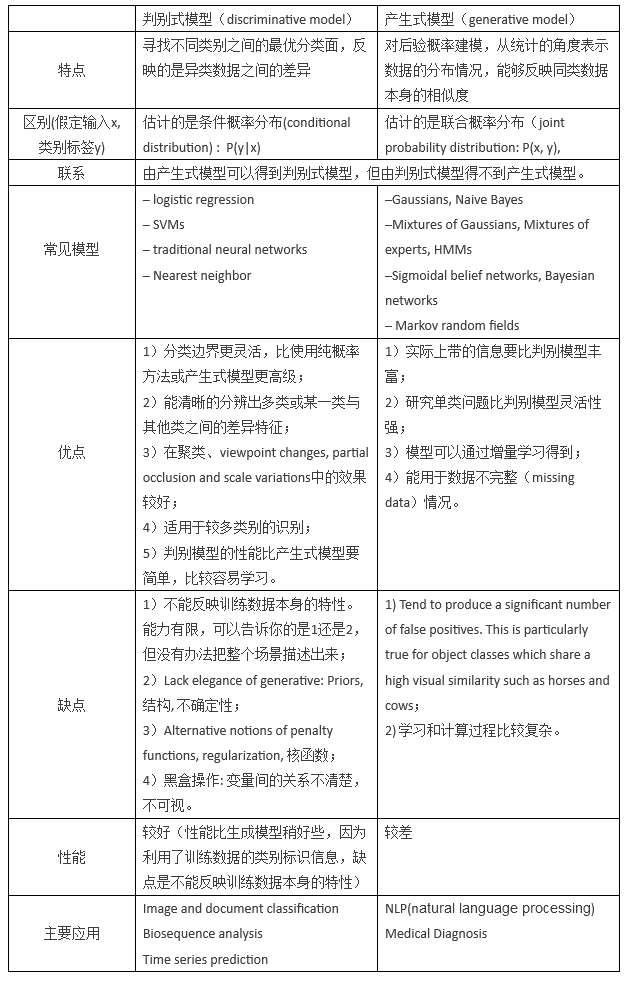
产生式模型(Generative Model)与判别式模型(Discrimitive Model)是分类器常遇到的概念,它们的区别在于:
对于输入x,类别标签y:产生式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
产生式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。
Andrew Ng在NIPS2001年有一篇专门比较判别模型和产生式模型的文章:
On Discrimitive vs. Generative classifiers: A comparision of logistic regression and naive Bayes
(http://robotics.stanford.edu/~ang/papers/nips01-discriminativegenerative.pdf)
判别式模型常见的主要有:
Logistic Regression SVM Traditional Neural Networks Nearest Neighbor CRF Linear Discriminant Analysis Boosting Linear Regression产生式模型常见的主要有:
Gaussians Naive Bayes
Mixtures of Multinomials Mixtures of Gaussians Mixtures of Experts HMMs Sigmoidal Belief Networks, Bayesian Networks Markov Random Fields Latent Dirichlet Allocation
一个通俗易懂的解释
Let’s say you have input data x and you want to classify the data into labels y. A generative model learns the joint probability distribution p(x,y) and a discriminative model learns the conditional probability distribution p(y|x) – which you should read as ‘the probability of y given x’. Here’s a really simple example. Suppose you have the following data in the form (x,y): (1,0), (1,0), (2,0), (2, 1) p(x,y) is y=0 y=1 x=1 1/2 0 x=2 1/4 1/4p(y|x) is y=0 y=1 x=1 1 0 x=2 1/2 1/2
If you take a few minutes to stare at those two matrices, you will understand the difference between the two probability distributions. The distribution p(y|x) is the natural distribution for classifying a given example x into a class y, which is why algorithms that model this directly are called discriminative algorithms. Generative algorithms model p(x,y), which can be tranformed into p(y|x) by applying Bayes rule and then used for classification. However, the distribution p(x,y) can also be used for other purposes. For example you could use p(x,y) to generate likely (x,y) pairs. From the description above you might be thinking that generative models are more generally useful and therefore better, but it’s not as simple as that. This paper is a very popular reference on the subject of discriminative vs. generative classifiers, but it’s pretty heavy going. The overall gist is that discriminative models generally outperform generative models in classification tasks.
两个模型的对比
参考资料:
http://bbs.sciencenet.cn/blog-484653-442300.html http://www.leexiang.com/discriminative-model-and-generative-model
http://blog.163.com/huai_jing@126/blog/static/1718619832011227757554/