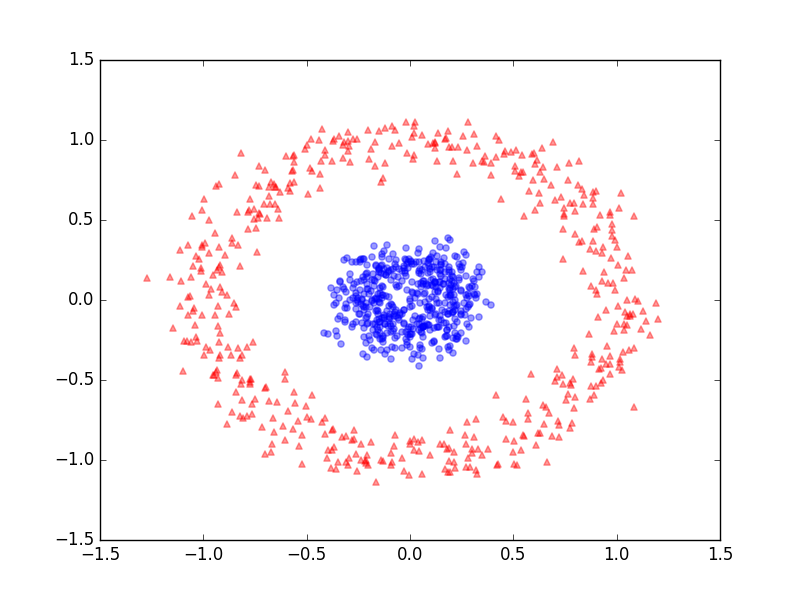
make_blobs
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=300, centers=4,
random_state=0, cluster_std=1.0)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='rainbow');
3. UCI 数据
Breast Cancer Wisconsin dataset
which contains 569 samples of malignant(恶性的) and benign(良性的) tumor cells.
The first two columns in the dataset store the unique ID numbers of the samples and the corresponding diagnoisi (M=malignant, B=benign), respectively.
The columns 3-32 contains 30 real-value features that have been computed from digitized images of the cell nuclei, which can be used to build a model to predict whether a tumor is benign or malignant.
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/''breast-cancer-wisconsin/wdbc.data', header=None)
X, y = df.values[:, 2:], df.values[:, 1]
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 chuanzi1990 的文章《example datasets in sklearn》','https://www.xiaopingtou.net/article-58909.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}