{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 loadinghl 的文章《U-Boot启动过程--详细版的完全分析》','https://www.xiaopingtou.net/article-71155.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
我们知道,bootloader是系统上电后最初加载运行的代码。它提供了处理器上电复位后最开始需要执行的初始化代码。 在PC机上引导程序一般由BIOS开始执行,然后读取硬盘中位于MBR(Main Boot Record,主引导记录)中的Bootloader(例如LILO或GRUB),并进一步引导操作系统的启动。 然而在嵌入式系统中通常没有像BIOS那样的固件程序,因此整个系统的加载启动就完全由bootloader来完成。它主要的功能是加载与引导内核映像 一个嵌入式的存储设备通过通常包括四个分区:第一分区:存放的当然是u-boot第二个分区:存放着u-boot要传给系统内核的参数第三个分区:是系统内核(kernel)第四个分区:则是根文件系统如下图所示: -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- u-boot是一种普遍用于嵌入式系统中的Bootloader。Bootloader介绍Bootloader是进行嵌入式开发必然会接触的一个概念,它是嵌入式学院<嵌入式工程师职业培训班>二期课程中嵌入式linux系统开发方面的重要内容。本篇文章主要讲解Bootloader的基本概念以及内部原理,这部分内容的掌握将对嵌入式linux系统开发的学习非常有帮助!Bootloader的定义:Bootloader是在操作系统运行之前执行的一小段程序,通过这一小段程序,我们可以初始化硬件设备、建立内存空间的映射表,从而建立适当的系统软硬件环境,为最终调用操作系统内核做好准备。意思就是说如果我们要想让一个操作系统在我们的板子上运转起来,我们就必须首先对我们的板子进行一些基本配置和初始化,然后才可以将操作系统引导进来运行。具体在Bootloader中完成了哪些操作我们会在后面分析到,这里我们先来回忆一下PC的体系结构:PC机中的引导加载程序是由BIOS和位于硬盘MBR中的OS Boot Loader(比如LILO和GRUB等)一起组成的,BIOS在完成硬件检测和资源分配后,将硬盘MBR中的Boot Loader读到系统的RAM中,然后将控制权交给OS Boot Loader。Boot Loader的主要运行任务就是将内核映象从硬盘上读到RAM中,然后跳转到内核的入口点去运行,即开始启动操作系统。在嵌入式系统中,通常并没有像BIOS那样的固件程序(注:有的嵌入式cpu也会内嵌一段短小的启动程序),因此整个系统的加载启动任务就完全由Boot Loader来完成。比如在一个基于ARM7TDMI core的嵌入式系统中,系统在上电或复位时通常都从地址0x00000000处开始执行,而在这个地址处安排的通常就是系统的Boot Loader程序。(先想一下,通用PC和嵌入式系统为何会在此处存在如此的差异呢?)Bootloader是基于特定硬件平台来实现的,因此几乎不可能为所有的嵌入式系统建立一个通用的Bootloader,不同的处理器架构都有不同的Bootloader,Bootloader不但依赖于cpu的体系结构,还依赖于嵌入式系统板级设备的配置。对于2块不同的板子而言,即使他们使用的是相同的处理器,要想让运行在一块板子上的Bootloader程序也能运行在另一块板子上,一般也需要修改Bootloader的源程序。Bootloader的启动方式Bootloader的启动方式主要有网络启动方式、磁盘启动方式和Flash启动方式。1、网络启动方式
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- u-boot是一种普遍用于嵌入式系统中的Bootloader。Bootloader介绍Bootloader是进行嵌入式开发必然会接触的一个概念,它是嵌入式学院<嵌入式工程师职业培训班>二期课程中嵌入式linux系统开发方面的重要内容。本篇文章主要讲解Bootloader的基本概念以及内部原理,这部分内容的掌握将对嵌入式linux系统开发的学习非常有帮助!Bootloader的定义:Bootloader是在操作系统运行之前执行的一小段程序,通过这一小段程序,我们可以初始化硬件设备、建立内存空间的映射表,从而建立适当的系统软硬件环境,为最终调用操作系统内核做好准备。意思就是说如果我们要想让一个操作系统在我们的板子上运转起来,我们就必须首先对我们的板子进行一些基本配置和初始化,然后才可以将操作系统引导进来运行。具体在Bootloader中完成了哪些操作我们会在后面分析到,这里我们先来回忆一下PC的体系结构:PC机中的引导加载程序是由BIOS和位于硬盘MBR中的OS Boot Loader(比如LILO和GRUB等)一起组成的,BIOS在完成硬件检测和资源分配后,将硬盘MBR中的Boot Loader读到系统的RAM中,然后将控制权交给OS Boot Loader。Boot Loader的主要运行任务就是将内核映象从硬盘上读到RAM中,然后跳转到内核的入口点去运行,即开始启动操作系统。在嵌入式系统中,通常并没有像BIOS那样的固件程序(注:有的嵌入式cpu也会内嵌一段短小的启动程序),因此整个系统的加载启动任务就完全由Boot Loader来完成。比如在一个基于ARM7TDMI core的嵌入式系统中,系统在上电或复位时通常都从地址0x00000000处开始执行,而在这个地址处安排的通常就是系统的Boot Loader程序。(先想一下,通用PC和嵌入式系统为何会在此处存在如此的差异呢?)Bootloader是基于特定硬件平台来实现的,因此几乎不可能为所有的嵌入式系统建立一个通用的Bootloader,不同的处理器架构都有不同的Bootloader,Bootloader不但依赖于cpu的体系结构,还依赖于嵌入式系统板级设备的配置。对于2块不同的板子而言,即使他们使用的是相同的处理器,要想让运行在一块板子上的Bootloader程序也能运行在另一块板子上,一般也需要修改Bootloader的源程序。Bootloader的启动方式Bootloader的启动方式主要有网络启动方式、磁盘启动方式和Flash启动方式。1、网络启动方式 
图1 Bootloader网络启动方式示意图如图1所示,里面主机和目标板,他们中间通过网络来连接,首先目标板的DHCP/BIOS通过BOOTP服务来为Bootloader分配IP地址,配置网络参数,这样才能支持网络传输功能。我们使用的u-boot可以直接设置网络参数,因此这里就不用使用DHCP的方式动态分配IP了。接下来目标板的Bootloader通过TFTP服务将内核映像下载到目标板上,然后通过网络文件系统来建立主机与目标板之间的文件通信过程,之后的系统更新通常也是使用Boot Loader的这种工作模式。工作于这种模式下的Boot Loader通常都会向它的终端用户提供一个简单的命令行接口。2、磁盘启动方式这种方式主要是用在台式机和服务器上的,这些计算机都使用BIOS引导,并且使用磁盘作为存储介质,这里面两个重要的用来启动linux的有LILO和GRUB,这里就不再具体说明了。3、Flash启动方式这是我们最常用的方式。Flash有NOR Flash和NAND Flash两种。NOR Flash可以支持随机访问,所以代码可以直接在Flash上执行,Bootloader一般是存储在Flash芯片上的。另外Flash上还存储着参数、内核映像和文件系统。这种启动方式与网络启动方式之间的不同之处就在于,在网络启动方式中,内核映像和文件系统首先是放在主机上的,然后经过网络传输下载进目标板的,而这种启动方式中内核映像和文件系统则直接是放在Flash中的,这两点在我们u-boot的使用过程中都用到了。U-boot的定义U-boot,全称Universal Boot Loader,是由DENX小组的开发的遵循GPL条款的开放源码项目,它的主要功能是完成硬件设备初始化、操作系统代码搬运,并提供一个控制台及一个指令集在操作系统运行前操控硬件设备。U-boot之所以这么通用,原因是他具有很多特点:开放源代码、支持多种嵌入式操作系统内核、支持多种处理器系列、较高的稳定性、高度灵活的功能设置、丰富的设备驱动源码以及较为丰富的开发调试文档与强大的网络技术支持。另外u-boot对操作系统和产品研发提供了灵活丰富的支持,主要表现在:可以引导压缩或非压缩系统内核,可以灵活设置/传递多个关键参数给操作系统,适合系统在不同开发阶段的调试要求与产品发布,支持多种文件系统,支持多种目标板环境参数存储介质,采用CRC32校验,可校验内核及镜像文件是否完好,提供多种控制台接口,使用户可以在不需要ICE的情况下通过串口/以太网/USB等接口下载数据并烧录到存储设备中去(这个功能在实际的产品中是很实用的,尤其是在软件现场升级的时候),以及提供丰富的设备驱动等。u-boot源代码的目录结构1、board中存放于开发板相关的配置文件,每一个开发板都以子文件夹的形式出现。2、Commom文件夹实现u-boot行下支持的命令,每一个命令对应一个文件。3、cpu中存放特定cpu架构相关的目录,每一款cpu架构都对应了一个子目录。4、Doc是文档目录,有u-boot非常完善的文档。5、Drivers中是u-boot支持的各种设备的驱动程序。6、Fs是支持的文件系统,其中最常用的是JFFS2文件系统。7、Include文件夹是u-boot使用的头文件,还有各种硬件平台支持的汇编文件,系统配置文件和文件系统支持的文件。8、Net是与网络协议相关的代码,bootp协议、TFTP协议、NFS文件系统得实现。9、Tooles是生成U-boot的工具。对u-boot的目录有了一些了解后,分析启动代码的过程就方便多了,其中比较重要的目录就是/board、/cpu、/drivers和/include目录,如果想实现u-boot在一个平台上的移植,就要对这些目录进行深入的分析。-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 什么是《编译地址》?什么是《运行地址》?(一)编译地址: 32位的处理器,它的每一条指令是4个字节,以4个字节存储顺序,进行顺序执行,CPU是顺序执行的,只要没发生什么跳转,它会顺序进行执行行, 编译器会对每一条指令分配一个编译地址,这是编译器分配的,在编译过程中分配的地址,我们称之为编译地址。
(二)运行地址:是指程序指令真正运行的地址,是由用户指定的,用户将运行地址烧录到哪里,哪里就是运行的地址。 比如有一个指令的编译地址是0x5,实际运行的地址是0x200,如果用户将指令烧到0x200上,那么这条指令的运行地址就是0x200, 当编译地址和运行地址不同的时候会出现什么结果?结果是不能跳转,编译后会产生跳转地址,如果实际地址和编译后产生的地址不相等,那么就不能跳转。 C语言编译地址:都希望把编译地址和实际运行地址放在一起的,但是汇编代码因为不需要做C语言到汇编的转换,可以认为的去写地址,所以直接写的就是他的运行地址这就是为什么任何bootloader刚开始会有一段汇编代码,因为起始代码编译地址和实际地址不相等,这段代码和汇编无关,跳转用的运行地址。 编译地址和运行地址如何来算呢? 1. 假如有两个编译地址a=0x10,b=0x7,b的运行地址是0x300,那么a的运行地址就是b的运行地址加上两者编译地址的差值,a-b=0x10-0x7=0x3, a的运行地址就是0x300+0x3=0x303。
2. 假设uboot上两条指令的编译地址为a=0x33000007和b=0x33000001,这两条指令都落在bank6上,现在要计算出他们对应的运行地址,要找出运行地址的始地址,这个是由用户烧录进去的,假设运行地址的首地址是0x0,则a的运行地址为0x7,b为0x1,就是这样算出来的。
为什么要分配编译地址?这样做有什么好处,有什么作用?
比如在函数a中定义了函数b,当执行到函数b时要进行指令跳转,要跳转到b函数所对应的起始地址上去,编译时,编译器给每条指令都分配了编译地址,如果编译器已经给分配了地址就可以直接进行跳转,查找b函数跳转指令所对应的表,进行直接跳转,因为有个编译地址和指令对应的一个表,如果没有分配,编译器就查找不到这个跳转地址,要进行计算,非常麻烦。
什么是《相对地址》?
以NOR Flash为例,NOR Falsh是映射到bank0上面,SDRAM是映射到bank6上面,uboot和内核最终是在SDRAM上面运行,最开始我们是从Nor Flash的零地址开始往后烧录,uboot中至少有一段代码编译地址和运行地址是不一样的,编译uboot或内核时,都会将编译地址放入到SDRAM中,他们最终都会在SDRAM中执行,刚开始uboot在Nor Flash中运行,运行地址是一个低端地址,是bank0中的一个地址,但编译地址是bank6中的地址,这样就会导致绝对跳转指令执行的失败,所以就引出了相对地址的概念。 那么什么是相对地址呢? 至少在bank0中uboot这段代码要知道不能用b+编译地址这样的方法去跳转指令,因为这段代码的编译地址和运行地址不一样,那如何去做呢? 要去计算这个指令运行的真实地址,计算出来后再做跳转,应该是b+运行地址,不能出现b+编译地址,而是b+运行地址,而运行地址是算出来的。
_TEXT_BASE:
.word TEXT_BASE //0x33F80000,在board/config.mk中
这段话表示,用户告诉编译器编译地址的起始地址
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- U-Boot工作过程 大多数 Boot Loader 都包含两种不同的操作模式:"启动加载"模式和"下载"模式,这种区别仅对于开发人员才有意义。 但从最终用户的角度看,Boot Loader 的作用就是:用来加载操作系统,而并不存在所谓的启动加载模式与下载工作模式的区别。
(一)启动加载(Boot loading)模式:这种模式也称为"自主"(Autonomous)模式。 也即 Boot Loader 从目标机上的某个固态存储设备上将操作系统加载到 RAM 中运行,整个过程并没有用户的介入。 这种模式是 Boot Loader 的正常工作模式,因此在嵌入式产品发布的时侯,Boot Loader 显然必须工作在这种模式下。
(二)下载(Downloading)模式:在这种模式下,目标机上的 Boot Loader 将通过串口连接或网络连接等通信手段从主机(Host)下载文件,比如:下载内核映像和根文件系统映像等。从主机下载的文件通常首先被 Boot Loader保存到目标机的RAM中,然后再被 BootLoader写到目标机上的FLASH类固态存储设备中。Boot Loader 的这种模式通常在第一次安装内核与根文件系统时被使用;此外,以后的系统更新也会使用 Boot Loader 的这种工作模式。工作于这种模式下的 Boot Loader 通常都会向它的终端用户提供一个简单的命令行接口。这种工作模式通常在第一次安装内核与跟文件系统时使用。或者在系统更新时使用。进行嵌入式系统调试时一般也让bootloader工作在这一模式下。
UBoot 这样功能强大的 Boot Loader 同时支持这两种工作模式,而且允许用户在这两种工作模式之间进行切换。 大多数 bootloader 都分为阶段 1(stage1)和阶段 2(stage2)两大部分,uboot 也不例外。依赖于 CPU 体系结构的代码(如 CPU 初始化代码等)通常都放在阶段 1 中且通常用汇编语言实现,而阶段 2 则通常用 C 语言来实现,这样可以实现复杂的功能,而且有更好的可读性和移植性。
-------------------------------------------------------------------------------------------------------------------------------------------第一、大概总结性得的分析 系统启动的入口点。既然我们现在要分析u-boot的启动过程,就必须先找到u-boot最先实现的是哪些代码,最先完成的是哪些任务。 另一方面一个可执行的image必须有一个入口点,并且只能有一个全局入口点,所以要通知编译器这个入口在哪里。由此我们可以找到程序的入口点是在/board/lpc2210/u-boot.lds中指定的,其中ENTRY(_start)说明程序从_start开始运行,而他指向的是cpu/arm7tdmi/start.o文件。因为我们用的是ARM7TDMI的cpu架构,在复位后从地址0x00000000取它的第一条指令,所以我们将Flash映射到这个地址上,这样在系统加电后,cpu将首先执行u-boot程序。u-boot的启动过程是多阶段实现的,分了两个阶段。依赖于cpu体系结构的代码(如设备初始化代码等)通常都放在stage1中,而且通常都是用汇编语言来实现,以达到短小精悍的目的。而stage2则通常是用C语言来实现的,这样可以实现复杂的功能,而且代码具有更好的可读性和可移植性。下面我们先详细分析下stage1中的代码,如图2所示: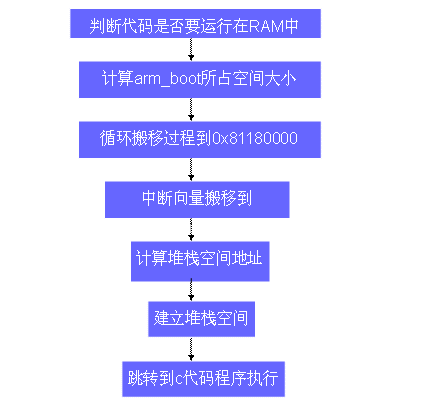
图2 Start.s程序流程 代码真正开始是在_start,设置异常向量表,这样在cpu发生异常时就跳转到/cpu/arm7tdmi/interrupts中去执行相应得中断代码。 在interrupts文件中大部分的异常代码都没有实现具体的功能,只是打印一些异常消息,其中关键的是reset中断代码,跳到reset入口地址。 reset复位入口之前有一些段的声明。 1.在reset中,首先是将cpu设置为svc32模式下,并屏蔽所有irq和fiq。 2.在u-boot中除了定时器使用了中断外,其他的基本上都不需要使用中断,比如串口通信和网络等通信等,在u-boot中只要完成一些简单的通信就可以了,所以在这里屏蔽掉了所有的中断响应。 3.初始化外部总线。这部分首先设置了I/O口功能,包括串口、网络接口等的设置,其他I/O口都设置为GPIO。然后设置BCFG0~BCFG3,即外部总线控制器。这里bank0对应Flash,设置为16位宽度,总线速度设为最慢,以实现稳定的操作;Bank1对应DRAM,设置和Flash相同;Bank2对应RTL8019。 4.接下来是cpu关键设置,包括系统重映射(告诉处理器在系统发生中断的时候到外部存储器中去读取中断向量表)和系统频率。 5.lowlevel_init,设定RAM的时序,并将中断控制器清零。这些部分和特定的平台有关,但大致的流程都是一样的。 下面就是代码的搬移阶段了。为了获得更快的执行速度, 通常把stage2加载到RAM空间中来执行,因此必须为加载Boot Loader的stage2准备好一段可用的RAM空间范围。空间大小最好是memory page大小(通常是4KB)的倍数 一般而言,1M的RAM空间已经足够了。 flash中存储的u-boot可执行文件中,代码段、数据段以及BSS段都是首尾相连存储的, 所以在计算搬移大小的时候就是利用了用BSS段的首地址减去代码的首地址,这样算出来的就是实际使用的空间。 程序用一个循环将代码搬移到0x81180000,即RAM底端1M空间用来存储代码。 然后程序继续将中断向量表搬到RAM的顶端。由于stage2通常是C语言执行代码,所以还要建立堆栈去。 在堆栈区之前还要将malloc分配的空间以及全局数据所需的空间空下来,他们的大小是由宏定义给出的,可以在相应位置修改。基本内存分布图: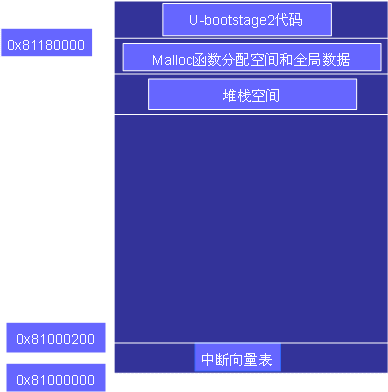
图3 搬移后内存分布情况图 下来是u-boot启动的第二个阶段,是用c代码写的, 这部分是一些相对变化不大的部分,我们针对不同的板子改变它调用的一些初始化函数,并且通过设置一些宏定义来改变初始化的流程, 所以这些代码在移植的过程中并不需要修改,也是错误相对较少出现的文件。 在文件的开始先是定义了一个函数指针数组,通过这个数组,程序通过一个循环来按顺序进行常规的初始化,并在其后通过一些宏定义来初始化一些特定的设备。 在最后程序进入一个循环,main_loop。这个循环接收用户输入的命令,以设置参数或者进行启动引导。本篇文章将分析重点放在了前面的start.s上,是因为这部分无论在移植还是在调试过程中都是最容易出问题的地方,要解决问题就需要程序员对代码进行修改,所以在这里简单介绍了一下start.s的基本流程,希望能对大家有所帮助--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------第二、代码分析 2.2 阶段 1 介绍
uboot 的 stage1 代码通常放在 start.s 文件中,它用汇编语言写成,其主要代码部分如下:
2.2.1 定义入口
由于一个可执行的 Image 必须有一个入口点,并且只能有一个全局入口,通常这个入口放在 ROM(Flash)的 0x0
地址,因此,必须通知编译器以使其知道这个入口,该工作可通过修改连接器脚本来完成。
1. board/crane2410/uboot.lds: ENTRY(_start) ==> cpu/arm920t/start.S: .globl _start
2. uboot 代码区(TEXT_BASE = 0x33F80000)定义在 board/crane2410/config.mkU-Boot启动内核的过程可以分为两个阶段,两个阶段的功能如下: (1)第一阶段的功能Ø 硬件设备初始化Ø 加载U-Boot第二阶段代码到RAM空间Ø 设置好栈Ø 跳转到第二阶段代码入口 (2)第二阶段的功能Ø 初始化本阶段使用的硬件设备Ø 检测系统内存映射Ø 将内核从Flash读取到RAM中Ø 为内核设置启动参数Ø 调用内核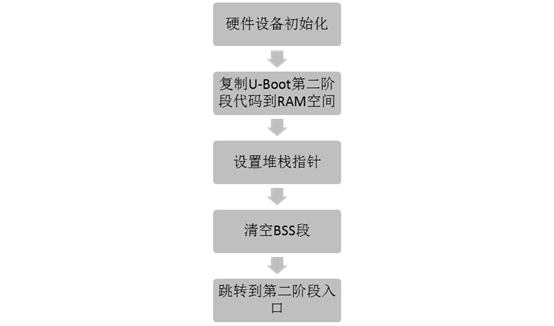 详细分析图 2.1 U-Boot启动第一阶段流程 根据cpu/arm920t/u-boot.lds中指定的连接方式: 看一下uboot.lds文件,在board/smdk2410目录下面,uboot.lds是告诉编译器这些段改怎么划分,GUN编译过的段,最基本的三个段是RO,RW,ZI,RO表示只读,对应于具体的指代码段,RW是数据段,ZI是归零段,就是全局变量的那段。Uboot代码这么多,如何保证start.s会第一个执行,编译在最开始呢?就是通过uboot.lds链接文件进行
详细分析图 2.1 U-Boot启动第一阶段流程 根据cpu/arm920t/u-boot.lds中指定的连接方式: 看一下uboot.lds文件,在board/smdk2410目录下面,uboot.lds是告诉编译器这些段改怎么划分,GUN编译过的段,最基本的三个段是RO,RW,ZI,RO表示只读,对应于具体的指代码段,RW是数据段,ZI是归零段,就是全局变量的那段。Uboot代码这么多,如何保证start.s会第一个执行,编译在最开始呢?就是通过uboot.lds链接文件进行
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
/*OUTPUT_FORMAT("elf32-arm", "elf32-arm", "elf32-arm")*/
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x00000000; //起始地址
. = ALIGN(4); //4字节对齐
.text : //test指代码段,上面3行标识是不占用任何空间的
{
cpu/arm920t/start.o (.text) //这里把start.o放在第一位就表示把start.s编
译时放到最开始,这就是为什么把uboot烧到起始地址上它肯定运行的是start.s
*(.text)
}
. = ALIGN(4); //前面的 “.” 代表当前值,是计算一个当前的值,是计算上
面占用的整个空间,再加一个单元就表示它现在的位置
.rodata : { *(.rodata) }
. = ALIGN(4);
.data : { *(.data) }
. = ALIGN(4);
.got : { *(.got) }
. = .;
__u_boot_cmd_start = .;
.u_boot_cmd : { *(.u_boot_cmd) }
__u_boot_cmd_end = .;
. = ALIGN(4);
__bss_start = .; //bss表示归零段
.bss : { *(.bss) }
_end = .;
}
第一个链接的是cpu/arm920t/start.o,因此u-boot.bin的入口代码在cpu/arm920t/start.o中,其源代码在cpu/arm920t/start.S中。下面我们来分析cpu/arm920t/start.S的执行。1. 硬件设备初始化(1)设置异常向量 下面代码是系统启动后U-boot上电后运行的第一段代码,它是什么意思? u-boot对应的第一阶段代码放在cpu/arm920t/start.S文件中,入口代码如下:.globl _startglobal /*声明一个符号可被其它文件引用,相当于声明了一个全局变量,.globl与.global相同*/_start: b start_code /* 复位 */b是不带返回的跳转(bl是带返回的跳转),意思是无条件直接跳转到start_code标号出执行程序 ldr pc, _undefined_instruction /* 未定义指令向量 l---dr相当于mov操作*/ ldr pc, _software_interrupt /* 软件中断向量 */ ldr pc, _prefetch_abort /* 预取指令异常向量 */ ldr pc, _data_abort /* 数据操作异常向量 */ ldr pc, _not_used /* 未使用 */ ldr pc, _irq /* irq中断向量 */ ldr pc, _fiq /* fiq中断向量 *//* 中断向量表入口地址 */_undefined_instruction: .word undefined_instruction /*就是在当前地址,即_undefined_instruction 处存放 undefined_instruction*/_software_interrupt: .word software_interrupt_prefetch_abort: .word prefetch_abort_data_abort: .word data_abort_not_used: .word not_used_irq: .word irq_fiq: .word fiq word伪操作用于分配一段字内存单元(分配的单元都是字对齐的),并用伪操作中的expr初始化 .balignl 16,0xdeadbeef 他们是系统定义的异常,一上电程序跳转到start_code异常处执行相应的汇编指令,下面定义出的都是不同的异常,比如软件发生软中断时,CPU就会去执行软中断的指令,这些异常中断在CUP中地址是从0开始,每个异常占4个字节 ldr pc, _undefined_instruction表示把_undefined_instruction存放的数值存放到pc指针上 _undefined_instruction: .word undefined_instruction表示未定义的这个异常是由.word来定义的,它表示定义一个字,一个32位的数. word后面的数:表示把该标识的编译地址写入当前地址,标识是不占用任何指令的。把标识存放的数值copy到指针pc上面,那么标识上存放的值是什么?是由.word undefined_instruction来指定的,pc就代表你运行代码的地址,她就实现了CPU要做一次跳转时的工作。
以上代码设置了ARM异常向量表,各个异常向量介绍如下:表 2.1 ARM异常向量表 地址 异常 进入模式描述0x00000000 复位 管理模式 复位电平有效时,产生复位异常,程序跳转到复位处理程序处执行0x00000004 未定义指令 未定义模式 遇到不能处理的指令时,产生未定义指令异常0x00000008软件中断 管理模式 执行SWI指令产生,用于用户模式下的程序调用特权操作指令0x0000000c预存指令 中止模式 处理器预取指令的地址不存在,或该地址不允许当前指令访问,产生指令预取中止异常0x00000010数据操作 中止模式 处理器数据访问指令的地址不存在,或该地址不允许当前指令访问时,产生数据中止异常0x00000014未使用 未使用 未使用0x00000018IRQ IRQ 外部中断请求有效,且CPSR中的I位为0时,产生IRQ异常0x0000001cFIQ FIQ 快速中断请求引脚有效,且CPSR中的F位为0时,产生FIQ异常 在cpu/arm920t/start.S中还有这些异常对应的异常处理程序。当一个异常产生时,CPU根据异常号在异常向量表中找到对应的异常向量,然后执行异常向量处的跳转指令,CPU就跳转到对应的异常处理程序执行。 其中复位异常向量的指令“b start_code”决定了U-Boot启动后将自动跳转到标号“start_code”处执行。(2)CPU进入SVC模式start_code: /* * set the cpu to SVC32 mode */ mrs r0, cpsr bic r0, r0, #0x1f /*工作模式位清零 */ orr r0, r0, #0xd3 /*工作模式位设置为“10011”(管理模式),并将中断禁止位和快中断禁止位置1 */ msr cpsr, r0 以上代码将CPU的工作模式位设置为管理模式,即设置相应的CPSR程序状态字,并将中断禁止位和快中断禁止位置一,从而屏蔽了IRQ和FIQ中断。 操作系统先注册一个总的中断,然后去查是由哪个中断源产生的中断,再去查用户注册的中断表,查出来后就去执行用户定义的用户中断处理函数。
(3)设置控制寄存器地址# if defined(CONFIG_S3C2400) /*关闭看门狗*/
# define pWTCON 0x15300000 /*;看门狗寄存器*/
# define INTMSK 0x14400008 /*;中断屏蔽寄存器*/# define CLKDIVN 0x14800014 /*;时钟分频寄存器*/
#else /* s3c2410与s3c2440下面4个寄存器地址相同 */# define pWTCON 0x53000000 /* WATCHDOG控制寄存器地址 */# define INTMSK 0x4A000008 /* INTMSK寄存器地址 */# define INTSUBMSK 0x4A00001C /* INTSUBMSK寄存器地址 次级中断屏蔽寄存器*/# define CLKDIVN 0x4C000014 /* CLKDIVN寄存器地址 ;时钟分频寄存器*/# endif 对与s3c2440开发板,以上代码完成了WATCHDOG,INTMSK,INTSUBMSK,CLKDIVN四个寄存器的地址的设置。各个寄存器地址参见参考文献[4] 。(4)关闭看门狗 ldr r0, =pWTCON /*将pwtcon寄存器地址赋给R0*/ mov r1, #0x0 /*r1的内容为0*/
str r1, [r0] /* 看门狗控制器的最低位为0时,看门狗不输出复位信号 */ 以上代码向看门狗控制寄存器写入0,关闭看门狗。否则在U-Boot启动过程中,CPU将不断重启。为什么要关看门狗? 就是防止,不同得两个以上得CPU,进行喂狗的时间间隔问题:说白了,就是你运行的代码如果超出喂狗时间,而你不关狗,就会导致,你代码还没运行完又得去喂狗,就这样反复得重启CPU,那你代码永远也运行不完,所以,得先关看门狗得原因,就是这样。关狗---详细的原因: 关闭看门狗,关闭中断,所谓的喂狗是每隔一段时间给某个寄存器置位而已,在实际中会专门启动一个线程或进程会专门喂狗,当上层软件出现故障时就会停止喂狗, 停止喂狗之后,cpu会自动复位,一般都在外部专门有一个看门狗,做一个外部的电路,不在cpu内部使用看门狗,cpu内部的看门狗是复位的cpu 当开发板很复杂时,有好几个cpu时,就不能完全让板子复位,但我们通常都让整个板子复位。看门狗每隔短时间就会喂狗,问题是在两次喂狗之间的时间间隔内,运行的代码的时间是否够用,两次喂狗之间的代码是否在两次喂狗的时间延迟之内,如果在延迟之外的话,代码还没改完就又进行喂狗,代码永远也改不完(5)屏蔽中断 /* * mask all IRQs by setting all bits in the INTMR - default */ mov r1, #0xffffffff /*屏蔽所有中断, 某位被置1则对应的中断被屏蔽 */ /*寄存器中的值*/ ldr r0, =INTMSK /*将管理中断的寄存器地址赋给ro*/ str r1, [r0] /*将全r1的值赋给ro地址中的内容*/ INTMSK是主中断屏蔽寄存器,每一位对应SRCPND(中断源引脚寄存器)中的一位,表明SRCPND相应位代表的中断请求是否被CPU所处理。 根据参考文献4,INTMSK寄存器是一个32位的寄存器,每位对应一个中断,向其中写入0xffffffff就将INTMSK寄存器全部位置一,从而屏蔽对应的中断。# if defined(CONFIG_S3C2440) ldr r1, =0x7fff ldr r0, =INTSUBMSK str r1, [r0] # endif INTSUBMSK每一位对应SUBSRCPND中的一位,表明SUBSRCPND相应位代表的中断请求是否被CPU所处理。 根据参考文献4,INTSUBMSK寄存器是一个32位的寄存器,但是只使用了低15位。向其中写入0x7fff就是将INTSUBMSK寄存器全部有效位(低15位)置一,从而屏蔽对应的中断。屏蔽所有中断,为什么要关中断?中断处理中ldr pc是将代码的编译地址放在了指针上,而这段时间还没有搬移代码,所以编译地址上面没有这个代码,如果进行跳转就会跳转到空指针上面
(6)设置MPLLCON,UPLLCON, CLKDIVN# if defined(CONFIG_S3C2440) #define MPLLCON 0x4C000004#define UPLLCON 0x4C000008 ldr r0, =CLKDIVN ;设置时钟
mov r1, #5 str r1, [r0] ldr r0, =MPLLCON ldr r1, =0x7F021 str r1, [r0] ldr r0, =UPLLCON ldr r1, =0x38022 str r1, [r0]# else /* FCLK:HCLK:PCLK = 1:2:4 */ /* default FCLK is 120 MHz ! */ ldr r0, =CLKDIVN mov r1, #3 str r1, [r0]#endif CPU上电几毫秒后,晶振输出稳定,FCLK=Fin(晶振频率),CPU开始执行指令。但实际上,FCLK可以高于Fin,为了提高系统时钟,需要用软件来启用PLL。这就需要设置CLKDIVN,MPLLCON,UPLLCON这3个寄存器。 CLKDIVN寄存器用于设置FCLK,HCLK,PCLK三者间的比例,可以根据表2.2来设置。表 2.2 S3C2440 的CLKDIVN寄存器格式 CLKDIVN 位 说明 初始值 HDIVN[2:1] 00 : HCLK = FCLK/1. 01 : HCLK = FCLK/2. 10 : HCLK = FCLK/4 (当 CAMDIVN[9] = 0 时) HCLK= FCLK/8 (当 CAMDIVN[9] = 1 时) 11 : HCLK = FCLK/3 (当 CAMDIVN[8] = 0 时) HCLK = FCLK/6 (当 CAMDIVN[8] = 1时)00PDIVN[0]0: PCLK = HCLK/1 1: PCLK = HCLK/20 设置CLKDIVN为5,就将HDIVN设置为二进制的10,由于CAMDIVN[9]没有被改变过,取默认值0,因此HCLK = FCLK/4。PDIVN被设置为1,因此PCLK= HCLK/2。因此分频比FCLK:HCLK:PCLK = 1:4:8 。 MPLLCON寄存器用于设置FCLK与Fin的倍数。MPLLCON的位[19:12]称为MDIV,位[9:4]称为PDIV,位[1:0]称为SDIV。 对于S3C2440,FCLK与Fin的关系如下面公式: MPLL(FCLK) = (2×m×Fin)/(p× ) 其中: m=MDIC+8,p=PDIV+2,s=SDIV MPLLCON与UPLLCON的值可以根据参考文献4中“PLL VALUE SELECTION TABLE”设置。该表部分摘录如下:表 2.3 推荐PLL值 输入频率 输出频率 MDIV PDIV SDIV 12.0000MHz48.00 MHz56(0x38)2212.0000MHz405.00 MHz127(0x7f)21 当mini2440系统主频设置为405MHZ,USB时钟频率设置为48MHZ时,系统可以稳定运行,因此设置MPLLCON与UPLLCON为: MPLLCON=(0x7f<<12) | (0x02<<4) | (0x01) = 0x7f021 UPLLCON=(0x38<<12) | (0x02<<4) | (0x02) = 0x38022默认频率为 FCLK:HCLK:PCLK = 1:2:4,默认 FCLK 的值为 120 MHz,该值为 S3C2410 手册的推荐值。设置时钟分频,为什么要设置时钟?起始可以不设,系统能不能跑起来和频率没有任何关系,频率的设置是要让外围的设备能承受所设置的频率,如果频率过高则会导致cpu操作外围设备失败说白了:设置频率,就为了CPU能去操作外围设备(7)关闭MMU,cache ------(也就是做bank的设置)
接着往下看:#ifndef CONFIG_SKIP_LOWLEVEL_INIT bl cpu_init_crit /* ;跳转并把转移后面紧接的一条指令地址保存到链接寄存器LR(R14)中,以此来完成子程序的调用*/
#endif cpu_init_crit这段代码在U-Boot正常启动时才需要执行,若将U-Boot从RAM中启动则应该注释掉这段代码。 下面分析一下cpu_init_crit到底做了什么:320 #ifndef CONFIG_SKIP_LOWLEVEL_INIT321 cpu_init_crit:322 /*323 * 使数据cache与指令cache无效 */324 */ 325 mov r0, #0326 mcr p15, 0, r0, c7, c7, 0 /* 向c7写入0将使ICache与DCache无效*/327 mcr p15, 0, r0, c8, c7, 0 /* 向c8写入0将使TLB失效 ,协处理器*/
328 329 /*330 * disable MMU stuff and caches331 */332 mrc p15, 0, r0, c1, c0, 0 /* 读出控制寄存器到r0中 */333 bic r0, r0, #0x00002300 @ clear bits 13, 9:8 (--V- --RS)334 bic r0, r0, #0x00000087 @ clear bits 7, 2:0 (B--- -CAM)335 orr r0, r0, #0x00000002 @ set bit 2 (A) Align336 orr r0, r0, #0x00001000 @ set bit 12 (I) I-Cache337 mcr p15, 0, r0, c1, c0, 0 /* 保存r0到控制寄存器 */338 339 /*340 * before relocating, we have to setup RAM timing341 * because memory timing is board-dependend, you will342 * find a lowlevel_init.S in your board directory.343 */344 mov ip, lr345 346 bl lowlevel_init347 348 mov lr, ip349 mov pc, lr350 #endif /* CONFIG_SKIP_LOWLEVEL_INIT */
代码中的c0,c1,c7,c8都是ARM920T的协处理器CP15的寄存器。其中c7是cache控制寄存器,c8是TLB控制寄存器。325~327行代码将0写入c7、c8,使Cache,TLB内容无效。 第332~337行代码关闭了MMU。这是通过修改CP15的c1寄存器来实现的,先看CP15的c1寄存器的格式(仅列出代码中用到的位):表 2.3 CP15的c1寄存器格式(部分) 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 ..VI..RSB....CAM 各个位的意义如下:V : 表示异常向量表所在的位置,0:异常向量在0x00000000;1:异常向量在 0xFFFF0000
I : 0 :关闭ICaches;1 :开启ICaches
R、S : 用来与页表中的描述符一起确定内存的访问权限
B : 0 :CPU为小字节序;1 : CPU为大字节序
C : 0:关闭DCaches;1:开启DCaches
A : 0:数据访问时不进行地址对齐检查;1:数据访问时进行地址对齐检查
M : 0:关闭MMU;1:开启MMU 332~337行代码将c1的 M位置零,关闭了MMU。为什么要关闭catch和MMU呢?catch和MMU是做什么用的?
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路 同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权 概述:一,关catch catch和MMU是通过CP15管理的,刚上电的时候,CPU还不能管理他们 上电的时候MMU必须关闭,指令catch可关闭,可不关闭,但数据catch一定要关闭 否则可能导致刚开始的代码里面,去取数据的时候,从catch里面取,而这时候RAM中数据还没有catch过来,导致数据预取异常二:关MMU 因为MMU是;把虚拟地址转化为物理地址得作用 而目的是设置控制寄存器,而控制寄存器本来就是实地址(物理地址),再使能MMU,不就是多此一举了吗?详细分析--- Catch是cpu内部的一个2级缓存,它的作用是将常用的数据和指令放在cpu内部,MMU是用来把虚实地址转换为物理地址用的 我们的目的:是设置控制的寄存器,寄存器都是实地址(物理地址),如果既要开启MMU又要做虚实地址转换的话,中间还多一步,多此一举了嘛?
先要把实地址转换成虚地址,然后再做设置,但对uboot而言就是起到一个简单的初始化的作用和引导操作系统,如果开启MMU的话,很麻烦,也没必要,所以关闭MMU.
说到catch就必须提到一个关键字Volatile,以后在设置寄存器时会经常遇到,他的本质:是告诉编译器不要对我的代码进行优化,作用是让编写者感觉不倒变量的变化情况(也就是说,让它执行速度加快吧) 优化的过程:是将常用的代码取出来放到catch中,它没有从实际的物理地址去取,它直接从cpu的缓存中去取,但常用的代码就是为了感觉一些常用变量的变化 优化原因:如果正在取数据的时候发生跳变,那么就感觉不到变量的变化了,所以在这种情况下要用Volatile关键字告诉编译器不要做优化,每次从实际的物理地址中去取指令,这就是为什么关闭catch关闭MMU。 但在C语言中是不会关闭catch和MMU的,会打开,如果编写者要感觉外界变化,或变化太快,从catch中取数据会有误差,就加一个关键字Volatile。(8)初始化RAM控制寄存器 bl lowlevel_init下来初始化各个bank,把各个bank设置必须搞清楚,对以后移植复杂的uboot有很大帮助
设置完毕后拷贝uboot代码到4k空间,拷贝完毕后执行内存中的uboot代码 其中的lowlevel_init就完成了内存初始化的工作,由于内存初始化是依赖于开发板的,因此lowlevel_init的代码一般放在board下面相应的目录中。对于mini2440,lowlevel_init在board/samsung/mini2440/lowlevel_init.S中定义如下:45 #define BWSCON 0x48000000 /* 13个存储控制器的开始地址 */ … …129 _TEXT_BASE:130 .word TEXT_BASE 0x33F80000, board/config.mk中这段话表示,用户告诉编译器编译地址的起始地址131 132 .globl lowlevel_init133 lowlevel_init:134 /* memory control configuration */135 /* make r0 relative the current location so that it */136 /* reads SMRDATA out of FLASH rather than memory ! */137 ldr r0, =SMRDATA138 ldr r1, _TEXT_BASE139 sub r0, r0, r1 /* SMRDATA减 _TEXT_BASE就是13个寄存器的偏移地址 */140 ldr r1, =BWSCON /* Bus Width Status Controller */141 add r2, r0, #13*4142 0:143 ldr r3, [r0], #4 /*将13个寄存器的值逐一赋值给对应的寄存器*/144 str r3, [r1], #4145 cmp r2, r0146 bne 0b147 148 /* everything is fine now */149 mov pc, lr150 151 .ltorg152 /* the literal pools origin */153 154 SMRDATA: /* 下面是13个寄存器的值 */155 .word … …156 .word … … … … lowlevel_init初始化了13个寄存器来实现RAM时钟的初始化。lowlevel_init函数对于U-Boot从NAND Flash或NOR Flash启动的情况都是有效的。 U-Boot.lds链接脚本有如下代码: .text : { cpu/arm920t/start.o (.text) board/samsung/mini2440/lowlevel_init.o (.text) board/samsung/mini2440/nand_read.o (.text) … … } board/samsung/mini2440/lowlevel_init.o将被链接到cpu/arm920t/start.o后面,因此board/samsung/mini2440/lowlevel_init.o也在U-Boot的前4KB的代码中。 U-Boot在NAND Flash启动时,lowlevel_init.o将自动被读取到CPU内部4KB的内部RAM中。因此第137~146行的代码将从CPU内部RAM中复制寄存器的值到相应的寄存器中。 对于U-Boot在NOR Flash启动的情况,由于U-Boot连接时确定的地址是U-Boot在内存中的地址,而此时U-Boot还在NOR Flash中,因此还需要在NOR Flash中读取数据到RAM中。 由于NOR Flash的开始地址是0,而U-Boot的加载到内存的起始地址是TEXT_BASE,SMRDATA标号在Flash的地址就是SMRDATA-TEXT_BASE。 综上所述,lowlevel_init的作用就是将SMRDATA开始的13个值复制给开始地址[BWSCON]的13个寄存器,从而完成了存储控制器的设置。------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 问题一:如果换一块开发板有可能改哪些东西?
首先,cpu的运行模式,如果需要对cpu进行设置那就设置,管看门狗,关中断不用改,时钟有可能要改,如果能正常使用则不用改,关闭catch和MMU不用改,设置bank有可能要改。最后一步拷贝时看地址会不会变,如果变化也要改,执行内存中代码,地址有可能要改。-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
问题二:Nor Flash和Nand Flash本质区别: 就在于是否进行代码拷贝,也就是下面代码所表述:无论是Nor Flash还是Nand Flash,核心思想就是将uboot代码搬运到内存中去运行,但是没有拷贝bss后面这段代码,只拷贝bss前面的代码,bss代码是放置全局变量的。Bss段代码是为了清零,拷贝过去再清零重复操作
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------(9)复制U-Boot第二阶段代码到RAM cpu/arm920t/start.S原来的代码是只支持从NOR Flash启动的,经过修改现在U-Boot在NOR Flash和NAND Flash上都能启动了,实现的思路是这样的: bl bBootFrmNORFlash /* 判断U-Boot是在NAND Flash还是NOR Flash启动 */ cmp r0, #0 /* r0存放bBootFrmNORFlash函数返回值,若返回0表示NAND Flash启动,否则表示在NOR Flash启动 */ beq nand_boot /* 跳转到NAND Flash启动代码 */ /* NOR Flash启动的代码 */ b stack_setup /* 跳过NAND Flash启动的代码 */ nand_boot:/* NAND Flash启动的代码 */ stack_setup: /* 其他代码 */ 其中bBootFrmNORFlash函数作用是判断U-Boot是在NAND Flash启动还是NOR Flash启动,若在NOR Flash启动则返回1,否则返回0。根据ATPCS规则,函数返回值会被存放在r0寄存器中,因此调用bBootFrmNORFlash函数后根据r0的值就可以判断U-Boot在NAND Flash启动还是NOR Flash启动。bBootFrmNORFlash函数在board/samsung/mini2440/nand_read.c中定义如下:int bBootFrmNORFlash(void){ volatile unsigned int *pdw = (volatile unsigned int *)0; unsigned int dwVal; dwVal = *pdw; /* 先记录下原来的数据 */ *pdw = 0x12345678; if (*pdw != 0x12345678) /* 写入失败,说明是在NOR Flash启动 */ { return 1; } else /* 写入成功,说明是在NAND Flash启动 */ { *pdw = dwVal; /* 恢复原来的数据 */ return 0; }} 无论是从NOR Flash还是从NAND Flash启动,地址0处为U-Boot的第一条指令“ b start_code”。 对于从NAND Flash启动的情况,其开始4KB的代码会被自动复制到CPU内部4K内存中,因此可以通过直接赋值的方法来修改。 对于从NOR Flash启动的情况,NOR Flash的开始地址即为0,必须通过一定的命令序列才能向NOR Flash中写数据,所以可以根据这点差别来分辨是从NAND Flash还是NOR Flash启动:向地址0写入一个数据,然后读出来,如果发现写入失败的就是NOR Flash,否则就是NAND Flash。 下面来分析NOR Flash启动部分代码:208 adr r0, _start /* r0 <- current position of code */209 ldr r1, _TEXT_BASE /* test if we run from flash or RAM */ /* 判断U-Boot是否是下载到RAM中运行,若是,则不用 再复制到RAM中了,这种情况通常在调试U-Boot时才发生 */210 cmp r0, r1 /*_start等于_TEXT_BASE说明是下载到RAM中运行 */211 beq stack_setup212 /* 以下直到nand_boot标号前都是NOR Flash启动的代码 */213 ldr r2, _armboot_start /*flash中armboot_start的起始地址*/
214 ldr r3, _bss_start /*uboot_bss的起始地址*/
215 sub r2, r3, r2 /* r2 <- size of armboot uboot实际程序代码的大小 */216 add r2, r0, r2 /* r2 <- source end address */217 /* 搬运U-Boot自身到RAM中*/218 copy_loop:219 ldmia r0!, {r3-r10} /* 从地址为[r0]的NOR Flash中读入8个字的数据 */220 stmia r1!, {r3-r10} /* 将r3至r10寄存器的数据复制给地址为[r1]的内存 */221 cmp r0, r2 /* until source end addreee [r2] */222 ble copy_loop223 b stack_setup /* 跳过NAND Flash启动的代码 */ 下面再来分析NAND Flash启动部分代码:nand_boot: mov r1, #NAND_CTL_BASE ldr r2, =( (7<<12)|(7<<8)|(7<<4)|(0<<0) ) str r2, [r1, #oNFCONF] /* 设置NFCONF寄存器 */ /* 设置NFCONT,初始化ECC编/解码器,禁止NAND Flash片选 */ ldr r2, =( (1<<4)|(0<<1)|(1<<0) ) str r2, [r1, #oNFCONT] ldr r2, =(0x6) /* 设置NFSTAT */str r2, [r1, #oNFSTAT] /* 复位命令,第一次使用NAND Flash前复位 */ mov r2, #0xff strb r2, [r1, #oNFCMD] mov r3, #0 /* 为调用C函数nand_read_ll准备堆栈 */ ldr sp, DW_STACK_START mov fp, #0 /* 下面先设置r0至r2,然后调用nand_read_ll函数将U-Boot读入RAM */ ldr r0, =TEXT_BASE /* 目的地址:U-Boot在RAM的开始地址 */ mov r1, #0x0 /* 源地址:U-Boot在NAND Flash中的开始地址 */ mov r2, #0x30000 /* 复制的大小,必须比u-boot.bin文件大,并且必须是NAND Flash块大小的整数倍,这里设置为0x30000(192KB) */ bl nand_read_ll /* 跳转到nand_read_ll函数,开始复制U-Boot到RAM */tst r0, #0x0 /* 检查返回值是否正确 */beq stack_setupbad_nand_read:loop2: b loop2 //infinite loop .align 2DW_STACK_START: .word STACK_BASE+STACK_SIZE-4 其中NAND_CTL_BASE,oNFCONF等在include/configs/mini2440.h中定义如下:#define NAND_CTL_BASE 0x4E000000 // NAND Flash控制寄存器基址 #define STACK_BASE 0x33F00000 //base address of stack#define STACK_SIZE 0x8000 //size of stack #define oNFCONF 0x00 /* NFCONF相对于NAND_CTL_BASE偏移地址 */#define oNFCONT 0x04 /* NFCONT相对于NAND_CTL_BASE偏移地址*/#define oNFADDR 0x0c /* NFADDR相对于NAND_CTL_BASE偏移地址*/#define oNFDATA 0x10 /* NFDATA相对于NAND_CTL_BASE偏移地址*/#define oNFCMD 0x08 /* NFCMD相对于NAND_CTL_BASE偏移地址*/#define oNFSTAT 0x20 /* NFSTAT相对于NAND_CTL_BASE偏移地址*/#define oNFECC 0x2c /* NFECC相对于NAND_CTL_BASE偏移地址*/ NAND Flash各个控制寄存器的设置在S3C2440的数据手册有详细说明,这里就不介绍了。 代码中nand_read_ll函数的作用是在NAND Flash中搬运U-Boot到RAM,该函数在board/samsung/mini2440/nand_read.c中定义。 NAND Flash根据page大小可分为2种: 512B/page和2048B/page的。这两种NAND Flash的读操作是不同的。因此就需要U-Boot识别到NAND Flash的类型,然后采用相应的读操作,也就是说nand_read_ll函数要能自动适应两种NAND Flash。 参考S3C2440的数据手册可以知道:根据NFCONF寄存器的Bit3(AdvFlash (Read only))和Bit2 (PageSize (Read only))可以判断NAND Flash的类型。Bit2、Bit3与NAND Flash的block类型的关系如下表所示:表 2.4 NFCONF的Bit3、Bit2与NAND Flash的关系 Bit2 Bit3 0 1 0256 B/page512 B/page11024 B/page2048 B/page 由于的NAND Flash只有512B/page和2048 B/page这两种,因此根据NFCONF寄存器的Bit3即可区分这两种NAND Flash了。 完整代码见board/samsung/mini2440/nand_read.c中的nand_read_ll函数,这里给出伪代码:int nand_read_ll(unsigned char *buf, unsigned long start_addr, int size){//根据NFCONF寄存器的Bit3来区分2种NAND Flash if( NFCONF & 0x8 ) /* Bit是1,表示是2KB/page的NAND Flash */ { //////////////////////////////////// 读取2K block 的NAND Flash //////////////////////////////////// } else /* Bit是0,表示是512B/page的NAND Flash */ { ///////////////////////////////////// 读取512B block 的NAND Flash ///////////////////////////////////// } return 0;}(10)设置堆栈 /* 设置堆栈 */stack_setup: ldr r0, _TEXT_BASE
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- u-boot是一种普遍用于嵌入式系统中的Bootloader。Bootloader介绍Bootloader是进行嵌入式开发必然会接触的一个概念,它是嵌入式学院<嵌入式工程师职业培训班>二期课程中嵌入式linux系统开发方面的重要内容。本篇文章主要讲解Bootloader的基本概念以及内部原理,这部分内容的掌握将对嵌入式linux系统开发的学习非常有帮助!Bootloader的定义:Bootloader是在操作系统运行之前执行的一小段程序,通过这一小段程序,我们可以初始化硬件设备、建立内存空间的映射表,从而建立适当的系统软硬件环境,为最终调用操作系统内核做好准备。意思就是说如果我们要想让一个操作系统在我们的板子上运转起来,我们就必须首先对我们的板子进行一些基本配置和初始化,然后才可以将操作系统引导进来运行。具体在Bootloader中完成了哪些操作我们会在后面分析到,这里我们先来回忆一下PC的体系结构:PC机中的引导加载程序是由BIOS和位于硬盘MBR中的OS Boot Loader(比如LILO和GRUB等)一起组成的,BIOS在完成硬件检测和资源分配后,将硬盘MBR中的Boot Loader读到系统的RAM中,然后将控制权交给OS Boot Loader。Boot Loader的主要运行任务就是将内核映象从硬盘上读到RAM中,然后跳转到内核的入口点去运行,即开始启动操作系统。在嵌入式系统中,通常并没有像BIOS那样的固件程序(注:有的嵌入式cpu也会内嵌一段短小的启动程序),因此整个系统的加载启动任务就完全由Boot Loader来完成。比如在一个基于ARM7TDMI core的嵌入式系统中,系统在上电或复位时通常都从地址0x00000000处开始执行,而在这个地址处安排的通常就是系统的Boot Loader程序。(先想一下,通用PC和嵌入式系统为何会在此处存在如此的差异呢?)Bootloader是基于特定硬件平台来实现的,因此几乎不可能为所有的嵌入式系统建立一个通用的Bootloader,不同的处理器架构都有不同的Bootloader,Bootloader不但依赖于cpu的体系结构,还依赖于嵌入式系统板级设备的配置。对于2块不同的板子而言,即使他们使用的是相同的处理器,要想让运行在一块板子上的Bootloader程序也能运行在另一块板子上,一般也需要修改Bootloader的源程序。Bootloader的启动方式Bootloader的启动方式主要有网络启动方式、磁盘启动方式和Flash启动方式。1、网络启动方式 图1 Bootloader网络启动方式示意图如图1所示,里面主机和目标板,他们中间通过网络来连接,首先目标板的DHCP/BIOS通过BOOTP服务来为Bootloader分配IP地址,配置网络参数,这样才能支持网络传输功能。我们使用的u-boot可以直接设置网络参数,因此这里就不用使用DHCP的方式动态分配IP了。接下来目标板的Bootloader通过TFTP服务将内核映像下载到目标板上,然后通过网络文件系统来建立主机与目标板之间的文件通信过程,之后的系统更新通常也是使用Boot Loader的这种工作模式。工作于这种模式下的Boot Loader通常都会向它的终端用户提供一个简单的命令行接口。2、磁盘启动方式这种方式主要是用在台式机和服务器上的,这些计算机都使用BIOS引导,并且使用磁盘作为存储介质,这里面两个重要的用来启动linux的有LILO和GRUB,这里就不再具体说明了。3、Flash启动方式这是我们最常用的方式。Flash有NOR Flash和NAND Flash两种。NOR Flash可以支持随机访问,所以代码可以直接在Flash上执行,Bootloader一般是存储在Flash芯片上的。另外Flash上还存储着参数、内核映像和文件系统。这种启动方式与网络启动方式之间的不同之处就在于,在网络启动方式中,内核映像和文件系统首先是放在主机上的,然后经过网络传输下载进目标板的,而这种启动方式中内核映像和文件系统则直接是放在Flash中的,这两点在我们u-boot的使用过程中都用到了。U-boot的定义U-boot,全称Universal Boot Loader,是由DENX小组的开发的遵循GPL条款的开放源码项目,它的主要功能是完成硬件设备初始化、操作系统代码搬运,并提供一个控制台及一个指令集在操作系统运行前操控硬件设备。U-boot之所以这么通用,原因是他具有很多特点:开放源代码、支持多种嵌入式操作系统内核、支持多种处理器系列、较高的稳定性、高度灵活的功能设置、丰富的设备驱动源码以及较为丰富的开发调试文档与强大的网络技术支持。另外u-boot对操作系统和产品研发提供了灵活丰富的支持,主要表现在:可以引导压缩或非压缩系统内核,可以灵活设置/传递多个关键参数给操作系统,适合系统在不同开发阶段的调试要求与产品发布,支持多种文件系统,支持多种目标板环境参数存储介质,采用CRC32校验,可校验内核及镜像文件是否完好,提供多种控制台接口,使用户可以在不需要ICE的情况下通过串口/以太网/USB等接口下载数据并烧录到存储设备中去(这个功能在实际的产品中是很实用的,尤其是在软件现场升级的时候),以及提供丰富的设备驱动等。u-boot源代码的目录结构1、board中存放于开发板相关的配置文件,每一个开发板都以子文件夹的形式出现。2、Commom文件夹实现u-boot行下支持的命令,每一个命令对应一个文件。3、cpu中存放特定cpu架构相关的目录,每一款cpu架构都对应了一个子目录。4、Doc是文档目录,有u-boot非常完善的文档。5、Drivers中是u-boot支持的各种设备的驱动程序。6、Fs是支持的文件系统,其中最常用的是JFFS2文件系统。7、Include文件夹是u-boot使用的头文件,还有各种硬件平台支持的汇编文件,系统配置文件和文件系统支持的文件。8、Net是与网络协议相关的代码,bootp协议、TFTP协议、NFS文件系统得实现。9、Tooles是生成U-boot的工具。对u-boot的目录有了一些了解后,分析启动代码的过程就方便多了,其中比较重要的目录就是/board、/cpu、/drivers和/include目录,如果想实现u-boot在一个平台上的移植,就要对这些目录进行深入的分析。-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 什么是《编译地址》?什么是《运行地址》?(一)编译地址: 32位的处理器,它的每一条指令是4个字节,以4个字节存储顺序,进行顺序执行,CPU是顺序执行的,只要没发生什么跳转,它会顺序进行执行行, 编译器会对每一条指令分配一个编译地址,这是编译器分配的,在编译过程中分配的地址,我们称之为编译地址。
(二)运行地址:是指程序指令真正运行的地址,是由用户指定的,用户将运行地址烧录到哪里,哪里就是运行的地址。 比如有一个指令的编译地址是0x5,实际运行的地址是0x200,如果用户将指令烧到0x200上,那么这条指令的运行地址就是0x200, 当编译地址和运行地址不同的时候会出现什么结果?结果是不能跳转,编译后会产生跳转地址,如果实际地址和编译后产生的地址不相等,那么就不能跳转。 C语言编译地址:都希望把编译地址和实际运行地址放在一起的,但是汇编代码因为不需要做C语言到汇编的转换,可以认为的去写地址,所以直接写的就是他的运行地址这就是为什么任何bootloader刚开始会有一段汇编代码,因为起始代码编译地址和实际地址不相等,这段代码和汇编无关,跳转用的运行地址。 编译地址和运行地址如何来算呢? 1. 假如有两个编译地址a=0x10,b=0x7,b的运行地址是0x300,那么a的运行地址就是b的运行地址加上两者编译地址的差值,a-b=0x10-0x7=0x3, a的运行地址就是0x300+0x3=0x303。
2. 假设uboot上两条指令的编译地址为a=0x33000007和b=0x33000001,这两条指令都落在bank6上,现在要计算出他们对应的运行地址,要找出运行地址的始地址,这个是由用户烧录进去的,假设运行地址的首地址是0x0,则a的运行地址为0x7,b为0x1,就是这样算出来的。
为什么要分配编译地址?这样做有什么好处,有什么作用?
比如在函数a中定义了函数b,当执行到函数b时要进行指令跳转,要跳转到b函数所对应的起始地址上去,编译时,编译器给每条指令都分配了编译地址,如果编译器已经给分配了地址就可以直接进行跳转,查找b函数跳转指令所对应的表,进行直接跳转,因为有个编译地址和指令对应的一个表,如果没有分配,编译器就查找不到这个跳转地址,要进行计算,非常麻烦。
什么是《相对地址》?
以NOR Flash为例,NOR Falsh是映射到bank0上面,SDRAM是映射到bank6上面,uboot和内核最终是在SDRAM上面运行,最开始我们是从Nor Flash的零地址开始往后烧录,uboot中至少有一段代码编译地址和运行地址是不一样的,编译uboot或内核时,都会将编译地址放入到SDRAM中,他们最终都会在SDRAM中执行,刚开始uboot在Nor Flash中运行,运行地址是一个低端地址,是bank0中的一个地址,但编译地址是bank6中的地址,这样就会导致绝对跳转指令执行的失败,所以就引出了相对地址的概念。 那么什么是相对地址呢? 至少在bank0中uboot这段代码要知道不能用b+编译地址这样的方法去跳转指令,因为这段代码的编译地址和运行地址不一样,那如何去做呢? 要去计算这个指令运行的真实地址,计算出来后再做跳转,应该是b+运行地址,不能出现b+编译地址,而是b+运行地址,而运行地址是算出来的。
_TEXT_BASE:
.word TEXT_BASE //0x33F80000,在board/config.mk中
这段话表示,用户告诉编译器编译地址的起始地址
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- U-Boot工作过程 大多数 Boot Loader 都包含两种不同的操作模式:"启动加载"模式和"下载"模式,这种区别仅对于开发人员才有意义。 但从最终用户的角度看,Boot Loader 的作用就是:用来加载操作系统,而并不存在所谓的启动加载模式与下载工作模式的区别。
(一)启动加载(Boot loading)模式:这种模式也称为"自主"(Autonomous)模式。 也即 Boot Loader 从目标机上的某个固态存储设备上将操作系统加载到 RAM 中运行,整个过程并没有用户的介入。 这种模式是 Boot Loader 的正常工作模式,因此在嵌入式产品发布的时侯,Boot Loader 显然必须工作在这种模式下。
(二)下载(Downloading)模式:在这种模式下,目标机上的 Boot Loader 将通过串口连接或网络连接等通信手段从主机(Host)下载文件,比如:下载内核映像和根文件系统映像等。从主机下载的文件通常首先被 Boot Loader保存到目标机的RAM中,然后再被 BootLoader写到目标机上的FLASH类固态存储设备中。Boot Loader 的这种模式通常在第一次安装内核与根文件系统时被使用;此外,以后的系统更新也会使用 Boot Loader 的这种工作模式。工作于这种模式下的 Boot Loader 通常都会向它的终端用户提供一个简单的命令行接口。这种工作模式通常在第一次安装内核与跟文件系统时使用。或者在系统更新时使用。进行嵌入式系统调试时一般也让bootloader工作在这一模式下。
UBoot 这样功能强大的 Boot Loader 同时支持这两种工作模式,而且允许用户在这两种工作模式之间进行切换。 大多数 bootloader 都分为阶段 1(stage1)和阶段 2(stage2)两大部分,uboot 也不例外。依赖于 CPU 体系结构的代码(如 CPU 初始化代码等)通常都放在阶段 1 中且通常用汇编语言实现,而阶段 2 则通常用 C 语言来实现,这样可以实现复杂的功能,而且有更好的可读性和移植性。
-------------------------------------------------------------------------------------------------------------------------------------------第一、大概总结性得的分析 系统启动的入口点。既然我们现在要分析u-boot的启动过程,就必须先找到u-boot最先实现的是哪些代码,最先完成的是哪些任务。 另一方面一个可执行的image必须有一个入口点,并且只能有一个全局入口点,所以要通知编译器这个入口在哪里。由此我们可以找到程序的入口点是在/board/lpc2210/u-boot.lds中指定的,其中ENTRY(_start)说明程序从_start开始运行,而他指向的是cpu/arm7tdmi/start.o文件。因为我们用的是ARM7TDMI的cpu架构,在复位后从地址0x00000000取它的第一条指令,所以我们将Flash映射到这个地址上,这样在系统加电后,cpu将首先执行u-boot程序。u-boot的启动过程是多阶段实现的,分了两个阶段。依赖于cpu体系结构的代码(如设备初始化代码等)通常都放在stage1中,而且通常都是用汇编语言来实现,以达到短小精悍的目的。而stage2则通常是用C语言来实现的,这样可以实现复杂的功能,而且代码具有更好的可读性和可移植性。下面我们先详细分析下stage1中的代码,如图2所示:
图2 Start.s程序流程 代码真正开始是在_start,设置异常向量表,这样在cpu发生异常时就跳转到/cpu/arm7tdmi/interrupts中去执行相应得中断代码。 在interrupts文件中大部分的异常代码都没有实现具体的功能,只是打印一些异常消息,其中关键的是reset中断代码,跳到reset入口地址。 reset复位入口之前有一些段的声明。 1.在reset中,首先是将cpu设置为svc32模式下,并屏蔽所有irq和fiq。 2.在u-boot中除了定时器使用了中断外,其他的基本上都不需要使用中断,比如串口通信和网络等通信等,在u-boot中只要完成一些简单的通信就可以了,所以在这里屏蔽掉了所有的中断响应。 3.初始化外部总线。这部分首先设置了I/O口功能,包括串口、网络接口等的设置,其他I/O口都设置为GPIO。然后设置BCFG0~BCFG3,即外部总线控制器。这里bank0对应Flash,设置为16位宽度,总线速度设为最慢,以实现稳定的操作;Bank1对应DRAM,设置和Flash相同;Bank2对应RTL8019。 4.接下来是cpu关键设置,包括系统重映射(告诉处理器在系统发生中断的时候到外部存储器中去读取中断向量表)和系统频率。 5.lowlevel_init,设定RAM的时序,并将中断控制器清零。这些部分和特定的平台有关,但大致的流程都是一样的。 下面就是代码的搬移阶段了。为了获得更快的执行速度, 通常把stage2加载到RAM空间中来执行,因此必须为加载Boot Loader的stage2准备好一段可用的RAM空间范围。空间大小最好是memory page大小(通常是4KB)的倍数 一般而言,1M的RAM空间已经足够了。 flash中存储的u-boot可执行文件中,代码段、数据段以及BSS段都是首尾相连存储的, 所以在计算搬移大小的时候就是利用了用BSS段的首地址减去代码的首地址,这样算出来的就是实际使用的空间。 程序用一个循环将代码搬移到0x81180000,即RAM底端1M空间用来存储代码。 然后程序继续将中断向量表搬到RAM的顶端。由于stage2通常是C语言执行代码,所以还要建立堆栈去。 在堆栈区之前还要将malloc分配的空间以及全局数据所需的空间空下来,他们的大小是由宏定义给出的,可以在相应位置修改。基本内存分布图:
图3 搬移后内存分布情况图 下来是u-boot启动的第二个阶段,是用c代码写的, 这部分是一些相对变化不大的部分,我们针对不同的板子改变它调用的一些初始化函数,并且通过设置一些宏定义来改变初始化的流程, 所以这些代码在移植的过程中并不需要修改,也是错误相对较少出现的文件。 在文件的开始先是定义了一个函数指针数组,通过这个数组,程序通过一个循环来按顺序进行常规的初始化,并在其后通过一些宏定义来初始化一些特定的设备。 在最后程序进入一个循环,main_loop。这个循环接收用户输入的命令,以设置参数或者进行启动引导。本篇文章将分析重点放在了前面的start.s上,是因为这部分无论在移植还是在调试过程中都是最容易出问题的地方,要解决问题就需要程序员对代码进行修改,所以在这里简单介绍了一下start.s的基本流程,希望能对大家有所帮助--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------第二、代码分析 2.2 阶段 1 介绍
uboot 的 stage1 代码通常放在 start.s 文件中,它用汇编语言写成,其主要代码部分如下:
2.2.1 定义入口
由于一个可执行的 Image 必须有一个入口点,并且只能有一个全局入口,通常这个入口放在 ROM(Flash)的 0x0
地址,因此,必须通知编译器以使其知道这个入口,该工作可通过修改连接器脚本来完成。
1. board/crane2410/uboot.lds: ENTRY(_start) ==> cpu/arm920t/start.S: .globl _start
2. uboot 代码区(TEXT_BASE = 0x33F80000)定义在 board/crane2410/config.mkU-Boot启动内核的过程可以分为两个阶段,两个阶段的功能如下: (1)第一阶段的功能Ø 硬件设备初始化Ø 加载U-Boot第二阶段代码到RAM空间Ø 设置好栈Ø 跳转到第二阶段代码入口 (2)第二阶段的功能Ø 初始化本阶段使用的硬件设备Ø 检测系统内存映射Ø 将内核从Flash读取到RAM中Ø 为内核设置启动参数Ø 调用内核
1.1.1 U-Boot启动第一阶段代码分析
第一阶段对应的文件是cpu/arm920t/start.S和board/samsung/mini2440/lowlevel_init.S。 U-Boot启动第一阶段流程如下:详细分析图 2.1 U-Boot启动第一阶段流程 根据cpu/arm920t/u-boot.lds中指定的连接方式: 看一下uboot.lds文件,在board/smdk2410目录下面,uboot.lds是告诉编译器这些段改怎么划分,GUN编译过的段,最基本的三个段是RO,RW,ZI,RO表示只读,对应于具体的指代码段,RW是数据段,ZI是归零段,就是全局变量的那段。Uboot代码这么多,如何保证start.s会第一个执行,编译在最开始呢?就是通过uboot.lds链接文件进行OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
/*OUTPUT_FORMAT("elf32-arm", "elf32-arm", "elf32-arm")*/
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
. = 0x00000000; //起始地址
. = ALIGN(4); //4字节对齐
.text : //test指代码段,上面3行标识是不占用任何空间的
{
cpu/arm920t/start.o (.text) //这里把start.o放在第一位就表示把start.s编
译时放到最开始,这就是为什么把uboot烧到起始地址上它肯定运行的是start.s
*(.text)
}
. = ALIGN(4); //前面的 “.” 代表当前值,是计算一个当前的值,是计算上
面占用的整个空间,再加一个单元就表示它现在的位置
.rodata : { *(.rodata) }
. = ALIGN(4);
.data : { *(.data) }
. = ALIGN(4);
.got : { *(.got) }
. = .;
__u_boot_cmd_start = .;
.u_boot_cmd : { *(.u_boot_cmd) }
__u_boot_cmd_end = .;
. = ALIGN(4);
__bss_start = .; //bss表示归零段
.bss : { *(.bss) }
_end = .;
}
第一个链接的是cpu/arm920t/start.o,因此u-boot.bin的入口代码在cpu/arm920t/start.o中,其源代码在cpu/arm920t/start.S中。下面我们来分析cpu/arm920t/start.S的执行。1. 硬件设备初始化(1)设置异常向量 下面代码是系统启动后U-boot上电后运行的第一段代码,它是什么意思? u-boot对应的第一阶段代码放在cpu/arm920t/start.S文件中,入口代码如下:.globl _startglobal /*声明一个符号可被其它文件引用,相当于声明了一个全局变量,.globl与.global相同*/_start: b start_code /* 复位 */b是不带返回的跳转(bl是带返回的跳转),意思是无条件直接跳转到start_code标号出执行程序 ldr pc, _undefined_instruction /* 未定义指令向量 l---dr相当于mov操作*/ ldr pc, _software_interrupt /* 软件中断向量 */ ldr pc, _prefetch_abort /* 预取指令异常向量 */ ldr pc, _data_abort /* 数据操作异常向量 */ ldr pc, _not_used /* 未使用 */ ldr pc, _irq /* irq中断向量 */ ldr pc, _fiq /* fiq中断向量 *//* 中断向量表入口地址 */_undefined_instruction: .word undefined_instruction /*就是在当前地址,即_undefined_instruction 处存放 undefined_instruction*/_software_interrupt: .word software_interrupt_prefetch_abort: .word prefetch_abort_data_abort: .word data_abort_not_used: .word not_used_irq: .word irq_fiq: .word fiq word伪操作用于分配一段字内存单元(分配的单元都是字对齐的),并用伪操作中的expr初始化 .balignl 16,0xdeadbeef 他们是系统定义的异常,一上电程序跳转到start_code异常处执行相应的汇编指令,下面定义出的都是不同的异常,比如软件发生软中断时,CPU就会去执行软中断的指令,这些异常中断在CUP中地址是从0开始,每个异常占4个字节 ldr pc, _undefined_instruction表示把_undefined_instruction存放的数值存放到pc指针上 _undefined_instruction: .word undefined_instruction表示未定义的这个异常是由.word来定义的,它表示定义一个字,一个32位的数. word后面的数:表示把该标识的编译地址写入当前地址,标识是不占用任何指令的。把标识存放的数值copy到指针pc上面,那么标识上存放的值是什么?是由.word undefined_instruction来指定的,pc就代表你运行代码的地址,她就实现了CPU要做一次跳转时的工作。
以上代码设置了ARM异常向量表,各个异常向量介绍如下:表 2.1 ARM异常向量表 地址 异常 进入模式描述0x00000000 复位 管理模式 复位电平有效时,产生复位异常,程序跳转到复位处理程序处执行0x00000004 未定义指令 未定义模式 遇到不能处理的指令时,产生未定义指令异常0x00000008软件中断 管理模式 执行SWI指令产生,用于用户模式下的程序调用特权操作指令0x0000000c预存指令 中止模式 处理器预取指令的地址不存在,或该地址不允许当前指令访问,产生指令预取中止异常0x00000010数据操作 中止模式 处理器数据访问指令的地址不存在,或该地址不允许当前指令访问时,产生数据中止异常0x00000014未使用 未使用 未使用0x00000018IRQ IRQ 外部中断请求有效,且CPSR中的I位为0时,产生IRQ异常0x0000001cFIQ FIQ 快速中断请求引脚有效,且CPSR中的F位为0时,产生FIQ异常 在cpu/arm920t/start.S中还有这些异常对应的异常处理程序。当一个异常产生时,CPU根据异常号在异常向量表中找到对应的异常向量,然后执行异常向量处的跳转指令,CPU就跳转到对应的异常处理程序执行。 其中复位异常向量的指令“b start_code”决定了U-Boot启动后将自动跳转到标号“start_code”处执行。(2)CPU进入SVC模式start_code: /* * set the cpu to SVC32 mode */ mrs r0, cpsr bic r0, r0, #0x1f /*工作模式位清零 */ orr r0, r0, #0xd3 /*工作模式位设置为“10011”(管理模式),并将中断禁止位和快中断禁止位置1 */ msr cpsr, r0 以上代码将CPU的工作模式位设置为管理模式,即设置相应的CPSR程序状态字,并将中断禁止位和快中断禁止位置一,从而屏蔽了IRQ和FIQ中断。 操作系统先注册一个总的中断,然后去查是由哪个中断源产生的中断,再去查用户注册的中断表,查出来后就去执行用户定义的用户中断处理函数。
(3)设置控制寄存器地址# if defined(CONFIG_S3C2400) /*关闭看门狗*/
# define pWTCON 0x15300000 /*;看门狗寄存器*/
# define INTMSK 0x14400008 /*;中断屏蔽寄存器*/# define CLKDIVN 0x14800014 /*;时钟分频寄存器*/
#else /* s3c2410与s3c2440下面4个寄存器地址相同 */# define pWTCON 0x53000000 /* WATCHDOG控制寄存器地址 */# define INTMSK 0x4A000008 /* INTMSK寄存器地址 */# define INTSUBMSK 0x4A00001C /* INTSUBMSK寄存器地址 次级中断屏蔽寄存器*/# define CLKDIVN 0x4C000014 /* CLKDIVN寄存器地址 ;时钟分频寄存器*/# endif 对与s3c2440开发板,以上代码完成了WATCHDOG,INTMSK,INTSUBMSK,CLKDIVN四个寄存器的地址的设置。各个寄存器地址参见参考文献[4] 。(4)关闭看门狗 ldr r0, =pWTCON /*将pwtcon寄存器地址赋给R0*/ mov r1, #0x0 /*r1的内容为0*/
str r1, [r0] /* 看门狗控制器的最低位为0时,看门狗不输出复位信号 */ 以上代码向看门狗控制寄存器写入0,关闭看门狗。否则在U-Boot启动过程中,CPU将不断重启。为什么要关看门狗? 就是防止,不同得两个以上得CPU,进行喂狗的时间间隔问题:说白了,就是你运行的代码如果超出喂狗时间,而你不关狗,就会导致,你代码还没运行完又得去喂狗,就这样反复得重启CPU,那你代码永远也运行不完,所以,得先关看门狗得原因,就是这样。关狗---详细的原因: 关闭看门狗,关闭中断,所谓的喂狗是每隔一段时间给某个寄存器置位而已,在实际中会专门启动一个线程或进程会专门喂狗,当上层软件出现故障时就会停止喂狗, 停止喂狗之后,cpu会自动复位,一般都在外部专门有一个看门狗,做一个外部的电路,不在cpu内部使用看门狗,cpu内部的看门狗是复位的cpu 当开发板很复杂时,有好几个cpu时,就不能完全让板子复位,但我们通常都让整个板子复位。看门狗每隔短时间就会喂狗,问题是在两次喂狗之间的时间间隔内,运行的代码的时间是否够用,两次喂狗之间的代码是否在两次喂狗的时间延迟之内,如果在延迟之外的话,代码还没改完就又进行喂狗,代码永远也改不完(5)屏蔽中断 /* * mask all IRQs by setting all bits in the INTMR - default */ mov r1, #0xffffffff /*屏蔽所有中断, 某位被置1则对应的中断被屏蔽 */ /*寄存器中的值*/ ldr r0, =INTMSK /*将管理中断的寄存器地址赋给ro*/ str r1, [r0] /*将全r1的值赋给ro地址中的内容*/ INTMSK是主中断屏蔽寄存器,每一位对应SRCPND(中断源引脚寄存器)中的一位,表明SRCPND相应位代表的中断请求是否被CPU所处理。 根据参考文献4,INTMSK寄存器是一个32位的寄存器,每位对应一个中断,向其中写入0xffffffff就将INTMSK寄存器全部位置一,从而屏蔽对应的中断。# if defined(CONFIG_S3C2440) ldr r1, =0x7fff ldr r0, =INTSUBMSK str r1, [r0] # endif INTSUBMSK每一位对应SUBSRCPND中的一位,表明SUBSRCPND相应位代表的中断请求是否被CPU所处理。 根据参考文献4,INTSUBMSK寄存器是一个32位的寄存器,但是只使用了低15位。向其中写入0x7fff就是将INTSUBMSK寄存器全部有效位(低15位)置一,从而屏蔽对应的中断。屏蔽所有中断,为什么要关中断?中断处理中ldr pc是将代码的编译地址放在了指针上,而这段时间还没有搬移代码,所以编译地址上面没有这个代码,如果进行跳转就会跳转到空指针上面
(6)设置MPLLCON,UPLLCON, CLKDIVN# if defined(CONFIG_S3C2440) #define MPLLCON 0x4C000004#define UPLLCON 0x4C000008 ldr r0, =CLKDIVN ;设置时钟
mov r1, #5 str r1, [r0] ldr r0, =MPLLCON ldr r1, =0x7F021 str r1, [r0] ldr r0, =UPLLCON ldr r1, =0x38022 str r1, [r0]# else /* FCLK:HCLK:PCLK = 1:2:4 */ /* default FCLK is 120 MHz ! */ ldr r0, =CLKDIVN mov r1, #3 str r1, [r0]#endif CPU上电几毫秒后,晶振输出稳定,FCLK=Fin(晶振频率),CPU开始执行指令。但实际上,FCLK可以高于Fin,为了提高系统时钟,需要用软件来启用PLL。这就需要设置CLKDIVN,MPLLCON,UPLLCON这3个寄存器。 CLKDIVN寄存器用于设置FCLK,HCLK,PCLK三者间的比例,可以根据表2.2来设置。表 2.2 S3C2440 的CLKDIVN寄存器格式 CLKDIVN 位 说明 初始值 HDIVN[2:1] 00 : HCLK = FCLK/1. 01 : HCLK = FCLK/2. 10 : HCLK = FCLK/4 (当 CAMDIVN[9] = 0 时) HCLK= FCLK/8 (当 CAMDIVN[9] = 1 时) 11 : HCLK = FCLK/3 (当 CAMDIVN[8] = 0 时) HCLK = FCLK/6 (当 CAMDIVN[8] = 1时)00PDIVN[0]0: PCLK = HCLK/1 1: PCLK = HCLK/20 设置CLKDIVN为5,就将HDIVN设置为二进制的10,由于CAMDIVN[9]没有被改变过,取默认值0,因此HCLK = FCLK/4。PDIVN被设置为1,因此PCLK= HCLK/2。因此分频比FCLK:HCLK:PCLK = 1:4:8 。 MPLLCON寄存器用于设置FCLK与Fin的倍数。MPLLCON的位[19:12]称为MDIV,位[9:4]称为PDIV,位[1:0]称为SDIV。 对于S3C2440,FCLK与Fin的关系如下面公式: MPLL(FCLK) = (2×m×Fin)/(p× ) 其中: m=MDIC+8,p=PDIV+2,s=SDIV MPLLCON与UPLLCON的值可以根据参考文献4中“PLL VALUE SELECTION TABLE”设置。该表部分摘录如下:表 2.3 推荐PLL值 输入频率 输出频率 MDIV PDIV SDIV 12.0000MHz48.00 MHz56(0x38)2212.0000MHz405.00 MHz127(0x7f)21 当mini2440系统主频设置为405MHZ,USB时钟频率设置为48MHZ时,系统可以稳定运行,因此设置MPLLCON与UPLLCON为: MPLLCON=(0x7f<<12) | (0x02<<4) | (0x01) = 0x7f021 UPLLCON=(0x38<<12) | (0x02<<4) | (0x02) = 0x38022默认频率为 FCLK:HCLK:PCLK = 1:2:4,默认 FCLK 的值为 120 MHz,该值为 S3C2410 手册的推荐值。设置时钟分频,为什么要设置时钟?起始可以不设,系统能不能跑起来和频率没有任何关系,频率的设置是要让外围的设备能承受所设置的频率,如果频率过高则会导致cpu操作外围设备失败说白了:设置频率,就为了CPU能去操作外围设备(7)关闭MMU,cache ------(也就是做bank的设置)
接着往下看:#ifndef CONFIG_SKIP_LOWLEVEL_INIT bl cpu_init_crit /* ;跳转并把转移后面紧接的一条指令地址保存到链接寄存器LR(R14)中,以此来完成子程序的调用*/
#endif cpu_init_crit这段代码在U-Boot正常启动时才需要执行,若将U-Boot从RAM中启动则应该注释掉这段代码。 下面分析一下cpu_init_crit到底做了什么:320 #ifndef CONFIG_SKIP_LOWLEVEL_INIT321 cpu_init_crit:322 /*323 * 使数据cache与指令cache无效 */324 */ 325 mov r0, #0326 mcr p15, 0, r0, c7, c7, 0 /* 向c7写入0将使ICache与DCache无效*/327 mcr p15, 0, r0, c8, c7, 0 /* 向c8写入0将使TLB失效 ,协处理器*/
328 329 /*330 * disable MMU stuff and caches331 */332 mrc p15, 0, r0, c1, c0, 0 /* 读出控制寄存器到r0中 */333 bic r0, r0, #0x00002300 @ clear bits 13, 9:8 (--V- --RS)334 bic r0, r0, #0x00000087 @ clear bits 7, 2:0 (B--- -CAM)335 orr r0, r0, #0x00000002 @ set bit 2 (A) Align336 orr r0, r0, #0x00001000 @ set bit 12 (I) I-Cache337 mcr p15, 0, r0, c1, c0, 0 /* 保存r0到控制寄存器 */338 339 /*340 * before relocating, we have to setup RAM timing341 * because memory timing is board-dependend, you will342 * find a lowlevel_init.S in your board directory.343 */344 mov ip, lr345 346 bl lowlevel_init347 348 mov lr, ip349 mov pc, lr350 #endif /* CONFIG_SKIP_LOWLEVEL_INIT */
代码中的c0,c1,c7,c8都是ARM920T的协处理器CP15的寄存器。其中c7是cache控制寄存器,c8是TLB控制寄存器。325~327行代码将0写入c7、c8,使Cache,TLB内容无效。 第332~337行代码关闭了MMU。这是通过修改CP15的c1寄存器来实现的,先看CP15的c1寄存器的格式(仅列出代码中用到的位):表 2.3 CP15的c1寄存器格式(部分) 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 ..VI..RSB....CAM 各个位的意义如下:V : 表示异常向量表所在的位置,0:异常向量在0x00000000;1:异常向量在 0xFFFF0000
I : 0 :关闭ICaches;1 :开启ICaches
R、S : 用来与页表中的描述符一起确定内存的访问权限
B : 0 :CPU为小字节序;1 : CPU为大字节序
C : 0:关闭DCaches;1:开启DCaches
A : 0:数据访问时不进行地址对齐检查;1:数据访问时进行地址对齐检查
M : 0:关闭MMU;1:开启MMU 332~337行代码将c1的 M位置零,关闭了MMU。为什么要关闭catch和MMU呢?catch和MMU是做什么用的?
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路 同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权 概述:一,关catch catch和MMU是通过CP15管理的,刚上电的时候,CPU还不能管理他们 上电的时候MMU必须关闭,指令catch可关闭,可不关闭,但数据catch一定要关闭 否则可能导致刚开始的代码里面,去取数据的时候,从catch里面取,而这时候RAM中数据还没有catch过来,导致数据预取异常二:关MMU 因为MMU是;把虚拟地址转化为物理地址得作用 而目的是设置控制寄存器,而控制寄存器本来就是实地址(物理地址),再使能MMU,不就是多此一举了吗?详细分析--- Catch是cpu内部的一个2级缓存,它的作用是将常用的数据和指令放在cpu内部,MMU是用来把虚实地址转换为物理地址用的 我们的目的:是设置控制的寄存器,寄存器都是实地址(物理地址),如果既要开启MMU又要做虚实地址转换的话,中间还多一步,多此一举了嘛?
先要把实地址转换成虚地址,然后再做设置,但对uboot而言就是起到一个简单的初始化的作用和引导操作系统,如果开启MMU的话,很麻烦,也没必要,所以关闭MMU.
说到catch就必须提到一个关键字Volatile,以后在设置寄存器时会经常遇到,他的本质:是告诉编译器不要对我的代码进行优化,作用是让编写者感觉不倒变量的变化情况(也就是说,让它执行速度加快吧) 优化的过程:是将常用的代码取出来放到catch中,它没有从实际的物理地址去取,它直接从cpu的缓存中去取,但常用的代码就是为了感觉一些常用变量的变化 优化原因:如果正在取数据的时候发生跳变,那么就感觉不到变量的变化了,所以在这种情况下要用Volatile关键字告诉编译器不要做优化,每次从实际的物理地址中去取指令,这就是为什么关闭catch关闭MMU。 但在C语言中是不会关闭catch和MMU的,会打开,如果编写者要感觉外界变化,或变化太快,从catch中取数据会有误差,就加一个关键字Volatile。(8)初始化RAM控制寄存器 bl lowlevel_init下来初始化各个bank,把各个bank设置必须搞清楚,对以后移植复杂的uboot有很大帮助
设置完毕后拷贝uboot代码到4k空间,拷贝完毕后执行内存中的uboot代码 其中的lowlevel_init就完成了内存初始化的工作,由于内存初始化是依赖于开发板的,因此lowlevel_init的代码一般放在board下面相应的目录中。对于mini2440,lowlevel_init在board/samsung/mini2440/lowlevel_init.S中定义如下:45 #define BWSCON 0x48000000 /* 13个存储控制器的开始地址 */ … …129 _TEXT_BASE:130 .word TEXT_BASE 0x33F80000, board/config.mk中这段话表示,用户告诉编译器编译地址的起始地址131 132 .globl lowlevel_init133 lowlevel_init:134 /* memory control configuration */135 /* make r0 relative the current location so that it */136 /* reads SMRDATA out of FLASH rather than memory ! */137 ldr r0, =SMRDATA138 ldr r1, _TEXT_BASE139 sub r0, r0, r1 /* SMRDATA减 _TEXT_BASE就是13个寄存器的偏移地址 */140 ldr r1, =BWSCON /* Bus Width Status Controller */141 add r2, r0, #13*4142 0:143 ldr r3, [r0], #4 /*将13个寄存器的值逐一赋值给对应的寄存器*/144 str r3, [r1], #4145 cmp r2, r0146 bne 0b147 148 /* everything is fine now */149 mov pc, lr150 151 .ltorg152 /* the literal pools origin */153 154 SMRDATA: /* 下面是13个寄存器的值 */155 .word … …156 .word … … … … lowlevel_init初始化了13个寄存器来实现RAM时钟的初始化。lowlevel_init函数对于U-Boot从NAND Flash或NOR Flash启动的情况都是有效的。 U-Boot.lds链接脚本有如下代码: .text : { cpu/arm920t/start.o (.text) board/samsung/mini2440/lowlevel_init.o (.text) board/samsung/mini2440/nand_read.o (.text) … … } board/samsung/mini2440/lowlevel_init.o将被链接到cpu/arm920t/start.o后面,因此board/samsung/mini2440/lowlevel_init.o也在U-Boot的前4KB的代码中。 U-Boot在NAND Flash启动时,lowlevel_init.o将自动被读取到CPU内部4KB的内部RAM中。因此第137~146行的代码将从CPU内部RAM中复制寄存器的值到相应的寄存器中。 对于U-Boot在NOR Flash启动的情况,由于U-Boot连接时确定的地址是U-Boot在内存中的地址,而此时U-Boot还在NOR Flash中,因此还需要在NOR Flash中读取数据到RAM中。 由于NOR Flash的开始地址是0,而U-Boot的加载到内存的起始地址是TEXT_BASE,SMRDATA标号在Flash的地址就是SMRDATA-TEXT_BASE。 综上所述,lowlevel_init的作用就是将SMRDATA开始的13个值复制给开始地址[BWSCON]的13个寄存器,从而完成了存储控制器的设置。------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 问题一:如果换一块开发板有可能改哪些东西?
首先,cpu的运行模式,如果需要对cpu进行设置那就设置,管看门狗,关中断不用改,时钟有可能要改,如果能正常使用则不用改,关闭catch和MMU不用改,设置bank有可能要改。最后一步拷贝时看地址会不会变,如果变化也要改,执行内存中代码,地址有可能要改。-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
问题二:Nor Flash和Nand Flash本质区别: 就在于是否进行代码拷贝,也就是下面代码所表述:无论是Nor Flash还是Nand Flash,核心思想就是将uboot代码搬运到内存中去运行,但是没有拷贝bss后面这段代码,只拷贝bss前面的代码,bss代码是放置全局变量的。Bss段代码是为了清零,拷贝过去再清零重复操作
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------(9)复制U-Boot第二阶段代码到RAM cpu/arm920t/start.S原来的代码是只支持从NOR Flash启动的,经过修改现在U-Boot在NOR Flash和NAND Flash上都能启动了,实现的思路是这样的: bl bBootFrmNORFlash /* 判断U-Boot是在NAND Flash还是NOR Flash启动 */ cmp r0, #0 /* r0存放bBootFrmNORFlash函数返回值,若返回0表示NAND Flash启动,否则表示在NOR Flash启动 */ beq nand_boot /* 跳转到NAND Flash启动代码 */ /* NOR Flash启动的代码 */ b stack_setup /* 跳过NAND Flash启动的代码 */ nand_boot:/* NAND Flash启动的代码 */ stack_setup: /* 其他代码 */ 其中bBootFrmNORFlash函数作用是判断U-Boot是在NAND Flash启动还是NOR Flash启动,若在NOR Flash启动则返回1,否则返回0。根据ATPCS规则,函数返回值会被存放在r0寄存器中,因此调用bBootFrmNORFlash函数后根据r0的值就可以判断U-Boot在NAND Flash启动还是NOR Flash启动。bBootFrmNORFlash函数在board/samsung/mini2440/nand_read.c中定义如下:int bBootFrmNORFlash(void){ volatile unsigned int *pdw = (volatile unsigned int *)0; unsigned int dwVal; dwVal = *pdw; /* 先记录下原来的数据 */ *pdw = 0x12345678; if (*pdw != 0x12345678) /* 写入失败,说明是在NOR Flash启动 */ { return 1; } else /* 写入成功,说明是在NAND Flash启动 */ { *pdw = dwVal; /* 恢复原来的数据 */ return 0; }} 无论是从NOR Flash还是从NAND Flash启动,地址0处为U-Boot的第一条指令“ b start_code”。 对于从NAND Flash启动的情况,其开始4KB的代码会被自动复制到CPU内部4K内存中,因此可以通过直接赋值的方法来修改。 对于从NOR Flash启动的情况,NOR Flash的开始地址即为0,必须通过一定的命令序列才能向NOR Flash中写数据,所以可以根据这点差别来分辨是从NAND Flash还是NOR Flash启动:向地址0写入一个数据,然后读出来,如果发现写入失败的就是NOR Flash,否则就是NAND Flash。 下面来分析NOR Flash启动部分代码:208 adr r0, _start /* r0 <- current position of code */209 ldr r1, _TEXT_BASE /* test if we run from flash or RAM */ /* 判断U-Boot是否是下载到RAM中运行,若是,则不用 再复制到RAM中了,这种情况通常在调试U-Boot时才发生 */210 cmp r0, r1 /*_start等于_TEXT_BASE说明是下载到RAM中运行 */211 beq stack_setup212 /* 以下直到nand_boot标号前都是NOR Flash启动的代码 */213 ldr r2, _armboot_start /*flash中armboot_start的起始地址*/
214 ldr r3, _bss_start /*uboot_bss的起始地址*/
215 sub r2, r3, r2 /* r2 <- size of armboot uboot实际程序代码的大小 */216 add r2, r0, r2 /* r2 <- source end address */217 /* 搬运U-Boot自身到RAM中*/218 copy_loop:219 ldmia r0!, {r3-r10} /* 从地址为[r0]的NOR Flash中读入8个字的数据 */220 stmia r1!, {r3-r10} /* 将r3至r10寄存器的数据复制给地址为[r1]的内存 */221 cmp r0, r2 /* until source end addreee [r2] */222 ble copy_loop223 b stack_setup /* 跳过NAND Flash启动的代码 */ 下面再来分析NAND Flash启动部分代码:nand_boot: mov r1, #NAND_CTL_BASE ldr r2, =( (7<<12)|(7<<8)|(7<<4)|(0<<0) ) str r2, [r1, #oNFCONF] /* 设置NFCONF寄存器 */ /* 设置NFCONT,初始化ECC编/解码器,禁止NAND Flash片选 */ ldr r2, =( (1<<4)|(0<<1)|(1<<0) ) str r2, [r1, #oNFCONT] ldr r2, =(0x6) /* 设置NFSTAT */str r2, [r1, #oNFSTAT] /* 复位命令,第一次使用NAND Flash前复位 */ mov r2, #0xff strb r2, [r1, #oNFCMD] mov r3, #0 /* 为调用C函数nand_read_ll准备堆栈 */ ldr sp, DW_STACK_START mov fp, #0 /* 下面先设置r0至r2,然后调用nand_read_ll函数将U-Boot读入RAM */ ldr r0, =TEXT_BASE /* 目的地址:U-Boot在RAM的开始地址 */ mov r1, #0x0 /* 源地址:U-Boot在NAND Flash中的开始地址 */ mov r2, #0x30000 /* 复制的大小,必须比u-boot.bin文件大,并且必须是NAND Flash块大小的整数倍,这里设置为0x30000(192KB) */ bl nand_read_ll /* 跳转到nand_read_ll函数,开始复制U-Boot到RAM */tst r0, #0x0 /* 检查返回值是否正确 */beq stack_setupbad_nand_read:loop2: b loop2 //infinite loop .align 2DW_STACK_START: .word STACK_BASE+STACK_SIZE-4 其中NAND_CTL_BASE,oNFCONF等在include/configs/mini2440.h中定义如下:#define NAND_CTL_BASE 0x4E000000 // NAND Flash控制寄存器基址 #define STACK_BASE 0x33F00000 //base address of stack#define STACK_SIZE 0x8000 //size of stack #define oNFCONF 0x00 /* NFCONF相对于NAND_CTL_BASE偏移地址 */#define oNFCONT 0x04 /* NFCONT相对于NAND_CTL_BASE偏移地址*/#define oNFADDR 0x0c /* NFADDR相对于NAND_CTL_BASE偏移地址*/#define oNFDATA 0x10 /* NFDATA相对于NAND_CTL_BASE偏移地址*/#define oNFCMD 0x08 /* NFCMD相对于NAND_CTL_BASE偏移地址*/#define oNFSTAT 0x20 /* NFSTAT相对于NAND_CTL_BASE偏移地址*/#define oNFECC 0x2c /* NFECC相对于NAND_CTL_BASE偏移地址*/ NAND Flash各个控制寄存器的设置在S3C2440的数据手册有详细说明,这里就不介绍了。 代码中nand_read_ll函数的作用是在NAND Flash中搬运U-Boot到RAM,该函数在board/samsung/mini2440/nand_read.c中定义。 NAND Flash根据page大小可分为2种: 512B/page和2048B/page的。这两种NAND Flash的读操作是不同的。因此就需要U-Boot识别到NAND Flash的类型,然后采用相应的读操作,也就是说nand_read_ll函数要能自动适应两种NAND Flash。 参考S3C2440的数据手册可以知道:根据NFCONF寄存器的Bit3(AdvFlash (Read only))和Bit2 (PageSize (Read only))可以判断NAND Flash的类型。Bit2、Bit3与NAND Flash的block类型的关系如下表所示:表 2.4 NFCONF的Bit3、Bit2与NAND Flash的关系 Bit2 Bit3 0 1 0256 B/page512 B/page11024 B/page2048 B/page 由于的NAND Flash只有512B/page和2048 B/page这两种,因此根据NFCONF寄存器的Bit3即可区分这两种NAND Flash了。 完整代码见board/samsung/mini2440/nand_read.c中的nand_read_ll函数,这里给出伪代码:int nand_read_ll(unsigned char *buf, unsigned long start_addr, int size){//根据NFCONF寄存器的Bit3来区分2种NAND Flash if( NFCONF & 0x8 ) /* Bit是1,表示是2KB/page的NAND Flash */ { //////////////////////////////////// 读取2K block 的NAND Flash //////////////////////////////////// } else /* Bit是0,表示是512B/page的NAND Flash */ { ///////////////////////////////////// 读取512B block 的NAND Flash ///////////////////////////////////// } return 0;}(10)设置堆栈 /* 设置堆栈 */stack_setup: ldr r0, _TEXT_BASE