{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 a372708078 的文章《kafka解决的问题》','https://www.xiaopingtou.net/article-61974.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
假设你意气风发,要开发新一代的互联网应用,以期在互联网事业中一展宏图。借助云计算,很容易开发出如下原型系统:
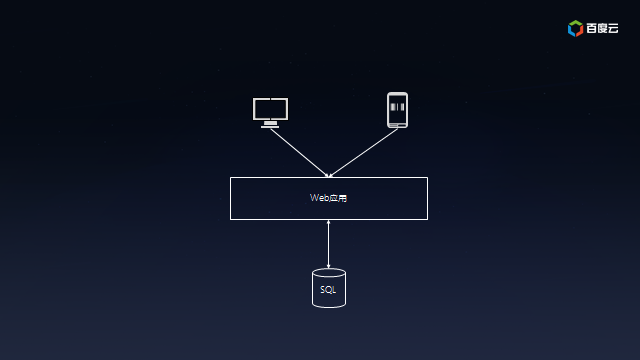 这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
<img src="https://pic3.zhimg.com/50/v2-54ce5889e9445f43cc8712443865fce2_hd.png" class="content_image">
这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
<img src="https://pic3.zhimg.com/50/v2-54ce5889e9445f43cc8712443865fce2_hd.png" class="content_image">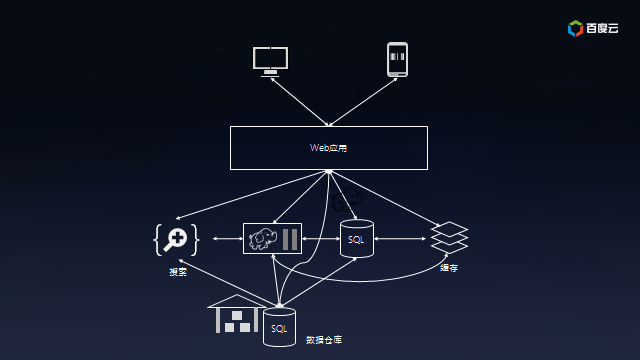 这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
<img src="https://pic1.zhimg.com/50/v2-7ddccdcd1e287b0c95a643a040a0afec_hd.png" class="content_image">
这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
<img src="https://pic1.zhimg.com/50/v2-7ddccdcd1e287b0c95a643a040a0afec_hd.png" class="content_image">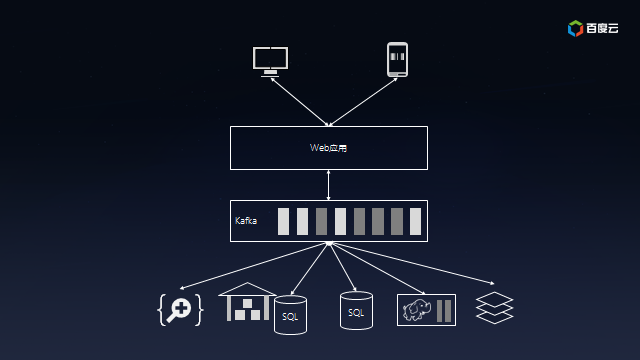 在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息中间件,只是粗略的讲解,目前kafka已经可以做更多的事情。 举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个"篮子"
老板有个好消息要告诉大家,有两个办法:
1.到每个座位上挨个儿告诉每个人。什么?张三去上厕所了?那张三就只能错过好消息了!
2.老板把消息写到黑板报上,谁想知道就来看一下,什么?张三请假了?没关系,我一周之后才擦掉,总会看见的!什么张三请假两周?那就算了,我反正只保留一周,不然其他好消息没地方写了
redis用第一种办法,kafka用第二种办法,知道什么区别了吧
转自:https://www.zhihu.com/question/53331259
- Web应用:部署在云服务器上,为个人电脑或者移动用户提供的访问体验。
- SQL数据库:为Web应用提供数据持久化以及数据查询。
这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
<img src="https://pic3.zhimg.com/50/v2-54ce5889e9445f43cc8712443865fce2_hd.png" class="content_image">这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
<img src="https://pic1.zhimg.com/50/v2-7ddccdcd1e287b0c95a643a040a0afec_hd.png" class="content_image">在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
以上故事说明了Kafka主要用途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是分布式的流数据平台,因为以下特性而著名:
- 提供Pub/Sub方式的海量消息处理。
- 以高容错的方式存储海量数据流。
- 保证数据流的顺序。
Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息中间件,只是粗略的讲解,目前kafka已经可以做更多的事情。 举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个"篮子"
老板有个好消息要告诉大家,有两个办法:
1.到每个座位上挨个儿告诉每个人。什么?张三去上厕所了?那张三就只能错过好消息了!
2.老板把消息写到黑板报上,谁想知道就来看一下,什么?张三请假了?没关系,我一周之后才擦掉,总会看见的!什么张三请假两周?那就算了,我反正只保留一周,不然其他好消息没地方写了
redis用第一种办法,kafka用第二种办法,知道什么区别了吧
转自:https://www.zhihu.com/question/53331259