{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 LLLGGW 的文章《嵌入式Linux设备驱动开发(二)》','https://www.xiaopingtou.net/article-69339.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
上一篇中介绍到设备驱动如何匹配设备以及绑定设备的,在Linux系统下进行注册,这里将继续介绍probe函数的功能。
5、probe函数
Probe()函数必须验证指定设备的硬件是否真的存在,probe()可以使用设备的资源,包括时钟,platform_data等。一般来说设备是不能被热插拔的,所以可以将probe()函数放在init段里面来节省driver运行时候的内存开销。 probe函数在设备驱动注册最后收尾工作,当设备的device 和其对应的driver 在总线上完成配对之后,系统就调用platform设备的probe函数完成驱动注册最后工作。资源、中断调用函数以及其他相关工作。 probe函数接收到plarform_device这个参数后,就需要从中提取出需要的信息。它一般会通过调用内核提供的platform_get_resource和platform_get_irq等函数来获得相关信息。如通过platform_get_resource获得设备的起始地址后,可以对其进行request_mem_region和ioremap等操作,以便应用程序对其进行操作。通过platform_get_irq得到设备的中断号以后,就可以调用request_irq函数来向系统申请中断。这些操作在设备驱动程序中一般都要完成。
在完成了上面这些工作和一些其他必须的初始化操作后,就可以向系统注册我们在/dev目录下能看在的设备文件了。
函数进入for里面,i=0,num_resources=7,拿出resource[0]资源。resource_type(r)提取出该份资源 的资源类型并与函数传递下来的资源类型进行比较,匹配。Num=0(这里先判断是否等于0再自减1)符合要求,从而返回该资源。 c、
将ndev保存成平台总线设备的私有数据,提取用dev_get_drvdata
初始化这个sem为互斥锁 g、
但要使用I/O内存首先要申请,然后才能映射,使用I/O端口首先要申请,或者叫请求,对于I/O端口的请求意思是让内核知道你要访问这个端口,这样内核知道了以后它就不会再让别人也访问这个端口了.毕竟这个世界僧多粥少啊.申请I/O端口的函数是request_region, 申请I/O内存的函数是request_mem_region。request_mem_region函数并没有做实际性的映射工作,只是告诉内核要使用一块内存地址,声明占有,也方便内核管理这些资源。 h、
ioremap主要是检查传入地址的合法性,建立页表(包括访问权限),完成物理地址到虚拟地址的转换。如果出错,iounmap函数用于取消ioremap()所做的映射。
使用cdev_add注册字符设备前应该先调用register_chrdev_region或alloc_chrdev_region分配设备号。alloc_chrdev_region申请一个动态主设备号,并申请一系列次设备号。baseminor为起始次设备号,count为次设备号的数量。注销设备号(cdev_del)后使用unregister_chrdev_region。
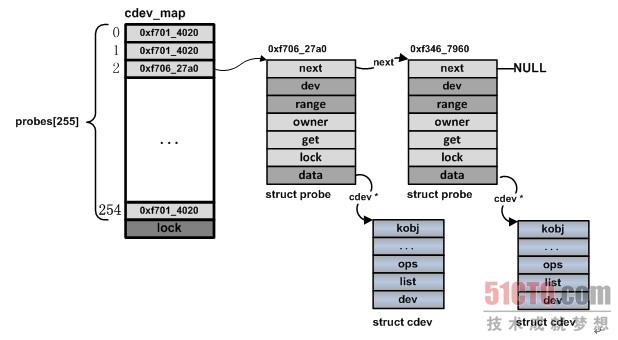
内核中所有都字符设备都会记录在一个 kobj_map 结构的 cdev_map 变量中。这个结构的变量中包含一个散列表用来快速存取所有的对象。kobj_map() 函数就是用来把字符设备编号和 cdev 结构变量一起保存到 cdev_map 这个散列表里。当后续要打开一个字符设备文件时,通过调用 kobj_lookup() 函数,根据设备编号就可以找到 cdev 结构变量,从而取出其中的 ops 字段。
对系统而言,当设备驱动程序成功调用了cdev_add之后,就意味着一个字符设备对象已经加入到了系统,在需要的时候,系统就可以找到它。对用户态的程序而言,cdev_add调用之后,就已经可以通过文件系统的接口呼叫到我们的驱动程序。
sysfs是用于表现设备驱动模型的文件系统,它基于ramfs。
sysfs_update_group()在kobj目录下创建一个属性集合,并显示集合中的属性文件。文件已存在也不会报错。sysfs_update_group()也用于group改动影响到文件显示时调用。
sysfs_remove_group()在kobj目录下删除一个属性集合,并删除集合中的属性文件。
sysfs_add_file_to_group()将一个属性attr加入kobj目录下已存在的的属性集合group。
sysfs_remove_file_from_group()将属性attr从kobj目录下的属性集合group中删除。
更详细的参考我的另一篇博客[DEVICE_ATTR分析](http://blog.csdn.net/chuhang_zhqr/article/details/50174813)
可以使得可以在用户空间直接对驱动的这些变量读写或调用驱动的某些函数。 通 过以上简单的几个步骤,就可以在终端查看到接口了。当我们将数据 echo 到接口中时,在上层实际上完成了一次 write 操 作,对应到 kernel ,调用了驱动中的 “wirte”。同理,当我们cat 一个 接口时则会调用 “show” 。到这里,只是简单的建立 了 应用 层到 kernel 的桥梁,真正实现对硬件操作的,还是在 “show” 和 “set” 中完成的。 至此,已经注册设备驱动程序,并且对设备的资源进行申请,映射,并设置了如何操作四个存储器接口。
irfpa_regs_res使用对sys目录下的设备集进行echo和cat就可以对这个寄存器进行读写操作了。
vdma_regs_res和 vbuf_mem_res是被设置成字符型设备了irfpa,在/dev下面,可以根据irfpa_fops的设置对该设备接口进行操作。
xinfo_mem_res直接在probe程序中设置了如何操作:
这是probe函数的最后一步,也是整个驱动程序的最后一步。初始化设备寄存器,这是对设备进行初始化操作,开机启动时对整个设备的控制寄存器进行初始化,控制设备合理运行。
5、probe函数
Probe()函数必须验证指定设备的硬件是否真的存在,probe()可以使用设备的资源,包括时钟,platform_data等。一般来说设备是不能被热插拔的,所以可以将probe()函数放在init段里面来节省driver运行时候的内存开销。 probe函数在设备驱动注册最后收尾工作,当设备的device 和其对应的driver 在总线上完成配对之后,系统就调用platform设备的probe函数完成驱动注册最后工作。资源、中断调用函数以及其他相关工作。 probe函数接收到plarform_device这个参数后,就需要从中提取出需要的信息。它一般会通过调用内核提供的platform_get_resource和platform_get_irq等函数来获得相关信息。如通过platform_get_resource获得设备的起始地址后,可以对其进行request_mem_region和ioremap等操作,以便应用程序对其进行操作。通过platform_get_irq得到设备的中断号以后,就可以调用request_irq函数来向系统申请中断。这些操作在设备驱动程序中一般都要完成。
在完成了上面这些工作和一些其他必须的初始化操作后,就可以向系统注册我们在/dev目录下能看在的设备文件了。
/**
* irfpa_drv_probe - Probe call for the device.
//*针对设备探测驱动
* @pdev: handle to the platform device structure.
//*参数是平台设备的结构体。分配存储区,注册设备
* It does all the memory allocation and registration for the device.//0成功,其他负数
* Returns 0 on success, negative error otherwise.
**/
static int __devinit irfpa_drv_probe(struct platform_device *pdev)
{
struct resource *irfpa_regs_res;
struct resource *vdma_regs_res;
struct resource *vbuf_mem_res;
struct resource *xinfo_mem_res;
struct irfpa_drvdata *drvdata;
dev_t devt;
int retval;
//参考设备树文件中对设备包括的几个地址区间
irfpa_regs_res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
vdma_regs_res = platform_get_resource(pdev, IORESOURCE_MEM, 1);
vbuf_mem_res = platform_get_resource(pdev, IORESOURCE_MEM, 2);
xinfo_mem_res = platform_get_resource(pdev, IORESOURCE_MEM, 3);
if ((!irfpa_regs_res) || (!vdma_regs_res) || (!vbuf_mem_res) || (!xinfo_mem_res)) {
dev_err(&pdev->dev, "Invalid address.
");
return -ENODEV;
}
/*组合设备号符合dev_t类型
devt = MKDEV(IRFPA_MAJOR, IRFPA_MINOR);
retval = register_chrdev_region(devt, IRFPA_DEVICES, DRIVER_NAME);
if (retval < 0)
return retval;
*/
retval = alloc_chrdev_region(&devt, IRFPA_MINOR, IRFPA_DEVICES, DRIVER_NAME);//动态分配设备编号,该函数需要传递给它指定的第一个次设备号firstminor(一般为0)和要分配的设备数count,以及设备名,调用该函数后自动分配得到的设备号保存在dev中。
if (retval < 0) {
dev_err(&pdev->dev, "alloc_chrdev_region fail.
");
return retval;
}
drvdata = kzalloc(sizeof(struct irfpa_drvdata), GFP_KERNEL);//用kzalloc申请内存的时候, 效果等同于先是用 kmalloc() 申请空间 , 然后用 memset() 来初始化 ,所有申请的元素都被初始化为 0.GFP_KERNEL 内核内存的正常分配. 可能睡眠.
if (!drvdata) {
dev_err(&pdev->dev, "Couldn't allocate device private record.
");
retval = -ENOMEM;
goto failed0;
}
dev_set_drvdata(&pdev->dev, (void *)drvdata);
drvdata->devt = devt;
drvdata->is_open = 0;
mutex_init(&drvdata->sem);
// == request_mem_region
if (!request_mem_region(irfpa_regs_res->start, irfpa_regs_res->end - irfpa_regs_res->start + 1, DRIVER_NAME)) {
dev_err(&pdev->dev, "Couldn't lock memory region at %Lx
", (unsigned long long) irfpa_regs_res->start);
retval = -EBUSY;
goto failed1_1;
}
if (!request_mem_region(vdma_regs_res->start, vdma_regs_res->end - vdma_regs_res->start + 1, DRIVER_NAME)) {
dev_err(&pdev->dev, "Couldn't lock memory region at %Lx
", (unsigned long long) vdma_regs_res->start);
retval = -EBUSY;
goto failed1_2;
}
if (!request_mem_region(vbuf_mem_res->start, vbuf_mem_res->end - vbuf_mem_res->start + 1, DRIVER_NAME)) {
dev_err(&pdev->dev, "Couldn't lock memory region at %Lx
", (unsigned long long) vbuf_mem_res->start);
retval = -EBUSY;
goto failed1_3;
}
if (!request_mem_region(xinfo_mem_res->start, xinfo_mem_res->end - xinfo_mem_res->start + 1, DRIVER_NAME)) {
dev_err(&pdev->dev, "Couldn't lock memory region at %Lx
", (unsigned long long) xinfo_mem_res->start);
retval = -EBUSY;
goto failed1_4;
}
// ==== ioremap ====
drvdata->irfpa_base_address = ioremap(irfpa_regs_res->start, (irfpa_regs_res->end - irfpa_regs_res->start + 1));
if (!drvdata->irfpa_base_address) {
dev_err(&pdev->dev, "irfpa_reg_res ioremap() failed
");
goto failed2_1;
}
drvdata->vdma_base_address = ioremap(vdma_regs_res->start, (vdma_regs_res->end - vdma_regs_res->start + 1));
if (!drvdata->vdma_base_address) {
dev_err(&pdev->dev, "vdma_reg_res ioremap() failed
");
goto failed2_2;
}
drvdata->vbuf_base_address = ioremap(vbuf_mem_res->start, (vbuf_mem_res->end - vbuf_mem_res->start + 1));
if (!drvdata->vbuf_base_address) {
dev_err(&pdev->dev, "vbuf_mem_res ioremap() failed
");
goto failed2_3;
}
drvdata->vbuf_current_address = drvdata->vbuf_base_address;
drvdata->xinfo_base_address = ioremap(xinfo_mem_res->start, (xinfo_mem_res->end - xinfo_mem_res->start + 1));
if (!drvdata->xinfo_base_address) {
dev_err(&pdev->dev, "xinfo_mem_res ioremap() failed
");
goto failed2_4;
}
// ==== print ioremap info ===
dev_info(&pdev->dev, "ioremap %llx to %p with size %llx
",
(unsigned long long) irfpa_regs_res->start,
drvdata->irfpa_base_address,
(unsigned long long) (irfpa_regs_res->end - irfpa_regs_res->start + 1));
dev_info(&pdev->dev, "ioremap %llx to %p with size %llx
",
(unsigned long long) vdma_regs_res->start,
drvdata->vdma_base_address,
(unsigned long long) (vdma_regs_res->end - vdma_regs_res->start + 1));
dev_info(&pdev->dev, "ioremap %llx to %p with size %llx
",
(unsigned long long) vbuf_mem_res->start,
drvdata->vbuf_base_address,
(unsigned long long) (vbuf_mem_res->end - vbuf_mem_res->start + 1));
dev_info(&pdev->dev, "ioremap %llx to %p with size %llx
",
(unsigned long long) xinfo_mem_res->start,
drvdata->xinfo_base_address,
(unsigned long long) (xinfo_mem_res->end - xinfo_mem_res->start + 1));
cdev_init(&drvdata->cdev, &irfpa_fops);
drvdata->cdev.owner = THIS_MODULE;
drvdata->cdev.ops = &irfpa_fops;
retval = cdev_add(&drvdata->cdev, devt, 1);
if (retval) {
dev_err(&pdev->dev, "cdev_add() failed
");
goto failed3;
}
/* create sysfs files for the device */
retval = sysfs_create_group(&(pdev->dev.kobj), &irfpa_attr_group);
if (retval) {
dev_err(&pdev->dev, "Failed to create sysfs attr group
");
goto failed4;
}
irfpa_device_init(drvdata->irfpa_base_address, drvdata->vdma_base_address, vbuf_mem_res->start);
drvdata->irfpa_xinfo_pinpon = irfpa_readreg(drvdata->irfpa_base_address + IRFPA_XINFO_PINPON);
drvdata->nuc_buffer_pinpon = 1;
return 0; /* Success */
failed4:
cdev_del(&drvdata->cdev);
failed3:
iounmap(drvdata->xinfo_base_address);
failed2_4:
iounmap(drvdata->vbuf_base_address);
failed2_3:
iounmap(drvdata->vdma_base_address);
failed2_2:
iounmap(drvdata->irfpa_base_address);
failed2_1:
release_mem_region(xinfo_mem_res->start, xinfo_mem_res->end - xinfo_mem_res->start + 1);
failed1_4:
release_mem_region(vbuf_mem_res->start, vbuf_mem_res->end - vbuf_mem_res->start + 1);
failed1_3:
release_mem_region(vdma_regs_res->start, vdma_regs_res->end - vdma_regs_res->start + 1);
failed1_2:
release_mem_region(irfpa_regs_res->start, irfpa_regs_res->end - irfpa_regs_res->start + 1);
failed1_1:
kfree(drvdata);
failed0:
unregister_chrdev_region(devt, IRFPA_DEVICES);
return retval;
}
a、struct resource *irfpa_regs_res;
struct resource {
const char *name;
unsigned long start, end;
unsigned long flags;
struct resource *parent, *sibling, *child;
};
linux采用struct resource结构体来描述一个挂接在cpu总线上的设备实体(32位cpu的总线地址范围是0~4G):
resource->start描述设备实体在cpu总线上的线性起始物理地址;
resource->end -描述设备实体在cpu总线上的线性结尾物理地址;
resource->name 描述这个设备实体的名称,这个名字开发人员可以随意起,但最好贴切;
resource->flag 描述这个设备实体的一些共性和特性的标志位;
只需要了解一个设备实体的以上4项,linux就能够知晓这个挂接在cpu总线的上的设备实体的基本使用情况,也就是[resource->start, resource->end]这段物理地址现在是空闲着呢,还是被什么设备占用着呢?
linux会坚决避免将一个已经被一个设备实体使用的总线物理地址区间段[resource->start, resource->end],再分配给另一个后来的也需要这个区间段或者区间段内部分地址的设备实体,进而避免设备之间出现对同一总线物理地址段的重复引用,而造成对唯一物理地址的设备实体二义性.
以上的4个属性仅仅用来描述一个设备实体自身,或者是设备实体可以用来自治的单元,但是这不是linux所想的,linux需要管理4G物理总线的所有空间,所以挂接到总线上的形形 {MOD} {MOD}的各种设备实体,这就需要链在一起,因此resource结构体提供了另外3个成员:指针parent、sibling和child:分别为指向父亲、兄弟和子资源的指针。
以root source为例,root->child(*pchild)指向root所有孩子中地址空间最小的一个;pchild->sibling是兄弟链表的开头,指向比自己地址空间大的兄弟。
物理内存页面是重要的资源。从另一个角度看,地址空间本身,或者物理存储器在地址空间中的位置,也是一种资源,也要加以管理 -- resource管理地址空间资源。
内核中有两棵resource树,一棵是iomem_resource, 另一棵是ioport_resource,分别代表着两类不同性质的地址资源。两棵树的根也都是resource数据结构,不过这两个数据结构描述的并不是用于具体操作对象的地址资源,而是概念上的整个地址空间。
将主板上的ROM空间纳入iomem_resource树中;系统固有的I/O类资源则纳入ioport_resource树
b、irfpa_regs_res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
struct resource *platform_get_resource(struct platform_device *dev,
unsigned int type, unsigned int num)
{
int i;
for (i = 0; i < dev->num_resources; i++) {
struct resource *r = &dev->resource[i];//不管你是想获取哪一份资源都从第一份资源开始搜索。
if (type == resource_type(r) && num-- == 0)//首先通过type == resource_type(r)判断当前这份资源的类型是否匹配,如果匹配则再通过num-- == 0判断是否是你要的,如果不匹配重新提取下一份资源而不会执行num-- == 0这一句代码。
return r;
}
return NULL;
}
unsigned int type决定资源的类型,unsigned int num决定type类型的第几份资源(从0开始)。即使同类型资源在资源数组中不是连续排放也可以定位得到该资源。 函数进入for里面,i=0,num_resources=7,拿出resource[0]资源。resource_type(r)提取出该份资源 的资源类型并与函数传递下来的资源类型进行比较,匹配。Num=0(这里先判断是否等于0再自减1)符合要求,从而返回该资源。 c、
retval = alloc_chrdev_region(&devt, IRFPA_MINOR, IRFPA_DEVICES, DRIVER_NAME);//动态分配设备编号,该函数需要传递给它指定的第一个次设备号firstminor(一般为0)和要分配的设备数count,以及设备名,调用该函数后自动分配得到的设备号保存在dev中。
d、drvdata = kzalloc(sizeof(struct irfpa_drvdata), GFP_KERNEL);//用kzalloc申请内存的时候, 效果等同于先是用 kmalloc() 申请空间 , 然后用 memset() 来初始化 ,所有申请的元素都被初始化为 0.GFP_KERNEL 内核内存的正常分配. 可能睡眠.
e、dev_set_drvdata(&pdev->dev, (void *)drvdata); 将ndev保存成平台总线设备的私有数据,提取用dev_get_drvdata
int dev_set_drvdata(struct device *dev, void *data)
{
int error;
if (!dev->p) {
error = device_private_init(dev);
if (error)
return error;
}
dev->p->driver_data = data;
return 0;
}
从代码中,我们可以看到此函数主要是把drvdata赋给了device->p->driver_data指针。那么,我们下面来看一下,Kernel中比较重要的Device结构体,它其实是对内核中所有设备的抽象表示。 所有的设备都有一个device实例与之对应,而且Device结构体的主要用法为将其嵌入到其他的设备结构体中,如platform_device等。同时,Device结构体也负责作为子系统之间交互的统一参数。
device结构体的构成。
include/linux/device.h
struct device {
struct device *parent;
struct device_private *p; //负责保存driver核心部分的数据
struct kobject kobj;
const char *init_name;
.......
struct device_driver *driver;
#ifdef CONFIG_PINCTRL
struct dev_pin_info *pins;
#endfi
.......
struct device_node *of_node; //负责保存device_tree中相应的node地址
.......
const struct attribute_group **groups;
......
}
struct device_private {
struct klist klist_children;
struct klist_node knode_parent;
struct klist_node knode_driver;
struct klist_node knode_bus;
struct list_head deferred_probe;
void *driver_data; //负责保存driver中相应的driver_data
struct device *device;
}
那么,driver_data是何时进行初始化的呢?我们通过追踪代码是可以发现,一般driver_data的初始化是发生在Driver文件中的probe函数中的。
在probe函数中,malloc完相应的driver data结构体,填充完相应的域后,就会将driver data的地址赋值给driver data。这样,在实现与其他子系统交互的接口时,就能通过其他子系统传递过来的device指针来找到相应的driver data。
f、mutex_init(&drvdata->sem); 初始化这个sem为互斥锁 g、
request_mem_region(irfpa_regs_res->start, irfpa_regs_res->end - irfpa_regs_res->start + 1, DRIVER_NAME)) (irfpa_regs_res->start, irfpa_regs_res->end - irfpa_regs_res->start + 1, DRIVER_NAME))
#define request_mem_region(start,n,name) __request_region(&iomem_resource, (start), (n), (name))
//__request_region检查是否可以安全占用起始物理地址S1D_PHYSICAL_REG_ADDR之后的连续S1D_PHYSICAL_REG_SIZE字节大小空间
一般来说,在系统运行时,外设的I/O内存资源的物理地址是已知的,由硬件的设计决定。但是CPU通常并没有为这些已知的外设I/O内存资源的物理地址预定义虚拟地址范围,驱动程序并不能直接通过物理地址访问I/O内存资源,而必须将它们映射到核心虚地址空间内(通过页表),然后才能根据映射所得到的核心虚地址范围,通过访内指令访问这些I/O内存资源。Linux在io.h头文件中声明了函数ioremap(),用来将I/O内存资源的物理地址映射到核心虚地址空间。 但要使用I/O内存首先要申请,然后才能映射,使用I/O端口首先要申请,或者叫请求,对于I/O端口的请求意思是让内核知道你要访问这个端口,这样内核知道了以后它就不会再让别人也访问这个端口了.毕竟这个世界僧多粥少啊.申请I/O端口的函数是request_region, 申请I/O内存的函数是request_mem_region。request_mem_region函数并没有做实际性的映射工作,只是告诉内核要使用一块内存地址,声明占有,也方便内核管理这些资源。 h、
drvdata->irfpa_base_address = ioremap(irfpa_regs_res->start, (irfpa_regs_res->end - irfpa_regs_res->start + 1)); ioremap主要是检查传入地址的合法性,建立页表(包括访问权限),完成物理地址到虚拟地址的转换。如果出错,iounmap函数用于取消ioremap()所做的映射。
void * __ioremap(unsigned long phys_addr, unsigned long size, unsigned long flags)
void *ioremap(unsigned long phys_addr, unsigned long size)
入口: phys_addr:要映射的起始的IO地址;
size:要映射的空间的大小;
flags:要映射的IO空间的和权限有关的标志;
phys_addr:是要映射的物理地址
size:是要映射的长度,单位是字节
头文件:io.h
功能:将一个IO地址空间映射到内核的虚拟地址空间上去,便于访问;在将I/O内存资源的物理地址映射成核心虚地址后,理论上讲我们就可以象读写RAM那样直接读写I/O内存资源了。为了保证驱动程序的跨平台的可移植性,我们应该使用Linux中特定的函数来访问I/O内存资源,而不应该通过指向核心虚地址的指针来访问。 i、
实现:对要映射的IO地址空间进行判断,低PCI/ISA地址不需要重新映射,也不允许用户将IO地址空间映射到正在使用的RAM中,最后申请一个 vm_area_struct结构,调用remap_area_pages填写页表,若填写过程不成功则释放申请的vm_area_struct空间;
ioremap 依靠 __ioremap实现,它只是在__ioremap中以第三个参数为0调用来实现.
ioremap是内核提供的用来映射外设寄存器到主存的函数,我们要映射的地址已经从pci_dev中读了出来(上一步),这样就水到渠成的成功映射了而不会和其他地址有冲突。映射完了有什么效果呢,我举个例子,比如某个网卡有100 个寄存器,他们都是连在一块的,位置是固定的,假如每个寄存器占4个字节,那么一共400个字节的空间被映射到内存成功后,ioaddr就是这段地址的开头(注意ioaddr是虚拟地址,而mmio_start是物理地址,它是BIOS得到的,肯定是物理地址,而保护模式下CPU不认物理地址,只认虚拟地址),ioaddr+0就是第一个寄存器的地址,ioaddr+4就是第二个寄存器地址(每个寄存器占4个字节),以此类推,我们就能够在内存中访问到所有的寄存器进而操控他们了。
cdev_init(&drvdata->cdev, &irfpa_fops);
struct cdev {
struct kobject kobj; // 每个 cdev 都是一个 kobject
struct module *owner; // 指向实现驱动的模块
const struct file_operations *ops; // 操纵这个字符设备文件的方法
struct list_head list; // 与 cdev 对应的字符设备文件的 inode->i_devices 的链表头
dev_t dev; // 起始设备编号
unsigned int count; // 设备范围号大小
};
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
{
memset(cdev, 0, sizeof *cdev);
INIT_LIST_HEAD(&cdev->list);
kobject_init(&cdev->kobj, &ktype_cdev_default);
cdev->ops = fops;
}
一个 cdev 一般它有两种定义初始化方式:静态的和动态的。
静态内存定义初始化:这里采用静态初始化:
struct cdev my_cdev;
cdev_init(&my_cdev, &fops);
my_cdev.owner = THIS_MODULE;
动态内存定义初始化:
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops = &fops;
my_cdev->owner = THIS_MODULE;
cdev_init(&drvdata->cdev, &irfpa_fops);
drvdata->cdev.owner = THIS_MODULE;
drvdata->cdev.ops = &irfpa_fops;
初始化 cdev 后,需要把它添加到系统中去。为此可以调用 cdev_add() 函数。传入 cdev 结构的指针,起始设备编号,以及设备编号范围。 retval = cdev_add(&drvdata->cdev, devt, 1);
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
{
p->dev = dev;
p->count = count;
return kobj_map(cdev_map, dev, count, NULL, exact_match, exact_lock, p);
}
设备驱动程序通过调用cdev_add把它所管理的设备对象的指针嵌入到一个类型为struct probe的节点之中,然后再把该节点加入到cdev_map所实现的哈希链表中。 使用cdev_add注册字符设备前应该先调用register_chrdev_region或alloc_chrdev_region分配设备号。alloc_chrdev_region申请一个动态主设备号,并申请一系列次设备号。baseminor为起始次设备号,count为次设备号的数量。注销设备号(cdev_del)后使用unregister_chrdev_region。
内核中所有都字符设备都会记录在一个 kobj_map 结构的 cdev_map 变量中。这个结构的变量中包含一个散列表用来快速存取所有的对象。kobj_map() 函数就是用来把字符设备编号和 cdev 结构变量一起保存到 cdev_map 这个散列表里。当后续要打开一个字符设备文件时,通过调用 kobj_lookup() 函数,根据设备编号就可以找到 cdev 结构变量,从而取出其中的 ops 字段。
对系统而言,当设备驱动程序成功调用了cdev_add之后,就意味着一个字符设备对象已经加入到了系统,在需要的时候,系统就可以找到它。对用户态的程序而言,cdev_add调用之后,就已经可以通过文件系统的接口呼叫到我们的驱动程序。
static const struct file_operations irfpa_fops = {
.owner = THIS_MODULE,
.write = irfpa_write,
.read = irfpa_read,
.open = irfpa_open,
.release = irfpa_release,
};
j、retval = sysfs_create_group(&(pdev->dev.kobj), &irfpa_attr_group); sysfs是用于表现设备驱动模型的文件系统,它基于ramfs。
sysfs文件系统中提供了四类文件的创建与管理,分别是目录、普通文件、软链接文件、二进制文件。目录层次往往代表着设备驱动模型的结构,软链接文件则代表着不同部分间的关系。比如某个设备的目录只出现在/sys/devices下,其它地方涉及到它时只好用软链接文件链接过去,保持了设备唯一的实例。而普通文件和二进制文件往往代表了设备的属性,读写这些文件需要调用相应的属性读写。sysfs_create_group()在kobj目录下创建一个属性集合,并显示集合中的属性文件。如果文件已存在,会报错。
sysfs是表现设备驱动模型的文件系统,它的目录层次实际反映的是对象的层次。为了配合这种目录,linux专门提供了两个结构作为sysfs的骨架,它们就是struct kobject和struct kset。我们知道,sysfs是完全虚拟的,它的每个目录其实都对应着一个kobject,要想知道这个目录下有哪些子目录,就要用到kset。从面向对象的角度来讲,kset继承了kobject的功能,既可以表示sysfs中的一个目录,还可以包含下层目录。
sysfs_update_group()在kobj目录下创建一个属性集合,并显示集合中的属性文件。文件已存在也不会报错。sysfs_update_group()也用于group改动影响到文件显示时调用。
sysfs_remove_group()在kobj目录下删除一个属性集合,并删除集合中的属性文件。
sysfs_add_file_to_group()将一个属性attr加入kobj目录下已存在的的属性集合group。
sysfs_remove_file_from_group()将属性attr从kobj目录下的属性集合group中删除。
更详细的参考我的另一篇博客[DEVICE_ATTR分析](http://blog.csdn.net/chuhang_zhqr/article/details/50174813)
可以使得可以在用户空间直接对驱动的这些变量读写或调用驱动的某些函数。 通 过以上简单的几个步骤,就可以在终端查看到接口了。当我们将数据 echo 到接口中时,在上层实际上完成了一次 write 操 作,对应到 kernel ,调用了驱动中的 “wirte”。同理,当我们cat 一个 接口时则会调用 “show” 。到这里,只是简单的建立 了 应用 层到 kernel 的桥梁,真正实现对硬件操作的,还是在 “show” 和 “set” 中完成的。 至此,已经注册设备驱动程序,并且对设备的资源进行申请,映射,并设置了如何操作四个存储器接口。
irfpa_regs_res使用对sys目录下的设备集进行echo和cat就可以对这个寄存器进行读写操作了。
vdma_regs_res和 vbuf_mem_res是被设置成字符型设备了irfpa,在/dev下面,可以根据irfpa_fops的设置对该设备接口进行操作。
xinfo_mem_res直接在probe程序中设置了如何操作:
drvdata->irfpa_xinfo_pinpon = irfpa_readreg(drvdata->irfpa_base_address + IRFPA_XINFO_PINPON);
在系统的目录下,就可以找到一个字符型设备和一些寄存器设备集合。
k、irfpa_device_init(drvdata->irfpa_base_address, drvdata->vdma_base_address, vbuf_mem_res->start); 这是probe函数的最后一步,也是整个驱动程序的最后一步。初始化设备寄存器,这是对设备进行初始化操作,开机启动时对整个设备的控制寄存器进行初始化,控制设备合理运行。