{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 weixin_38061718 的文章《电商设计架构》','https://www.xiaopingtou.net/article-58029.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
初学者整理,学习用。有不完善地方请大大们指出。。。后续学习了更多知识再陆续补充。
静态架构蓝图:
 CDN:
Content Delivery Network 内容分发网络
其目的是避开影响数据传输速度和稳定的瓶颈和环节,使内容访问更快,更稳定。
通过在网络各处设置节点服务器,构成在现有互联网基础上的一层智能虚拟网络,实时的根据数据流量和各节点连接,负载状况,用户的访问距离,响应时间将用户的请求重新定向到最近的服务节点上,使用户可以就近取得数据,解决了网络拥挤情况,提高用户访问网络的响应速度。
CDN:
Content Delivery Network 内容分发网络
其目的是避开影响数据传输速度和稳定的瓶颈和环节,使内容访问更快,更稳定。
通过在网络各处设置节点服务器,构成在现有互联网基础上的一层智能虚拟网络,实时的根据数据流量和各节点连接,负载状况,用户的访问距离,响应时间将用户的请求重新定向到最近的服务节点上,使用户可以就近取得数据,解决了网络拥挤情况,提高用户访问网络的响应速度。
负载均衡/反向代理 负载均衡:建立在现有网络结构之上,提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽,增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。 英文Load Balance ,其意思就是分摊到多个操作单元上进行执行,如web服务器,FTP服务器,企业关键应用服务器和其他关键任务服务器等,从而共同完成工作任务。
反向代理: 指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。 F5(4层) 四层负责均衡:是通过报文中的目标地址和接口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器与请求客户建立TCP连接,然后发送Client请求的数据。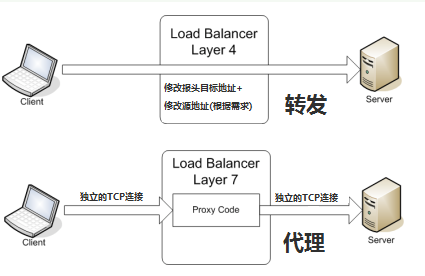 上图,在四层负责设备中,把client发送的报文目标地址(原来是负载均衡设备的IP地址),根据均衡设备设置选择的web服务器的规则选择对应的web服务器IP地址,这样client就可以直接跟此服务器建立TCP连接并发送数据。
Nginx (7层)
是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
是一款轻量级的web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。
Varnish :
是一款高性能的开源http加速器。
Web应用层:
tomcat:是一个免费的开放源代码的应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下普遍使用,是开发和调试JSP的首选。
jboss:是一个基于J2EE的开放源代码的应用服务器。JBoss代码遵循LGPL许可,可以在任何商业应用中免费使用,而不用支付费用,JBoss是一个管理EJB的容器和服务器,支持EJB1.1,EJB2.0和EJB3的规范。但JBoss核心服务不包括支持servlet/JSP的web容器,一般与tomcat或jetty邦定使用。
spring:Spring是一个开源框架。
struts2:Struts2是一个基于MVC设计模式的Web应用框架,它本质上相当于一个servlet,在MVC设计模式中,Struts2作为控制器(Controller)来建立模型与视图的数据交互。
业务层:
mina:Apache Mina是一个能够帮助用户开发高性能和高伸缩性网络应用程序的框架。它通过Java
nio技术基于TCP/IP和UDP/IP协议提供了抽象的、事件驱动的、异步的API。用于内部服务间调用。单线程。
spring:Spring是一个开源框架。
ibatis:iBATIS一词来源于“internet”和“abatis”的组合,是一个由Clinton
Begin在2002年发起的开放源代码项目。于2010年6月16号被谷歌托管,改名为MyBatis。是一个基于SQL映射支持Java和·NET的持久层框架。
基础服务层:
路由:对数据库进行切分,增加吞吐量。
zookeeper:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
router:
可被路由的协议(Routed Protocol)由路由协议(Routing
Protocol)传输,前者亦称为网络协议。
对数据库进行切分,增加吞吐量。对不同的表进行垂直切分到数据库,当数据库的表中的一个表超过一定大小时,进行水平切分。
Zookeeper:zookeeper在这里提供分布式应用协调服务。
数据收集:
flume:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
MQ:
rabbitMQ:
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过
队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ。
上图,在四层负责设备中,把client发送的报文目标地址(原来是负载均衡设备的IP地址),根据均衡设备设置选择的web服务器的规则选择对应的web服务器IP地址,这样client就可以直接跟此服务器建立TCP连接并发送数据。
Nginx (7层)
是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
是一款轻量级的web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。
Varnish :
是一款高性能的开源http加速器。
Web应用层:
tomcat:是一个免费的开放源代码的应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下普遍使用,是开发和调试JSP的首选。
jboss:是一个基于J2EE的开放源代码的应用服务器。JBoss代码遵循LGPL许可,可以在任何商业应用中免费使用,而不用支付费用,JBoss是一个管理EJB的容器和服务器,支持EJB1.1,EJB2.0和EJB3的规范。但JBoss核心服务不包括支持servlet/JSP的web容器,一般与tomcat或jetty邦定使用。
spring:Spring是一个开源框架。
struts2:Struts2是一个基于MVC设计模式的Web应用框架,它本质上相当于一个servlet,在MVC设计模式中,Struts2作为控制器(Controller)来建立模型与视图的数据交互。
业务层:
mina:Apache Mina是一个能够帮助用户开发高性能和高伸缩性网络应用程序的框架。它通过Java
nio技术基于TCP/IP和UDP/IP协议提供了抽象的、事件驱动的、异步的API。用于内部服务间调用。单线程。
spring:Spring是一个开源框架。
ibatis:iBATIS一词来源于“internet”和“abatis”的组合,是一个由Clinton
Begin在2002年发起的开放源代码项目。于2010年6月16号被谷歌托管,改名为MyBatis。是一个基于SQL映射支持Java和·NET的持久层框架。
基础服务层:
路由:对数据库进行切分,增加吞吐量。
zookeeper:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
router:
可被路由的协议(Routed Protocol)由路由协议(Routing
Protocol)传输,前者亦称为网络协议。
对数据库进行切分,增加吞吐量。对不同的表进行垂直切分到数据库,当数据库的表中的一个表超过一定大小时,进行水平切分。
Zookeeper:zookeeper在这里提供分布式应用协调服务。
数据收集:
flume:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
MQ:
rabbitMQ:
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过
队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ。
Cache: memCache: memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著。
搜索: solr:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。基于lucene进行全文搜索。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML/json格式的返回结果。 lucene:Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。 计算:MR:MR模型是无共享的架构,数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map),将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至reduce节点),避免了大量数据的传输,提高了处理效率。 Storm: 数据存储: mogileFs:MogileFS是一套高效的文件自动备份组件。 oracle:关系型数据库。 mysql:关系型数据库。 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。由于其社区版的性能卓越,搭配 PHP 和 Apache 可组成良好的开发环境。 hadoop:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 hbase:HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。 mongodb: mongodb:是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。是一个介于关系数据库和非关系数据库之间的产品。 redis: Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
是一个独立的企业级应用服务器,对外提供web-service的API接口,用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件生成索引,也可以通过http Get操作查找请求,并得到XML/json类型的返回结果。 redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
CDN:
Content Delivery Network 内容分发网络
其目的是避开影响数据传输速度和稳定的瓶颈和环节,使内容访问更快,更稳定。
通过在网络各处设置节点服务器,构成在现有互联网基础上的一层智能虚拟网络,实时的根据数据流量和各节点连接,负载状况,用户的访问距离,响应时间将用户的请求重新定向到最近的服务节点上,使用户可以就近取得数据,解决了网络拥挤情况,提高用户访问网络的响应速度。
负载均衡/反向代理 负载均衡:建立在现有网络结构之上,提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽,增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。 英文Load Balance ,其意思就是分摊到多个操作单元上进行执行,如web服务器,FTP服务器,企业关键应用服务器和其他关键任务服务器等,从而共同完成工作任务。
反向代理: 指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。 F5(4层) 四层负责均衡:是通过报文中的目标地址和接口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器与请求客户建立TCP连接,然后发送Client请求的数据。
上图,在四层负责设备中,把client发送的报文目标地址(原来是负载均衡设备的IP地址),根据均衡设备设置选择的web服务器的规则选择对应的web服务器IP地址,这样client就可以直接跟此服务器建立TCP连接并发送数据。
Nginx (7层)
是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。
是一款轻量级的web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。
Varnish :
是一款高性能的开源http加速器。
Web应用层:
tomcat:是一个免费的开放源代码的应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下普遍使用,是开发和调试JSP的首选。
jboss:是一个基于J2EE的开放源代码的应用服务器。JBoss代码遵循LGPL许可,可以在任何商业应用中免费使用,而不用支付费用,JBoss是一个管理EJB的容器和服务器,支持EJB1.1,EJB2.0和EJB3的规范。但JBoss核心服务不包括支持servlet/JSP的web容器,一般与tomcat或jetty邦定使用。
spring:Spring是一个开源框架。
struts2:Struts2是一个基于MVC设计模式的Web应用框架,它本质上相当于一个servlet,在MVC设计模式中,Struts2作为控制器(Controller)来建立模型与视图的数据交互。
业务层:
mina:Apache Mina是一个能够帮助用户开发高性能和高伸缩性网络应用程序的框架。它通过Java
nio技术基于TCP/IP和UDP/IP协议提供了抽象的、事件驱动的、异步的API。用于内部服务间调用。单线程。
spring:Spring是一个开源框架。
ibatis:iBATIS一词来源于“internet”和“abatis”的组合,是一个由Clinton
Begin在2002年发起的开放源代码项目。于2010年6月16号被谷歌托管,改名为MyBatis。是一个基于SQL映射支持Java和·NET的持久层框架。
基础服务层:
路由:对数据库进行切分,增加吞吐量。
zookeeper:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
router:
可被路由的协议(Routed Protocol)由路由协议(Routing
Protocol)传输,前者亦称为网络协议。
对数据库进行切分,增加吞吐量。对不同的表进行垂直切分到数据库,当数据库的表中的一个表超过一定大小时,进行水平切分。
Zookeeper:zookeeper在这里提供分布式应用协调服务。
数据收集:
flume:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
MQ:
rabbitMQ:
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过
队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ。Cache: memCache: memcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著。
搜索: solr:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。基于lucene进行全文搜索。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML/json格式的返回结果。 lucene:Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。 计算:MR:MR模型是无共享的架构,数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map),将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至reduce节点),避免了大量数据的传输,提高了处理效率。 Storm: 数据存储: mogileFs:MogileFS是一套高效的文件自动备份组件。 oracle:关系型数据库。 mysql:关系型数据库。 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。由于其社区版的性能卓越,搭配 PHP 和 Apache 可组成良好的开发环境。 hadoop:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 hbase:HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。 mongodb: mongodb:是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。是一个介于关系数据库和非关系数据库之间的产品。 redis: Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
是一个独立的企业级应用服务器,对外提供web-service的API接口,用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件生成索引,也可以通过http Get操作查找请求,并得到XML/json类型的返回结果。 redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。