{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 chengfeng0_0 的文章《理解 linux 工作队列》','https://www.xiaopingtou.net/article-69858.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
在系统初始化的时候定义一个函数,这个函数在未来的某个情况下我会调用执行,但我不知道这个具体的时间是什么时候,所以我可以将这个任务储存在一个地方,然后在需要执行这个任务的时候调用它,这个任务被称为工作,这个储存任务的地方被称为工作队列。
这样一个目的和中断系统一样,但我们为什么不用中断呢?
IBM的工程师给出的解释:
在中断上下文里,不能睡眠,不能阻塞;原因是中断上下文并不与任何进程关联,如在中断上下文睡眠,调度器将不能将其唤醒,所以在中断上下文中不能有导致内核进入睡眠的行为,如持有信号量,执行非原子的内存分配等。工作队列运行于进程上下文中 ( 他们通过内核线程执行 ),因此它完全可以睡眠,可以被调度,也可以被其他进程所抢占。(对进程上下文和中断上下文的理解推荐文章:http://blog.csdn.net/liusirboke/article/details/49681625) 如何使用工作队列? 对于使用者,基本上只需要做 3 件事情,依次为:
1. 创建工作项
INIT_WORK(struct work_struct work, work_func_t func);
这是一个宏,在运行时初始化工作项 work,并设置了回调函数 func
2. 创建工作队列
create_singlethread_workqueue(name)
或者create_workqueue(name)
3. 调度执行工作
int schedule_work(struct work_struct *work);
或者int queue_work(struct workqueue_struct *wq, struct work_struct *work);
通过tp的代码来理解工作队列的原理。
static struct work_struct touch_resume_work;
首先定义一个任务
static struct workqueue_struct *touch_resume_workqueue;
定义一个工作队列
static void touch_resume_workqueue_callback(struct work_struct *work)
{
TPD_DEBUG(“GTP touch_resume_workqueue_callback ”);
g_tpd_drv->resume(NULL);
tpd_suspend_flag = 0;
}
定义调度这个工作所要执行的函数
err = queue_work(touch_resume_workqueue, &touch_resume_work);
调度这个工作
err = cancel_work_sync(&touch_resume_work);
在这个工作没有被执行之前取消调度
probe 中:
touch_resume_workqueue = create_singlethread_workqueue(“touch_resume”);
创建工作队列,名字叫做 touch_resume ,用于存放一些任务,这些任务我们现在不想做。
INIT_WORK(&touch_resume_work, touch_resume_workqueue_callback);
初始化一个任务,这个任务绑定一个函数,这个函数现在不想执行,我只是告诉线程这有一个函数我后面可能会执行。
我这就不明白了,干嘛还非得用个工作队列,想用的时候直接调用不得了?!
照我现在的理解就是因为这个函数被执行时间的不确定性,所以要在我想要执行的时候随时就能调用,当这个工作所在的工作者线程被唤醒的时候,就可以执行这个函数了。整个linux系统在启动期间是按照规定的顺序执行一些代码,但在系统初始化完成之后你就不知道什么时候执行什么函数了,这个时候就需要随时能够把函数给到线程,让cpu去调度(不对,感觉解释的还是不对)。 一张画的很好的图(出处:http://blog.csdn.net/xy010902100449/article/details/46346735)
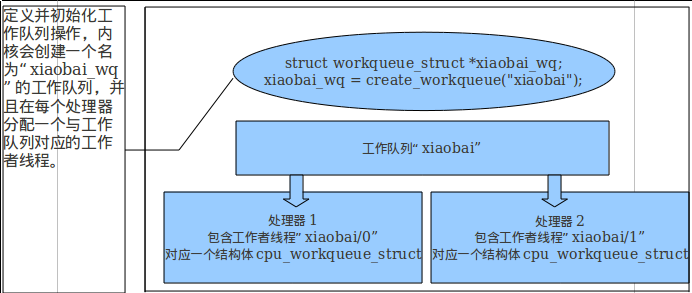

 推荐文章:
推荐文章:
Linux 的并发可管理工作队列机制探讨
https://www.ibm.com/developerworks/cn/linux/l-cn-cncrrc-mngd-wkq/
这样一个目的和中断系统一样,但我们为什么不用中断呢?
IBM的工程师给出的解释:
在中断上下文里,不能睡眠,不能阻塞;原因是中断上下文并不与任何进程关联,如在中断上下文睡眠,调度器将不能将其唤醒,所以在中断上下文中不能有导致内核进入睡眠的行为,如持有信号量,执行非原子的内存分配等。工作队列运行于进程上下文中 ( 他们通过内核线程执行 ),因此它完全可以睡眠,可以被调度,也可以被其他进程所抢占。(对进程上下文和中断上下文的理解推荐文章:http://blog.csdn.net/liusirboke/article/details/49681625) 如何使用工作队列? 对于使用者,基本上只需要做 3 件事情,依次为:
1. 创建工作项
INIT_WORK(struct work_struct work, work_func_t func);
这是一个宏,在运行时初始化工作项 work,并设置了回调函数 func
2. 创建工作队列
create_singlethread_workqueue(name)
或者create_workqueue(name)
3. 调度执行工作
int schedule_work(struct work_struct *work);
或者int queue_work(struct workqueue_struct *wq, struct work_struct *work);
通过tp的代码来理解工作队列的原理。
static struct work_struct touch_resume_work;
首先定义一个任务
static struct workqueue_struct *touch_resume_workqueue;
定义一个工作队列
static void touch_resume_workqueue_callback(struct work_struct *work)
{
TPD_DEBUG(“GTP touch_resume_workqueue_callback ”);
g_tpd_drv->resume(NULL);
tpd_suspend_flag = 0;
}
定义调度这个工作所要执行的函数
err = queue_work(touch_resume_workqueue, &touch_resume_work);
调度这个工作
err = cancel_work_sync(&touch_resume_work);
在这个工作没有被执行之前取消调度
probe 中:
touch_resume_workqueue = create_singlethread_workqueue(“touch_resume”);
创建工作队列,名字叫做 touch_resume ,用于存放一些任务,这些任务我们现在不想做。
INIT_WORK(&touch_resume_work, touch_resume_workqueue_callback);
初始化一个任务,这个任务绑定一个函数,这个函数现在不想执行,我只是告诉线程这有一个函数我后面可能会执行。
我这就不明白了,干嘛还非得用个工作队列,想用的时候直接调用不得了?!
照我现在的理解就是因为这个函数被执行时间的不确定性,所以要在我想要执行的时候随时就能调用,当这个工作所在的工作者线程被唤醒的时候,就可以执行这个函数了。整个linux系统在启动期间是按照规定的顺序执行一些代码,但在系统初始化完成之后你就不知道什么时候执行什么函数了,这个时候就需要随时能够把函数给到线程,让cpu去调度(不对,感觉解释的还是不对)。 一张画的很好的图(出处:http://blog.csdn.net/xy010902100449/article/details/46346735)
推荐文章: Linux 的并发可管理工作队列机制探讨
https://www.ibm.com/developerworks/cn/linux/l-cn-cncrrc-mngd-wkq/