{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 liuyi1207164339 的文章《谈GPU的作用、原理及与CPU、DSP的区别》','https://www.xiaopingtou.net/article-75691.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
GPU是显示卡的“心脏”,也就相当于CPU在电脑中的作用,它决定了该显卡的档次和大部分性能,同时也是2D显示卡和3D显示卡的区别依据。2D显示芯片在处理3D图像和特效时主要依赖CPU的处理能力,称为“软加速”。3D显示芯片是将三维图像和特效处理功能集中在显示芯片内,也即所谓的“硬件加速”功能。显示芯片通常是显示卡上最大的芯片(也是引脚最多的)。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时。GPU所采用的核心技术有硬件T&l、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。
主要作用
今天,GPU已经不再局限于3D图形处理了,GPU通用计算技术发展已经引起业界不少的关注,事实也证明在浮点运算、并行计算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能,如此强悍的“新星”难免会让CPU厂商老大英特尔为未来而紧张,NVIDIA和英特尔也经常为CPU和GPU谁更重要而展开口水战。GPU通用计算方面的标准目前有OPEN CL、CUDA、ATI STREAM.其中,OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景,AMD-ATI、NVIDIA现在的产品都支持OPEN
CL.NVIDIA公司在1999年发布GeForce 256图形处理芯片时首先提出GPU的概念。从此NV显卡的芯就用这个新名字GPU来称呼。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时。GPU所采用的核心技术有硬体T
工作原理
简单说GPU就是能够从硬件上支持T&L(Transform and Lighting,多边形转换与光源处理)的显示芯片,因为T&L是3D渲染中的一个重要部分,其作用是计算多边形的3D位置和处理动态光线效果,也可以称为“几何处理”。一个好的T&L单元,可以提供细致的3D物体和高级的光线特效;只不过大多数PC中,T&L的大部分运算是交由CPU处理的(这就也就是所谓的软件T&L),由于CPU的任务繁多,除了T&L之外,还要做内存管理、输入响应等非3D图形处理工作,因此在实际运算的时候性能会大打折扣,常常出现显卡等待CPU数据的情况,其运算速度远跟不上今天复杂三维游戏的要求。即使CPU的工作频率超过1GHz或更高,对它的帮助也不大,由于这是PC本身设计造成的问题,与CPU的速度无太大关系。
GPU与DSP区别
GPU在几个主要方面有别于DSP(Digital Signal Processing,简称DSP(数字信号处理)架构。其所有计算均使用浮点算法,而且目前还没有位或整数运算指令。此外,由于GPU专为图像处理设计,因此存储系统实际上是一个二维的分段存储空间,包括一个区段号(从中读取图像)和二维地址(图像中的X、Y坐标)。此外,没有任何间接写指令。输出写地址由光栅处理器确定,而且不能由程序改变。这对于自然分布在存储器之中的算法而言是极大的挑战。最后一点,不同碎片的处理过程间不允许通信。实际上,碎片处理器是一个SIMD数据并行执行单元,在所有碎片中独立执行代码。
尽管有上述约束,但是GPU还是可以有效地执行多种运算,从线性代数和信号处理到数值仿真。虽然概念简单,但新用户在使用GPU计算时还是会感到迷惑,因为GPU需要专有的图形知识。这种情况下,一些软件工具可以提供帮助。两种高级描影语言CG和HLSL能够让用户编写类似C的代码,随后编译成碎片程序汇编语言。Brook是专为GPU计算设计,且不需要图形知识的高级语言。因此对第一次使用GPU进行开发的工作人员而言,它可以算是一个很好的起点。Brook是C语言的延伸,整合了可以直接映射到GPU的简单数据并行编程构造。经GPU存储和操作的数据被形象地比喻成“流”(stream),类似于标准C中的数组。核心(Kernel)是在流上操作的函数。在一系列输入流上调用一个核心函数意味着在流元素上实施了隐含的循环,即对每一个流元素调用核心体。Brook还提供了约简机制,例如对一个流中所有的元素进行和、最大值或乘积计算。Brook还完全隐藏了图形API的所有细节,并把GPU中类似二维存储器系统这样许多用户不熟悉的部分进行了虚拟化处理。用Brook编写的应用程序包括线性代数子程序、快速傅立叶转换、光线追踪和图像处理。利用ATI的X800XT和Nvidia的GeForce
6800 Ultra型GPU,在相同高速缓存、SSE汇编优化Pentium 4执行条件下,许多此类应用的速度提升高达7倍之多。
对GPU计算感兴趣的用户努力将算法映射到图形基本元素。类似Brook这样的高级编程语言的问世使编程新手也能够很容易就掌握GPU的性能优势。访问GPU计算功能的便利性也使得GPU的演变将继续下去,不仅仅作为绘制引擎,而是会成为个人电脑的主要计算引擎。
GPU和CPU的区别是什么?
要解释两者的区别,要先明白两者的相同之处:两者都有总线和外界联系,有自己的缓存体系,以及数字和逻辑运算单元。一句话,两者都为了完成计算任务而设计。
两者的区别在于存在于片内的缓存体系和数字逻辑运算单元的结构差异:CPU虽然有多核,但总数没有超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件;GPU的核数远超CPU,被称为众核(NVIDIA
Fermi有512个核)。每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单(GPU初始时在浮点计算上一直弱于CPU)。从结果上导致CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算,数据压缩,人工智能,物理模拟,以及其他很多很多计算任务等。GPU由于历史原因,是为了视频游戏而产生的(至今其主要驱动力还是不断增长的视频游戏市场),在三维游戏中常常出现的一类操作是对海量数据进行相同的操作,如:对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜 {MOD}值。GPU的众核架构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行。在2003-2004年左右,图形学之外的领域专家开始注意到GPU与众不同的计算能力,开始尝试把GPU用于通用计算(即GPGPU)。之后NVIDIA发布了CUDA,AMD和Apple等公司也发布了OpenCL,GPU开始在通用计算领域得到广泛应用,包括:数值分析,海量数据处理(排序,Map-Reduce等),金融分析等等。
简而言之,当程序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时间,即Latency.当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来掩盖Lantency.目前,CPU和GPU的区别正在逐渐缩小,因为GPU也在处理不规则任务和线程间通信方面有了长足的进步。另外,功耗问题对于GPU比CPU更严重。
总的来讲,GPU和CPU的区别是个很大的话题。
处理器
用法
操作系统
芯片
CPU
桌面系统工业控制机
WINDOWS/UNIX
INTEL奔腾系列
ARM
向上扩展 向下扩展
WIN CE/UC/OS
ARM9/ARM7
DSP-MCU
工业控制 实使系统
不跑操作系统
51系列 TMS320系列
from: http://www.eepw.com.cn/article/276092_2.htm
CPU 、GPU的浮点运算能力比较
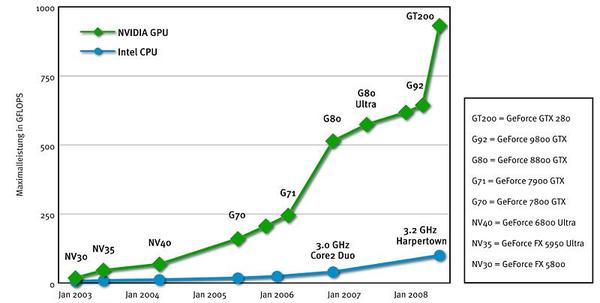
CPU-GPU浮点运算比较
作者:匿名用户
链接:http://www.zhihu.com/question/20978963/answer/17194080
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
英伟达的CUDA文档里给了这样一幅图:其中ALU就是“算术逻辑单元(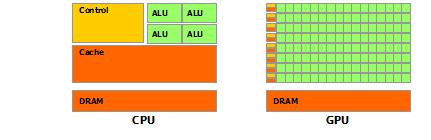 其中ALU就是“算术逻辑单元(Arithmetic
logic unit)”。
其中ALU就是“算术逻辑单元(Arithmetic
logic unit)”。
CPU和GPU进行计算的部分都是ALU,而如图所示,GPU绝大部分的芯片面积都是ALU,而且是超大阵列排布的ALU。这些ALU都是可以并行运行的,所以浮点计算速度就特别高了。
相比起来,CPU大多数面积都需要给控制单元和Cache,因为CPU要承担整个计算机的控制工作,没有GPU那么单纯。
所以GPU的程序控制能力相比CPU来说不强,稍早时候的CUDA程序像是递归都是不能用的(较新的设备上可以了)。
CPU不能提高浮点计算速度,而是因为没什么特别的必要了。咱们通常的桌面应用根本没有什么特别的浮点计算能力要求。而同时GPU这样的设备已经出现了,那么需要浮点计算的场合利用上就行了。
作者:冯东
链接:http://www.zhihu.com/question/20978963/answer/17195552
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先,CPU 能不能像 GPU 那样去掉 cache?不行。GPU 能去掉 cache 关键在于两个因素:数据的特殊性(高度对齐,pipeline 处理,不符合局部化假设,很少回写数据)、高速度的总线。对于后一个问题,CPU 受制于落后的数据总线标准,理论上这是可以改观的。对于前一个问题,从理论上就很难解决。因为 CPU 要提供通用性,就不能限制处理数据的种类。这也是 GPGPU 永远无法取代 CPU 的原因。
其次,CPU 能不能增加很多核?不行。首先 cache 占掉了面积。其次,CPU 为了维护 cache 的一致性,要增加每个核的复杂度。还有,为了更好的利用 cache 和处理非对齐以及需要大量回写的数据,CPU 需要复杂的优化(分支预测、out-of-order 执行、以及部分模拟 GPU 的 vectorization 指令和长流水线)。所以一个 CPU 核的复杂度要比 GPU 高的多,进而成本就更高(并不是说蚀刻的成本高,而是复杂度降低了成片率,所以最终成本会高)。所以 CPU 不能像 GPU 那样增加核。
至于控制能力,GPU 的现状是差于 CPU,但是并不是本质问题。而像递归这样的控制,并不适合高度对齐和 pipeline 处理的数据,本质上还是数据问题。
作者:谢天奇
链接:http://www.zhihu.com/question/20978963/answer/86818933
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在不考虑 指令集、缓存、优化的情况下,光看主频就知道,CPU单个核心浮点运算能力比GPU强多了。
GPU核心最高也就1Ghz左右 ,CPU核心却要3-4Ghz。区别是CPU最多也就十几个核心,GPU动辄几百上千个核心。
更别说CPU核心指令集更全面,GPU核心基本只有SIMD指令(因为GPU主要是用于图形处理,向量运算远比标量运算多。并且对CPU来说,多一套指令运算单元,就是几个核心的成本;对GPU来说就是多几百上千个核心的成本。)
CPU处理一次标量乘法只要一次标量乘法指令,GPU却把标量先转换成向量 然后用一条SIMD指令。
CPU每个核心有独立的缓存,GPU基本是所有核心共享一个缓存(GPU主要做图形渲染,所有核心都执行同一份指令,获取同样的数据。CPU主要是执行多个串行任务,每个核心可以处理不同的任务,从不同地方获取不同的数据。),所以CPU单核性能秒GPU单核十条街。
CPU每个核心都有独立的优化、分支预测、乱序执行之类的。
GPU乱序执行可以有,因为所有核心都干一样的事情,可以共享一份指令,不需要独立的乱序执行(不过一般不会有,因为这个功能可以直接放到编译器中实现。因为GPU的开发语言少 ,基本只有GLSL和HLSL,编译器是厂商自己开发的。不像CPU那样,开发语言多如牛毛,各种编译器五花八门,指令集大相径庭,所以才迫切需求这种动态的乱序执行优化)。
GPU分支预测肯定不会有,成本上来说分支预测不能共享 ,每个核心都多一个分支预测的逻辑单元成本太大。关键是根本就不需要。GPU程序一般都很短,本来就可以全部装载到高速缓存中;其次是对于GPU处理的任务而言,分支预测也无意义。
GPU的强项是并行运算能力比CPU强(多个不同任务的并行运算GPU也无法胜任,GPU只适合处理单个可并行任务的并行运算),而不是浮点运算能力强。(这个谣言也不知道谁传出来的,非要强调浮点运算。非要说浮点运算的话,不如说大多数老式GPU甚至没有整数运算能力,因为根本没有整数指令。GPU最早设计目的是加速图形渲染,基本都是浮点运算。所以GPU核心的SIMD指令 只有浮点指令,没有整数指令;新型GPU因为不光光用于图形渲染,还想推广到通用计算,就是所谓的GPGPU 所以开始加入整数运算的支持。)
GPU完全是为了并行运算设计的。
只有可并行 无数据依赖的运算在GPU上才会快。
举个简单的例子
CPU的核心就像一个心算高手 并且掌握各种奇技淫巧 一分钟能算100次四则运算
GPU的核心就是一个普通人 一分钟能算10次四则运算
但是 你让10个心算高手合作算10000个四则运算 和 1000个普通人合作算10000个四则运算
你说谁完成的快?
当然是1000个普通人快
(10个心算高手每人算1000个要花10秒 1000个普通人每人算10个只要1秒)
但是如果这10000个四则运算有依赖 就是下一题的条件依赖于上一题的结果
你说谁算的快?
当然是心算高手快 因为一旦有这种强依赖 就只能串行 10个人干和1000个人干并不会比1个人干来得快
(1个心算高手只要花100秒 1个普通人要花1000秒)
CPU 、GPU的浮点运算能力比较
CPU-GPU浮点运算比较
作者:匿名用户
链接:http://www.zhihu.com/question/20978963/answer/17194080
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
英伟达的CUDA文档里给了这样一幅图:其中ALU就是“算术逻辑单元(
其中ALU就是“算术逻辑单元(Arithmetic
logic unit)”。CPU和GPU进行计算的部分都是ALU,而如图所示,GPU绝大部分的芯片面积都是ALU,而且是超大阵列排布的ALU。这些ALU都是可以并行运行的,所以浮点计算速度就特别高了。
相比起来,CPU大多数面积都需要给控制单元和Cache,因为CPU要承担整个计算机的控制工作,没有GPU那么单纯。
所以GPU的程序控制能力相比CPU来说不强,稍早时候的CUDA程序像是递归都是不能用的(较新的设备上可以了)。
CPU不能提高浮点计算速度,而是因为没什么特别的必要了。咱们通常的桌面应用根本没有什么特别的浮点计算能力要求。而同时GPU这样的设备已经出现了,那么需要浮点计算的场合利用上就行了。
作者:冯东
链接:http://www.zhihu.com/question/20978963/answer/17195552
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先,CPU 能不能像 GPU 那样去掉 cache?不行。GPU 能去掉 cache 关键在于两个因素:数据的特殊性(高度对齐,pipeline 处理,不符合局部化假设,很少回写数据)、高速度的总线。对于后一个问题,CPU 受制于落后的数据总线标准,理论上这是可以改观的。对于前一个问题,从理论上就很难解决。因为 CPU 要提供通用性,就不能限制处理数据的种类。这也是 GPGPU 永远无法取代 CPU 的原因。
其次,CPU 能不能增加很多核?不行。首先 cache 占掉了面积。其次,CPU 为了维护 cache 的一致性,要增加每个核的复杂度。还有,为了更好的利用 cache 和处理非对齐以及需要大量回写的数据,CPU 需要复杂的优化(分支预测、out-of-order 执行、以及部分模拟 GPU 的 vectorization 指令和长流水线)。所以一个 CPU 核的复杂度要比 GPU 高的多,进而成本就更高(并不是说蚀刻的成本高,而是复杂度降低了成片率,所以最终成本会高)。所以 CPU 不能像 GPU 那样增加核。
至于控制能力,GPU 的现状是差于 CPU,但是并不是本质问题。而像递归这样的控制,并不适合高度对齐和 pipeline 处理的数据,本质上还是数据问题。
作者:谢天奇
链接:http://www.zhihu.com/question/20978963/answer/86818933
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在不考虑 指令集、缓存、优化的情况下,光看主频就知道,CPU单个核心浮点运算能力比GPU强多了。
GPU核心最高也就1Ghz左右 ,CPU核心却要3-4Ghz。区别是CPU最多也就十几个核心,GPU动辄几百上千个核心。
更别说CPU核心指令集更全面,GPU核心基本只有SIMD指令(因为GPU主要是用于图形处理,向量运算远比标量运算多。并且对CPU来说,多一套指令运算单元,就是几个核心的成本;对GPU来说就是多几百上千个核心的成本。)
CPU处理一次标量乘法只要一次标量乘法指令,GPU却把标量先转换成向量 然后用一条SIMD指令。
CPU每个核心有独立的缓存,GPU基本是所有核心共享一个缓存(GPU主要做图形渲染,所有核心都执行同一份指令,获取同样的数据。CPU主要是执行多个串行任务,每个核心可以处理不同的任务,从不同地方获取不同的数据。),所以CPU单核性能秒GPU单核十条街。
CPU每个核心都有独立的优化、分支预测、乱序执行之类的。
GPU乱序执行可以有,因为所有核心都干一样的事情,可以共享一份指令,不需要独立的乱序执行(不过一般不会有,因为这个功能可以直接放到编译器中实现。因为GPU的开发语言少 ,基本只有GLSL和HLSL,编译器是厂商自己开发的。不像CPU那样,开发语言多如牛毛,各种编译器五花八门,指令集大相径庭,所以才迫切需求这种动态的乱序执行优化)。
GPU分支预测肯定不会有,成本上来说分支预测不能共享 ,每个核心都多一个分支预测的逻辑单元成本太大。关键是根本就不需要。GPU程序一般都很短,本来就可以全部装载到高速缓存中;其次是对于GPU处理的任务而言,分支预测也无意义。
GPU的强项是并行运算能力比CPU强(多个不同任务的并行运算GPU也无法胜任,GPU只适合处理单个可并行任务的并行运算),而不是浮点运算能力强。(这个谣言也不知道谁传出来的,非要强调浮点运算。非要说浮点运算的话,不如说大多数老式GPU甚至没有整数运算能力,因为根本没有整数指令。GPU最早设计目的是加速图形渲染,基本都是浮点运算。所以GPU核心的SIMD指令 只有浮点指令,没有整数指令;新型GPU因为不光光用于图形渲染,还想推广到通用计算,就是所谓的GPGPU 所以开始加入整数运算的支持。)
GPU完全是为了并行运算设计的。
只有可并行 无数据依赖的运算在GPU上才会快。
举个简单的例子
CPU的核心就像一个心算高手 并且掌握各种奇技淫巧 一分钟能算100次四则运算
GPU的核心就是一个普通人 一分钟能算10次四则运算
但是 你让10个心算高手合作算10000个四则运算 和 1000个普通人合作算10000个四则运算
你说谁完成的快?
当然是1000个普通人快
(10个心算高手每人算1000个要花10秒 1000个普通人每人算10个只要1秒)
但是如果这10000个四则运算有依赖 就是下一题的条件依赖于上一题的结果
你说谁算的快?
当然是心算高手快 因为一旦有这种强依赖 就只能串行 10个人干和1000个人干并不会比1个人干来得快
(1个心算高手只要花100秒 1个普通人要花1000秒)