{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 包租公 的文章《python3.5爬取网站图片》','https://www.xiaopingtou.net/article-63530.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:Users
ullDesktoppic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos + 1:])
return t
if __name__ == "__main__":
hostname = "http://category.dangdang.com/cid4003599.html"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
爬虫调度器:启动、停止、监视爬虫运行情况; URL管理器:将要爬取的URL和已经爬取的URL
网页下载器:URL管理器将将要爬取的URL传送给网页下载器下载下来;
网页解析器:将网页下载器下载的网页的内容传递给网页解析器解析;
(1)、解析出新的URL传递给URL管理器;
(2)、解析出有价值的数据;
上面三个形成了一个循环,只要网页解析器有找到新的URL,就一直执行下去; **URL管理器:存储待爬取和已抓取的url集合。
一个待爬取的url爬取之后,就会进入已爬取集合。
防止重复抓取和循环抓取**
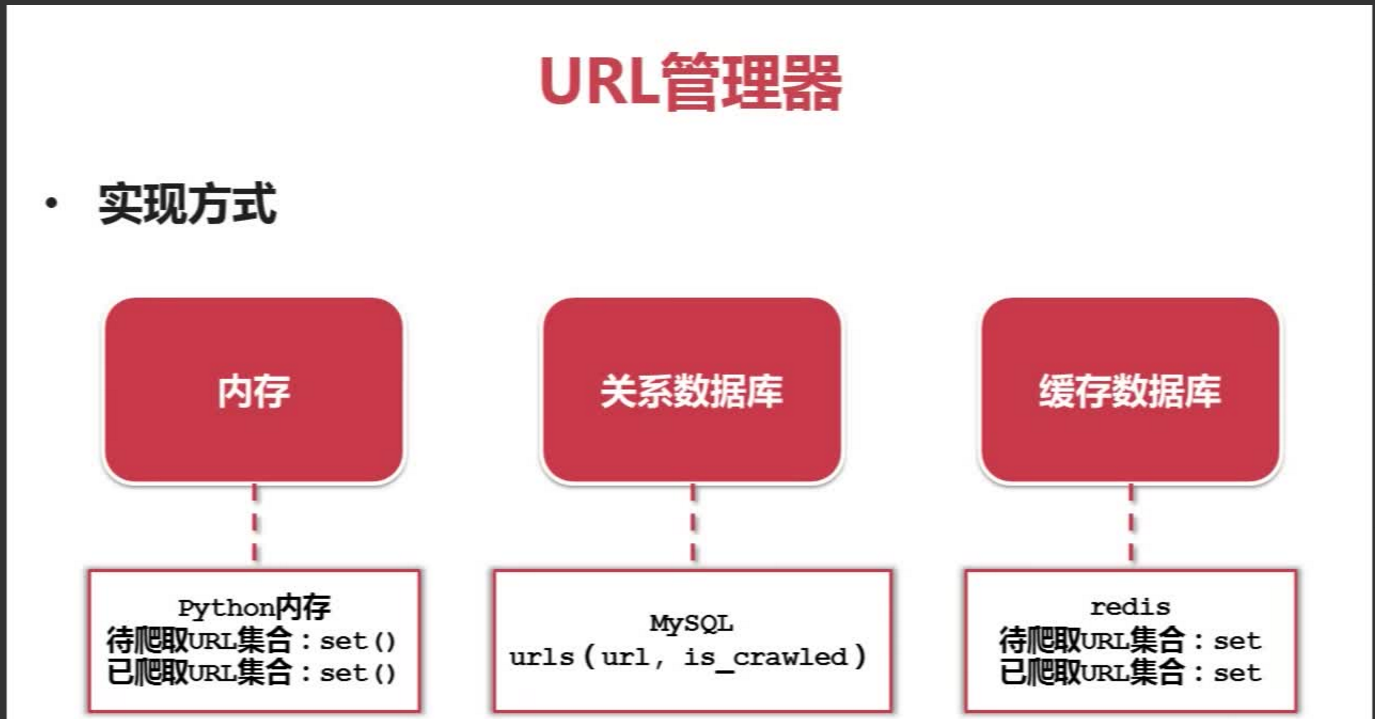
URL管理器的三种实现方式,Python适合小量数据,redis大公司常用,MySQL适合较复杂的存储。
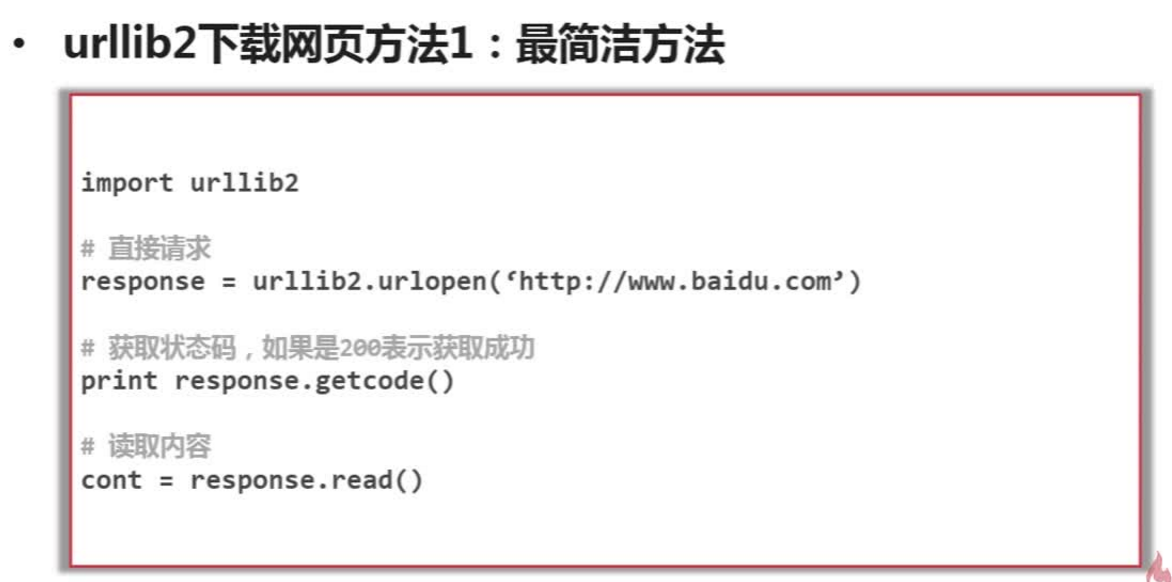
python2.*
import urllib2
url = "http://www.baidu.com/"
response1 = urllib2.urlopen(url)
print response1.getcode()
print len(response1.read())
python3.*
from urllib import request
import http.cookiejar
url = 'http://www.baidu.com'
print('第一种方法:')
response1 = request.urlopen(url)
print(response1.getcode())
print(len(response1.read()))
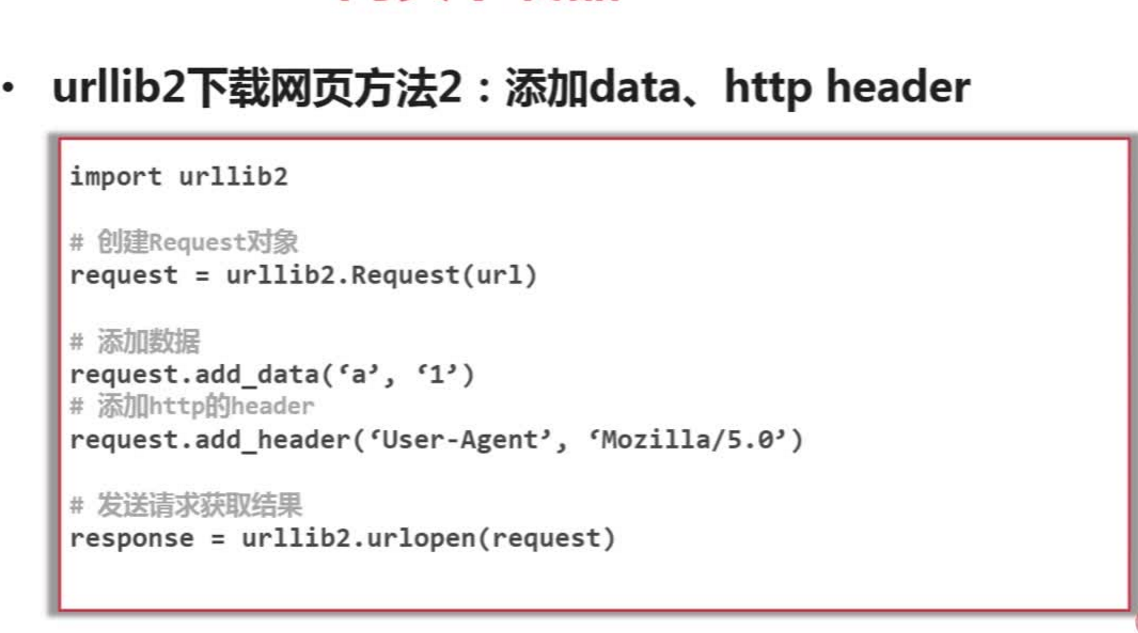
python2.*
import urllib2
url = "http://www.baidu.com/"
response1 = urllib2.urlopen(request)
request=urllib2.Request(url)
request.add_header("user-agent","Mozilla/5.0")
print response2.getcode()
print len(response2.read())
python3.*
print('第二种方法')
req = request.Request(url)
req.add_header('user-agent', 'Mozilla/5.0')
response2 = request.urlopen(req)
print(response2.getcode())
print(len(response2.read()))
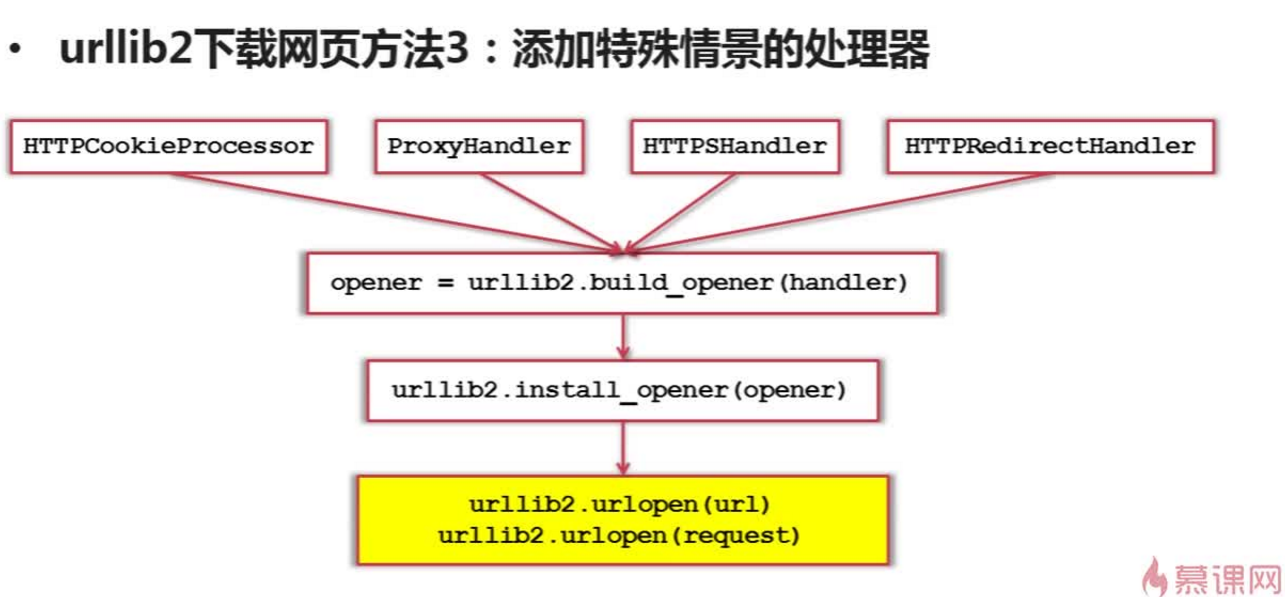
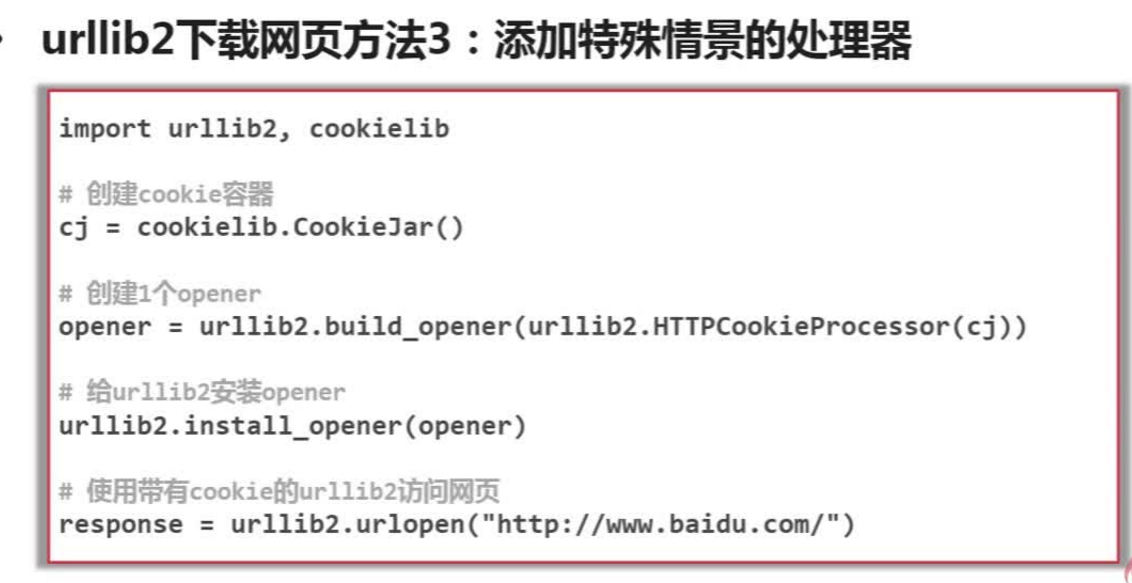
需要登录才可以访问的情形;需要代理才能访问的,htps加密访问的,url相互访问的。添加特殊场景的处理能力。
python2.*
print '第三种方法'
cj=cookielib.CookieJar()
opener =urllib2.bulid_opener(urllib.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3=urllib2.urlopen(url)
print response3.getcode()
print cj
print response3.read()
python3.*
print('第三种方法')
cj = http.cookiejar.CookieJar()
opener = request.build_opener(request.HTTPCookieProcessor(cj))
request.install_opener(opener)
response3 = request.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())
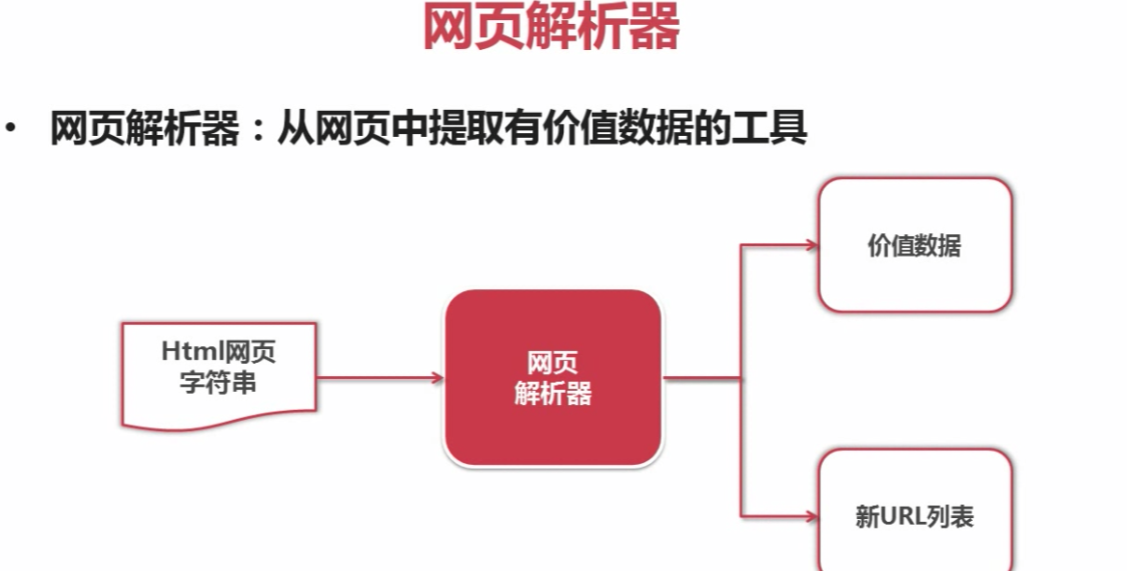
网页解析器
- 正则 : re,模糊匹配,下面三种为结构化解析
- html.parser,程序自带
- BeautifulSoup(可调用html.parser和lxml)
lxml : 需安装lxml第三方库,xpath
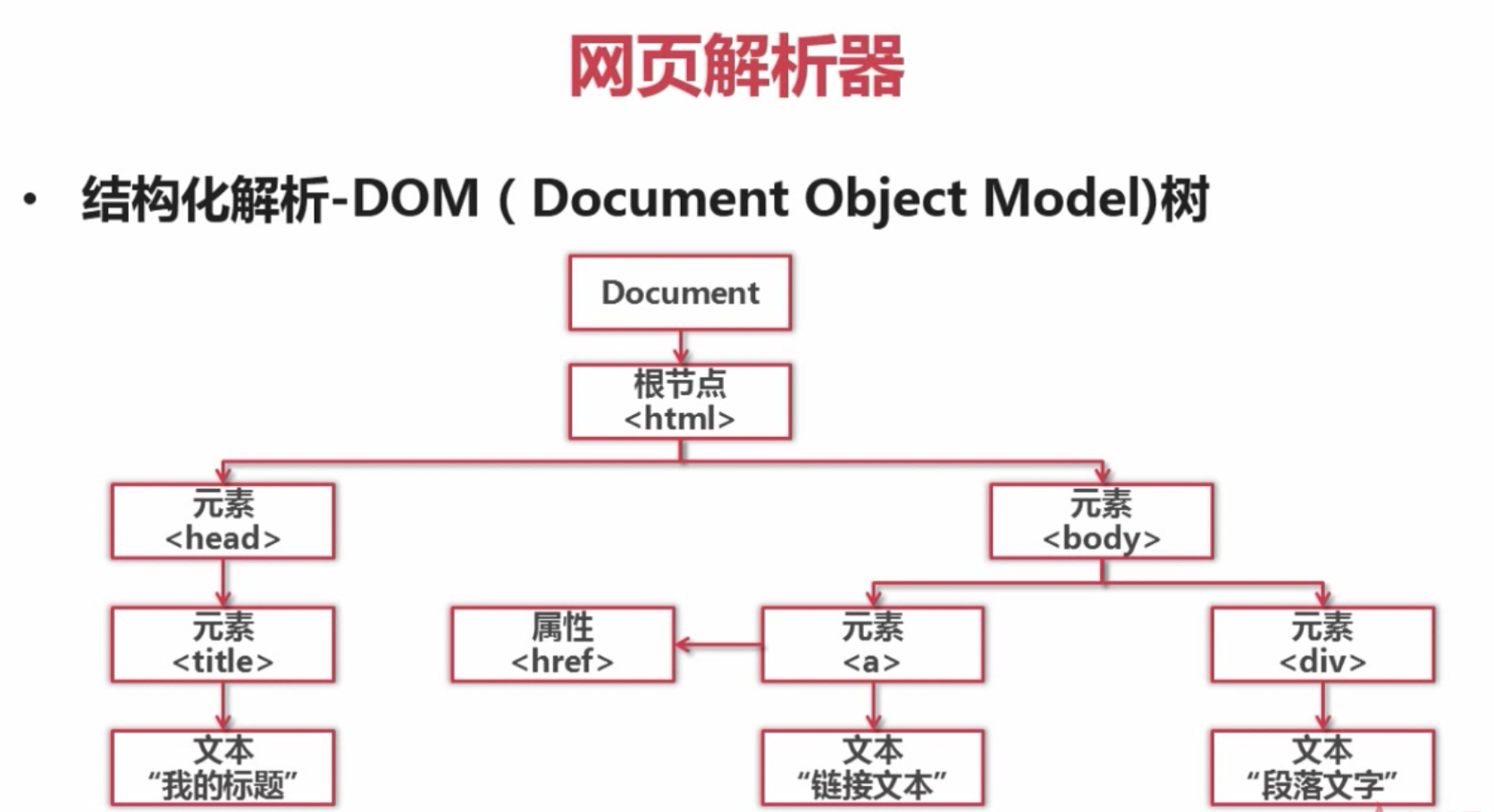
这里我们使用beautifulsoup来充当网页解析器

http://www.crummy.com/software/BeautifulSoup/
import bs4
print(bs4)
需要自行下载
C:Users ullAppDataLocalProgramsPythonPython35-32Scripts
可以自行下载插件,解压后拷贝到python安装目录中的lib目录下,打开cmd进入插件的目录,输入python setup.py install,即可安装。
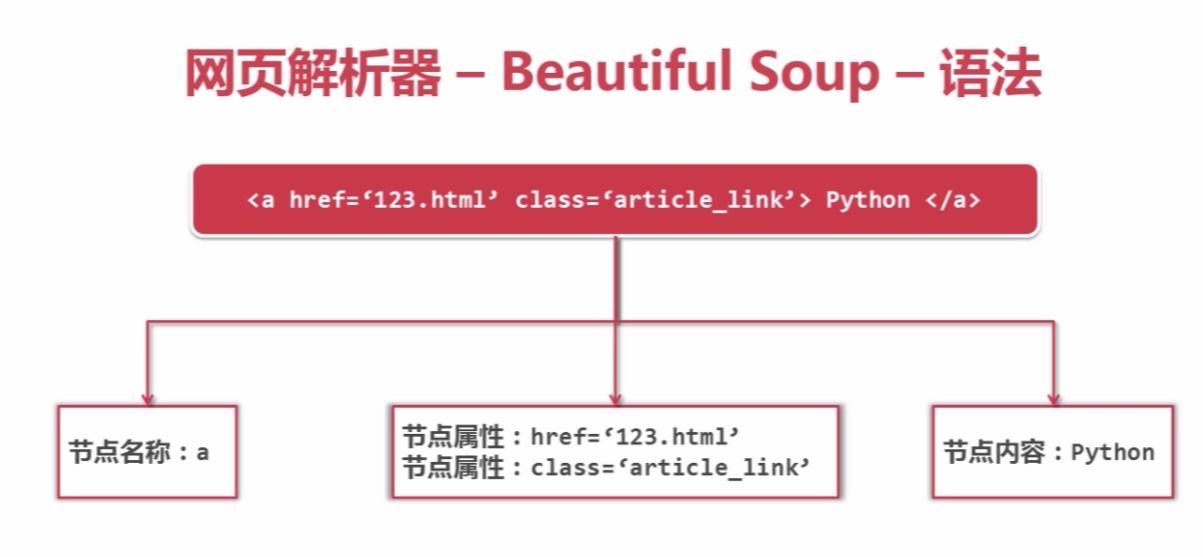

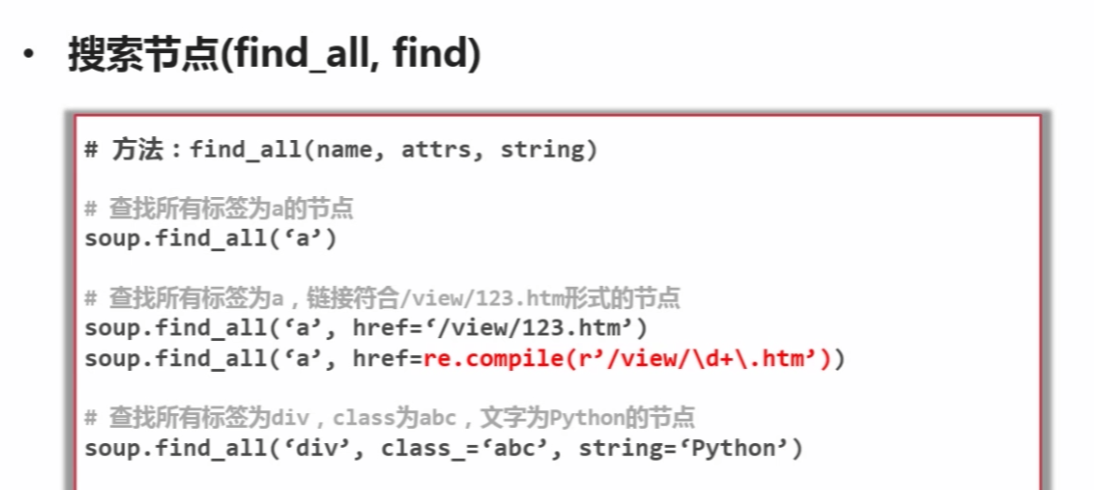

soup测试
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's storytitle>head>
<body>
<p class="title"><b>The Dormouse's storyb>p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsiea>,
<a href="http://example.com/lacie" class="sister" id="link2">Laciea> and
<a href="http://example.com/tillie" class="sister" id="link3">Tilliea>;
and they lived at the bottom of a well.p>
<p class="story">...p>
"""
soup = BeautifulSoup(html_doc,'html.parser')
print ('获取所有的连接')
links=soup.find_all('a')
print(links)
实例
