嵌入式Linux应用程序访问物理地址的实例
2013-05-28 14:09:25 来源:EEWORLD关键字: Linux 驱动 可移植 接口
前言按照Linux分层驱动思想,外设驱动与主机控制器的驱动不相关,主机控制器的驱动不关心外设,而外设驱动也不关心主机,外设访问核心层的通用应用程序接口进行数据传输,主机和外设之间可以进行任意的组合。这样思想要求应用程序不应当直接访问物理地址,而是应当通过驱动程序的调用来实现,以便保持应用程序的可移植性,操作访问的统一性,应用程序利用系统的统一调用接口访问外设,如使用write(),read()等函数进行实际的外设读写控制。应用程序通过调用接口进入内核函数后,内核利用copy_from_user()获得应用层数据,内核驱动程序也通过分层最终执行物理访问,之后把获得的数据用copy_to_user()回传给应用程序的调用者。由于驱动对外需要有个统一接口,所以定义了一些结构体,链表等机制,以便让应用程序操作简单化,数据在内核一应用之间的复制,填充结构体等都需要时间开销,有时按这种标准调用方式,因为操作时间过长,无法完成设计目的。 操作效率评估
我们的一个项目中,系统由FPGA和ARM11结合为核心控制器,其中FPGA连接外部高速ADC、DAC和RF器件在ARM11的控制下,实现GB18000-6C标准的UHF RFID读写控制状态机。FPGA与ARM11的接口采用SPI,其中ARM11选用三星S3C6410,作为SPI的主机,FPGA作为SPI的从机,受S3C6410的控制。在本系统中,SPI接口充当ARM11和FPGA交互的桥梁,ARM11的命令和动作参数传给FPGA并启动FPGA处理状态机,FPGA动作的结果也通过SPI回传给ARM11,两者之间的通讯效率在系统中需要重点关注。
评估通讯接口时,利用三星提供的SPI驱动函数,系统运行在533MHz,SPI时钟配置为16MHz,程序在linux3.0环境下通过read/write进行操作,为了评估效率,另外采用一个GPIO输出脉冲指示操作过程,试验结果显示效率非常低下,从应用层执行write代码开始到SPI端口输出时钟,延时长达72μs,SPI操作之后,再回到应用层的下一个语句也延时42μs,对于比较少的数据传输情况,附加的额外等待时间远远长于实际传输有效时间,从前面数据看出,通过标准库调用严重影响系统性能,没法满足系统需求。通过查看驱动程序的源代码,可以发现因为驱动程序层层封装,并且包含应用层到内核的copy_from_user()和内核到应用层的copy_to_user()两次数据搬移,导致执行效率很低。为了提高数据交互效率,就要设法绕开数据搬移等时间开销,最好能直接操作寄存器,虽然这种想法与Linux分层驱动思想不相符合,但是在嵌入式系统中,有时需要高的执行效率,如果利用系统一些特定函数,实现高效率的数据交互从而完成设计目标是有必要和可能的。
linux存在名为mmap的函数,能把物理地址映射为虚拟地址,并且这个函数能直接在应用程序中直接调用而不是仅仅属于内核调用的函数,这样在应用层直接操作S3C6410的物理外设成为可能。考虑到在特定的嵌入式系统中,特定外设的使用可以由程序控制,这样可以简化共享设备的互斥保护,进一步减少代码量,提高了访问效率。
mmap函数调用实例
mmap函数作用是将物理地址映射至用户空间。下面是函数的参数简单说明
void* mmap(void * addr, size_t len, int prot, int flags, int fd, off_t offset);
addr: 指定文件应被映射到进程空间的起始地址
len: 映射到用户空间的字节数
prot: 指定被映射空间的访问权限,
flags: 由以下几个常值指定:
fd: 映射到用户空间的文件的描述符
offset: 被映射内存区在文件中的偏移值该函数映射文件描述符
通过这个函数,我们可以在应用层访问对应物理地址正确映射后的虚拟地址,这个函数使我们在应用层也具有对任意物理地址的操作权限,下面代码配置S3C6410的SPI0,因为使用mmap映射,所以不论内核是否带有SPI驱动都不影响我们使用SPI0,但是因为本程序需要对比研究标准驱动方式与直接存储器访问方式的执行差异,所以在内核中编译了标准SPI的驱动程序。由于S3C6410多数脚都有复用功能,为了使SPI0正确工作,还需要配置相关对应的GPIO为SPI功能(实际上因为我们编译的内核带有SPI0的驱动,内核程序已经完成了SPI的初始化,有的内核没有编译SPI,所以下面还是完整配置了SPI,供参考),同时为了观察研究SPI的执行效率,我们程序还对其他GPIO做了配置以便输出脉冲,通过示波器来评估观察。另外我们还使用若干时间标志来记录操作过程时间,对于在没有示波器的情况下也能评估执行时间。
下面是测试程序代码以及测试过程的示波器记录抓图。 #include "test.h"
void Init_FPGA_SPI(){ //配置SPI端口
int fbb;
fbb=open("/dev/mem",O_RDWR | O_SYNC);
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f00b000);
*(volatile unsigned int *)(map_base+0x04)=0x00000101; //CLK=16.625MHz
*(volatile unsigned int *)(map_base+0x08)=0x00000000;
*(volatile unsigned int *)(map_base+0x0c)=0x00000002;
*(volatile unsigned int *)(map_base)=0x00000003;
FPGA_RUN=map_base+0x18;
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f008000);
GPC=map_base+0x40; //配置端口复用功能为SPI
map_GPC=*(volatile unsigned int *)(GPC+4);
*(volatile unsigned int *)(GPC)=0x12201222;
GPC+=4;
virt_addr2=map_base+0x824;//配置观察IO
GLEDstate=*(volatile unsigned int *)(virt_addr2);
}
void Init_Timer(){ //添加加配置1微秒时基定时器
int fbb;
unsigned int temp;
fbb=open("/dev/mem",O_RDWR | O_SYNC);
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f006000);
…………………… 篇幅原因略去部分次要代码
MYSYSTICK=map_base+0x14;
}
void SPI_init(){
bits=8;
speed = 16625000;
trr.len =20;
trr.delay_usecs = 0;
trr.speed_hz = speed;
trr.bits_per_word = bits;
fspi = open("/dev/spidev0.0", O_RDWR);
ioctl(fspi, SPI_IOC_RD_MODE, &mode);
ioctl(fspi, SPI_IOC_WR_MODE, &mode);
}
__inline unsigned int GETSYSCLK(){
return(*(volatile unsigned int *)(MYSYSTICK));
}
__inline void CSFPGAL(){
map_GPC&=0xfffffff7;
*(volatile unsigned int *)(GPC)=map_GPC;
}
__inline void CSFPGAH(){
map_GPC|=0x00000008;
*(volatile unsigned int *)(GPC)=map_GPC;
}
void test(){
GLEDstate&=0xfffffffe;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;//产生GPIO负跳变
starttime2=GETSYSCLK();
*(volatile unsigned int *)(FPGA_RUN-0x0c)=0x00;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x23;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x03;
CSFPGAL();
*(volatile unsigned int *)(FPGA_RUN)=tx[0];
*(volatile unsigned int *)(FPGA_RUN)=tx[1];
*(volatile unsigned int *)(FPGA_RUN)=tx[2];
*(volatile unsigned int *)(FPGA_RUN)=tx[3];
*(volatile unsigned int *)(FPGA_RUN)=tx[4];
while (((*(volatile unsigned int *)(FPGA_RUN-4)&0xfe000)>>13)<5){};
CSFPGAH();
stoptime2=GETSYSCLK();
GLEDstate|=0x00000001;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;
GLEDstate&=0xfffffffe;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;
starttime1=GETSYSCLK(); //产生GPIO一个正脉冲
write(fspi,&tx,5);
stoptime1=GETSYSCLK();
GLEDstate|=0x00000001;
*(volatile unsigned int *)(virt_addr2)=GLEDstate; //产生GPIO正跳变
printf("DRVtime=%d REGtime=%d ",starttime1-stoptime1,starttime2-stoptime2);
}
int main(void){
SPI_init(); Init_FPGA_SPI(); Init_Timer();
waittime=GETSYSCLK();
while(1){
if ((waittime-GETSYSCLK())>2000000){ //2000ms测试一次
waittime=GETSYSCLK();
test();
}
}
}
图1示波器截图添加了一些时间信息以便对应代码注释说明,对应于代码mmap方式和标准驱动调用方式产生了两组SCK时钟,GPIO观察脚显示第一次SPI访问消耗5μs,第二次访问消耗114μs,其中真正操作SPI的时间也就4μs不到,其它时间消耗在系统应用层到内核两次双向的数据拷贝以及为了统一对外接口所做的数据结构配置等方面,由此对比可以看出两种方式访问效率上的巨大差异。
图 1
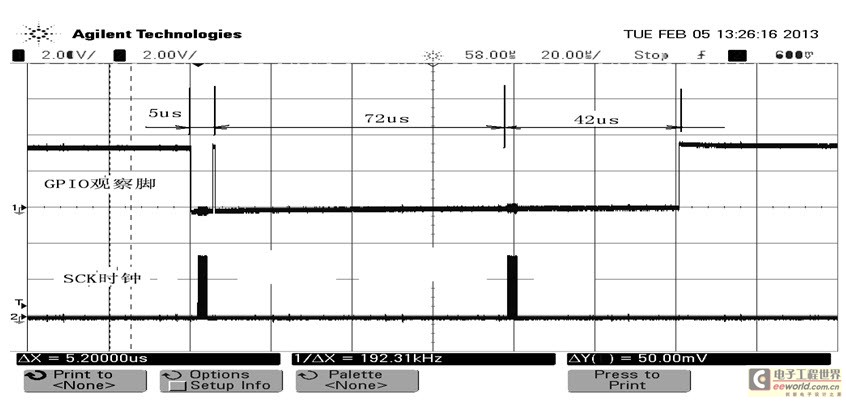 图 1
图 1
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 liangcsdn111 的文章《嵌入式Linux应用程序访问物理地址的实例》','https://www.xiaopingtou.net/article-67890.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
结语
通过mmap方式应用程序在Linux下操作硬件寄存器,适合于关注高效率的访问场合,在嵌入式应用中,我们既能够获得使用操作系统管理任务和丰富开源驱动库的好处,同时又能在局部提升处理效率,提高处理数据的实时性。