{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 雨阳 的文章《HexagonDSP的内存操作》','https://www.xiaopingtou.net/article-78785.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
HexagonDSP的内存操作
概述
Hexagon处理器配备了load/store架构,数值与逻辑计算均在寄存器上进行操作。清晰定义的load指令可将内存中的操作数存放于寄存器中,store指令可将寄存器中的操作数存放于内存中。有一部分指令(mem-ops)可直接在内存上进行数值与逻辑操作。
地址空间已封装,所有的访问都以线性地址空间为目标,可访问的值可以是指令或者数据。
内存模型
本章介绍Hexagon处理器的内存模型
地址空间
Hexagon处理器拥有一个32位的字节可寻址内存地址空间。整个4G的线性地址空间可由用户指定。同时Hexagon处理器还提供虚拟内存机制。
字节序列
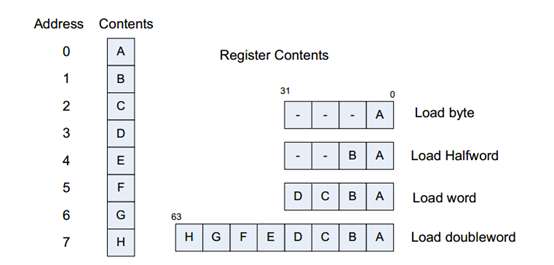
Hexagon处理器属于小端机器:内存中的低位地址在寄存器中的最低位,如下图所示:
对齐
Hexagon处理器虽然能够进行字节地址的编程,指令以及数据在内存中必须被对齐到特定的地址边界
指令与指令包必须是32位对齐
数据必须对齐至本地访问大小
未对其的指令访问将会导致内存对齐异常
置换内存指令在应用中用来应用未对其的向量数据。Load与store指令仍然是内存对齐的;然而置换指令可以使数据更加轻松地重新安排寄存器
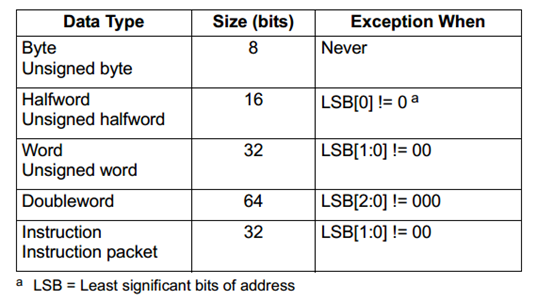
内存的Load指令
内存可以以字节,半字或双字尺寸来导入。数据类型支持有符号与无符号型数据。语法类型为 ,XX用来表示数据类型:
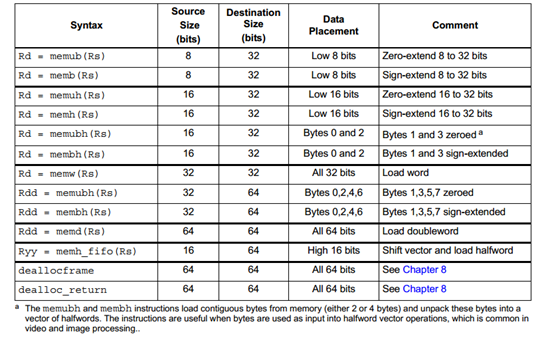
内存stores
内存可以以字节,半字,字或双字尺寸存储。语法运用类似于 ,X意味着数据的类型。下图总结了可支持的store指令:
双存储
两个存储指令可以出现在同一个指令包中。这种指令被称作双存储
新值存储
在同一个指令包中,内存存储指令可存储一个对齐了新值的寄存器。这种功能可通过加入 前缀来使用,例如:
如果指令调用自动加或绝对集合寻址模式,其地址寄存器不能被用于新值寄存器。
如果指令产生了一个64位的结果或操作与浮点指令。其结果寄存器不能被用于新值寄存器。
如果设置为新值存储器的寄存器是有条件的,那么使用新值寄存器的指令也必须是有条件的。这两个都必须有分支评价。否则执行的结果将会是未知的。
Mem-ops
Mem-ops可以在内存上进行基础的数值,逻辑以及位运算,无需单独的load或store指令。Mem-ops可以操作字节,半字或字。下图显示了mem-ops的语法:
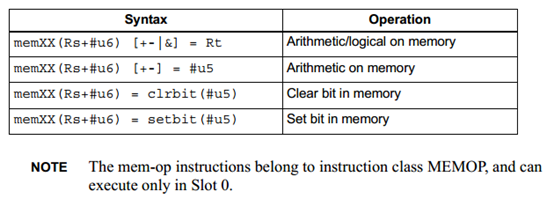
寻址模式
下图总结了可支持的寻址模式:
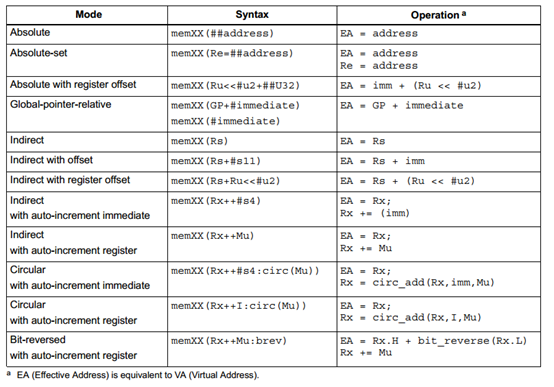
有条件的load/store
某些load以及stora治疗可以有条件的基于分支值来执行,这些分支的值在以前的指令中被设置。编译器产生有条件的Load和store指令用来提高指令的并行级别
有条件的load以及store在汇编语言中通过指令前缀“if来实现,pred_expr定义了分支预测寄存器的表达,例如:
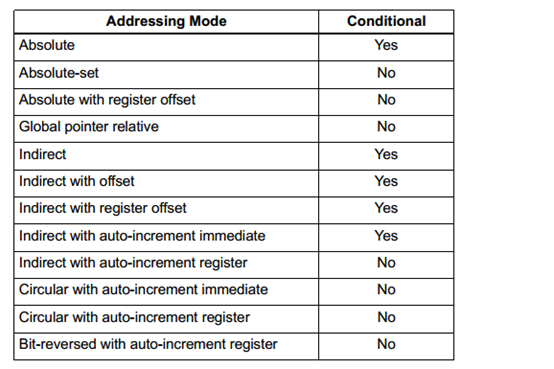
寻址方式的细节将会在下一章单独为一篇
内存缓存
Hexagon处理器配备了基于缓存的内存架构
一级指令缓存可保存最近执行的指令
一级数据缓存可保存最近访问的内存
可通过缓存访问内存的Load/store指令被定义为缓存访问
特殊内存区域可被配置,从而实现缓存或非缓存访问。可通过Hexagon内存管理模块(MMU)来配置。
两种支持缓存的模式
写入缓存使缓存中的数据与内存中数据保持一致,时刻将缓存中数据写入到内存中
写回缓存允许缓存中保存的数据被立即保存到内存中。不一致的数据被标记为dirty。
Hexagon处理器包括精细的缓存维持治疗用于将dirty数据移除出内存。
 内存序列
内存序列
某些设备可能会在访问时需要存储与导出的同步。在这种情况时,需要一系列处理器指令来使能程序控制来同步内存访问的序列。
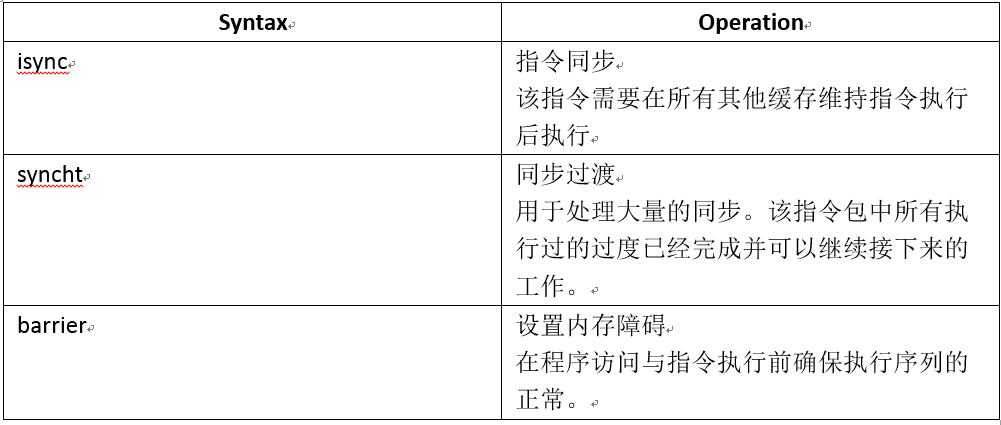
数据内存访问以及程序内存访问在软件中被区别开来。软件需要确保在数据与程序代码中的一致性。
例如,对于生成或自我修改的代码,代码将会被放置于数据缓存区并与软件缓存不一致。此时,软件必须强迫被更改的数据清晰的被写入内存中。一个障碍指令在这时可以确保store指令的正确执行。最终,相关指令缓存内容需要更新并重新提取新的指令
如下为案例代码序列:
Hexagon处理器包括了LL/SC(导入锁/存储状态转移)机制来提供原子实现。这对于实现同步信号量、互斥量是非常重要的。下图描述了原子指令的操作

如下为官方推荐的取得互斥锁的代码:
在可缓存的内存中,页必须被设置为可缓存的并且可写回,否则CPU行为可能未知。可缓存内存必须在线程需要同步其他数据时使用
概述
Hexagon处理器配备了load/store架构,数值与逻辑计算均在寄存器上进行操作。清晰定义的load指令可将内存中的操作数存放于寄存器中,store指令可将寄存器中的操作数存放于内存中。有一部分指令(mem-ops)可直接在内存上进行数值与逻辑操作。
地址空间已封装,所有的访问都以线性地址空间为目标,可访问的值可以是指令或者数据。
内存模型
本章介绍Hexagon处理器的内存模型
地址空间
Hexagon处理器拥有一个32位的字节可寻址内存地址空间。整个4G的线性地址空间可由用户指定。同时Hexagon处理器还提供虚拟内存机制。
字节序列
Hexagon处理器属于小端机器:内存中的低位地址在寄存器中的最低位,如下图所示:
对齐
Hexagon处理器虽然能够进行字节地址的编程,指令以及数据在内存中必须被对齐到特定的地址边界
指令与指令包必须是32位对齐
数据必须对齐至本地访问大小
未对其的指令访问将会导致内存对齐异常
置换内存指令在应用中用来应用未对其的向量数据。Load与store指令仍然是内存对齐的;然而置换指令可以使数据更加轻松地重新安排寄存器
内存的Load指令
内存可以以字节,半字或双字尺寸来导入。数据类型支持有符号与无符号型数据。语法类型为 ,XX用来表示数据类型:
内存stores
内存可以以字节,半字,字或双字尺寸存储。语法运用类似于 ,X意味着数据的类型。下图总结了可支持的store指令:
双存储
两个存储指令可以出现在同一个指令包中。这种指令被称作双存储
{
memw(R5) = R2 // dual store
memh(R6) = R3
}
与大多数可封装的指令不同,双存储指令无法被并行的执行。在指令中,第一位置的指令被先执行,而后在执行第二个指令。 新值存储
在同一个指令包中,内存存储指令可存储一个对齐了新值的寄存器。这种功能可通过加入 前缀来使用,例如:
{
R2 = memh(R4+#8) // load halfword
memw(R5) = R2.new // store newly-loaded value
}
新值存储有如下限制 如果指令调用自动加或绝对集合寻址模式,其地址寄存器不能被用于新值寄存器。
如果指令产生了一个64位的结果或操作与浮点指令。其结果寄存器不能被用于新值寄存器。
如果设置为新值存储器的寄存器是有条件的,那么使用新值寄存器的指令也必须是有条件的。这两个都必须有分支评价。否则执行的结果将会是未知的。
Mem-ops
Mem-ops可以在内存上进行基础的数值,逻辑以及位运算,无需单独的load或store指令。Mem-ops可以操作字节,半字或字。下图显示了mem-ops的语法:
寻址模式
下图总结了可支持的寻址模式:
有条件的load/store
某些load以及stora治疗可以有条件的基于分支值来执行,这些分支的值在以前的指令中被设置。编译器产生有条件的Load和store指令用来提高指令的并行级别
有条件的load以及store在汇编语言中通过指令前缀“if来实现,pred_expr定义了分支预测寄存器的表达,例如:
if (P0) R0 = memw(R2) // conditional load
if (!P2) memh(R3 + #100) = R1 // conditional store
if (P1.new) R3 = memw(R3++#4) // conditional load
并不是所有的寻址模式都支持有条件的load与store指令。 寻址方式的细节将会在下一章单独为一篇
内存缓存
Hexagon处理器配备了基于缓存的内存架构
一级指令缓存可保存最近执行的指令
一级数据缓存可保存最近访问的内存
可通过缓存访问内存的Load/store指令被定义为缓存访问
特殊内存区域可被配置,从而实现缓存或非缓存访问。可通过Hexagon内存管理模块(MMU)来配置。
两种支持缓存的模式
写入缓存使缓存中的数据与内存中数据保持一致,时刻将缓存中数据写入到内存中
写回缓存允许缓存中保存的数据被立即保存到内存中。不一致的数据被标记为dirty。
Hexagon处理器包括精细的缓存维持治疗用于将dirty数据移除出内存。
内存序列 某些设备可能会在访问时需要存储与导出的同步。在这种情况时,需要一系列处理器指令来使能程序控制来同步内存访问的序列。
数据内存访问以及程序内存访问在软件中被区别开来。软件需要确保在数据与程序代码中的一致性。
例如,对于生成或自我修改的代码,代码将会被放置于数据缓存区并与软件缓存不一致。此时,软件必须强迫被更改的数据清晰的被写入内存中。一个障碍指令在这时可以确保store指令的正确执行。最终,相关指令缓存内容需要更新并重新提取新的指令
如下为案例代码序列:
memw(R1) = R0
dccleana(R1) // force data out of data cache
barrier // ensure data is in memory
icinva(R1) // clear it from instruction cache
isync // ensure icinva instr is finished
jumpr R1 // can now execute code at R1
原子操作 Hexagon处理器包括了LL/SC(导入锁/存储状态转移)机制来提供原子实现。这对于实现同步信号量、互斥量是非常重要的。下图描述了原子指令的操作
如下为官方推荐的取得互斥锁的代码:
// assume mutex address is held in R0
// assume R1,R3,P0,P1 are scratch
lockMutex:
R3 = #1
lock_test_spin:
R1 = memw_locked(R0) // do normal test to wait
P1 = cmp.eq(R1,#0) // for lock to be available
if (!P1) jump lock_test_spin
memw_locked(R0,P0) = r3 // do store conditional (SC)
if (!P0) jump lock_test_spin // was LL and SC done atomically?
如下为官方推荐的释放互斥锁的代码:
// assume mutex address is held in R0
// assume R1 is scratch
R1 = #0
memw(R0) = R1
原子的 操作用于支持AXI总线的外部访问。为实现外部内存的导入锁操作。操作系统必须定义内存页为不可缓存项,否则CPU的操作可能为未知。 在可缓存的内存中,页必须被设置为可缓存的并且可写回,否则CPU行为可能未知。可缓存内存必须在线程需要同步其他数据时使用