作者: Zhibin Niu (Intel) (5 篇文章) 日期: 九月 15, 2011 在 10:00 上午
计算机视觉领域主要研究内容包括:图像分割,目标检测,目标跟踪,图像识别。
1. 图像分割在医学图像处理,目标跟踪和图像识别方面有重要应用,经常是图像理解的第一步,在时间的压缩上有着巨大需求。
2. 目标检测和目标跟踪在智能监控,车辆/导弹导航等方面有诸多应用,相关内容对实时性有着严格的界定和需求。
3. 图像识别是计算机视觉方向当前最火的研究内容之一,由于经典的基于统计学习的框架需要处理海量数据,需要大规模的并行计算,离线训练的时间往往让一般企业难以承受。但是图像识别技术有着重要意义(参见下图),近些年涌现出大批相关应用和产品,比如各大搜索引擎公司都积极开发了基于内容的图像检索和识别的产品,而对于一般方案的海量数据训练时间,如果能够有效地利用分布式计算,算法优化,以及更好的提升X86架构CPU和GPU的联合运算都将是非常有价值的工作。
 接下来主要从图像识别开始,简述笔者对于计算机视觉领域的优化的任务的总结和思考:
接下来主要从图像识别开始,简述笔者对于计算机视觉领域的优化的任务的总结和思考:
1. 识别正确率与图像数据和所建立的图像类别模型有关,前者即与所提取的image representation的判别性有关,进一步,与所提取的local description和encoding完的描述子的判别性有关;后者与所采用的数学模型有关,至于具体采用什么模型,与前者encoding完的数据在高维空间中的相对位置关系有关(Data Drive)。
2. 图像理解是一个大规模的数据并行计算过程,用到了大量的矩阵运算。可以优化的地方:
1) local feature descriptor的获取,这方面效果最好的是SIFT描述子,是十年来效果最好的,但是效率低,提取一副720*576的图像的特征,可能需要几秒钟,当然提取的时间与图像梯度的复杂度正相关。09年,CVPR best demo 在这方面做了很漂亮的工作,他们将提取一个点的时间减少到2.5毫秒。参看demo(http://mi.eng.cam.ac.uk/~sjt59/hips.html)同时,该实验室也制作了iPhone 应用oMoby,识别效果我认为比Google goggles 效果还要好。提升特征描述的时间,是图像理解的第一步,对于将图像信息转化为计算机可识别信息至关重要。
2) Local descriptorre-encoding 由于局部特征描述繁杂无序,难以通过训练得到有意义的模型。通过将其量化(建立码书模型)得到统一的,可分的多维空间中的点,以便于通过训练可以将这些模型区分开。
3) 对于数学模型计算的优化。基本上所有的判别式模型都可以归结为是凸优化问题如支持向量机SVM,面临大量的数值计算。模型计算过程一般是离线过程。
这里有一个很好的讲座:http://www.youtube.com/watch?v=g1tLjptuTBo(Kaiyu是NEC美国研究院的研究员,在09年的VOC中拿了classification组第一名。)
重申一下,这里所介绍的最经典的基于统计学习的识别框架,近些年有一些科学家试图跳出这个套路,提出了deep learning等算法,可以参看文末给出的demo。
3. 图像理解相关领域进行优化的价值:
1) 图像识别技术在03年以后有了突飞猛进的进展。Google 有相关产品,goggles,similar image search(两者均是基于图像内容的检索和识别),微软亚洲研究院中,图像识别是其非常重要的研究领域(如sun,jian所作的工作), 其他的有:百度淘宝都有以图识图的产品。
2) 这些图像产品都面临着计算效率的问题,即:图像特征提取慢,数学模型离线训练慢。这方面的优化具有非常有价值的意义。
3) 优化过程是否可以考虑:强化OpenCV和IPP(这两者我估计在实际产品中用到的很多),CPU+GPU的联合优化(由于是大规模的矩阵运算,有效地利用GPU是可行之路,即:OpenCL),针对特定算法有效利用IA架构CPU优势,分布式计算等。
4) 扩展:随着图像识别技术的发展,基于相关技术的视频序列识别近些年也得到了更多的应用和发展,比如行为识别等。由此而引发的,传统监控系统向智能监控系统的转变这两年也逐渐兴起,具体内容请看下面。
所谓智能,是指让计算机具备一部分自主的分析功能。比如监控视频中的目标锁定(detection 可以是基于特征的检测,比如人脸检测,可以使基于行为的检测,比如犯罪分子有某种行为习惯),目标跟踪(tracking),目标识别(recognition首先将目标分割出来,然后利用前面所述的图像识别方法进行识别)。
对于智能监控来说,实时性极为重要。但是detection, tracking, segmentation都是非常耗时的过程(比如采用单纯粒子滤波进行单目标跟踪,对于DVD图像,未优化的程序处理速度不超过15fps,使用效果更好的改进算法,速度可能降至5fps),计算效率极大的阻碍了前沿技术在工程实际中的应用。
目前智能监控在国内和世界范围内都是非常火的领域。国内海康威视,银江科技等都是监控领域炙手可热的公司,尤其是前者,他在这个领域世界排名大约第六,产品遍及国内各大城市街道,高速公路,大型工业企业。但是目前的主流监控市场是不断的提升监控的分辨率,智能算法很少被引入到实际产品中,很大一部分原因是因为算法的复杂性。尽管一些海归和博士建立了一些拥有自己算法的智能监控系统公司,比如莲花山研究院所办的公司在这方面所作的尝试。
智能监控是一个非常有价值的领域,成长快,利润高。英特尔的优势在于OpenCV中已经开发了大量前沿视觉算法,这些在Intel的CPU上都可以进行优化。
在移动终端上,图像和语音可能成为和打字同等重要的信息输入方法。比较火的领域有:图像识别,语音识别(如科大讯飞),增强现实(无数的APP),图像拼接(如微软的重量产品Kinect和photosynth(在bing上结合地图有重要应用))等领域,这些都是与计算能力十分相关的内容,而其本质上也是大规模的矩阵运算,如果能有效地利用OpenCV, Ipp, Intel数学运算库和利用好CPU-GPU的联合运算,都会对性能和功耗有比较大的提升。
(四) 其他
视觉识别一般分为图像层次和视频序列的识别;前者在一些大的搜索引擎公司都有所涉及,后者主要集中于国外高校实验室和一些本领域的领军人物的创业型公司(比如莲花山研究院所作的将视觉理论所做的产业化工作,Zhu,chunsong是UCLA的professor,在弯曲评论上有个简单的对他的介绍或者可以到他的Lab网页查看)。国内本土的监控公司,很多也采取了和国内各大高校合作的方式。而实际上,某些基于视频的识别在实验室已经做到相当好的效果,面临的主要问题是:光照,角度形变,尺度,实时性等问题(其实人脸识别尽管已经发展到了相当成熟,仍然面临这个问题,比如无法区分照片中的人脸,光照变化大的时候正确率有较大的下降,甚至已经有人专门研究过什么情况下人脸识别会失效:http://ahprojects.com/art/cv-dazzle)
下面是几个关于有意思的demo:
表情识别: http://www.youtube.com/watch?v=n8wJ8tjmnmU&feature=feedf
http://www.youtube.com/watch?v=QP3ihC78YO4
匹配: http://www.youtube.com/watch?v=k9vHdeCMRm0
跟踪: http://www.youtube.com/watch?v=LQt6gnLOxBw
http://ivs.see-soft.net/(包括火焰识别,目标跟踪等)
内容识别:http://www.cs.nyu.edu/~yann/research/objreco/index.html
(对于基于内容的视觉认知来说,图像识别应用的更多一些,基于视频的识别做的比较好的demo是deep learning的,而实际上前不久微软在语音识别方面的进展也主要是基于deep learning:http://research.microsoft.com/en-us/news/features/speechrecognition-082911.aspx)
此外,还有两个比较神奇的Demo:
yi,ma老师的稀疏人脸识别: http://perception.csl.uiuc.edu/recognition/Robust_face.html
Michal Irani 的超分辨:http://www.wisdom.weizmann.ac.il/~vision/SingleImageSR.html
接下来主要从图像识别开始,简述笔者对于计算机视觉领域的优化的任务的总结和思考:
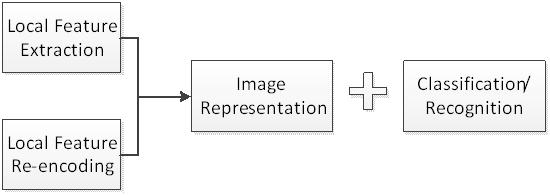
(一) 图像识别一般符合如下框架:
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 HNN10040420 的文章《从计算机视觉角度看处理器性能优化》','https://www.xiaopingtou.net/article-64286.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
{kind=link}
1. 识别正确率与图像数据和所建立的图像类别模型有关,前者即与所提取的image representation的判别性有关,进一步,与所提取的local description和encoding完的描述子的判别性有关;后者与所采用的数学模型有关,至于具体采用什么模型,与前者encoding完的数据在高维空间中的相对位置关系有关(Data Drive)。
2. 图像理解是一个大规模的数据并行计算过程,用到了大量的矩阵运算。可以优化的地方:
1) local feature descriptor的获取,这方面效果最好的是SIFT描述子,是十年来效果最好的,但是效率低,提取一副720*576的图像的特征,可能需要几秒钟,当然提取的时间与图像梯度的复杂度正相关。09年,CVPR best demo 在这方面做了很漂亮的工作,他们将提取一个点的时间减少到2.5毫秒。参看demo(http://mi.eng.cam.ac.uk/~sjt59/hips.html)同时,该实验室也制作了iPhone 应用oMoby,识别效果我认为比Google goggles 效果还要好。提升特征描述的时间,是图像理解的第一步,对于将图像信息转化为计算机可识别信息至关重要。
2) Local descriptorre-encoding 由于局部特征描述繁杂无序,难以通过训练得到有意义的模型。通过将其量化(建立码书模型)得到统一的,可分的多维空间中的点,以便于通过训练可以将这些模型区分开。
3) 对于数学模型计算的优化。基本上所有的判别式模型都可以归结为是凸优化问题如支持向量机SVM,面临大量的数值计算。模型计算过程一般是离线过程。
这里有一个很好的讲座:http://www.youtube.com/watch?v=g1tLjptuTBo(Kaiyu是NEC美国研究院的研究员,在09年的VOC中拿了classification组第一名。)
重申一下,这里所介绍的最经典的基于统计学习的识别框架,近些年有一些科学家试图跳出这个套路,提出了deep learning等算法,可以参看文末给出的demo。
3. 图像理解相关领域进行优化的价值:
1) 图像识别技术在03年以后有了突飞猛进的进展。Google 有相关产品,goggles,similar image search(两者均是基于图像内容的检索和识别),微软亚洲研究院中,图像识别是其非常重要的研究领域(如sun,jian所作的工作), 其他的有:百度淘宝都有以图识图的产品。
2) 这些图像产品都面临着计算效率的问题,即:图像特征提取慢,数学模型离线训练慢。这方面的优化具有非常有价值的意义。
3) 优化过程是否可以考虑:强化OpenCV和IPP(这两者我估计在实际产品中用到的很多),CPU+GPU的联合优化(由于是大规模的矩阵运算,有效地利用GPU是可行之路,即:OpenCL),针对特定算法有效利用IA架构CPU优势,分布式计算等。
4) 扩展:随着图像识别技术的发展,基于相关技术的视频序列识别近些年也得到了更多的应用和发展,比如行为识别等。由此而引发的,传统监控系统向智能监控系统的转变这两年也逐渐兴起,具体内容请看下面。
(二) 智能监控中的优化
所谓智能,是指让计算机具备一部分自主的分析功能。比如监控视频中的目标锁定(detection 可以是基于特征的检测,比如人脸检测,可以使基于行为的检测,比如犯罪分子有某种行为习惯),目标跟踪(tracking),目标识别(recognition首先将目标分割出来,然后利用前面所述的图像识别方法进行识别)。
对于智能监控来说,实时性极为重要。但是detection, tracking, segmentation都是非常耗时的过程(比如采用单纯粒子滤波进行单目标跟踪,对于DVD图像,未优化的程序处理速度不超过15fps,使用效果更好的改进算法,速度可能降至5fps),计算效率极大的阻碍了前沿技术在工程实际中的应用。
目前智能监控在国内和世界范围内都是非常火的领域。国内海康威视,银江科技等都是监控领域炙手可热的公司,尤其是前者,他在这个领域世界排名大约第六,产品遍及国内各大城市街道,高速公路,大型工业企业。但是目前的主流监控市场是不断的提升监控的分辨率,智能算法很少被引入到实际产品中,很大一部分原因是因为算法的复杂性。尽管一些海归和博士建立了一些拥有自己算法的智能监控系统公司,比如莲花山研究院所办的公司在这方面所作的尝试。
智能监控是一个非常有价值的领域,成长快,利润高。英特尔的优势在于OpenCV中已经开发了大量前沿视觉算法,这些在Intel的CPU上都可以进行优化。
(三) 移动终端上的性能优化
在移动终端上,图像和语音可能成为和打字同等重要的信息输入方法。比较火的领域有:图像识别,语音识别(如科大讯飞),增强现实(无数的APP),图像拼接(如微软的重量产品Kinect和photosynth(在bing上结合地图有重要应用))等领域,这些都是与计算能力十分相关的内容,而其本质上也是大规模的矩阵运算,如果能有效地利用OpenCV, Ipp, Intel数学运算库和利用好CPU-GPU的联合运算,都会对性能和功耗有比较大的提升。
(四) 其他
视觉识别一般分为图像层次和视频序列的识别;前者在一些大的搜索引擎公司都有所涉及,后者主要集中于国外高校实验室和一些本领域的领军人物的创业型公司(比如莲花山研究院所作的将视觉理论所做的产业化工作,Zhu,chunsong是UCLA的professor,在弯曲评论上有个简单的对他的介绍或者可以到他的Lab网页查看)。国内本土的监控公司,很多也采取了和国内各大高校合作的方式。而实际上,某些基于视频的识别在实验室已经做到相当好的效果,面临的主要问题是:光照,角度形变,尺度,实时性等问题(其实人脸识别尽管已经发展到了相当成熟,仍然面临这个问题,比如无法区分照片中的人脸,光照变化大的时候正确率有较大的下降,甚至已经有人专门研究过什么情况下人脸识别会失效:http://ahprojects.com/art/cv-dazzle)
下面是几个关于有意思的demo:
表情识别: http://www.youtube.com/watch?v=n8wJ8tjmnmU&feature=feedf
http://www.youtube.com/watch?v=QP3ihC78YO4
匹配: http://www.youtube.com/watch?v=k9vHdeCMRm0
跟踪: http://www.youtube.com/watch?v=LQt6gnLOxBw
http://ivs.see-soft.net/(包括火焰识别,目标跟踪等)
内容识别:http://www.cs.nyu.edu/~yann/research/objreco/index.html
(对于基于内容的视觉认知来说,图像识别应用的更多一些,基于视频的识别做的比较好的demo是deep learning的,而实际上前不久微软在语音识别方面的进展也主要是基于deep learning:http://research.microsoft.com/en-us/news/features/speechrecognition-082911.aspx)
此外,还有两个比较神奇的Demo:
yi,ma老师的稀疏人脸识别: http://perception.csl.uiuc.edu/recognition/Robust_face.html
Michal Irani 的超分辨:http://www.wisdom.weizmann.ac.il/~vision/SingleImageSR.html