{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 kimheesun211 的文章《互联网广告精准投放DSP项目》','https://www.xiaopingtou.net/article-76399.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、项目介绍:
(1) 项目名称:互联网广告精准投放DSP项目(2) 项目目的:通过分析处理用户使用APP或者点击网页等产生的日志数据来得到一些有价值的信息,以此来帮助广告主 进行精准广告投放。我们利用大数据技术对海量人群的上网行为进行细分,根据不同人群的上网习惯构建海量用户的画像系 统,给不同的人群打上相应的标签,基于用户的标签进行精准的广告推送。
(3) 集群规模:
服务器硬盘raid0之后为10T。
项目生产环境规划: 服务器安装Esxi6.0系统,虚拟出8台centos6.5服务器,一共 8 台,4 台都为 40 核,120G 内 存;4 台 4 核 32G 内存;
网络配置:万兆网卡
(4) 数据量规划
每条数据0.9k左右,每日压缩数据20G左右, 其中有效数据大概在2000-3000万条。
(5) 技术选型:
Hadoop2.6.4、Hive1.2、Zookeeper3.4、Spark1.6、Hbase0.98.x、Scala2.10.x、Flume1.5、Kafka0.8、 ElasticSearch2.3、smartbi
二、项目业务流程
项目业务流程图: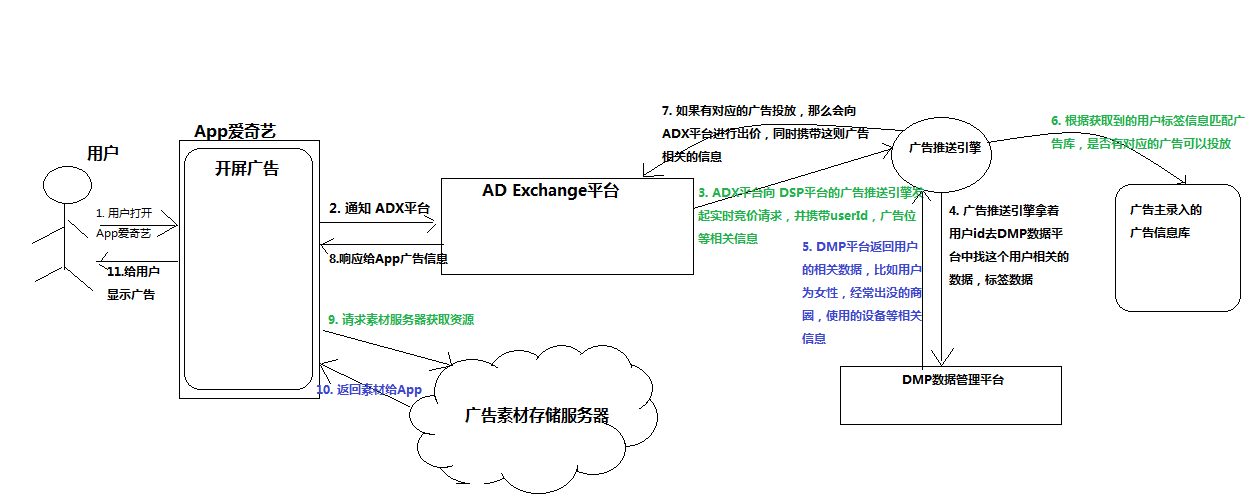
离线业务部分:
- AD Exchange平台和广告投放引擎进行交互的时候会产生大量的日志数据,我们将日志数据写入到redis中。
- 后台还有一个线程不停的扫描redis,当redis中存储的日志数据到一定阈值的时候把数据写入到磁盘中。
- Flume监听磁盘上的文件夹目录,当发现有文件的时候进行采集,并将数据写入到hdfs中。
- 每天凌晨用spark进行昨天的数据指标统计,并给每一个用户打上对应的标签,将每天的标签数据存入到hbase中,将报表数据存入到mysql中。
- 同时再将ES中存储的用户历史标签进行聚合并做标签的衰减,剔除不需要的标签。
三、项目DMP技术架构

四、项目中主要职责:
- 报表分析——主要分析了当日的展示量、点击量、点击率、参与竞价数、竞价成功数、广告消费、广告成本、原始请求数、有效请求数、广告请求数等指标。这些指标分别按照不同的维度进行统计,他们分别是:地域分布情况(各省市)、运营商(移动、电信、联通)、网络类型(2G、3G、4G、WIFI)、终端设备类型(手机、平板、其他)、操作系统(安卓、ios)、媒体(爱奇艺、腾讯新闻、PPTV)、渠道(搜狐、芒果RTB、Tanx)等。
- 打标签——我们的标签库一共大约有200个标签,我们的标签体系最多有分为四个层级,根据用户上网行为和兴趣爱好为一级标签,其中上网行为又可以继续细分为时间特征,活跃程度、广告态度、终端类型、联网方式、运营商等。其中时间特征又可以继续细分为使用的时间段,比如有上班早高峰、下班晚高峰、午休、上班时间、夜晚休闲、夜猫。我们给用户打上的都是最后一级的具体的标签类型。打标签的过程其实是根据日志进行匹配的过程,如果有匹配上的才打上对应的标签,平均每个用户最多能够给打上20-30个标签。例如:商圈标签,关键字标签等等
四、项目用到的技术点
- Parquet文件存储
a. 基于列式存储,可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
b. 压缩编码可以降低磁盘存储空间,由于同一列的数据类型是一样的,可以使用不同的压缩编码。
c. 只读取需要的列, 支持向量运算, 能够获取更好的扫描性能。
d. Parquet 适配多种计算框架(MR、spark)。 - spark SQL、spark core
用spark sql 和spark core 统计用户报表并且对数据进行打标签,存入数据库为生成用户画像提供详细信息 - GeoHash算法
GeoHash 算法是一种是将经纬度先进行二进制转换,然后使用0-9,b-z(去掉a,i,l,o)这32个字母进行base32编码成字 符串的方法,并且使得在大部分情况下,字符串前缀匹配越多的距离越近。
当GeoHash base32编码的长度匹配前8位时,两点距离相差精度在19米左右,长度匹配前9位时,两点距离相差精度在2米左右。最大支持的编码长度是12位。 - Spark graphx图计算聚合用户标签数据
构建出顶点和边,构建出连通图(连通图中只有id,没有关于id的其他信息),再将连通图中的数据和顶点的数据进行join,得到聚合后的结果。 - 调用百度云逆地理位置编码服务解析json数据获得商圈标签
- 使用redis 替换广播变量不能广播动态数据的业务场景
redis替换广播变量广播app字典文件的做法,因为app字典文件每天会进行更新是会动态变化的,但是广播变量一旦广播出去就不能变了,所以我们这里有redis代替广播变量。
五、项目的难点以及遇到的问题
1.id标识不唯一,导致一个用户的信息不能聚合解决方法:用spark graphx图计算聚合用户标签数据
2. 业务字段过多导致的异常。
我们项目当中日志一共有105个字段,在对原始日志进行处理转换成parquet文件的过程中,我们使用的方法是定义一个case class类,将这105个字段封装到这个对象里面,基于这种方式构建的DataFrame。结果运行的时候报错了,之后我们查阅官网,发现在scala 2.10版本中case class一共只支持22个字段,如果超过了就会报错,然后官网也给了我们解决方法,就是自定义一个类实现product特质,这样就能解决这个问题。
3. Spark序列化的问题
在查app字典文件的时候,我在driver端构建了一个map,然后在读取字典文件方法中不停的往map里面put,最后再将这个map广播出去,最后发现出来的结果没有匹配上app字典文件里面的值。后来上spark官网查阅资料,发现原因是因为spark在task序列化的时候有一个闭包的概念。我在RDD操作内传入的这个map其实是driver端那个map的副本,这时候driver端的map和executor端的map不是同一个map,所以广播出去的map是没有值的。正确的方法是在executor端收集数据然后collect到driver端,在driver端toMap,然后再进行广播,这样就没问题了。
4. 数据倾斜,导致某个task数据量过大
我们在跑spark的job的时候发现多数的task执行速度很快,但是有个别的1~2个task执行速度很慢,进度一直卡在99%。首先我们对处理的数据的key进行采样,统计出现的次数,根据出现次数大小排序取出前几个。发现多数数据分布都较为平均,而个别数据比其他数据大上若干个数量级,则说明发生了数据倾斜。我们再对个别的大key进行进一步观察,发现有很多key为null或者是一些无意义的数据。针对这种情况,我们在程序中把这些无意义的数据给过滤掉,然后再跑一次job就没有发生数据倾斜了。
六、项目优化
**数据倾斜的优化:**有一次发现Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。代码优化:
(1) 避免创建重复的RDD;
(2) 尽可能复用同一个RDD
(3) 广播大变量
(4) 减少使用产生shuffle的算子等等