{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 ASsingle 的文章《物体检测的一些概念(1)》','https://www.xiaopingtou.net/article-78018.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
转自:http://blog.csdn.net/zhang_shuai12/article/details/52716952
1、迁移学习 迁移学习也即所谓的有监督预训练(Supervised pre-training),我们通常把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。 图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,比如我们先对imagenet图片数据集先进行网络的图片分类训练。这个数据库有大量的标注数据。 2、IOU(交并比) 物体检测需要定位出物体的bounding box,就像上面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
物体检测需要定位出物体的bounding box,就像上面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。
IOU表示了bounding box 与 ground truth 的重叠度,如下图所示: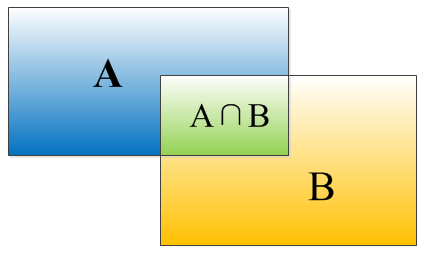 矩形框A、B的一个重合度IOU计算公式为:
矩形框A、B的一个重合度IOU计算公式为:
 就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
所谓非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。 (1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值; (2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。 (3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。 就这样一直重复,找到所有被保留下来的矩形框。
1、迁移学习 迁移学习也即所谓的有监督预训练(Supervised pre-training),我们通常把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。 图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,比如我们先对imagenet图片数据集先进行网络的图片分类训练。这个数据库有大量的标注数据。 2、IOU(交并比)
物体检测需要定位出物体的bounding box,就像上面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。 IOU表示了bounding box 与 ground truth 的重叠度,如下图所示:
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
3、NMS
NMS也即非极大值抑制。在最近几年常见的物体检测算法(包括rcnn、sppnet、fast-rcnn、faster-rcnn等)中,最终都会从一张图片中找出很多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:
就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。 所谓非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。 (1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值; (2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。 (3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。 就这样一直重复,找到所有被保留下来的矩形框。