{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 mamingliang 的文章《嵌入式linux之高级c语言专题--指针3》','https://www.xiaopingtou.net/article-72900.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
第三部分:嵌入式linux高级c--指针3
2.1指针数组与数组指针
2.1.1字面意思来理解指针数组与数组指针
(1)指针数组的实质是一个数组,这个数组中存储的内容全部是指针变量。 (2)数组指针的实质是一个指针,这个指针指向的是一个数组。2.1.2、分析指针数组与数组指针的表达式
看变量定义的一般规律: 第一:找核心(如果核心和*结合,表示核心是指针;如果核心和[]结合,表示核心是数组;如果核心和()结合,表示核心是函数)。 第二:向外扩展(找完核心,继续向外找其他符号) 题目1:int *p[5];int (*p)[5];int *(p[5]); 第一题分析:核心是p,因为【】的优先级比*高,故p和【】结合后是一个数组,数组大小为5个。再和*号结合,则数组中的元素都是指针,指针指向的元素类型是int类型的;整个符号是一个指针数组。 第二题分析:核心是p,p先和*结合,故p是一个指针;p再和【】结合,则p是指向数组(大小为5)的指针;数组中存的元素是int类型。整个符号是一个数组指针。 第三题分析:第三题和第一题的解析一样。即int *p[5]; 和int *(p[5]); 是等价的。2.2.函数指针与typedef
2.2.1函数指针的实质
(1)函数指针的实质还是指针,还是指针变量。本身占4字节(在32位系统中,所有的指针都是4字节) (2)函数指针、数组指针、普通指针之间并没有本质区别,区别在于指针指向的东西是个什么玩意。 (3)函数的实质是一段代码,这一段代码在内存中是连续分布的(一个函数的大括号括起来的所有语句将来编译出来生成的可执行程序是连续的),所以对于函数来说很关键的就是函数中的第一句代码的地址,这个地址就是所谓的函数地址,在C语言中用函数名这个符号来表示。 综上,结合函数的实质,函数指针其实就是一个普通变量,这个普通变量的类型是函数指针变量类型,它的值就是某个函数的地址(也就是它的函数名这个符号在编译器中对应的值)2.2.2函数指针的书写和分析方法
C语言本身是强类型语言(每一个变量都有自己的变量类型),编译器可以帮我们做严格的类型检查。 题目1:数组指针的定义和使 数组是int a[10];对应的数组指针:int (*变量名)[10];类型是:int (*)[10];#include
int main(void)
{
int a[10];
int (*p1)[10];
int (*p2)[5];
int *p3;
p1 = &a;
//注意以下的三种情况都出现以下警告(指针类型不匹配)
//warning: assignment from incompatible pointer type [enabled by default]
p1 = a;
p2 = &a;
p3 = &a;
return 0;
}
题目2:函数指针的定义与使用 函数是:void func(void);对应的函数指针:void (*p)(void);类型是:void (*)(void);
#include
void func(void)
{
printf("test for function pointer
");
}
int main(void)
{
void (*pFunc)(void); //函数指针定义
pFunc = func; //第一种方法初始化指针
pFunc = &func; //第二种方法初始化指针
pFunc(); //用指针调用函数func();
return 0;
}
对比题目1和2我们发现函数名和数组名最大的区别就是:函数名做右值时加不加&效果和意义都是一样的;但是数组名做右值时加不加&意义就不一样,如果直接用数组名给数组指针赋值,则会出现类型不匹配的警告。 原因就是编译器规定的! 题目3:写一个复杂的函数指针的实例:譬如函数是strcpy函数(char * strcpy(char *dest, const char *src);) 对应的函数指针是:char *(*pFunc)(char *dest, const char *src); 总结:定义指针变量的方法(普通变量指针,数组指针,函数指针)就是讲其核心名字替换成(*+名字)就是其对于的指针定义. 变量/函数 指针 Int a; Int (*p);/Int *p; Int a[10]; Int (*p)[10] Void a(void); Int (*p)(void)
2.2.3 typedef关键字的用法
(1)typedef是C语言中一个关键字,作用是用来定义(或者叫重命名类型) (2)C语言中的类型一共有2种:一种是编译器定义的原生类型(基础数据类型,如int、double之类的);第二种是用户自定义类型,不是语言自带的是程序员自己定义的(譬如数组类型、结构体类型、函数类型·····)。 (3)我们今天讲的数组指针、指针数组、函数指针等都属于用户自定义类型。 (4)有时候自定义类型太长了,用起来不方便,所以用typedef给它重命名一个短点的名字。 (5)注意:typedef是给类型重命名,也就是说typedef加工出来的都是类型,而不是变量。 定义函数char * strcpy(char *dest, const char *src);的指针第一种方法: char *(*p)(char *dest, const char *src);
第二种方法:typedef char *(*pType)(char *dest, const char *src); pType p;
2.3.函数指针实战1
2.3.1用函数指针调用执行函数
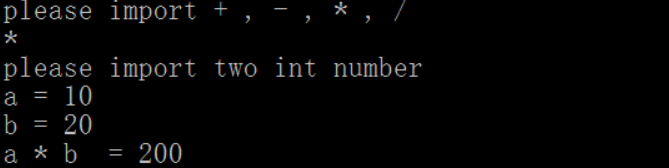
题目1:用函数指针来制作一个简单计算器#include
//定义了一个类型pFunc
typedef int (*pFunc)(int, int);
int add(int a, int b);
int sub(int a, int b);
int multiply(int a, int b);
int divide(int a, int b); int main(void)
{
pFunc p1 = NULL; //用pFunc 定义一个函数指针变量
char c=0;
int a=0,b=0;
printf("please import + , - , * , /
");
scanf("%c",&c);
switch (c)
{
case '+': p1 = add;break;
case '-': p1 = sub;break;
case '*': p1 = multiply;break;
case '/': p1 = divide;break;
default : p1 = NULL ; break;
}
printf("please import two int number
");
printf("a = ");
scanf("%d",&a);
printf("b = ");
scanf("%d",&b);
printf("a %c b = %d
",c,p1(a,b));
return 0;
}
int add(int a, int b) //加法
{
return a + b;
}
int sub(int a, int b) //减法
{
return a - b;
}
int multiply(int a, int b)// 乘法
{
return a * b;
}
int divide(int a, int b) //除法
{
return a / b;
}
2.4.结构体内嵌函数指针实现分层
第一:分层写代码的思路是:有多个层次结合来完成任务,每个层次专注各自不同的领域和任务;不同层次之间用头文件来交互。 第二:分层之后上层为下层提供服务,上层写的代码是为了在下层中被调用。 第三:上层注重业务逻辑,与我们最终的目标相直接关联,而没有具体干活的函数。 第四:下层注重实际干活的函数,注重为上层填充变量,并且将变量传递给上层中的函数(其实就是调用上层提供的接口函数)来完成任务。 第五:下层代码中其实核心是一个结构体变量(譬如本例中的struct cal_t),写下层代码的逻辑其实很简单:第一步先定义结构体变量;第二步填充结构体变量;第三步调用上层写好的接口函数,把结构体变量传给它既可。2.5.再论typedef
2.5.1、C语言的2种类型:内建类型与用户自定义类型
(1)内建类型ADT、自定义类型UDT2.5.2、typedef定义(或者叫重命名)类型而不是变量
(1)类型是一个数据模板,变量是一个实在的数据。类型是不占内存的,而变量是占内存的。 (2)面向对象的语言中:类型就是类class,变量就是对象。2.5.3、typedef与#define宏的区别
typedef char *pChar; //新的类型
#define pChar char * //只是替换代码中的pchar的内容为char*
2.5.4、typedef与结构体
第一种:结构体的定义与使用//定义结构体类型:struct student
typedef struct student
{
char name[20];
int age;
};
struct student s1; //定义struct student类型的变量
第二种:结构体定义中添加typedef //定义结构体类型有两个名字(1)struct student (2)student_t //定义结构体类型有两个名字(1)struct student* (2)pStudent*
typedef struct student
{
char name[20];
int age;
}student_t,*pStudent;
student_t s1; //定义struct student类型的变量
(1)结构体在使用时都是先定义结构体类型,再用结构体类型去定义变量。 (2)C语言语法规定,结构体类型使用时必须是struct结构体类型名 结构体变量名;这样的方式来定义变量。 (3)使用typedef一次定义2个类型,分别是结构体变量类型,和结构体变量指针类型。
2.5.5、typedef与const
(1)typedef int *PINT; const PINT p2; 相当于是int *const p2;
(2)typedef int *PINT; PINT const p2; 相当于是int *const p2;
(3)如果确实想得到const int *p;这种效果,只能typedef const int *CPINT; CPINT p1;
2.5.6、使用typedef的重要意义(2个:简化类型、创造平台无关类型)
(1)简化类型的描述。char *(*)(char *, char *);
typedef char *(*pFunc)(char *, char *);
(2)很多编程体系下,人们倾向于不使用int、double等C语言内建类型,因为这些类型本身和平台是相关的(譬如int在16位机器上是16位的,在32位机器上就是32位的)。为了解决这个问题,很多程序使用自定义的中间类型来做缓冲。譬如linux内核中大量使用了这种技术.
内核中先定义:typedef int size_t;然后在特定的编码需要下用size_t来替代int(譬如可能还有typedef
int len_t)
(3)STM32的库中全部使用了自定义类型,譬如typedef
volatile unsigned int vu32