{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 wangtao 的文章《基于卷积神经网络的P300脑机接口信号检测》','https://www.xiaopingtou.net/article-59078.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
参考文献《Convolutional Neural Networks for P300 Detection with Application to Brain-Computer Interface》;
论文下载地址:https://ieeexplore.ieee.org/document/5492691/
本文主旨:通过CNN网络检测P300信号是否存在。贯穿全文的有两类CNN模型;
1.分析数据集的电极设定位置,并选取最佳的点作为特征提取的数据。
2. P300信号是否存在的检测性能。
P300波形是一种神经诱发电位成分的脑电图(EEG)。p300信号可用作认知障碍病人的检测。
其波形示意图:
 p300具体参数及用途可参考维基百科: https://en.wikipedia.org/wiki/P300_(neuroscience)
P300在本文中的介绍如下:
P300波是事件相关电位(ERP),可通过EEG记录。该波对应于EEG中在约300ms的等待时间的正电压偏转。换句话说,这意味着在诸如闪光之类的事件之后,信号的偏转应该在300ms之后发生。通常通过覆盖顶叶的电极测量信号最强烈。但是,Krusienski等人。表明枕部位更重要[23]。此外,该信号的存在,幅度,地形和时间通常用作决策过程中认知功能的度量。如果在特定位置的闪光灯后300毫秒检测到P300波,则表示用户正在关注同一位置。 P300波的检测相当于检测用户在检测之前300毫秒的位置。在P300拼写器中,主要目标是准确,即时地检测脑电图中的P300峰。这种检测的准确性将确保用户和机器之间的高信息传输速率。 Farwell和Donchin于1988年推出了第一款P300-BCI。
脑机接口(BCI)是最直接的人机交互方式,其直接通过人脑或者动物大脑与外部电子设备直接连接,获取大脑的电位信息,无需传统方式:键入信息或者其他图像信息。
1. 1 数据集
首先对采集的波形信号采样,本文使用120Hz的采样频率,且通过0.1Hz至20Hz的带通滤波器,滤出最为相关的信号,每个样本采样时长为650ms,及每个样本的采样点数为120个/s *0.65s =78个。
如下图所示,整个大圆可看作一个头盖骨(前面突出来的可看作鼻子~ ~),上面类似星座地分布着64个采集器(电极),每个采集器都在同一时刻采集波形。
p300具体参数及用途可参考维基百科: https://en.wikipedia.org/wiki/P300_(neuroscience)
P300在本文中的介绍如下:
P300波是事件相关电位(ERP),可通过EEG记录。该波对应于EEG中在约300ms的等待时间的正电压偏转。换句话说,这意味着在诸如闪光之类的事件之后,信号的偏转应该在300ms之后发生。通常通过覆盖顶叶的电极测量信号最强烈。但是,Krusienski等人。表明枕部位更重要[23]。此外,该信号的存在,幅度,地形和时间通常用作决策过程中认知功能的度量。如果在特定位置的闪光灯后300毫秒检测到P300波,则表示用户正在关注同一位置。 P300波的检测相当于检测用户在检测之前300毫秒的位置。在P300拼写器中,主要目标是准确,即时地检测脑电图中的P300峰。这种检测的准确性将确保用户和机器之间的高信息传输速率。 Farwell和Donchin于1988年推出了第一款P300-BCI。
脑机接口(BCI)是最直接的人机交互方式,其直接通过人脑或者动物大脑与外部电子设备直接连接,获取大脑的电位信息,无需传统方式:键入信息或者其他图像信息。
1. 1 数据集
首先对采集的波形信号采样,本文使用120Hz的采样频率,且通过0.1Hz至20Hz的带通滤波器,滤出最为相关的信号,每个样本采样时长为650ms,及每个样本的采样点数为120个/s *0.65s =78个。
如下图所示,整个大圆可看作一个头盖骨(前面突出来的可看作鼻子~ ~),上面类似星座地分布着64个采集器(电极),每个采集器都在同一时刻采集波形。
 所以,最后输入CNN的数据尺寸是64×78。
数据集的尺寸为:
所以,最后输入CNN的数据尺寸是64×78。
数据集的尺寸为:
 1.2. 神经网络拓扑结构
1.2. 神经网络拓扑结构
 拓扑结构如上图所示,总共由四层组成(不包含输入层);
第一层(L1):是各电极(64个采集器)的一个结合。由Ns个通道组成,每个通道有的78个神经元。(空间特征的卷积层)
第二层(L2):在时域的一个变换及下采样过程。由5Ns个通道组成,每个通道有6个神经元。(时域特征的卷积层)
第三层(L3):由一个通道组成,其神经元个数为100,此层为全连接层,将前层个通道提取的特征连接关联起来,综合分析。
第四层(L4): 输出层。一个通道,两个神经元,两个bit可表征P300信号存在与否。
由图上可知,此模型采用的卷积核是一维矢量形式,而非矩阵形式。这是本文区别于常规CNN用法的较为重大改变。而使用一维矢量卷积核的原因是,不混合空间和时域的信息。
1.3 学习过程
此章节主要描述一下CNN网络学习过程中的一些超参数设定。
1.3.1 激活函数:
前两层隐藏层是tanh激活函数:其具体表达形式为:
拓扑结构如上图所示,总共由四层组成(不包含输入层);
第一层(L1):是各电极(64个采集器)的一个结合。由Ns个通道组成,每个通道有的78个神经元。(空间特征的卷积层)
第二层(L2):在时域的一个变换及下采样过程。由5Ns个通道组成,每个通道有6个神经元。(时域特征的卷积层)
第三层(L3):由一个通道组成,其神经元个数为100,此层为全连接层,将前层个通道提取的特征连接关联起来,综合分析。
第四层(L4): 输出层。一个通道,两个神经元,两个bit可表征P300信号存在与否。
由图上可知,此模型采用的卷积核是一维矢量形式,而非矩阵形式。这是本文区别于常规CNN用法的较为重大改变。而使用一维矢量卷积核的原因是,不混合空间和时域的信息。
1.3 学习过程
此章节主要描述一下CNN网络学习过程中的一些超参数设定。
1.3.1 激活函数:
前两层隐藏层是tanh激活函数:其具体表达形式为:
 最后两层采用sigmoid激活函数:及具体表现形式为:
最后两层采用sigmoid激活函数:及具体表现形式为:
 1.3.2 网络各层σ的设计
L1层:主要提取空间特征;
两个作用:1)结合空间输入信息
2)空间滤波器
1.3.2 网络各层σ的设计
L1层:主要提取空间特征;
两个作用:1)结合空间输入信息
2)空间滤波器
 上式中,m是一个固定值,第一项w(1,m,0)可看作偏置项b;
L2:主要提取时域特征;
三个作用:1) 结合时域信息
2)下采样
3)时域滤波器
上式中,m是一个固定值,第一项w(1,m,0)可看作偏置项b;
L2:主要提取时域特征;
三个作用:1) 结合时域信息
2)下采样
3)时域滤波器
 L3: 全连接层;
作用:1)连接共享所有前层的特征
L3: 全连接层;
作用:1)连接共享所有前层的特征
 L4:分类输出;
L4:分类输出;
 1.3.3 初始化:
输入的权重和阈值的初始化都在
1.3.3 初始化:
输入的权重和阈值的初始化都在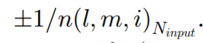 之间;
之间;
 定义为
定义为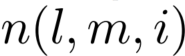 的输入数目。
1.3.4 学习速率:
前两层学习速率定于:
的输入数目。
1.3.4 学习速率:
前两层学习速率定于:
 其中分子中的λ为常数,
其中分子中的λ为常数, 是共享同一组权值的神经元数目。
后面两层网络学习率设计:
是共享同一组权值的神经元数目。
后面两层网络学习率设计:
 1.3.5 网络输出
最后的输出层有两个神经元,可表达P300信号是否存在。
用
1.3.5 网络输出
最后的输出层有两个神经元,可表达P300信号是否存在。
用 和
和 来表示两个神经元的输出。
最终网络输出可描述成:
来表示两个神经元的输出。
最终网络输出可描述成:
 X为输入数据样本,E为分类器(整个网络模型前向方程的抽象)。
2.1 分类器
当然,做paper实验部分是较为关键的,这个时候就是各种性能优劣的对比及取舍了,本文比较了七种不同内核的CNN分类器;
1. CNN-1: 这个模型的参数就是上述第一章节讲的全部了,用来和其他做对比的。
2. CNN-2a: 为了适应现实场景,这个模型将64个电极改为8个。其他和CNN-1超参数一致。
3. CNN-2b:和CNN-2a一样八个电极,但这八个电极是根据CNN-1的权重分析中,选出的最大关联的八个电极。
4.CNN-3:将第一层隐藏层的通道数设置为1;也就是说,后面所有的提取,都只和前面这一个空间滤波器有关,主要作用是测试多通道的好处及性能。
下面三种主要是针对不同的数据集设计而测试的分类器,其模型和CNN-1一致;
5.MCNN-1:从前面数据集数量的表格中,我们知道,P300和非P300信号并不是相同比例存在的,非P300信号是P300信号的五倍之多,这个模型的网络所以组建了五个分类器,及将非P300信号平均分成5份,这样每一份非p300信号的样本数就接近于P300信号的样本数,然后将这五份非P300信号和P300信号分别送入五个分类器训练。
6.MCNN-2: 考虑到数据集的信号质量是不断变化的,一个分类器也不能完美建模,采用了五个分类器。考虑到特定的数据集可靠性的问题,将EEG信号切成连续的五份,每个分类器训练一份。
7.MCNN-3: 三个分类器组成;权重随机初始化,其他和CNN-1一致。主要作用是提高CNN-1的可靠性;我们会发现,随机初始化权值,最终训练的分类器和CNN-1一样。
2.2 CNN-2b的特征选择
前面说到了CNN-2b的电极是选取最重要的,也就是对分类结果准确率贡献最大的那八个电极。然而怎么选呢?
这就要开始本章节的算法了。
首先,天灵盖上的电极的选择,是建立在CNN-1第一层隐藏层的权重分析上的。因为第一层隐藏层的主要作用就是结合并提取电极的空间特征;众所周知,当连接该电极的权值接近0时;可以认为该极点对判别能力较低。相反,权值较大,则可认为该极点贡献较大。所以对电极i能量的定义为:
X为输入数据样本,E为分类器(整个网络模型前向方程的抽象)。
2.1 分类器
当然,做paper实验部分是较为关键的,这个时候就是各种性能优劣的对比及取舍了,本文比较了七种不同内核的CNN分类器;
1. CNN-1: 这个模型的参数就是上述第一章节讲的全部了,用来和其他做对比的。
2. CNN-2a: 为了适应现实场景,这个模型将64个电极改为8个。其他和CNN-1超参数一致。
3. CNN-2b:和CNN-2a一样八个电极,但这八个电极是根据CNN-1的权重分析中,选出的最大关联的八个电极。
4.CNN-3:将第一层隐藏层的通道数设置为1;也就是说,后面所有的提取,都只和前面这一个空间滤波器有关,主要作用是测试多通道的好处及性能。
下面三种主要是针对不同的数据集设计而测试的分类器,其模型和CNN-1一致;
5.MCNN-1:从前面数据集数量的表格中,我们知道,P300和非P300信号并不是相同比例存在的,非P300信号是P300信号的五倍之多,这个模型的网络所以组建了五个分类器,及将非P300信号平均分成5份,这样每一份非p300信号的样本数就接近于P300信号的样本数,然后将这五份非P300信号和P300信号分别送入五个分类器训练。
6.MCNN-2: 考虑到数据集的信号质量是不断变化的,一个分类器也不能完美建模,采用了五个分类器。考虑到特定的数据集可靠性的问题,将EEG信号切成连续的五份,每个分类器训练一份。
7.MCNN-3: 三个分类器组成;权重随机初始化,其他和CNN-1一致。主要作用是提高CNN-1的可靠性;我们会发现,随机初始化权值,最终训练的分类器和CNN-1一样。
2.2 CNN-2b的特征选择
前面说到了CNN-2b的电极是选取最重要的,也就是对分类结果准确率贡献最大的那八个电极。然而怎么选呢?
这就要开始本章节的算法了。
首先,天灵盖上的电极的选择,是建立在CNN-1第一层隐藏层的权重分析上的。因为第一层隐藏层的主要作用就是结合并提取电极的空间特征;众所周知,当连接该电极的权值接近0时;可以认为该极点对判别能力较低。相反,权值较大,则可认为该极点贡献较大。所以对电极i能量的定义为:
 其中i为电极位置,j为通道。
2.3 复杂度
前面两层隐藏层,一个通道内都是共享一组权值,以减少网络的权值数量;
整个网络权值的数量定义如下:
L1: 自由变量的数目是
其中i为电极位置,j为通道。
2.3 复杂度
前面两层隐藏层,一个通道内都是共享一组权值,以减少网络的权值数量;
整个网络权值的数量定义如下:
L1: 自由变量的数目是 比如CNN-1,2,3的参数分别是:650,90,65;
L2:自由变量的数量是:
比如CNN-1,2,3的参数分别是:650,90,65;
L2:自由变量的数量是: 比如CNN-1,2,3的参数分别是:700,700,70;
L3:自由变量的数量是
比如CNN-1,2,3的参数分别是:700,700,70;
L3:自由变量的数量是 ,
比如CNN-1,2,3的参数数量分别是30100,30100,3010;
L4;自由变量的数目是
,
比如CNN-1,2,3的参数数量分别是30100,30100,3010;
L4;自由变量的数目是 ,
比如CNN-1,2,3的参数数目都是202;
其中
,
比如CNN-1,2,3的参数数目都是202;
其中 因此,CNN-1,2,3分别包含的自由变量数:31652,31092,3347;
在Intel Core 2 Duo T7500 CPU上,CNN-1平均训练时间为10分钟。学习率对训练时间很关键,公式中,参数λ设定为0.2;
这个模型是由C++编写,并未由GPU或者其他多核硬件加速;
3. 结果分析
因此,CNN-1,2,3分别包含的自由变量数:31652,31092,3347;
在Intel Core 2 Duo T7500 CPU上,CNN-1平均训练时间为10分钟。学习率对训练时间很关键,公式中,参数λ设定为0.2;
这个模型是由C++编写,并未由GPU或者其他多核硬件加速;
3. 结果分析
p300具体参数及用途可参考维基百科: https://en.wikipedia.org/wiki/P300_(neuroscience)
P300在本文中的介绍如下:
P300波是事件相关电位(ERP),可通过EEG记录。该波对应于EEG中在约300ms的等待时间的正电压偏转。换句话说,这意味着在诸如闪光之类的事件之后,信号的偏转应该在300ms之后发生。通常通过覆盖顶叶的电极测量信号最强烈。但是,Krusienski等人。表明枕部位更重要[23]。此外,该信号的存在,幅度,地形和时间通常用作决策过程中认知功能的度量。如果在特定位置的闪光灯后300毫秒检测到P300波,则表示用户正在关注同一位置。 P300波的检测相当于检测用户在检测之前300毫秒的位置。在P300拼写器中,主要目标是准确,即时地检测脑电图中的P300峰。这种检测的准确性将确保用户和机器之间的高信息传输速率。 Farwell和Donchin于1988年推出了第一款P300-BCI。
脑机接口(BCI)是最直接的人机交互方式,其直接通过人脑或者动物大脑与外部电子设备直接连接,获取大脑的电位信息,无需传统方式:键入信息或者其他图像信息。
1. 1 数据集
首先对采集的波形信号采样,本文使用120Hz的采样频率,且通过0.1Hz至20Hz的带通滤波器,滤出最为相关的信号,每个样本采样时长为650ms,及每个样本的采样点数为120个/s *0.65s =78个。
如下图所示,整个大圆可看作一个头盖骨(前面突出来的可看作鼻子~ ~),上面类似星座地分布着64个采集器(电极),每个采集器都在同一时刻采集波形。
所以,最后输入CNN的数据尺寸是64×78。
数据集的尺寸为:
1.2. 神经网络拓扑结构
拓扑结构如上图所示,总共由四层组成(不包含输入层);
第一层(L1):是各电极(64个采集器)的一个结合。由Ns个通道组成,每个通道有的78个神经元。(空间特征的卷积层)
第二层(L2):在时域的一个变换及下采样过程。由5Ns个通道组成,每个通道有6个神经元。(时域特征的卷积层)
第三层(L3):由一个通道组成,其神经元个数为100,此层为全连接层,将前层个通道提取的特征连接关联起来,综合分析。
第四层(L4): 输出层。一个通道,两个神经元,两个bit可表征P300信号存在与否。
由图上可知,此模型采用的卷积核是一维矢量形式,而非矩阵形式。这是本文区别于常规CNN用法的较为重大改变。而使用一维矢量卷积核的原因是,不混合空间和时域的信息。
1.3 学习过程
此章节主要描述一下CNN网络学习过程中的一些超参数设定。
1.3.1 激活函数:
前两层隐藏层是tanh激活函数:其具体表达形式为:
最后两层采用sigmoid激活函数:及具体表现形式为:
1.3.2 网络各层σ的设计
L1层:主要提取空间特征;
两个作用:1)结合空间输入信息
2)空间滤波器
上式中,m是一个固定值,第一项w(1,m,0)可看作偏置项b;
L2:主要提取时域特征;
三个作用:1) 结合时域信息
2)下采样
3)时域滤波器
L3: 全连接层;
作用:1)连接共享所有前层的特征
L4:分类输出;
1.3.3 初始化:
输入的权重和阈值的初始化都在定义为
其中分子中的λ为常数,
1.3.5 网络输出
最后的输出层有两个神经元,可表达P300信号是否存在。
用
X为输入数据样本,E为分类器(整个网络模型前向方程的抽象)。
2.1 分类器
当然,做paper实验部分是较为关键的,这个时候就是各种性能优劣的对比及取舍了,本文比较了七种不同内核的CNN分类器;
1. CNN-1: 这个模型的参数就是上述第一章节讲的全部了,用来和其他做对比的。
2. CNN-2a: 为了适应现实场景,这个模型将64个电极改为8个。其他和CNN-1超参数一致。
3. CNN-2b:和CNN-2a一样八个电极,但这八个电极是根据CNN-1的权重分析中,选出的最大关联的八个电极。
4.CNN-3:将第一层隐藏层的通道数设置为1;也就是说,后面所有的提取,都只和前面这一个空间滤波器有关,主要作用是测试多通道的好处及性能。
下面三种主要是针对不同的数据集设计而测试的分类器,其模型和CNN-1一致;
5.MCNN-1:从前面数据集数量的表格中,我们知道,P300和非P300信号并不是相同比例存在的,非P300信号是P300信号的五倍之多,这个模型的网络所以组建了五个分类器,及将非P300信号平均分成5份,这样每一份非p300信号的样本数就接近于P300信号的样本数,然后将这五份非P300信号和P300信号分别送入五个分类器训练。
6.MCNN-2: 考虑到数据集的信号质量是不断变化的,一个分类器也不能完美建模,采用了五个分类器。考虑到特定的数据集可靠性的问题,将EEG信号切成连续的五份,每个分类器训练一份。
7.MCNN-3: 三个分类器组成;权重随机初始化,其他和CNN-1一致。主要作用是提高CNN-1的可靠性;我们会发现,随机初始化权值,最终训练的分类器和CNN-1一样。
2.2 CNN-2b的特征选择
前面说到了CNN-2b的电极是选取最重要的,也就是对分类结果准确率贡献最大的那八个电极。然而怎么选呢?
这就要开始本章节的算法了。
首先,天灵盖上的电极的选择,是建立在CNN-1第一层隐藏层的权重分析上的。因为第一层隐藏层的主要作用就是结合并提取电极的空间特征;众所周知,当连接该电极的权值接近0时;可以认为该极点对判别能力较低。相反,权值较大,则可认为该极点贡献较大。所以对电极i能量的定义为:
其中i为电极位置,j为通道。
2.3 复杂度
前面两层隐藏层,一个通道内都是共享一组权值,以减少网络的权值数量;
整个网络权值的数量定义如下:
L1: 自由变量的数目是