{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 花果茶 的文章《嵌入式设备的网络性能该如何分析》','https://www.xiaopingtou.net/article-71110.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
最近对公司的嵌入式设备做了一个网络性能测试,如何确定网络性能的瓶颈在哪里,以及网络性能影响因素有哪些,有些心得记录在此。
一般评判网络性能都是看数据下载上传的速度。现在主流的带宽有2种,100Mbps和1000Mbps,2者理论上可以达到的下载最大速度分别为12.5MB/s和125MB/s。
设备的网络性能如何,影响因素很多,受所在局域网网络状况,对端设备性能影响很大,而且不同的应用程序测试速度也会有所不同。
那么该如何来分析设备的性能瓶颈?
对于嵌入式设备,测试网络性能一般是看从局域网内的PC服务器上下载上传数据速度。这里我们假设对端设备(PC服务器)性能够高,可以达到最大带宽。 分析影响网络性能因素,以下载为例,我的想法,可以从数据整个的流程来分析,就像一条河流,判断最终水流速度受哪些影响,可以看水流经过的地段哪里宽哪里窄。 (以下分析都假设是在1000M带宽网络环境中,使用1000M phy和1000M mac,mac是synopsys的gmac) 在数据下载中,数据的流程图如下: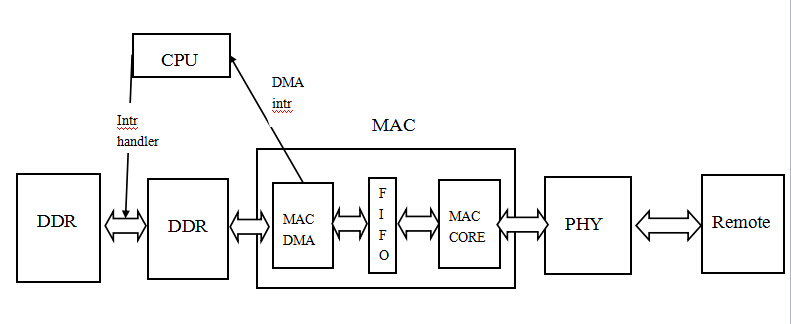
从数据由对端设备发出,按照先后顺序我们来分析,对于网络性能的影响因素: (1)局域网网络状况 数据由对端设备到测试设备可能会经过很多个路由器,如果当前局域网网络状况差,数据量大,路由器转发负载比较大,就有可能造成我们下载数据转发慢,在该环节影响我们的网络性能。 如果想要一个理想网络环境的性能测试,获取一个可以达到的最大性能,可以采用测试设备与对端设备直连的方式,排除局域网能其他设备数据包的影响。
(2)phy芯片 phy作为OSI网络模型的最底物理层,是一个数据收发器。phy不存在性能问题,这一点我问过一些phy芯片技术支持,只要提供给phy正确的工作时钟(GMII 125MHZ,MII 25MHZ,RMII 50MHZ) 它就可以达到它所支持的最大带宽,也就是说对于phy只有通或者不通,而没有快慢问题。
(3)mac core模块 mac控制器内部逻辑中跟数据收发相关的模块有3个:mac core,mtl, dma。 mac core部分功能在于提供与phy芯片相连的接口,在phy完成自动协商后,软件上会根据phy的协商状态来配置mac core,如配置其工作模式(GMII MII RMII),数据包过滤模式,流控,CRC校验,传输调度(Rx/Tx优先级)等。 mac core在与phy配合正确配置后,与phy类似,就可以达到其所支持的最大带宽,只有通或者不通,而没有快慢。 所以mac core不会对网络性能造成影响。 这里有一点需要记录下,之前有同事说对于工作在GMII模式下的phy与mac core,就一定要供125MHZ时钟嘛,低一点,速率是不是低一点也可以工作。 这个是不行的。最简单答案就是协议规定GMII的phy mac clk必须为125MHZ。 其实仔细想想,原因也简单,数据传输的clk很重要的作用是来保证其采样正确性,如果两端clk不一致,一端的数据采样肯定就不对了。
(4)mtl模块 mtl是mac内部的传输层,mtl提供了2个FIFO在mac core和dma之间,Rx FIFO和Tx FIFO。在mac core和dma之间起到缓冲区作用,因为mac core和dma是不同的时钟域,也就是mac core和dma的工作时钟肯定是不同。 FIFO由外部的一个two-ports RAM提供,一个port连接dma的clk和data,一个port连接mac core的clk和data。所以FIFO性能决定于dma和mac core的性能,它应该不会主动影响网络性能。
(5)dma模块 dma模块完成了mac跟系统内存之间的数据传输。其工作时钟的高低会影响dma的搬运性能。 但是由于mac内部dma是只进行网络数据搬运,没有其他数据通道,即使其clk比ddr cpu低,其也可能完全满足对于最大带宽的要求。 这个可以通过改变dma clk来看其对网络性能的影响来进行判断。 如果测试发现网络性能受到dma影响,可以采用提高emac的dma clk方式来提高网络性能。
(6)ddr内存 ddr的带宽对网络性能也是有影响的。 mac的dma跟内存进行数据搬运,dma是设备具有的一种仲裁能力,设备具有这种仲裁能力,能够抢占总线,获取总线的控制权,直接完成对内存的读写操作。 如果有多个设备对内存发起读写,如cpu mac dc等,这些主设备来抢占总线控制权,在同一个时刻,只能有一个设备获取总线控制权,对内存读写。 内存带宽指的是内存的数据位宽X内存频率,就是1s的数据传输量。 对于软件来说数据位宽是硬件做死,可以通过提高内存频率,也就是让3个主设备在1s内有可以获取到更多的次数的总线控制权,来提高网络性能。 也可以分析哪些设备在进行内存读写,将一些暂时不用的设备disable。 如何来确定内存是否对当前网络性能有影响,还是采用数据通路上其他模块不变,修改ddr clk,看对网络性能是否有影响来判断。
(7)cpu 根据我之前的性能测试记录,cpu性能对嵌入式设备网络性能影响最大。 可以想象,cpu因为要进行多任务切换,还要处理大量异步中断。在我的测试环境下cpu 800MHZ + ddr 800MHZ +dma 4000MHZ,性能影响最大就是cpu。 我们可以进行一个计算。在1000M环境下,假设外部网络速度 ddr性能 dma性能都达到峰值,给到ddr中的数据速率是125MB/s。 mac的dma intr模块是按照一数据包一中断进行设计,按照网络最大MTU计算,一个数据包在1500 bytes左右。 那么125MB/s就应该产生: 125X1024X1024/1500 = 89478 intr/s 一秒钟产生8.9万个intr,这还只是接收数据intr,还不包括发送请求intr和一些控制数据intr。 那么这些intr对于cpu来说处理的过来吗,根据我的实际测试,arm A8处理器800MHZ,实际处理的网络intr只有1.9万左右每秒。 因为mac driver中采用的是遍历整个dma的描述符链表,将所有数据包收下,所以这保证了在丢中断的情况并不会发生丢数据的现象。 但这还是说明了cpu过载。 这里cpu过载的原因,cpu频率是一个原因,提高cpu的clk肯定是有作用的。其次,其他外设intr,这个是不可避免的。最后,很重要的一点就是复杂的网络协议栈处理,在收到数据后,cpu还需要对数据包进行拆封,层层剥离。 这里我也就可以理解现在一些硬件协议栈处理模块以及网上大牛对于网络协议栈优化的初衷了,都是因为嵌入式设备cpu性能不够啊!
(8)app 上面已经将整个数据流程中硬件模块分析完了,但是在实际应用中我却发现,对于同样的网络环境,设备。使用不同的工具,所测试出来的速度是不同的。这是什么原因,我想到了下面这一点。 假设我们的网络环境非常好,设备ddr dma cpu性能足够,1000M带宽下可以达到12.5MB/s下载速度。但是要注意,这个12.5MB/s必须要保证我的测试程序完全占有cpu进行数据传输才可能达到的速度。 而对于跑在kernel之上的app,是不可能完全占有cpu的,kernel进行进程调度,如果系统中有10个进程,我们的下载测试程序,在1s内也只能有1/10s进行下载。 这我就可以理解不同测试工具测试速度的差别了,单进程程序下载速度肯定是要慢于多进程程序的下载速度,因为多进程测试程序对于cpu的占有率更高。
以上纯属个人实验总结分析,才疏学浅,不足之处敬请大家指正,共同学习进步。
对于嵌入式设备,测试网络性能一般是看从局域网内的PC服务器上下载上传数据速度。这里我们假设对端设备(PC服务器)性能够高,可以达到最大带宽。 分析影响网络性能因素,以下载为例,我的想法,可以从数据整个的流程来分析,就像一条河流,判断最终水流速度受哪些影响,可以看水流经过的地段哪里宽哪里窄。 (以下分析都假设是在1000M带宽网络环境中,使用1000M phy和1000M mac,mac是synopsys的gmac) 在数据下载中,数据的流程图如下:
从数据由对端设备发出,按照先后顺序我们来分析,对于网络性能的影响因素: (1)局域网网络状况 数据由对端设备到测试设备可能会经过很多个路由器,如果当前局域网网络状况差,数据量大,路由器转发负载比较大,就有可能造成我们下载数据转发慢,在该环节影响我们的网络性能。 如果想要一个理想网络环境的性能测试,获取一个可以达到的最大性能,可以采用测试设备与对端设备直连的方式,排除局域网能其他设备数据包的影响。
(2)phy芯片 phy作为OSI网络模型的最底物理层,是一个数据收发器。phy不存在性能问题,这一点我问过一些phy芯片技术支持,只要提供给phy正确的工作时钟(GMII 125MHZ,MII 25MHZ,RMII 50MHZ) 它就可以达到它所支持的最大带宽,也就是说对于phy只有通或者不通,而没有快慢问题。
(3)mac core模块 mac控制器内部逻辑中跟数据收发相关的模块有3个:mac core,mtl, dma。 mac core部分功能在于提供与phy芯片相连的接口,在phy完成自动协商后,软件上会根据phy的协商状态来配置mac core,如配置其工作模式(GMII MII RMII),数据包过滤模式,流控,CRC校验,传输调度(Rx/Tx优先级)等。 mac core在与phy配合正确配置后,与phy类似,就可以达到其所支持的最大带宽,只有通或者不通,而没有快慢。 所以mac core不会对网络性能造成影响。 这里有一点需要记录下,之前有同事说对于工作在GMII模式下的phy与mac core,就一定要供125MHZ时钟嘛,低一点,速率是不是低一点也可以工作。 这个是不行的。最简单答案就是协议规定GMII的phy mac clk必须为125MHZ。 其实仔细想想,原因也简单,数据传输的clk很重要的作用是来保证其采样正确性,如果两端clk不一致,一端的数据采样肯定就不对了。
(4)mtl模块 mtl是mac内部的传输层,mtl提供了2个FIFO在mac core和dma之间,Rx FIFO和Tx FIFO。在mac core和dma之间起到缓冲区作用,因为mac core和dma是不同的时钟域,也就是mac core和dma的工作时钟肯定是不同。 FIFO由外部的一个two-ports RAM提供,一个port连接dma的clk和data,一个port连接mac core的clk和data。所以FIFO性能决定于dma和mac core的性能,它应该不会主动影响网络性能。
(5)dma模块 dma模块完成了mac跟系统内存之间的数据传输。其工作时钟的高低会影响dma的搬运性能。 但是由于mac内部dma是只进行网络数据搬运,没有其他数据通道,即使其clk比ddr cpu低,其也可能完全满足对于最大带宽的要求。 这个可以通过改变dma clk来看其对网络性能的影响来进行判断。 如果测试发现网络性能受到dma影响,可以采用提高emac的dma clk方式来提高网络性能。
(6)ddr内存 ddr的带宽对网络性能也是有影响的。 mac的dma跟内存进行数据搬运,dma是设备具有的一种仲裁能力,设备具有这种仲裁能力,能够抢占总线,获取总线的控制权,直接完成对内存的读写操作。 如果有多个设备对内存发起读写,如cpu mac dc等,这些主设备来抢占总线控制权,在同一个时刻,只能有一个设备获取总线控制权,对内存读写。 内存带宽指的是内存的数据位宽X内存频率,就是1s的数据传输量。 对于软件来说数据位宽是硬件做死,可以通过提高内存频率,也就是让3个主设备在1s内有可以获取到更多的次数的总线控制权,来提高网络性能。 也可以分析哪些设备在进行内存读写,将一些暂时不用的设备disable。 如何来确定内存是否对当前网络性能有影响,还是采用数据通路上其他模块不变,修改ddr clk,看对网络性能是否有影响来判断。
(7)cpu 根据我之前的性能测试记录,cpu性能对嵌入式设备网络性能影响最大。 可以想象,cpu因为要进行多任务切换,还要处理大量异步中断。在我的测试环境下cpu 800MHZ + ddr 800MHZ +dma 4000MHZ,性能影响最大就是cpu。 我们可以进行一个计算。在1000M环境下,假设外部网络速度 ddr性能 dma性能都达到峰值,给到ddr中的数据速率是125MB/s。 mac的dma intr模块是按照一数据包一中断进行设计,按照网络最大MTU计算,一个数据包在1500 bytes左右。 那么125MB/s就应该产生: 125X1024X1024/1500 = 89478 intr/s 一秒钟产生8.9万个intr,这还只是接收数据intr,还不包括发送请求intr和一些控制数据intr。 那么这些intr对于cpu来说处理的过来吗,根据我的实际测试,arm A8处理器800MHZ,实际处理的网络intr只有1.9万左右每秒。 因为mac driver中采用的是遍历整个dma的描述符链表,将所有数据包收下,所以这保证了在丢中断的情况并不会发生丢数据的现象。 但这还是说明了cpu过载。 这里cpu过载的原因,cpu频率是一个原因,提高cpu的clk肯定是有作用的。其次,其他外设intr,这个是不可避免的。最后,很重要的一点就是复杂的网络协议栈处理,在收到数据后,cpu还需要对数据包进行拆封,层层剥离。 这里我也就可以理解现在一些硬件协议栈处理模块以及网上大牛对于网络协议栈优化的初衷了,都是因为嵌入式设备cpu性能不够啊!
(8)app 上面已经将整个数据流程中硬件模块分析完了,但是在实际应用中我却发现,对于同样的网络环境,设备。使用不同的工具,所测试出来的速度是不同的。这是什么原因,我想到了下面这一点。 假设我们的网络环境非常好,设备ddr dma cpu性能足够,1000M带宽下可以达到12.5MB/s下载速度。但是要注意,这个12.5MB/s必须要保证我的测试程序完全占有cpu进行数据传输才可能达到的速度。 而对于跑在kernel之上的app,是不可能完全占有cpu的,kernel进行进程调度,如果系统中有10个进程,我们的下载测试程序,在1s内也只能有1/10s进行下载。 这我就可以理解不同测试工具测试速度的差别了,单进程程序下载速度肯定是要慢于多进程程序的下载速度,因为多进程测试程序对于cpu的占有率更高。
以上纯属个人实验总结分析,才疏学浅,不足之处敬请大家指正,共同学习进步。