线性代数
核心问题
求多元方程组的解。
核心技能
已知矩阵 A 和矩阵 B,求 A 和 B 的
乘积 C=AB。矩阵 A 大小为 mxn,矩阵 B 大小为 nxp。
 常规方法:
常规方法:矩阵 C 中每一个元素 Cij = A 的第i行 乘以(点乘)B 的第 j 列。设有 n 维向量

令
![[x,y]=x_{1}y_{1}+x_{2}y_{2}+...+x_{n}y_{n}](data/attach/1907/6mi9krwvj0twiyluo7uhl20s83etjs6h.jpg)
,称
![[x,y]](data/attach/1907/08jgj1duq8ordhfnwbgmvheaz9vytzh7.jpg)
为向量 x 与 y 的
内积。在线代中秩的定义:一个矩阵 A 的列秩是 A 的线性无关的列的极大数目。类似地,行秩是 A 的线性无关的行的极大数目。矩阵的列秩和行秩总是相等的,因此它们可以简单地称作矩阵 A 的
秩,通常表示为 rank(A)。矩阵列空间、行空间的维度相等。任意一个矩阵都可以经过一些列的初等变换为阶梯形矩阵,而且阶梯形矩阵的秩等于其中非零行的个数。所以矩阵秩的计算方法:用初等变换把矩阵华为阶梯形,则该阶梯形矩阵中的非零行数就是所求矩阵的秩。
 高斯消元法
高斯消元法(Gaussian Elimination),是线性代数中的一个算法,可用来为线性方程组求解,求出矩阵的
秩,以及求出可逆方阵的
逆矩阵。当用于一个矩阵时,高斯消元法会产生出一个“行梯阵式”。值得提一下的是,虽然该方法以数学家卡尔·高斯命名,但最早出现于中国古籍《九章算术》,成书于约公元前150年。
复杂度:高斯消元法的算法复杂度是

;这就是说,如果系数矩阵的是 n × n,那么高斯消元法所需要的计算量大约与

成比例。
求矩阵的
逆矩阵的常用方法有两种:
- 伴随矩阵法
- 初等变换法
最小二乘法是对过度确定系统,即其中存在比未知数更多的方程组,以
回归分析求得近似解的标准方法。在这整个解决方案中,最小二乘法演算为每一方程式的结果中,将残差平方和的总和最小化。

回归分析模型
主要思想:选择未知参数,使得理论值与观测值之差的平方和达到最小:

最重要的应用是在
曲线拟合上。最小平方所涵义的最佳拟合,即
残差(残差为:观测值与模型提供的拟合值之间的差距)平方总和的最小化。
应用
- 最小二乘法
- 梯度下降法
假设有一个估计函数:

,其错误函数为:

这个错误估计函数是 x(i) 的估计值与真实值 y(i) 的差的平方和,前面乘上 1/2,是因为在求导的时候,这个系数就不见了。梯度下降法的流程:
1)首先对 θ 赋值,这个值可以是随机的,也可以让 θ 是一个全零的向量。
2)改变 θ 的值,使得 J(θ) 的值按梯度下降的方向减小。
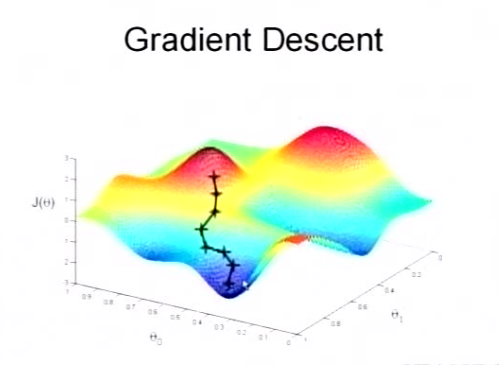
参数 θ 与误差函数 J(θ) 的关系图红 {MOD}部分表示 J(θ) 有着比较高的取值,我们希望能够让 J(θ) 的值尽可能的低,也就是取到深蓝 {MOD}的部分。θ0、θ1 表示 θ 向量的两个维度。上面提到梯度下降法的第一步,是给 θ 一个初值,假设随机的初值位于图上红 {MOD}部分的十字点。然后我们将 θ 按梯度下降的方向进行调整,就会使 J(θ) 往更低的方向进行变化,如图所示,算法的结束将在 θ 下降到无法继续下降为止。θ 的更新:

θi 表示更新前的值,减号后边的部分表示按梯度方向减少的量,α 表示步长,也就是每次按梯度减少的方向变化多少。梯度是有方向的,对于一个向量 θ,每一维分量 θi 都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化,就可以达到一个最小点,不管它是局部的还是全局的。
主成分分析(Principal components analysis,PCA)是一种分析、简化数据集的技术。常用于降低数据集的维数,同时保持数据集中对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。其方法主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征向量)与它们的权值(即特征值)。PCA 是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大?换而言之,PCA 提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(也即,这样降低维度必定是失去讯息最少的方法)。主成分分析在分析复杂数据时尤为有用,比如人脸识别。实例参考:
PCA 简单实例奇异值分解(Singular Value Decomposition, SVD)是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。PCA 的实现一般有两种,一种是通过特征值分解实现,另一种就是用奇异值分解来实现。但特征值分解只是针对方针而言的,当处理 m*n 的矩阵时,就需要特征值分解了。在吴军老师的《数学之美》中也有提到用 SVD 做文本分类的篇幅,提到的例子是这样的:首先用一个 M * N 的大型矩阵 A 来描述一百万篇文章和五十万个词的关联性。矩阵中,每一行对应一篇文章,每一列对应一个词。

在该矩阵中,M=1,000,000 ,N=500,000 ,第 i 行第 j 列的元素是字典中第 j 个词在第 i 篇文章中出现的加权词频(比如,TF/IDF) 。奇异值分解就是把这样一个大矩阵,分解成三个小矩阵相乘:
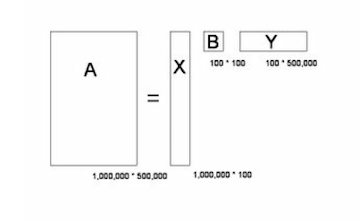
(矩形面积的大小也对应了信息量的大小~)这个大矩阵被分解成一个100万乘100的矩阵 X ,一个100乘100的矩阵 B ,以及一个100乘50万的矩阵 Y 。分解后,相应的存储量和计算量都小了三个数量级以上。
第一个矩阵 X 中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的相关性,数值越大越相关。最后一个矩阵 Y 中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵 A 进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
在实际应用过程中,可以直接调用
numpy.linalg.svd实例参考:
机器学习中 SVD 的应用
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 hpy518 的文章《机器学习算法数学基础之 —— 线性代数篇(2)》','https://www.xiaopingtou.net/article-64274.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}