{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 fpy135 的文章《【转载】如何应对视觉深度学习存在的问题》','https://www.xiaopingtou.net/article-57989.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
雷锋网 AI 科技评论按:我们经常见到介绍计算机视觉领域的深度学习新进展的文章,不过针对深度学习本身的研究经常告诉我们:深度学习并不是那个最终的解决方案,它有许多问题等待我们克服。
曾经在 UCLA 任教,如今来到约翰霍普金斯大学的认知科学与计算机科学教授 Alan L. Yuille 撰写了一篇学术报告(arxiv.org/abs/1805.04025)分析总结了他眼中深度学习在计算机视觉领域的优势和不足,也介绍了自己认为有潜力的解决办法。经过近期的一次修订之后,他也在 thegradient.pub 上发表了这篇论文的通俗介绍文章《The Limitations of Deep Learning for Vision and How We Might Fix Them》(视觉深度学习有哪些限制,我们要如何克服它们)。雷锋网(公众号:雷锋网) AI 科技评论全文翻译如下。

 深度学习方法已经引入各种视觉任务当中
但是,即便深度学习相比于以往的方法有很大优势,它也并不是一种通用的解决方案。在这里,我们重点分析它面对的三方面的限制。
首先,深度学习绝大多数时候都需要大量标注数据。这种方法本身的偏向性也就使得研究人员们更多研究的是那些「有充足数据的、获取标注很容易的任务」,而不是「真正重要的任务」。
目前我们也确实有一些方法可以降低对监督的需求,比如迁移学习、小样本学习、无监督学习、弱监督学习等等。但目前为止,这些方法的表现并不如监督学习那样令人满意。
其次,深度学习在研究人员们构建的评价数据集上表现良好,但对于数据集之外的真实世界图像可能会表现得非常糟糕。所有的数据集都有偏向,早期的视觉数据中的偏向尤其明显,研究人员们也很快就学会了如何利用这些偏向(比如在 Caltech101 数据集中检测「鱼」就很简单,因为只有这一类物体的背景是水,这种情境偏向就可以被利用起来)。随着数据集变得更大、深度神经网络的表现越来越好,这些问题如今稍有缓解,但仍然不容乐观。比如下图中,在 ImageNet 上训练一个能够检测沙发的模型,如果展示给它的图像的视角是 ImageNet 中很少出现的,那么它就不一定能检测出图中的沙发。更具体地说,深度神经网络的偏向是对于数据集中很少出现的情况会表现很糟糕。然而在真实世界应用中,这种偏向尤其可能带来很多问题,在某些情况下如果视觉系统出现失效可能会带来严重的后果。举个例子,用来训练自动驾驶汽车的数据集从来就不会包含路面上坐着一个婴儿的状况。
深度学习方法已经引入各种视觉任务当中
但是,即便深度学习相比于以往的方法有很大优势,它也并不是一种通用的解决方案。在这里,我们重点分析它面对的三方面的限制。
首先,深度学习绝大多数时候都需要大量标注数据。这种方法本身的偏向性也就使得研究人员们更多研究的是那些「有充足数据的、获取标注很容易的任务」,而不是「真正重要的任务」。
目前我们也确实有一些方法可以降低对监督的需求,比如迁移学习、小样本学习、无监督学习、弱监督学习等等。但目前为止,这些方法的表现并不如监督学习那样令人满意。
其次,深度学习在研究人员们构建的评价数据集上表现良好,但对于数据集之外的真实世界图像可能会表现得非常糟糕。所有的数据集都有偏向,早期的视觉数据中的偏向尤其明显,研究人员们也很快就学会了如何利用这些偏向(比如在 Caltech101 数据集中检测「鱼」就很简单,因为只有这一类物体的背景是水,这种情境偏向就可以被利用起来)。随着数据集变得更大、深度神经网络的表现越来越好,这些问题如今稍有缓解,但仍然不容乐观。比如下图中,在 ImageNet 上训练一个能够检测沙发的模型,如果展示给它的图像的视角是 ImageNet 中很少出现的,那么它就不一定能检测出图中的沙发。更具体地说,深度神经网络的偏向是对于数据集中很少出现的情况会表现很糟糕。然而在真实世界应用中,这种偏向尤其可能带来很多问题,在某些情况下如果视觉系统出现失效可能会带来严重的后果。举个例子,用来训练自动驾驶汽车的数据集从来就不会包含路面上坐着一个婴儿的状况。

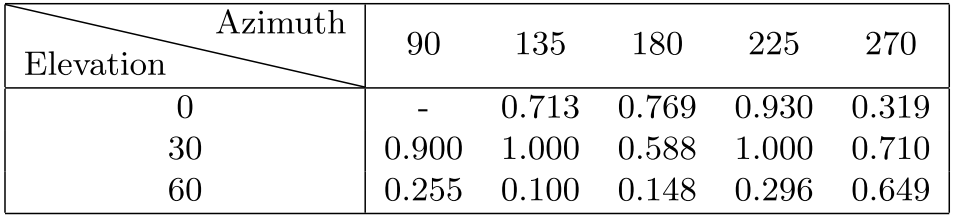 在 UnrealCV 环境中,研究人员们变化摄像机的角度,让 Faster-RCNN 模型识别不同角度的室内环境照片。随着视角变化,检测到沙发的 AP 在 1.0 到 0.1 之间剧烈变化
第三,深度学习对于图像中的变化过于敏感,人类则难以被欺骗得多。我们不仅已经知道标准的对抗性攻击可以对图像做出人类无法感知的微小改变,但可以让深度神经网络的识别结果发生彻底的变化,同时神经网络还对背景环境的变化过于敏感。下图中,研究人眼们把不同的物体拼贴到一张森林中的猴子的照片上。这会让深度神经网络把猴子误识别为人,同时也把吉他误识别为鸟,我们猜测这大概是因为「拿着吉他的更有可能是人类而不是猴子」以及「树林中的猴子周围更有可能出现一只鸟而不是吉他」。深度神经网络记忆相关性的能力在此时反倒成了累赘。近期有许多研究都挖掘了深度神经网络对于背景环境变化过于敏感的问题。
在 UnrealCV 环境中,研究人员们变化摄像机的角度,让 Faster-RCNN 模型识别不同角度的室内环境照片。随着视角变化,检测到沙发的 AP 在 1.0 到 0.1 之间剧烈变化
第三,深度学习对于图像中的变化过于敏感,人类则难以被欺骗得多。我们不仅已经知道标准的对抗性攻击可以对图像做出人类无法感知的微小改变,但可以让深度神经网络的识别结果发生彻底的变化,同时神经网络还对背景环境的变化过于敏感。下图中,研究人眼们把不同的物体拼贴到一张森林中的猴子的照片上。这会让深度神经网络把猴子误识别为人,同时也把吉他误识别为鸟,我们猜测这大概是因为「拿着吉他的更有可能是人类而不是猴子」以及「树林中的猴子周围更有可能出现一只鸟而不是吉他」。深度神经网络记忆相关性的能力在此时反倒成了累赘。近期有许多研究都挖掘了深度神经网络对于背景环境变化过于敏感的问题。
 在照片中增加不同的物体,会影响照片中原有的猴子的识别结果
这种敏感问题也可以归因到数据集的大小上。对于每种物体,它在数据集中出现的时候对应的背景也就只有很少的几种,所以神经网络会对它们有所偏向。比如人们发现,早期的图像转文字数据集中长颈鹿总是和树一起出现,用这样的数据集训练出的模型就无法识别单独出现的长颈鹿,即便它在图像中占据主体位置也不行。
但是我们毕竟没有能力把各种各样的背景环境收集齐全,对模型表现有影响的因素除了这个也还有很多别的,所以深度神经网络这样的数据驱动的方法就面临了不小的问题。想全面改善模型在这些方面的表现需要大得惊人的数据集,这又为构建训练和测试数据集带来了很多挑战。下文我们还会聊到这个问题。
在照片中增加不同的物体,会影响照片中原有的猴子的识别结果
这种敏感问题也可以归因到数据集的大小上。对于每种物体,它在数据集中出现的时候对应的背景也就只有很少的几种,所以神经网络会对它们有所偏向。比如人们发现,早期的图像转文字数据集中长颈鹿总是和树一起出现,用这样的数据集训练出的模型就无法识别单独出现的长颈鹿,即便它在图像中占据主体位置也不行。
但是我们毕竟没有能力把各种各样的背景环境收集齐全,对模型表现有影响的因素除了这个也还有很多别的,所以深度神经网络这样的数据驱动的方法就面临了不小的问题。想全面改善模型在这些方面的表现需要大得惊人的数据集,这又为构建训练和测试数据集带来了很多挑战。下文我们还会聊到这个问题。
 以验证码为例,三个例子从左到右的变化和遮挡逐步增大。(c) 已经达到 CAPTCHA 验证码的难度,深度学习对这样的验证码的表现就要差得多,而复合性模型仍然有不错的表现
复合性模型这个概念的优点已经在一些任务上得到了初步验证,比如用同一个模型执行多种任务,以及识别 CAPTCHA 验证码;深度神经网络就无法维持高水平的表现。还有一些非平凡的视觉任务也表现出了相同的趋势,比如用深度神经网络做 IQ 测试就不怎么成功。这项测试的具体内容是,9 张图像组成一个 3x3 的网格,但只给出其中的 8 张,要推测最后一张的内容;图像之间的变化规律是复合性的,而且会有干扰。对于神经模块网络之类的自然语言模型,由于它们具有动态的网络结构,可以捕捉到一些有意义的组合,就可以在这样的任务中击败传统的神经网络。实际上,我们最近也实验验证了其中的不同模块确实能够在联合训练后各自发挥原本设计的复合功能(比如执行与、或、过滤操作等等)。
复合性模型也还有许多理想的理论属性,比如可解释,还可以用来生成样本。这可以让我们更方便地诊断错误,也就比深度神经网络这样的黑盒模型更难以被欺骗。但是复合性模型也很难学习,因为它需要同时学习基础结构和复合方法(但复合方法的本质是什么都还有待讨论)。而且,为了能够以生成的方式进行分析,复合性模型还需要搭配物体和场景的生成式模型。按分类生成图像到现在都还是一个有难度的课题。
更基础地,处理组合爆炸的问题还需要学习到三维世界事物的常识模型,以及学会这些模型和图像的对应关系。对人类婴儿的研究表明他们的学习方式是构建能够预测他们所在的环境(包括其中的简单几何体)的常识模型。这种常识理解的方式让他们能够从有限的数据中学习,并真正地泛化到全新的环境中。这就好比是牛顿的万有引力定律,从一些基本的数字就可以猜测出引力公式的基本形式,并推广到太阳系内行星的运动规律,不过计算公式中的常数和精确的运动周期还需要大量的数据。
在组合性的数据上测试
测试视觉算法的一个潜在的挑战是我们只能在有限的数据上测试,即便我们测试的算法是为了解决真实世界中巨大的组合复杂度而设计的。博弈论中对这种问题的思考方式是关注于那些最糟糕的情况解决得如何,而不那么关注平均难度的状况解决得如何。正如我们前面谈到的,有限数据集中的平均难度的结果意义并不高,尤其是当数据集无法完全捕捉到问题的组合复杂性的时候。更为关注最糟糕的情况当然是有一定理由的,比如目标是设计自动驾驶汽车的视觉系统,或者在医疗图像中诊断癌症,失误都是更容易在复杂的情况下出现,出现以后也更可能带来严重的后果。
如果失效模式可以在低维空间中捕捉到,比如可以缩小到只有两三个因素的影响,我们就可以通过计算机图形学和网格搜索的方法进行研究。但是对于多数视觉任务,尤其是涉及组合性数据的任务,我们就很难分辨出来一小组影响因素并独立地研究它们。一种策略是在标准的对抗性训练的基础上进行拓展,让它也可以作用于非局部的结构,方法是允许模型对图像的主要结构、场景做复杂的操作(比如遮挡、改变图像中对象的物理属性),但同时不显著改变人类的观感。把这种方法拓展到视觉算法用来解决组合复杂度的问题仍然有不小挑战。不过,如果我们设计算法的时候心里就注意着复合性的事情,它们的显式结构也可以让我们更方便地进行诊断并判断它们是如何失效的。
以验证码为例,三个例子从左到右的变化和遮挡逐步增大。(c) 已经达到 CAPTCHA 验证码的难度,深度学习对这样的验证码的表现就要差得多,而复合性模型仍然有不错的表现
复合性模型这个概念的优点已经在一些任务上得到了初步验证,比如用同一个模型执行多种任务,以及识别 CAPTCHA 验证码;深度神经网络就无法维持高水平的表现。还有一些非平凡的视觉任务也表现出了相同的趋势,比如用深度神经网络做 IQ 测试就不怎么成功。这项测试的具体内容是,9 张图像组成一个 3x3 的网格,但只给出其中的 8 张,要推测最后一张的内容;图像之间的变化规律是复合性的,而且会有干扰。对于神经模块网络之类的自然语言模型,由于它们具有动态的网络结构,可以捕捉到一些有意义的组合,就可以在这样的任务中击败传统的神经网络。实际上,我们最近也实验验证了其中的不同模块确实能够在联合训练后各自发挥原本设计的复合功能(比如执行与、或、过滤操作等等)。
复合性模型也还有许多理想的理论属性,比如可解释,还可以用来生成样本。这可以让我们更方便地诊断错误,也就比深度神经网络这样的黑盒模型更难以被欺骗。但是复合性模型也很难学习,因为它需要同时学习基础结构和复合方法(但复合方法的本质是什么都还有待讨论)。而且,为了能够以生成的方式进行分析,复合性模型还需要搭配物体和场景的生成式模型。按分类生成图像到现在都还是一个有难度的课题。
更基础地,处理组合爆炸的问题还需要学习到三维世界事物的常识模型,以及学会这些模型和图像的对应关系。对人类婴儿的研究表明他们的学习方式是构建能够预测他们所在的环境(包括其中的简单几何体)的常识模型。这种常识理解的方式让他们能够从有限的数据中学习,并真正地泛化到全新的环境中。这就好比是牛顿的万有引力定律,从一些基本的数字就可以猜测出引力公式的基本形式,并推广到太阳系内行星的运动规律,不过计算公式中的常数和精确的运动周期还需要大量的数据。
在组合性的数据上测试
测试视觉算法的一个潜在的挑战是我们只能在有限的数据上测试,即便我们测试的算法是为了解决真实世界中巨大的组合复杂度而设计的。博弈论中对这种问题的思考方式是关注于那些最糟糕的情况解决得如何,而不那么关注平均难度的状况解决得如何。正如我们前面谈到的,有限数据集中的平均难度的结果意义并不高,尤其是当数据集无法完全捕捉到问题的组合复杂性的时候。更为关注最糟糕的情况当然是有一定理由的,比如目标是设计自动驾驶汽车的视觉系统,或者在医疗图像中诊断癌症,失误都是更容易在复杂的情况下出现,出现以后也更可能带来严重的后果。
如果失效模式可以在低维空间中捕捉到,比如可以缩小到只有两三个因素的影响,我们就可以通过计算机图形学和网格搜索的方法进行研究。但是对于多数视觉任务,尤其是涉及组合性数据的任务,我们就很难分辨出来一小组影响因素并独立地研究它们。一种策略是在标准的对抗性训练的基础上进行拓展,让它也可以作用于非局部的结构,方法是允许模型对图像的主要结构、场景做复杂的操作(比如遮挡、改变图像中对象的物理属性),但同时不显著改变人类的观感。把这种方法拓展到视觉算法用来解决组合复杂度的问题仍然有不小挑战。不过,如果我们设计算法的时候心里就注意着复合性的事情,它们的显式结构也可以让我们更方便地进行诊断并判断它们是如何失效的。
风水轮流转的深度学习
如今的深度学习热潮已经是第三次来临了。上世纪 50 年代和 80 年代的两次 AI 热潮虽然也产生了不小的热度,但很快就归于冷清,因为那时的神经网络既无法带来多少性能提升,也没能帮助我们增加对生物视觉系统的理解。2010 年之后愈演愈烈的这次新浪潮就不一样了,如今的神经网络在各种各样的 bechmark 中都取得了前所未有的成绩,也在真实世界中得到了不少应用。其实我们现在在深度学习中用到的许多基础思路在第二次浪潮中就已经出现了,不过,也只有到了第三波浪潮中出现了大规模数据集、高性能计算设备(GPU)之后,它们的威力才得以发挥出来。 神经网络的起起落落也反应了人类对智慧的研究、以及热门的学习算法的不断变化。在第二次浪潮中,我们见证了传统 AI 如何夸下海口、又如何交不出及格的答卷。1980 年代的第二次寒冬就这样来了。这次寒冬中我们也见证了 SVM、核方法等机器学习方法的兴起。如今我们会称赞那些在寒冬中不顾反对之声一直坚持研究神经网络、深度学习的研究人员们,但走向另一个极端的是,当年很难发表一篇关于神经网络的论文,如何则很难发表一篇不是关于神经网络的论文。这并不是什么好的发展方式。如果研究者们能够积极探索各种不同的方法和技术,而不是一窝蜂地涌入深度学习的话,也许整个 AI 领域可以进步得更快一些。而且还有一件事令人担心,如今的 AI 课程有不少已经完全省略了旧时代的 AI 技术,仅仅关注当前趋势的走向。深度学习的成功与失败
直到 2011 年 AlexNet 在 ImageNet 上带来跨越式的表现提升之前,计算机视觉研究领域都对深度学习抱着怀疑的态度。这之后,深度学习越来越成为图像分类、物体检测等许多任务中的标准工具,研究人员们提出的各种网络架构和建模、训练技巧也让深度学习的表现越来越好。 相比于图像分类,物体检测任务针对的图像通常含有一个或更多的物体,背景也更大。用于解决目标识别任务的神经网络通常会分为两个阶段工作,第一个阶段会为物体位置和大小选出一些候选边界框,然后在第二阶段中挑选出正确地包含了物体的边界框并进行分类。在 ImageNet 出现之前,这项任务上表现最佳的方法是 PASCAL 物体检测竞赛中的 Deformable Part Models,它也是那时候主流的物体检测和图像分类算法。在各种其他计算机视觉任务中,不同架构的深度学习模型也分别带来了大规模的表现提升。
深度学习方法已经引入各种视觉任务当中
但是,即便深度学习相比于以往的方法有很大优势,它也并不是一种通用的解决方案。在这里,我们重点分析它面对的三方面的限制。
首先,深度学习绝大多数时候都需要大量标注数据。这种方法本身的偏向性也就使得研究人员们更多研究的是那些「有充足数据的、获取标注很容易的任务」,而不是「真正重要的任务」。
目前我们也确实有一些方法可以降低对监督的需求,比如迁移学习、小样本学习、无监督学习、弱监督学习等等。但目前为止,这些方法的表现并不如监督学习那样令人满意。
其次,深度学习在研究人员们构建的评价数据集上表现良好,但对于数据集之外的真实世界图像可能会表现得非常糟糕。所有的数据集都有偏向,早期的视觉数据中的偏向尤其明显,研究人员们也很快就学会了如何利用这些偏向(比如在 Caltech101 数据集中检测「鱼」就很简单,因为只有这一类物体的背景是水,这种情境偏向就可以被利用起来)。随着数据集变得更大、深度神经网络的表现越来越好,这些问题如今稍有缓解,但仍然不容乐观。比如下图中,在 ImageNet 上训练一个能够检测沙发的模型,如果展示给它的图像的视角是 ImageNet 中很少出现的,那么它就不一定能检测出图中的沙发。更具体地说,深度神经网络的偏向是对于数据集中很少出现的情况会表现很糟糕。然而在真实世界应用中,这种偏向尤其可能带来很多问题,在某些情况下如果视觉系统出现失效可能会带来严重的后果。举个例子,用来训练自动驾驶汽车的数据集从来就不会包含路面上坐着一个婴儿的状况。
在 UnrealCV 环境中,研究人员们变化摄像机的角度,让 Faster-RCNN 模型识别不同角度的室内环境照片。随着视角变化,检测到沙发的 AP 在 1.0 到 0.1 之间剧烈变化
第三,深度学习对于图像中的变化过于敏感,人类则难以被欺骗得多。我们不仅已经知道标准的对抗性攻击可以对图像做出人类无法感知的微小改变,但可以让深度神经网络的识别结果发生彻底的变化,同时神经网络还对背景环境的变化过于敏感。下图中,研究人眼们把不同的物体拼贴到一张森林中的猴子的照片上。这会让深度神经网络把猴子误识别为人,同时也把吉他误识别为鸟,我们猜测这大概是因为「拿着吉他的更有可能是人类而不是猴子」以及「树林中的猴子周围更有可能出现一只鸟而不是吉他」。深度神经网络记忆相关性的能力在此时反倒成了累赘。近期有许多研究都挖掘了深度神经网络对于背景环境变化过于敏感的问题。
在照片中增加不同的物体,会影响照片中原有的猴子的识别结果
这种敏感问题也可以归因到数据集的大小上。对于每种物体,它在数据集中出现的时候对应的背景也就只有很少的几种,所以神经网络会对它们有所偏向。比如人们发现,早期的图像转文字数据集中长颈鹿总是和树一起出现,用这样的数据集训练出的模型就无法识别单独出现的长颈鹿,即便它在图像中占据主体位置也不行。
但是我们毕竟没有能力把各种各样的背景环境收集齐全,对模型表现有影响的因素除了这个也还有很多别的,所以深度神经网络这样的数据驱动的方法就面临了不小的问题。想全面改善模型在这些方面的表现需要大得惊人的数据集,这又为构建训练和测试数据集带来了很多挑战。下文我们还会聊到这个问题。
当数据集不够大的时候
组合爆炸 虽然上面提到的几个问题都还不至于否定了深度学习的成功,但我们认为这些都是存在问题的早期警示信号。具体来说,真实世界的图像是无数多种物体在无数多种背景环境中的组合,所以不管多大的数据集都无法完全代表真实世界的复杂性。 相比于人类天然地就对视觉环境的变化有高度的适应性,深度神经网络要敏感脆弱得多、对错误的容忍度要低得多,就像上面猴子的那张图表明的。值得说明的是,不同物体和不同环境的各种组合在有一些视觉任务中并不会出现,比如医疗图像应用,背景环境的变化要小得多(比如胰腺总是在十二指肠的附近),这时深度神经网络就可以发挥出十分优异的表现。但是对于许多真实世界应用来说,没有随着变量数据而指数级增加的数据集,就没办法捕捉到真实世界的复杂性。 这种状况会带来很大的挑战,因为「在有限数量的随机样本上进行训练和测试」的标准范式会变得不够实用,因为样本数量永远不够大、永远无法完全代表数据的内在分布状况。 这迫使我们思考这两个问题:- 我们如何在样本数量有限的数据集上训练算法,以便让它们在(假想)能够完全捕捉真实世界复杂度的无限大数据集上也能发挥出好的表现;
- 如果我们手中只有有限的数据集,我们要如何高效地测试这些算法才能确保它们在无限大数据集上也有好的表现
克服组合问题
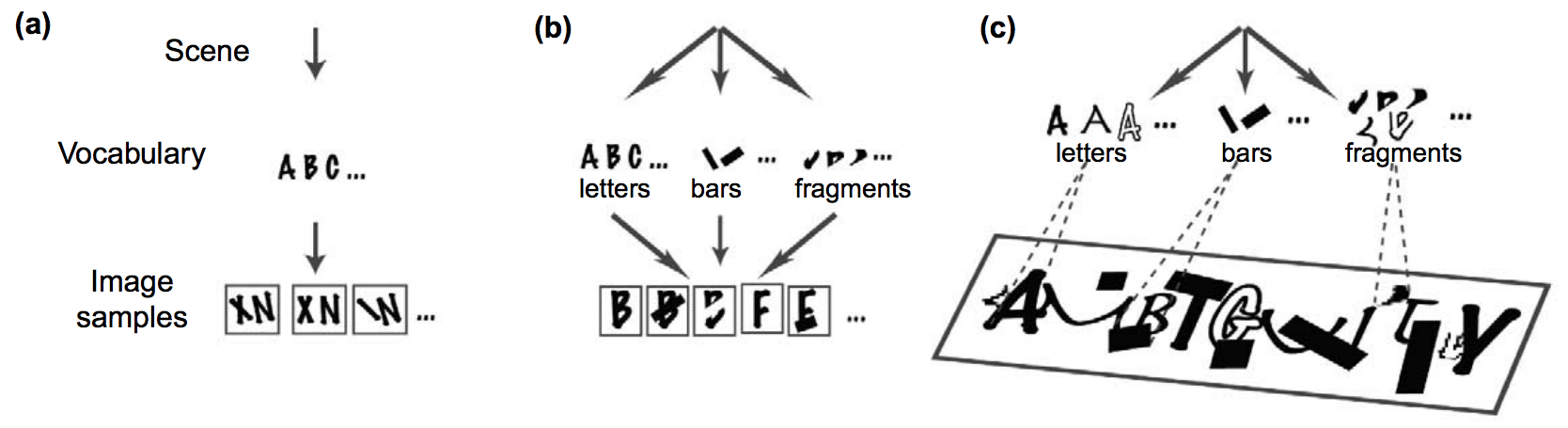
目前形式的数据驱动方法,比如深度神经网络,可能永远也无法完善解决组合爆炸的问题。下面我们列出一些别的有潜力的解决方案。 复合性(Compositionality) 复合性是一条通用原则,我们可以把它描述为「一种相信世界是可知的信念,我们可以把事物分解、理解它们,然后在意念中自由地重新组合它们」。这其中的关键假设是,事物都是按照某一套法则从基础的子结构复合成更大的结构的。这意味着,我们可以从有限的数据中学习到子结构和组合法则,然后把它们泛化到复合性的情境中。 和深度神经网络不同,复合性模型需要结构化的表征,其中要显式地表示出对象的结构和子结构。复合性模型也就拥有了外推到未曾见过的数据,对系统做推理、干涉和诊断,以及对于同样的知识结构回答不同问题的能力。值得指出的是,虽然深度神经网络也能捕捉到某种复合性(比如高级别的特征可以来自地级别特征的相应的复合),但这与这里讨论的复合性不是一回事。
以验证码为例,三个例子从左到右的变化和遮挡逐步增大。(c) 已经达到 CAPTCHA 验证码的难度,深度学习对这样的验证码的表现就要差得多,而复合性模型仍然有不错的表现
复合性模型这个概念的优点已经在一些任务上得到了初步验证,比如用同一个模型执行多种任务,以及识别 CAPTCHA 验证码;深度神经网络就无法维持高水平的表现。还有一些非平凡的视觉任务也表现出了相同的趋势,比如用深度神经网络做 IQ 测试就不怎么成功。这项测试的具体内容是,9 张图像组成一个 3x3 的网格,但只给出其中的 8 张,要推测最后一张的内容;图像之间的变化规律是复合性的,而且会有干扰。对于神经模块网络之类的自然语言模型,由于它们具有动态的网络结构,可以捕捉到一些有意义的组合,就可以在这样的任务中击败传统的神经网络。实际上,我们最近也实验验证了其中的不同模块确实能够在联合训练后各自发挥原本设计的复合功能(比如执行与、或、过滤操作等等)。
复合性模型也还有许多理想的理论属性,比如可解释,还可以用来生成样本。这可以让我们更方便地诊断错误,也就比深度神经网络这样的黑盒模型更难以被欺骗。但是复合性模型也很难学习,因为它需要同时学习基础结构和复合方法(但复合方法的本质是什么都还有待讨论)。而且,为了能够以生成的方式进行分析,复合性模型还需要搭配物体和场景的生成式模型。按分类生成图像到现在都还是一个有难度的课题。
更基础地,处理组合爆炸的问题还需要学习到三维世界事物的常识模型,以及学会这些模型和图像的对应关系。对人类婴儿的研究表明他们的学习方式是构建能够预测他们所在的环境(包括其中的简单几何体)的常识模型。这种常识理解的方式让他们能够从有限的数据中学习,并真正地泛化到全新的环境中。这就好比是牛顿的万有引力定律,从一些基本的数字就可以猜测出引力公式的基本形式,并推广到太阳系内行星的运动规律,不过计算公式中的常数和精确的运动周期还需要大量的数据。
在组合性的数据上测试
测试视觉算法的一个潜在的挑战是我们只能在有限的数据上测试,即便我们测试的算法是为了解决真实世界中巨大的组合复杂度而设计的。博弈论中对这种问题的思考方式是关注于那些最糟糕的情况解决得如何,而不那么关注平均难度的状况解决得如何。正如我们前面谈到的,有限数据集中的平均难度的结果意义并不高,尤其是当数据集无法完全捕捉到问题的组合复杂性的时候。更为关注最糟糕的情况当然是有一定理由的,比如目标是设计自动驾驶汽车的视觉系统,或者在医疗图像中诊断癌症,失误都是更容易在复杂的情况下出现,出现以后也更可能带来严重的后果。
如果失效模式可以在低维空间中捕捉到,比如可以缩小到只有两三个因素的影响,我们就可以通过计算机图形学和网格搜索的方法进行研究。但是对于多数视觉任务,尤其是涉及组合性数据的任务,我们就很难分辨出来一小组影响因素并独立地研究它们。一种策略是在标准的对抗性训练的基础上进行拓展,让它也可以作用于非局部的结构,方法是允许模型对图像的主要结构、场景做复杂的操作(比如遮挡、改变图像中对象的物理属性),但同时不显著改变人类的观感。把这种方法拓展到视觉算法用来解决组合复杂度的问题仍然有不小挑战。不过,如果我们设计算法的时候心里就注意着复合性的事情,它们的显式结构也可以让我们更方便地进行诊断并判断它们是如何失效的。