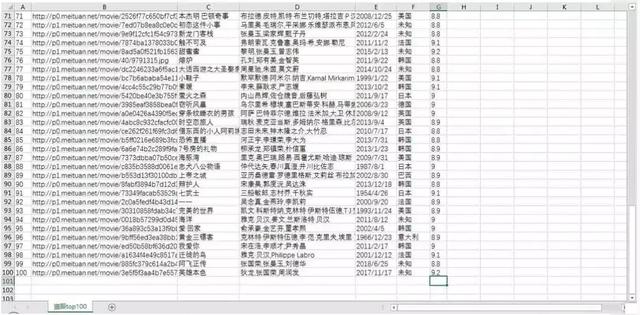
 该网页上有 100 电影的电影名称、演员名、评分、上映时间等信息,需要爬取下来,然后存储到本地 CSV 文件。
该网页上有 100 电影的电影名称、演员名、评分、上映时间等信息,需要爬取下来,然后存储到本地 CSV 文件。
 接着,对这些数据做简单地分析,分析内容包括这几方面:
接着,对这些数据做简单地分析,分析内容包括这几方面:
 接下来就需要从 HTML 源代码中提取出所需内容,我们前述所说的四种方法来解析提取,下面一一介绍。
2.2. 正则表达式提取
正则表达式从字面上难以理解,下面这串看起来乱七八糟的符号就是正则表达式。
'
接下来就需要从 HTML 源代码中提取出所需内容,我们前述所说的四种方法来解析提取,下面一一介绍。
2.2. 正则表达式提取
正则表达式从字面上难以理解,下面这串看起来乱七八糟的符号就是正则表达式。
' 下面,就来提取所需信息。右键网页-检查-Network 选项,选中左边第一个文件然后定位到电影信息的相应位置,如下图:
下面,就来提取所需信息。右键网页-检查-Network 选项,选中左边第一个文件然后定位到电影信息的相应位置,如下图:
 可以看到每部电影的相关信息都在dd这个节点之中,就可以从该节点运用正则提取。
第 1 个要提取的内容是电影排名,是数字。
它位于 class="board-index"的i节点内。不需要提取的内容用'.*?'替代,需要提取的数字排名用()括起来,()里面的数字表示为(d+)。正则表达式可以写为:
可以看到每部电影的相关信息都在dd这个节点之中,就可以从该节点运用正则提取。
第 1 个要提取的内容是电影排名,是数字。
它位于 class="board-index"的i节点内。不需要提取的内容用'.*?'替代,需要提取的数字排名用()括起来,()里面的数字表示为(d+)。正则表达式可以写为:
 下面,我们利用 lxml 和 XPath 来提取信息。
下面,我们利用 lxml 和 XPath 来提取信息。
2018-08-18已更新
榜单规则:将猫眼电影库中的经典影片,按照评分和评分人数从高到低综合排序取前 100 名,每天上午 10 点更新。相关数据来源于“猫眼电影库”。
-
1


9.6
-
根据截取的部分 html 网页,先来提取第 1 个电影排名信息,有两种方法。
第一种是直接复制。
右键-Copy-Copy Xpath,得到 XPath 路径为://*[@id="app"]/div/div/div[1]/dl/dd[1]/i,为了能够提取到页面所有的排名信息,需进一步修改为:/*[@id="app"]/div/div/div[1]/dl/dd/i/text(),如果想要再精简一点,可以省去中间部分绝对路径'/'然后用相对路径'//'代替,最后进一步修改为://*[@id="app"]//div//dd/i/text()。
 第二种:观察网页结构自己写。
注意到id = app的 div 节点,因为在整个网页结构 id 是唯一的不会有第二个相同的,所有可以将该 div 节点作为 xpath 语法的起点,然后往下观察分别是 3 级 div 节点,可以省略写为://div,再往下分别是是两个并列的p节点、dl节点、dd节点和最后的i节点文本。中间可以随意省略,只要保证该路径能够选择到唯一的文本值'1'即可,例如省去 p 和 dl 节点,只保留后面的节点。这样,完整路径可以为:*//*[@id="app"]//div//dd/i/text(),和上式一样。
第二种:观察网页结构自己写。
注意到id = app的 div 节点,因为在整个网页结构 id 是唯一的不会有第二个相同的,所有可以将该 div 节点作为 xpath 语法的起点,然后往下观察分别是 3 级 div 节点,可以省略写为://div,再往下分别是是两个并列的p节点、dl节点、dd节点和最后的i节点文本。中间可以随意省略,只要保证该路径能够选择到唯一的文本值'1'即可,例如省去 p 和 dl 节点,只保留后面的节点。这样,完整路径可以为:*//*[@id="app"]//div//dd/i/text(),和上式一样。
 根据上述思路,可以写下其他内容的 XPath 路径。观察到路径的前一部分://*[@id="app"]//div//dd都是一样的,从后面才开始不同,因此为了能够精简代码,将前部分路径赋值为一个变量 items,最终提取的代码如下:
根据上述思路,可以写下其他内容的 XPath 路径。观察到路径的前一部分://*[@id="app"]//div//dd都是一样的,从后面才开始不同,因此为了能够精简代码,将前部分路径赋值为一个变量 items,最终提取的代码如下:
# 2 用 lxml 结合 xpath 提取内容 from lxml import etree def parse_one_page2(html): parse = etree.HTML(html) items = parse.xpath('//*[@id="app"]//div//dd') # 完整的是//*[@id="app"]/div/div/div[1]/dl/dd # print(type(items)) # *代表匹配所有节点,@表示属性 # 第一个电影是 dd[1],要提取页面所有电影则去掉[1] # xpath://*[@id="app"]/div/div/div[1]/dl/dd[1] for item in items: yield{ 'index': item.xpath('./i/text()')[0], #./i/text()前面的点表示从 items 节点开始 #/text()提取文本 'thumb': get_thumb(str(item.xpath('./a/img[2]/@src')[0].strip())), # 'thumb': 要在 network 中定位,在 elements 里会写成@src 而不是@data-src,从而会报 list index out of range 错误。 'name': item.xpath('./a/@title')[0], 'star': item.xpath('.//p[@class = "star"]/text()')[0].strip(), 'time': get_release_time(item.xpath( './/p[@class = "releasetime"]/text()')[0].strip()[5:]), 'area': get_release_area(item.xpath( './/p[@class = "releasetime"]/text()')[0].strip()[5:]), 'score' : item.xpath('.//p[@class = "score"]/i[1]/text()')[0] + item.xpath('.//p[@class = "score"]/i[2]/text()')[0] }tips:[0]:XPath 后面添加了[0]是因为返回的是只有 1 个字符串的 list,添加[0]是将 list 提取为字符串,使其简洁; Network:要在最原始的 Network 选项卡中定位,而不是 Elements 中,不然提取不到相关内容; p[@class = "star"]/text():提取 class 属性为"star"的 p 节点的文本值; img[2]/@src':提取 img 节点的 src 属性值,属性值后面无需添加'/text()'
运行程序,就可成功地提取出所需内容,结果和第一种方法一样。 如果不太习惯 XPath 语法,可以试试下面的第三种方法。Python学习群:556370268,有大牛答疑,有资源共享!是一个非常不错的交流基地!欢迎喜欢Python的小伙伴!
2.4. Beautiful Soup + CSS 选择器 Beautiful Soup 同 lxml 一样,是一个非常强大的 Python 解析库,可以从 HTML 或 XML 文件中提取效率非常高,常用的语法如下: 更多用法可参考下面的教程:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
不过 Beautiful Soup 通常结合 CSS 选择器一起使用,形成 soup.select 方法,提取信息更简单。CSS 选择器选是一种模式,用于选择需要添加样式的元素,使用它的语法同样能够快速定位到所需节点,然后提取相应内容。
CSS 选择器常用的规则 :
更多用法可参考下面的教程:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
不过 Beautiful Soup 通常结合 CSS 选择器一起使用,形成 soup.select 方法,提取信息更简单。CSS 选择器选是一种模式,用于选择需要添加样式的元素,使用它的语法同样能够快速定位到所需节点,然后提取相应内容。
CSS 选择器常用的规则 :
 更多用法可参考下面的教程:
http://www.w3school.com.cn/cssref/css_selectors.asp
下面就利用这种方式来提取:
更多用法可参考下面的教程:
http://www.w3school.com.cn/cssref/css_selectors.asp
下面就利用这种方式来提取:
# 3 用 beautifulsoup + css 选择器提取 def parse_one_page3(html): soup = BeautifulSoup(html, 'lxml') items = range(10) for item in items: yield{ 'index': soup.select('dd i.board-index')[item].string, # iclass 节点完整地为'board-index board-index-1',写 board-index 即可 'thumb': get_thumb(soup.select('a > img.board-img')[item]["src"]), # 表示 a 节点下面的 class = board-img 的 img 节点,注意浏览器 eelement 里面是 src 节点,而 network 里面是 src 节点,要用这个才能正确返回值 'name': soup.select('.name a')[item].string, 'star': soup.select('.star')[item].string.strip()[3:], 'time': get_release_time(soup.select('.releasetime')[item].string.strip()[5:]), 'area': get_release_area(soup.select('.releasetime')[item].string.strip()[5:]), 'score': soup.select('.integer')[item].string + soup.select('.fraction')[item].string运行上述程序,结果同同前述方法一样。 2.5. Beautiful Soup + find_all 函数提取 Beautifulsoup 除了和 CSS 选择器搭配,还可以直接用它自带的 find_all 函数进行提取。 find_all,顾名思义,就是查询所有符合条件的元素,可以给它传入一些属性或文本来得到符合条件的元素,功能十分强大,API 接口如下:find_all(name , attrs , recursive , text , **kwargs)常用的语法规则有这几点soup.find_all(name='ul'): 查找所有ul节点,ul 节点内还可以嵌套; li.string 和 li.get_text():都是获取li节点的文本,但推荐使用后者; soup.find_all(attrs={'id': 'list-1'})):传入 attrs 参数,参数的类型是字典类型,表示查询 id 为list-1 的节点; 常用的属性比如 id、class 等,可以省略 attrs 采用更简洁的形式,例如: soup.find_all(id='list-1') soup.find_all(class_='element')
用这种方法提取内容,可以这样写:def parse_one_page4(html): soup = BeautifulSoup(html,'lxml') items = range(10) for item in items: yield{ 'index': soup.find_all(class_='board-index')[item].string, 'thumb': soup.find_all(class_ = 'board-img')[item].attrs['src'], # 用.get('src')获取图片 src 链接,或者用 attrs['src'] 'name': soup.find_all(name = 'p',attrs = {'class' : 'name'})[item].string, 'star': soup.find_all(name = 'p',attrs = {'class':'star'})[item].string.strip()[3:], 'time': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]), 'area': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]), 'score':soup.find_all(name = 'i',attrs = {'class':'integer'})[item].string.strip() + soup.find_all(name = 'i',attrs = {'class':'fraction'})[item].string.strip() }提取结果仍然和前述方法一样。 以上,我们用了四种不同方法来解析提取信息,通过对比可以加深对每种方法的理解,接下来就要保存提取的内容。 3. 数据存储 上面输出的结果是字典格式,可利用 csv 包的 DictWriter 函数将字典格式数据存储到 csv 文件中。# 数据存储到 csv def write_to_file3(item): with open('猫眼 top100.csv', 'a', encoding='utf_8_sig',newline='') as f: # 'a'为追加模式(添加) # utf_8_sig 格式导出 csv 不乱码 fieldnames = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score'] w = csv.DictWriter(f,fieldnames = fieldnames) # w.writeheader() w.writerow(item)然后修改一下 main()方法:def main(): url = 'http://maoyan.com/board/4?offset=0' html = get_one_page(url) for item in parse_one_page(html): # print(item) write_to_csv(item) if __name__ == '__main__': main()结果如下图: 再把封面的图片下载下来:
def download_thumb(name, url,num): try: response = requests.get(url) with open('封面图/' + name + '.jpg', 'wb') as f: f.write(response.content) print('第%s 部电影封面下载完毕' %num) print('------') except RequestException as e: print(e) pass # 不能是 w,否则会报错,因为图片是二进制数据所以要用 wb 这样我们就完成了第一页信息爬取和存储。一共有十页信息,下面我们构造一个简单这样我们就完成了第一页信息爬取和存储。一共有十页信息,下面我们构造一个简单的循环,就可以爬取全部页数信息。 4. 分页爬取 剩下 9 页共 90 部电影的数据可以给网址传入一个 offset 参数,然后遍历 URL 重复执行上面的过程即可,代码修改如下:def main(offset): url = 'http://maoyan.com/board/4?offset=' + str(offset) html = get_one_page(url) for item in parse_one_page(html): write_to_csv(item) if __name__ == '__main__': for i in range(10): main(offset = i*10)这样我们就爬取了全部电影信息,结果如下:
 5. 数据分析
俗话说“文不如表,表不如图”。下面爬取的数据做简单的数据可视化分析。
5.1. 评分最高的十部电影
先来看一看评分最高的十部电影是哪些,代码编写如下:
5. 数据分析
俗话说“文不如表,表不如图”。下面爬取的数据做简单的数据可视化分析。
5.1. 评分最高的十部电影
先来看一看评分最高的十部电影是哪些,代码编写如下:
import pandas as pd import matplotlib.pyplot as plt import pylab as pl #用于修改 x 轴坐标 plt.style.use('ggplot') #默认绘图风格很难看,替换为好看的 ggplot 风格 fig = plt.figure(figsize=(8,5)) #设置图片大小 colors1 = '#6D6D6D' #设置图表 title、text 标注的颜 {MOD} columns = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score'] #设置表头 df = pd.read_csv('maoyan_top100.csv',encoding = "utf-8",header = None,names =columns,index_col = 'index') #打开表格 # index_col = 'index' 将索引设为 index df_score = df.sort_values('score',ascending = False) #按得分降序排列 name1 = df_score.name[:10] #x 轴坐标 score1 = df_score.score[:10] #y 轴坐标 plt.bar(range(10),score1,tick_label = name1) #绘制条形图,用 range()能搞保持 x 轴正确顺序 plt.ylim ((9,9.8)) #设置纵坐标轴范围 plt.title('电影评分最高 top10',color = colors1) #标题 plt.xlabel('电影名称') #x 轴标题 plt.ylabel('评分') #y 轴标题 # 为每个条形图添加数值标签 for x,y in enumerate(list(score1)): plt.text(x,y+0.01,'%s' %round(y,1),ha = 'center',color = colors1) pl.xticks(rotation=270) #x 轴名称太长发生重叠,旋转为纵向显示 plt.tight_layout() #自动控制空白边缘,以全部显示 x 轴名称 # plt.savefig('电影评分最高 top10.png') #保存图片 plt.show()结果如下图: 可以看到,排名最高的分别是两部国产片《霸王别姬》和《大话西游》,其他还包括《肖申克的救赎》、《教父》等。
5.2. 各国电影数量对比
来了解一下这 100 部电影都是来自哪些国家,代码编写如下:
可以看到,排名最高的分别是两部国产片《霸王别姬》和《大话西游》,其他还包括《肖申克的救赎》、《教父》等。
5.2. 各国电影数量对比
来了解一下这 100 部电影都是来自哪些国家,代码编写如下:
area_count = df.groupby(by = 'area').area.count().sort_values(ascending = False) # 绘图方法 1 area_count.plot.bar(color = '#4652B1') #设置为蓝紫 {MOD} pl.xticks(rotation=0) #x 轴名称太长重叠,旋转为纵向 # 绘图方法 2 # plt.bar(range(11),area_count.values,tick_label = area_count.index) for x,y in enumerate(list(area_count.values)): plt.text(x,y+0.5,'%s' %round(y,1),ha = 'center',color = colors1) plt.title('各国/地区电影数量排名',color = colors1) plt.xlabel('国家/地区') plt.ylabel('数量(部)') plt.show() # plt.savefig('各国(地区)电影数量排名.png')结果如下图: 可以看到,除去网站自身没有显示国家的电影以外,上榜电影被 10 个国家/地区"承包"了。其中,美国以 30 部电影的绝对优势占据第 1 名,其次是 8 部的日本,7 部的韩国。香港有 5 部,而内地一部都没有。
5.3. 电影大年
这些电影拍摄的年份时间跨度很大,统计一下各年的电影数量,看看是否存在"电影大年"。
可以看到,除去网站自身没有显示国家的电影以外,上榜电影被 10 个国家/地区"承包"了。其中,美国以 30 部电影的绝对优势占据第 1 名,其次是 8 部的日本,7 部的韩国。香港有 5 部,而内地一部都没有。
5.3. 电影大年
这些电影拍摄的年份时间跨度很大,统计一下各年的电影数量,看看是否存在"电影大年"。
# 从日期中提取年份 df['year'] = df['time'].map(lambda x:x.split('/')[0]) # print(df.info()) # print(df.head()) # 统计各年上映的电影数量 grouped_year = df.groupby('year') grouped_year_amount = grouped_year.year.count() top_year = grouped_year_amount.sort_values(ascending = False) # 绘图 top_year.plot(kind = 'bar',color = 'orangered') #颜 {MOD}设置为橙红 {MOD} for x,y in enumerate(list(top_year.values)): plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1) plt.title('电影数量年份排名',color = colors1) plt.xlabel('年份(年)') plt.ylabel('数量(部)') plt.tight_layout() # plt.savefig('电影数量年份排名.png') plt.show()结果如下图: 可以看到,100 部电影来自 37 个年份。其中 2011 年上榜电影数量最多,达到 9 部;其次是 2010 年的 7 部。网上盛传的传" 1994 电影史奇迹年" 仅排名第 6,猫眼榜单的权威性有待考量。
另外,上世纪三四十年代也有电影上榜,那会儿还是黑白电影,反映了电影的口碑好坏跟外在技术没有绝对的关系,质量才是王道。
5.4. 电影作品最多的演员
最后,看看前 100 部电影中哪些演员的作品数量最多。
可以看到,100 部电影来自 37 个年份。其中 2011 年上榜电影数量最多,达到 9 部;其次是 2010 年的 7 部。网上盛传的传" 1994 电影史奇迹年" 仅排名第 6,猫眼榜单的权威性有待考量。
另外,上世纪三四十年代也有电影上榜,那会儿还是黑白电影,反映了电影的口碑好坏跟外在技术没有绝对的关系,质量才是王道。
5.4. 电影作品最多的演员
最后,看看前 100 部电影中哪些演员的作品数量最多。
#表中的演员位于同一列,用逗号分割符隔开。需进行分割然后全部提取到 list 中 starlist = [] star_total = df.star for i in df.star.str.replace(' ','').str.split(','): starlist.extend(i) # print(starlist) # print(len(starlist)) # set 去除重复的演员名 starall = set(starlist) # print(starall) # print(len(starall)) starall2 = {} for i in starall: if starlist.count(i)>1: # 筛选出电影数量超过 1 部的演员 starall2[i] = starlist.count(i) starall2 = sorted(starall2.items(),key = lambda starlist:starlist[1] ,reverse = True) starall2 = dict(starall2[:10]) #将元组转为字典格式 # 绘图 x_star = list(starall2.keys()) #x 轴坐标 y_star = list(starall2.values()) #y 轴坐标 plt.bar(range(10),y_star,tick_label = x_star) pl.xticks(rotation = 270) for x,y in enumerate(y_star): plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1) plt.title('演员电影作品数量排名',color = colors1) plt.xlabel('演员') plt.ylabel('数量(部)') plt.tight_layout() plt.show() # plt.savefig('演员电影作品数量排名.png')结果如下图: 张国荣排在了第一位,觉得意外么?其次是梁朝伟和周星驰,再之后是布拉德·皮特。仔细数一下,前十名影星中,香港影星占了 6 位,这份榜单真是偏爱港星。
对张国荣以七部影片的巨大优势占据第一感到好奇,来看看是哪七部电影。
张国荣排在了第一位,觉得意外么?其次是梁朝伟和周星驰,再之后是布拉德·皮特。仔细数一下,前十名影星中,香港影星占了 6 位,这份榜单真是偏爱港星。
对张国荣以七部影片的巨大优势占据第一感到好奇,来看看是哪七部电影。
df['star1'] = df['star'].map(lambda x:x.split(',')[0]) #提取 1 号演员 df['star2'] = df['star'].map(lambda x:x.split(',')[1]) #提取 2 号演员 star_most = df[(df.star1 == '张国荣') | (df.star2 == '张国荣')][['star','name']].reset_index('index') # |表示两个条件或查询,之后重置索引 print(star_most)可以看到包括排名第一的《霸王别姬》、第 17 名的《春光乍泄》、第 27 名的《射雕英雄传之东成西就》等。这些电影你都看过么。index star name 0 1 张国荣,张丰毅,巩俐 霸王别姬 1 17 张国荣,梁朝伟,张震 春光乍泄 2 27 张国荣,梁朝伟,张学友 射雕英雄传之东成西就 3 37 张国荣,梁朝伟,刘嘉玲 东邪西毒 4 70 张国荣,王祖贤,午马 倩女幽魂 5 99 张国荣,张曼玉,刘德华 阿飞正传 6 100 狄龙,张国荣,周润发 英雄本 {MOD}以上,我们使用了多种方法爬取并分析了猫眼 TOP 100 电影,初步了解了爬虫的基本技法。Python学习群:556370268,有大牛答疑,有资源共享!是一个非常不错的交流基地!欢迎喜欢Python的小伙伴!

{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 yusifan520 的文章《用Python爬虫爬了猫眼TOP100电影后,我发现了……》','https://www.xiaopingtou.net/article-57947.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}