{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 电子机器人 的文章《Linux内核驱动之DDR3》','https://www.xiaopingtou.net/article-73407.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
1 相关原理
DDR3内部相当于存储表格,和表格的检索相似,需要先指定 行地址(row),再指定列地址(column),这样就可以准确的找到需要的单元格。对于DDR3内存,单元格称为基本存储单元(也就是每次能从该DDR3芯片读取的最小数据),存储表格称为逻辑bank(DDR3内存芯片都是8个bank,也就是说有8个这样的存储表格)
所以寻址的流程是先指定bank地址,再指定行地址(row),最后指列地址(column)来确定基本存储单元,每个基本存储单元的大小等于该DDR3芯片的数据线位宽,也就是每次能从单个DDR3芯片读取的最小数据长度。
2 地址线和内存容量分析 由上文可知要寻址DDR3芯片的基本存储单元需要指定3个地址: bank地址,行地址(row),列地址(column) 下面以三星MT41J1G4,MT41J512M8,MT41J256M16进行分析 MT41J1G4 – 128 Meg x 4 x 8 banks 、MT41J512M8 – 64 Meg x 8 x 8 banks 、MT41J256M16 – 32 Meg x 16 x 8 banks 三个型号的容量都是一样,仅仅只是数据线位宽不一样,从上述扩展命名可以分析DDR3芯片的地址线数量,数据线位宽,整体容量 比如:
MT41J256M16 - 32 Meg x 16 x 8 banks 单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2 每个bank大小是32M*16 bit = 64MB 有16根数据线即基本存储单元是16bit
每个bank有32M个基本存储单元,总共有32M*8=256M个地址 从datasheet分析有15bit row地址和10bit column地址。但是芯片只提供了15根地址线,不够25根。 其实原因是行地址线RA0-RA14和列地址线CA0-CA9地址线分时共用(反正是先取行地址再取列地址)所以只需要15根地址线就可以 每个bank总共有2^15 * 2^10 = 32M个基本存储单元 ,然后每个基本单元的大小是16bit所以总大小是32M*16bit*8 = 4Gbit
MT41J512M8 – 64 Meg x 8 x 8 banks 单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2 每个bank大小是64M*8bit = 64MB 有8根数据线即基本存储单元是8bit 每个bank有64M个基本存储单元,总共有64M*8=512M个地址 从datasheet分析有16bit row地址和10bit column地址。但是芯片只提供了16根地址线,不够26根。 原因也是行地址线RA0-RA15和列地址线CA0-CA9地址线分时共用 所以只需要16根地址线就可以 每个bank总共有2^16* 2^10 = 64M个基本存储单元 然后每个基本单元的大小是8bit所以总大小是64M * 8bit*8 = 4Gbit
MT41J1G4 – 128 Meg x 4 x 8 banks 单个DDR3芯片内部有8个banks 每个bank大小是128M* 4bit = 64MB 有4根数据线即基本存储单元是4bit 每个bank有128M个基本存储单元,总共是128M*8=1G个的地址 从datasheet分析有16bit row地址和11bit column地址 由于行地址线RA0-RA15和列地址线CA0-CA9,CA11地址线分时共用 所以只需要16根地址线就可以 每个bank总共有2^16* 2^11 = 128M个基本存储单元 然后每个基本单元的大小是4bit所以总大小是128M *4bit*8 = 4Gbit
注意DDR3芯片的PAGESIZE = 2^column * 数据线位宽/8 由此可知
MT41J1G4 – 128 Meg x 4 x 8 banks PAGESIZE = 2^11 * 4/8 = 1KB
MT41J512M8 – 64 Meg x 8 x 8 banks PAGESIZE = 2^10 * 8/8 = 1KB
MT41J256M16 – 32 Meg x 16 x 8 banks PAGESIZE = 2^10 * 16/8 = 2KB
3 DDR3控制器16bit/32bit概念
这儿所说的16bit/32bit指的是整个内存控制器以多长为单位进行存储,而不是单个DDR3芯片的基本存储单元
32bit表示内存控制器以32bit为单位访问内存,即给定一个内存地址。内存芯片会给内存控制器 32bit的数据到数据线上,当然该32bit数据可能不来自同一个DDR3芯片上,16bit与此类似 下面分析用两个16bit的DDR3内存如何拼成32bitDDR3 第一片16bit DDR3的BA0,BA1,BA2连接CPU的BA0, BA1, BA2 第二片16bit DDR3 的BA0,BA1,BA2连接CPU 的BA0, BA1, BA2 第一片16bit DDR3的A0~A13连接CPU的A0~A13 第二片16bit DDR3的A0~A13连接CPU的A0~A13 第一片16bit DDR3的D0~D15连接CPU的D0~D15 第二片16bit DDR3的D0~D15连接CPU的D16~D31 分析下该实例。
bank地址线是3bit所以单个16bit DDR3内部有8个bank. 行地址(row)A0~A13共14bit说明每个bank有2^14行 列地址(column)A0~A9共10bit说明每个bank有2^10列 每个bank大小是2^14 * 2^10 * 16 = 16M * 16bit = 32MB 每个bank有16M个基本存储单元,总共有16M*8=128M个地址 单个芯片总大小是 32MB * 8 = 256MB
从前面的连线可知两块16bit DDR3的BA0~BA2和D0~D14是并行连接到内存控制器,所以内存控制器认为只有一块内存,访问的时候按照BA0~BA2和A0~A13给出地址。两块16bit DDR3都收到了该地址,给出的反应是要么将给定地址上的2个字节读到数据线上,要么是将数据线上的两个字节写入到指定的地址。
此时内存控制认为自己成功的访问的了一块32bit的内存, 所以内存控制器每给出一个地址,将访问4个字节的数据,读取/写入。这4字节数据对应到内存控制器的D0~D31,又分别被连接到两片DDR3芯片的D0~D15,这样32bit就被拆成了两个16bit分别去访问单个DDR3芯片的基本存储单元。
注意:尽管DDR3芯片识别的地址只有128M个,但由于内存控制器每访问一个内存地址,将访问4个字节数据,所以对于内存控制器来说,能访问的内存大小仍是512M,只不过在内存控制器将地址传给DDR3芯片时,低两位被忽略,也就是说DDR3芯片识别的地址只有128M个。
比如内存控制器访问地址0x00000000,0x00000001,0x00000002,0x00000003,但对DDR3来说,都是访问地址0x00000000。
一 内存映射的概念 上文中的内存寻址主要讲的是内存控制器如何去访问DDR3芯片基本存储单元
本文中的内存映射主要讲的是如何将内存控制器管理的DDR3芯片地址空间映射到SOC芯片为DDR3预留的地址范围。比如基于ARM的SOC芯片,DDR3的预留地址一般都是0x80000000,如果没有使用内存映射,SOC去访问0x80000000地址时会造成整个系统崩溃,因为访问的地址并不存在实际的内存
DDR3控制器有两种映射模式:非交织映射和交织映射(interlave). 交织映射,即双通道内存技术,当访问在控制器A上进行时,控制器B为下一次访问做准备,数据访问在两个控制器上交替进行,从而提高DDR吞吐率。支持128byte,256byte,512byte的交织模式。如果要使用交织模式,要保证有两个内存控制器以及两个内存控制器有对称的物理内存(即两块内存大小一致;在各自的控制器上的地址映射一致)
非交织映射,即两个内存控制器的内存映射在各自的映射范围内线性递增。对于只存在1个内存控制器或者只使用1个内存控制器时则只能使用非交织的线性映射模式。
二 内存映射具体介绍
下面以DM385和DM8168来介绍内存映射 :
DM385有1个DDR控制器EMIF0支持JEDEC标准的DDR2,DDR3芯片. 当然DM385只能使用非交织映射模式 数据总线支持16bit和32bit. DM385有4个内存映射寄存器,所以最多可以映射4段地址空间 DMM_LISA_MAP__0, DMM_LISA_MAP__1, DMM_LISA_MAP__2, DMM_LISA_MAP__3 下图是该寄存器的具体介绍

SYS_ADDR: 映射到SOC系统上的物理地址, 比如需要映射到0x8000000则SYS_ADDR = 80
SYS_SIZE: 映射的内存大小,讲的是主要给系统映射了多大的内存
SDRC_INTL: 是否使用交织模式,以及使用何种交织模式映射
SDRC_MAP: 交织映射则为3,否则为1或者2
SDRC_ADDR:内存控制器的高位地址即没有映射前他的内存地址 一般都是从0x00000000开始
下面是我们DM385板卡的内存映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80400100 #define DDR3_DMM_LISA_MAP__4 0xB0400110
使用了两个映射寄存器,所以主要映射了两段地址空间
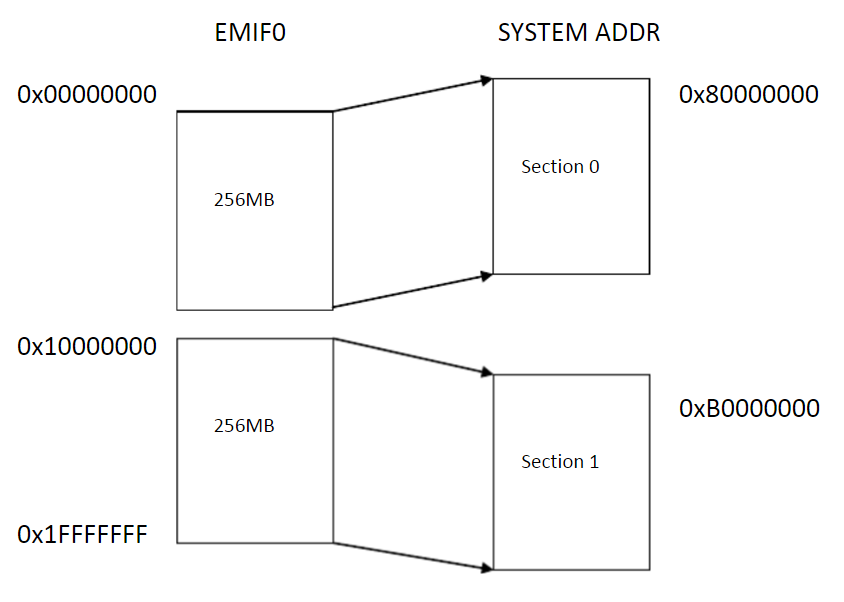
从上图可以看出来
第一段映射是将EMIF0的0x00000000映射到SOC系统地址0x8000000上,映射长度为256MB
第二段映射是将EMIF0的0x10000000映射到SOC系统地址0xB000000上,映射长度为256MB
下图是访问模式,线性访问物理地址

由于DM385只有一个内存控制器EMIF0所以只能非交织映射 当然对于上述映射方式可以变为如下映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x00 #define DDR3_DMM_LISA_MAP__4 0x80500100
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是512MB
DM8168内存映射
2个DDR控制器EMIF0和EMIF1,支持JEDEC标准的DDR2,DDR3芯片 DM8168支持非交织模式映射和交织模式映射 数据总线支持16bit和32bit.
DM8168有4个内存映射寄存器,所以最多可以映射4段地址空间 下面是我们DM8168板卡的内存映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80640300 #define DDR3_DMM_LISA_MAP__4 0xC0640320 使用了两个映射寄存器,所以主要映射了两段地址空间

从上图可知
第一段映射是将EMIF0和EMIF1的0x0000000交织映射到SOC系统的0x80000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
第二段映射是将EMIF0和EMIF1的0x2000000交织映射到SOC系统的0xC0000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
下图是访问模式,交织访问物理地址,128字节交替映射,在交织访问模式下,系统送出的物理地址在两个内存控制器上交替访问

当然也可以使用如下非交织映射
#define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80600100 #define DDR3_DMM_LISA_MAP__4 0xC0600200
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是1GB
将EMIF1的0x00000000映射到SOC系统地址0xC0000000,映射长度是1GB
使用下图的线性访问模式
三 DDR3引脚描述
4bit和8bit位宽芯片一般采用78球FBGA封装 16bit位宽芯片一般采用96球FBGA封装 下列信号方向都是针对DDR3芯片来说的 A0-A9,A10/AP,A11,A12/BC#,A13,A14 input 地址输入信号,行地址线和列地址线分时使用
A10/AP 表示PRECHARGE命令期间对某个bank预充电auto-precharge A10为低则有BA[0,2]来决定哪个bank进行auto-precharge,A10为高电平表示对所有bank进行auto-precharge
BA0,BA1,BA2 input
bank地址输入信号,三个bank地址线表明该DDR3内部有8个bank LOAD MODE命令期间定义DDR3芯片使用哪个模式(MR0,MR1,MR2)
CK,CK# input
差分时钟输入,所有控制和地址输入信号在CK上升沿和CK#的下降沿交叉处被采样,输出数据选通(DQS,DQS#)参考CK和CK#的交叉点
CKE input
时钟使能信号,高电平有效,CKE为低电平时提供PRECHARGE POWN-DOWN和SELF REFRESH操作(对所有bank里行有效)
CS# input
片选使能信号当CS#为高的时候,所有的命令被屏蔽,CS#提供了多RANK系统的RANK选择功能,CS#是命令代码的一部分
DM(mask) input
数据输入屏蔽,每8bit数据对应一个DM信号,在写期间,当伴随输入数据的DM信号被采样为高的时候,这8bit的输入数据视为无效。
DM信号相当于就是掩码控制位,该信号在读操作时没有用:比如在读32bit数据,但只需要8bit数据,在软件里将高24bit置0就行,有没有DM信号都关系不大,但执行写操作时,如果没有DM信号,可能程序只需要写8bit数据,但是物理连接是32bit到DDR3,只要WR信号有效,32bit数据就全部写到DDR3里边去了,高24bit数据就被覆盖了,有了DM信号它对应的8bit数据就会被忽略,这样就不会覆盖其他数据了。对于4bit位宽DDR3,两个芯片共用一个DM信号,对于8bit位宽DDR3芯片一个芯片占用一个DM信号,对于16bit位宽DDR3芯片则需要2个DM信号
虽然DM仅作为输入脚,但是,DM负载被设计成与DQ和DQS脚负载相匹配。DM的参考是VREFCA。DM可选作为TDQS
ODT input
片上终端使能。ODT使能(高)和禁止(低)片内终端电阻。在正常操作使能的时候,ODT仅对下面的管脚有效:DQ[15:0],DQS,DQS#和DM。如果通过LOAD MODE命令禁止,ODT输入被忽略
RAS#,CAS#,WE# input 命令输入,这三个信号,连同CS#用来定义一个命令
RESET# input 复位,低有效,参考是VSS
DQ0-DQ7/ DQ0-DQ15 I/O 数据输入/输出。双向数据
DQS,DQS# I/O
数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。
DQS是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每8bit数据都有一个DQS信号线,它是双向的,在写入时它用来传送由内存控制器发来的DQS信号,读取时,则由芯片生成DQS向内存控制器发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。
DQS在读取时与数据同步传输
而在接收方,一切必须保证同步接收,不能有偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
TDQS,TDQS# output
终端数据选通。当TDQS使能时,DM禁止,TDQS和TDDS提供终端电阻。 VDD
电源电压,1.5V+/-0.075V VDDQ
DQ电源,1.5V+/-0.075V。为了降低噪声,在芯片上进行了隔离 VREFCA
数据的参考电压。VREFDQ在所有时刻(除了自刷新)都必须保持规定的电压 VSS
地 VSSQ
DQ地,为了降低噪声,在芯片上进行了隔离 ZQ
输出驱动校准的外部参考。这个脚应该连接240ohm电阻到VSSQ
2 地址线和内存容量分析 由上文可知要寻址DDR3芯片的基本存储单元需要指定3个地址: bank地址,行地址(row),列地址(column) 下面以三星MT41J1G4,MT41J512M8,MT41J256M16进行分析 MT41J1G4 – 128 Meg x 4 x 8 banks 、MT41J512M8 – 64 Meg x 8 x 8 banks 、MT41J256M16 – 32 Meg x 16 x 8 banks 三个型号的容量都是一样,仅仅只是数据线位宽不一样,从上述扩展命名可以分析DDR3芯片的地址线数量,数据线位宽,整体容量 比如:
MT41J256M16 - 32 Meg x 16 x 8 banks 单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2 每个bank大小是32M*16 bit = 64MB 有16根数据线即基本存储单元是16bit
每个bank有32M个基本存储单元,总共有32M*8=256M个地址 从datasheet分析有15bit row地址和10bit column地址。但是芯片只提供了15根地址线,不够25根。 其实原因是行地址线RA0-RA14和列地址线CA0-CA9地址线分时共用(反正是先取行地址再取列地址)所以只需要15根地址线就可以 每个bank总共有2^15 * 2^10 = 32M个基本存储单元 ,然后每个基本单元的大小是16bit所以总大小是32M*16bit*8 = 4Gbit
MT41J512M8 – 64 Meg x 8 x 8 banks 单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2 每个bank大小是64M*8bit = 64MB 有8根数据线即基本存储单元是8bit 每个bank有64M个基本存储单元,总共有64M*8=512M个地址 从datasheet分析有16bit row地址和10bit column地址。但是芯片只提供了16根地址线,不够26根。 原因也是行地址线RA0-RA15和列地址线CA0-CA9地址线分时共用 所以只需要16根地址线就可以 每个bank总共有2^16* 2^10 = 64M个基本存储单元 然后每个基本单元的大小是8bit所以总大小是64M * 8bit*8 = 4Gbit
MT41J1G4 – 128 Meg x 4 x 8 banks 单个DDR3芯片内部有8个banks 每个bank大小是128M* 4bit = 64MB 有4根数据线即基本存储单元是4bit 每个bank有128M个基本存储单元,总共是128M*8=1G个的地址 从datasheet分析有16bit row地址和11bit column地址 由于行地址线RA0-RA15和列地址线CA0-CA9,CA11地址线分时共用 所以只需要16根地址线就可以 每个bank总共有2^16* 2^11 = 128M个基本存储单元 然后每个基本单元的大小是4bit所以总大小是128M *4bit*8 = 4Gbit
注意DDR3芯片的PAGESIZE = 2^column * 数据线位宽/8 由此可知
MT41J1G4 – 128 Meg x 4 x 8 banks PAGESIZE = 2^11 * 4/8 = 1KB
MT41J512M8 – 64 Meg x 8 x 8 banks PAGESIZE = 2^10 * 8/8 = 1KB
MT41J256M16 – 32 Meg x 16 x 8 banks PAGESIZE = 2^10 * 16/8 = 2KB
3 DDR3控制器16bit/32bit概念
这儿所说的16bit/32bit指的是整个内存控制器以多长为单位进行存储,而不是单个DDR3芯片的基本存储单元
32bit表示内存控制器以32bit为单位访问内存,即给定一个内存地址。内存芯片会给内存控制器 32bit的数据到数据线上,当然该32bit数据可能不来自同一个DDR3芯片上,16bit与此类似 下面分析用两个16bit的DDR3内存如何拼成32bitDDR3 第一片16bit DDR3的BA0,BA1,BA2连接CPU的BA0, BA1, BA2 第二片16bit DDR3 的BA0,BA1,BA2连接CPU 的BA0, BA1, BA2 第一片16bit DDR3的A0~A13连接CPU的A0~A13 第二片16bit DDR3的A0~A13连接CPU的A0~A13 第一片16bit DDR3的D0~D15连接CPU的D0~D15 第二片16bit DDR3的D0~D15连接CPU的D16~D31 分析下该实例。
bank地址线是3bit所以单个16bit DDR3内部有8个bank. 行地址(row)A0~A13共14bit说明每个bank有2^14行 列地址(column)A0~A9共10bit说明每个bank有2^10列 每个bank大小是2^14 * 2^10 * 16 = 16M * 16bit = 32MB 每个bank有16M个基本存储单元,总共有16M*8=128M个地址 单个芯片总大小是 32MB * 8 = 256MB
从前面的连线可知两块16bit DDR3的BA0~BA2和D0~D14是并行连接到内存控制器,所以内存控制器认为只有一块内存,访问的时候按照BA0~BA2和A0~A13给出地址。两块16bit DDR3都收到了该地址,给出的反应是要么将给定地址上的2个字节读到数据线上,要么是将数据线上的两个字节写入到指定的地址。
此时内存控制认为自己成功的访问的了一块32bit的内存, 所以内存控制器每给出一个地址,将访问4个字节的数据,读取/写入。这4字节数据对应到内存控制器的D0~D31,又分别被连接到两片DDR3芯片的D0~D15,这样32bit就被拆成了两个16bit分别去访问单个DDR3芯片的基本存储单元。
注意:尽管DDR3芯片识别的地址只有128M个,但由于内存控制器每访问一个内存地址,将访问4个字节数据,所以对于内存控制器来说,能访问的内存大小仍是512M,只不过在内存控制器将地址传给DDR3芯片时,低两位被忽略,也就是说DDR3芯片识别的地址只有128M个。
比如内存控制器访问地址0x00000000,0x00000001,0x00000002,0x00000003,但对DDR3来说,都是访问地址0x00000000。
一 内存映射的概念 上文中的内存寻址主要讲的是内存控制器如何去访问DDR3芯片基本存储单元
本文中的内存映射主要讲的是如何将内存控制器管理的DDR3芯片地址空间映射到SOC芯片为DDR3预留的地址范围。比如基于ARM的SOC芯片,DDR3的预留地址一般都是0x80000000,如果没有使用内存映射,SOC去访问0x80000000地址时会造成整个系统崩溃,因为访问的地址并不存在实际的内存
DDR3控制器有两种映射模式:非交织映射和交织映射(interlave). 交织映射,即双通道内存技术,当访问在控制器A上进行时,控制器B为下一次访问做准备,数据访问在两个控制器上交替进行,从而提高DDR吞吐率。支持128byte,256byte,512byte的交织模式。如果要使用交织模式,要保证有两个内存控制器以及两个内存控制器有对称的物理内存(即两块内存大小一致;在各自的控制器上的地址映射一致)
非交织映射,即两个内存控制器的内存映射在各自的映射范围内线性递增。对于只存在1个内存控制器或者只使用1个内存控制器时则只能使用非交织的线性映射模式。
二 内存映射具体介绍
下面以DM385和DM8168来介绍内存映射 :
DM385有1个DDR控制器EMIF0支持JEDEC标准的DDR2,DDR3芯片. 当然DM385只能使用非交织映射模式 数据总线支持16bit和32bit. DM385有4个内存映射寄存器,所以最多可以映射4段地址空间 DMM_LISA_MAP__0, DMM_LISA_MAP__1, DMM_LISA_MAP__2, DMM_LISA_MAP__3 下图是该寄存器的具体介绍
SYS_ADDR: 映射到SOC系统上的物理地址, 比如需要映射到0x8000000则SYS_ADDR = 80
SYS_SIZE: 映射的内存大小,讲的是主要给系统映射了多大的内存
SDRC_INTL: 是否使用交织模式,以及使用何种交织模式映射
SDRC_MAP: 交织映射则为3,否则为1或者2
SDRC_ADDR:内存控制器的高位地址即没有映射前他的内存地址 一般都是从0x00000000开始
下面是我们DM385板卡的内存映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80400100 #define DDR3_DMM_LISA_MAP__4 0xB0400110
使用了两个映射寄存器,所以主要映射了两段地址空间
从上图可以看出来
第一段映射是将EMIF0的0x00000000映射到SOC系统地址0x8000000上,映射长度为256MB
第二段映射是将EMIF0的0x10000000映射到SOC系统地址0xB000000上,映射长度为256MB
下图是访问模式,线性访问物理地址
由于DM385只有一个内存控制器EMIF0所以只能非交织映射 当然对于上述映射方式可以变为如下映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x00 #define DDR3_DMM_LISA_MAP__4 0x80500100
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是512MB
DM8168内存映射
2个DDR控制器EMIF0和EMIF1,支持JEDEC标准的DDR2,DDR3芯片 DM8168支持非交织模式映射和交织模式映射 数据总线支持16bit和32bit.
DM8168有4个内存映射寄存器,所以最多可以映射4段地址空间 下面是我们DM8168板卡的内存映射 #define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80640300 #define DDR3_DMM_LISA_MAP__4 0xC0640320 使用了两个映射寄存器,所以主要映射了两段地址空间
从上图可知
第一段映射是将EMIF0和EMIF1的0x0000000交织映射到SOC系统的0x80000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
第二段映射是将EMIF0和EMIF1的0x2000000交织映射到SOC系统的0xC0000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
下图是访问模式,交织访问物理地址,128字节交替映射,在交织访问模式下,系统送出的物理地址在两个内存控制器上交替访问
当然也可以使用如下非交织映射
#define DDR3_DMM_LISA_MAP__0 0x00 #define DDR3_DMM_LISA_MAP__1 0x00 #define DDR3_DMM_LISA_MAP__3 0x80600100 #define DDR3_DMM_LISA_MAP__4 0xC0600200
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是1GB
将EMIF1的0x00000000映射到SOC系统地址0xC0000000,映射长度是1GB
使用下图的线性访问模式
三 DDR3引脚描述
4bit和8bit位宽芯片一般采用78球FBGA封装 16bit位宽芯片一般采用96球FBGA封装 下列信号方向都是针对DDR3芯片来说的 A0-A9,A10/AP,A11,A12/BC#,A13,A14 input 地址输入信号,行地址线和列地址线分时使用
A10/AP 表示PRECHARGE命令期间对某个bank预充电auto-precharge A10为低则有BA[0,2]来决定哪个bank进行auto-precharge,A10为高电平表示对所有bank进行auto-precharge
BA0,BA1,BA2 input
bank地址输入信号,三个bank地址线表明该DDR3内部有8个bank LOAD MODE命令期间定义DDR3芯片使用哪个模式(MR0,MR1,MR2)
CK,CK# input
差分时钟输入,所有控制和地址输入信号在CK上升沿和CK#的下降沿交叉处被采样,输出数据选通(DQS,DQS#)参考CK和CK#的交叉点
CKE input
时钟使能信号,高电平有效,CKE为低电平时提供PRECHARGE POWN-DOWN和SELF REFRESH操作(对所有bank里行有效)
CS# input
片选使能信号当CS#为高的时候,所有的命令被屏蔽,CS#提供了多RANK系统的RANK选择功能,CS#是命令代码的一部分
DM(mask) input
数据输入屏蔽,每8bit数据对应一个DM信号,在写期间,当伴随输入数据的DM信号被采样为高的时候,这8bit的输入数据视为无效。
DM信号相当于就是掩码控制位,该信号在读操作时没有用:比如在读32bit数据,但只需要8bit数据,在软件里将高24bit置0就行,有没有DM信号都关系不大,但执行写操作时,如果没有DM信号,可能程序只需要写8bit数据,但是物理连接是32bit到DDR3,只要WR信号有效,32bit数据就全部写到DDR3里边去了,高24bit数据就被覆盖了,有了DM信号它对应的8bit数据就会被忽略,这样就不会覆盖其他数据了。对于4bit位宽DDR3,两个芯片共用一个DM信号,对于8bit位宽DDR3芯片一个芯片占用一个DM信号,对于16bit位宽DDR3芯片则需要2个DM信号
虽然DM仅作为输入脚,但是,DM负载被设计成与DQ和DQS脚负载相匹配。DM的参考是VREFCA。DM可选作为TDQS
ODT input
片上终端使能。ODT使能(高)和禁止(低)片内终端电阻。在正常操作使能的时候,ODT仅对下面的管脚有效:DQ[15:0],DQS,DQS#和DM。如果通过LOAD MODE命令禁止,ODT输入被忽略
RAS#,CAS#,WE# input 命令输入,这三个信号,连同CS#用来定义一个命令
RESET# input 复位,低有效,参考是VSS
DQ0-DQ7/ DQ0-DQ15 I/O 数据输入/输出。双向数据
DQS,DQS# I/O
数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。
DQS是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每8bit数据都有一个DQS信号线,它是双向的,在写入时它用来传送由内存控制器发来的DQS信号,读取时,则由芯片生成DQS向内存控制器发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。
DQS在读取时与数据同步传输
而在接收方,一切必须保证同步接收,不能有偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
TDQS,TDQS# output
终端数据选通。当TDQS使能时,DM禁止,TDQS和TDDS提供终端电阻。 VDD
电源电压,1.5V+/-0.075V VDDQ
DQ电源,1.5V+/-0.075V。为了降低噪声,在芯片上进行了隔离 VREFCA
数据的参考电压。VREFDQ在所有时刻(除了自刷新)都必须保持规定的电压 VSS
地 VSSQ
DQ地,为了降低噪声,在芯片上进行了隔离 ZQ
输出驱动校准的外部参考。这个脚应该连接240ohm电阻到VSSQ