{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 weixin_42079053 的文章《python爬虫(2)---虎扑电竞文章信息爬取》','https://www.xiaopingtou.net/article-58266.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
class="markdown_views prism-github-gist">
今天我们来爬取虎扑电竞英雄联盟区帖子的部分信息,提取文章的标题,作者,发布时间和文章链接信息,并将它们保存在csv文件中。
并发现其之后页面网址为:
但由于未登录原因,虎扑限定只能查看前十页的内容。但只要了解了方法,爬取十页和一百页也没什么不同。
我们进入https://bbs.hupu.com/lol使用开发者工具查看网页源码。我们的目标是提取文章标题,作者,发布时间和文章链接。开发者工具中我们选择Elements,然后鼠标左击左上角按钮,如图:
通过点击这个按钮后,鼠标在页面移动时,Elements中就可以迅速定位鼠标所在位置对应的页面代码。我们将鼠标分别移动到文章标题,作者和发布时间时,Elements中显示代码分别为:

在文章标题中还附带了文章的链接,点击进去后发现其完整链接为:
确定想要的信息位置后,我们就可以进行爬取了。
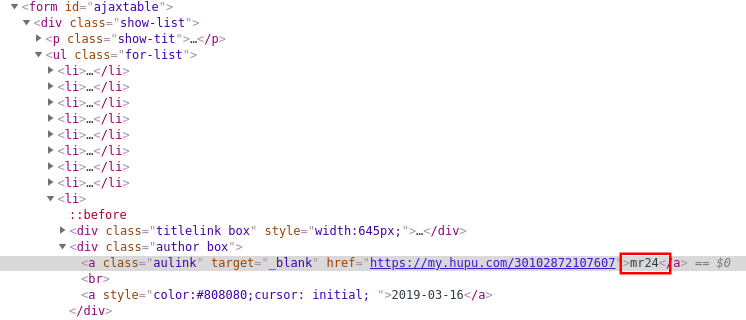
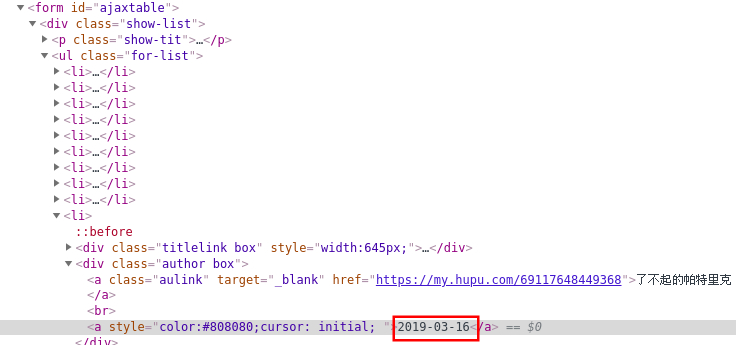
好像完美的成功了(顺序同网页显示的不同),但当我们再提取完作者等信息后,就会发现,标题竟然与作者信息等不匹配,标题数量少于其他信息的数量。这应该是有某些标题我们并没有爬取到,再次分析源码发现,虎扑对有些标题进行了特殊标记,它们存在与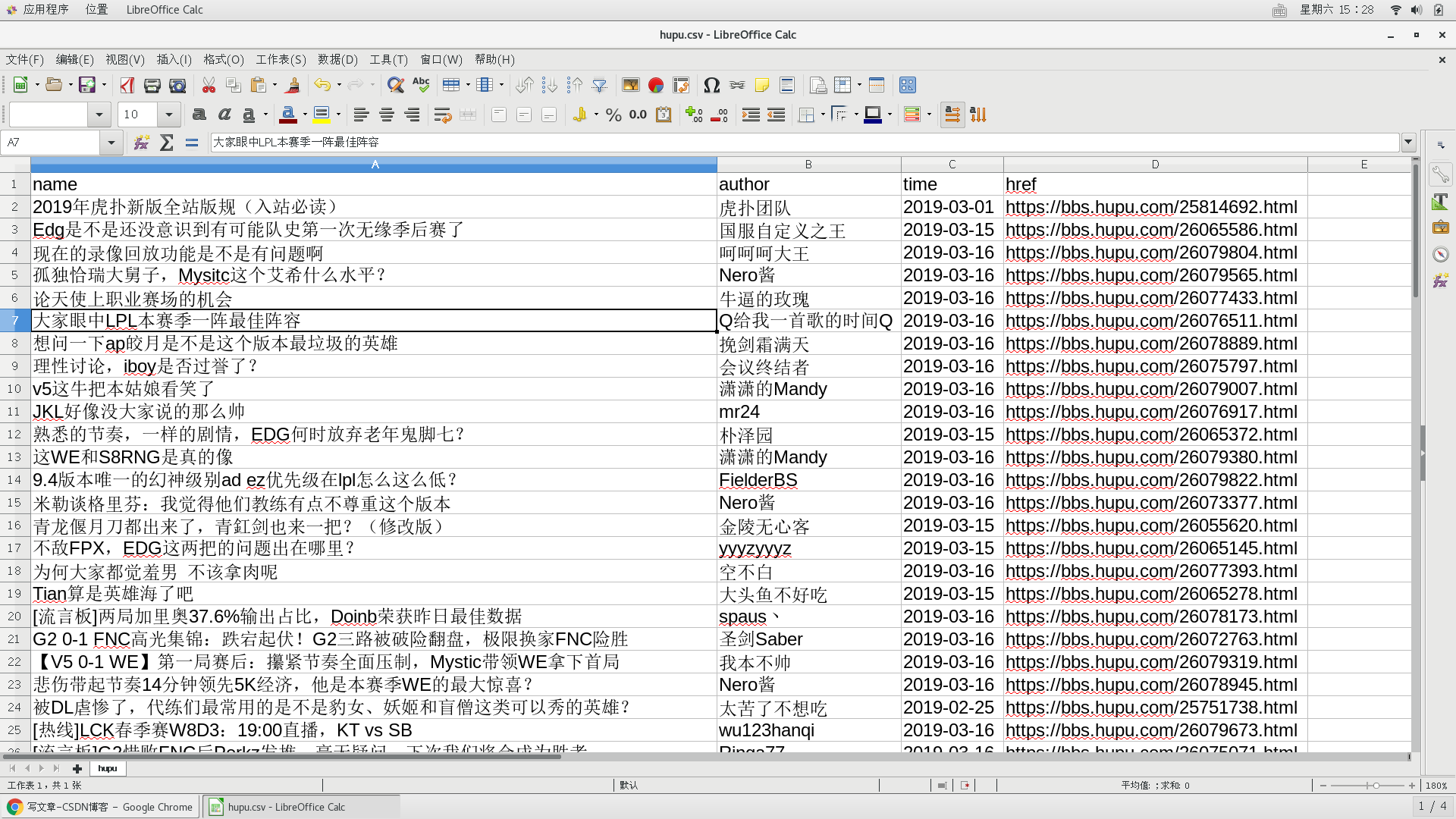
所以我们的xpath不能通过直接匹配text()来提取信息了,迂回一下:
本博客文章仅供博主学习交流,博主才疏学浅,语言表达能力有限,对知识的理解、编写代码能力都有很多不足,希望各路大神多多包涵,多加指点。
虎扑电竞文章信息爬取
今天我们来爬取虎扑电竞英雄联盟区帖子的部分信息,提取文章的标题,作者,发布时间和文章链接信息,并将它们保存在csv文件中。
1. 网页分析
虎扑电竞英雄联盟区主页网址为:https://bbs.hupu.com/lol并发现其之后页面网址为:
https://bbs.hupu.com/lol-2
https://bbs.hupu.com/lol-3
https://bbs.hupu.com/lol-4
即主页地址 + “-” + 页数但由于未登录原因,虎扑限定只能查看前十页的内容。但只要了解了方法,爬取十页和一百页也没什么不同。
我们进入https://bbs.hupu.com/lol使用开发者工具查看网页源码。我们的目标是提取文章标题,作者,发布时间和文章链接。开发者工具中我们选择Elements,然后鼠标左击左上角按钮,如图:
通过点击这个按钮后,鼠标在页面移动时,Elements中就可以迅速定位鼠标所在位置对应的页面代码。我们将鼠标分别移动到文章标题,作者和发布时间时,Elements中显示代码分别为:
在文章标题中还附带了文章的链接,点击进去后发现其完整链接为:
https://bbs.hupu.com/26070774.html
所以文章链接为https://bbs.hupu.com + href确定想要的信息位置后,我们就可以进行爬取了。
2. 代码
1. 初始准备
import requests
from lxml import etree # 使用xpath提取信息
import csv # 将提取信息保存在csv文件中需导入csv库
2.排坑,文章标题提取
寻找到位置信息后,我们开始开心的爬取,先写提取标题的代码测试一下:headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
}
url = 'https://bbs.hupu.com/lol-1' # 与首页地址https://bbs.hupu.com/lol等同
res = requests.get(url, headers=headers)
root = etree.HTML(res.text)
name = root.xpath('//ul[@class="for-list"]/li//a[@class="truetit"]/text()')
for i in name:
print(i)
结果为好像完美的成功了(顺序同网页显示的不同),但当我们再提取完作者等信息后,就会发现,标题竟然与作者信息等不匹配,标题数量少于其他信息的数量。这应该是有某些标题我们并没有爬取到,再次分析源码发现,虎扑对有些标题进行了特殊标记,它们存在与
标签中,如图:所以我们的xpath不能通过直接匹配text()来提取信息了,迂回一下:
name = root.xpath('//ul[@class="for-list"]/li//a[@class="truetit"]')
for i in range(len(name)):
if name[i].text:
print(name[i].text)
else
print(name[i][0].text)
由于xpath返回的是一个列表,如果标题不在 标签中name[i].text有内容即标题,否则标题存在于name[i][0].text中,这样爬取的才是全部的标题。而其他信息正常爬取即可。
3. 完整代码
def hupu_spilder(url):
info = [] # 存放所有信息的列表
# 对爬虫进行简单的伪装
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
}
res = requests.get(url, headers=headers)
root = etree.HTML(res.text)
# 通过xpath提取所有需要的信息
name = root.xpath('//ul[@class="for-list"]/li//a[@class="truetit"]')
href = root.xpath('//ul[@class="for-list"]/li//a[@class="truetit"]/@href')
author = root.xpath('//ul[@class="for-list"]/li//a[@class="aulink"]/text()')
time = root.xpath('//ul[@class="for-list"]/li//a[@style="color:#808080;cursor: initial; "]/text()')
# 判断标题存在于哪里,并将信息列表加入到info中
for i in range(len(name)):
if name[i].text:
info.append([name[i].text, author[i], time[i], 'https://bbs.hupu.com' + href[i]])
else:
info.append([name[i][0].text, author[i], time[i], 'https://bbs.hupu.com' + href[i]])
return info
if __name__ == '__main__':
fieldnames = ['name', 'author', 'time', 'href'] # 信息名称
f = open('hupu.csv', 'a+', encoding='utf-8') # 通过追加模式打开文件
f_csv = csv.writer(f)
f_csv.writerow(fieldnames) # 将各个信息的名称写入
for i in range(1, 11): # 爬取前十页
url = 'https://bbs.hupu.com/lol-{}'.format(i) # 拼接url
info = hupu_spilder(url)
f_csv.writerows(info) # 将一页的所有信息写入
f.close()
print("爬取完成!")
由此就将爬取的信息写入到csv文件中了
本博客文章仅供博主学习交流,博主才疏学浅,语言表达能力有限,对知识的理解、编写代码能力都有很多不足,希望各路大神多多包涵,多加指点。