{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 PowerAnts 的文章《用C为密集运算函数加速》','https://www.xiaopingtou.net/article-80132.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
用C为密集运算函数加速
密集运算函数的优化
——在应用程序中集成可编程逻辑
今天的电子设备,不管是嵌入、工业、消费、娱乐,还是通讯电子设备,它们中的应用程序,都比过去需要在更短的时间内处理更多的数据。一般来说,开发者通常会选用某种通用型处理器或数字信号处理器(DSP),对那些适应性为先的应用程序来说,通用型处理器一直都是最佳的架构选择,而同时DSP也是用于提高运算能力的首选。在许多情况中,既需要适应性,同时也需要强大的运算能力,当为了增加通用型处理器的执行能力而提高时钟频率时,也会带来成本与电能消耗的增加。为满足今日计算的要求,在这些设备中加入了硬件加速或某些特别的辅助部件,但由此付出的代价是增加了编程的复杂性。本文,将探讨通过C语言,怎样加速程序处理速度,以可配置软件架构的方式,达到硬件加速的目的。为举例说明,将介绍一个硬件加速有限脉冲响应(FIR)滤波器的真实案例。
以软件配置的处理器
大多数高性能IC产品的市场都在不断地变动,追寻更先进的标准,及满足永远都在变化的系统需求。基于ASIC的架构,虽然提供了所需的性能,但却不能快速及经济地满足这些变化着的应用规格,因此,许多开发者不得不转向以软件方式配置的架构,其可在应用型处理器中融入可编程逻辑。
以软件配置的架构,其优势在于,可编程的门电路可作为应用型处理器,有机地集成进同一流水线,而作为参考对比基于协处理器的架构,通常是使用FPGA或ASSP这样单独的系统部件来减轻系统负载的,这种使用协处理器的做法,带来的是复杂的、应用上的分割,并且在应用型处理器等待结果时,造成延迟,或需实现复杂的调度机制。加之对FPGA的设计需要一个单独的开发环境,和另一支开发队伍,所带来成本上的开销也是非同一般的。
因为以软件配置的处理器可作为应用型处理器,在同一流水线中实现了可编程逻辑,所以,编译器可把算法分为硬件和软件部分,由此也降低了相关的依赖性,其结果是,你可把“硬件”当成“软件”,并在单一开发环境中编写代码,使硬件和软件更优化地一同工作。不需要花费巨大的开发资源来手工调校代码,只需高亮标出运算热点,编译器就会以硬件的形式实现它。这些热点区域作为扩展指令实现,应用型处理器可将其视为传统的指令,并在同一流水线中执行。此处的差异在于,扩展指令可表现为成百上千条C指令,在单一时钟周期内高效地执行和计算。
基本FIR滤波器
FIR滤波器可把热点区域以并行的方式实现,在此,我们讨论的重点是对一个滤波器,怎样通过C的实现来硬件加速,这种优化的理念也可应用于其他算法。
可用以下方程式来描述一个FIR滤波器:
t=T-1
y(n)=SUM ((h(t)*x)(n-t)) for n=0,...N-1
t=0
x(n)在此是输入信号,y(n)是输出信号,h(t)是FIR滤波器系数,图1为一个直观的FIR函数示意图,格子内的每一点,代表了系数h(t)与数据点x(n-t)的乘积,而每条斜线上的所有乘积全部相加才能得到输出的y(n)。例1是对FIR滤波器一个直接用C语言的实现方法。利用此实现,一个使用T=64和N=80的64路滤波器执行完,将大约需要27230个时钟周期。而这种固有的并行架构,使它成为一个非常适合于实际应用中硬件加速的候选方案。
 图1:FIR函数示意图
例1:
void fir(short *X, short *H, short *Y, int N, int T)
{
int n, t, acc;
short *x, *h;
/* 滤波器输入 */
for (n = 0; n < N; n++) {
x = X;
h = H;
acc = (*x--) * (*h++);
for(t = 1; t < T; t++) {
acc += (*x--) * (*h++);
}
*Y = acc >> 14;
X++;
Y++;
}
}
加速的关键性考虑因素
当决定在算法中采用并行措施时,务必要留意架构上固有的一些特性:
总线位宽:数据怎样在CPU和其他部件之间传递,对整体效率和吞吐量都有着重大的影响,因为总线决定了数据可被多快地传递,输入与输出都会受到其影响。位宽太窄或速度太慢,都会成为一个处理上的瓶颈,从而影响扩展指令的执行效率,但如果总线不能被及时地填充数据以充分利用,那么不管扩展指令多有效率,都是无用的。
一般而言,总线的频率决定了扩展指令发出的频密度,而位宽则决定了扩展指令一次能处理多少数据。注意,某些架构提供了CPU与各部件之间的多重总线,由此来进行硬件加速,例如Stretch公司的S5以软件配置的处理器,在应用处理器与可编程部件之间,就有三个读取与两个写入端口,每个均为128位的位宽,并提供每条扩展指令最大读取384位及写入256位的能力。有效地利用这些总线,开发出高效的并行机制并不是件难事。
在带宽计算上,要保证带宽可把结果传回至主CPU并同时处理中间结果,这一点尤其重要。
状态寄存器:为一个复杂算法加速,通常会把算法进行分割,以便用于加速的硬件在每一次迭代中只计算结果的某一部分。因为滤波器是作为一个部分函数执行,也就是说,总体结果中只有一些离散的段是通过扩展指令执行的,而且,经常会有一些中间结果需要传递给下一个函数的调用,例如,在FIR函数最初的C实现中,一个连续的总数或中间结果必须在主算法循环的每一次迭代中都保留。再者,当应用更先进的优化技术时,中间结果的数量也会逐步增加。
为达到加速的目的,必须在每次迭代之间防止产生这些中间结果,因为这些值经常会通过数据总线传回到主CPU,而CPU又会把它们返回给函数,以便进行下一次迭代。此过程不仅消耗有限的总线带宽,而且也浪费了宝贵的CPU时钟周期,降低了整体处理的效率。
为保证效率,在此可使用状态寄存器。状态寄存器提供了一种机制,其可存储函数迭代的中间结果,而又不会涉及到主CPU或在总线上传递数据,因此,利用状态寄存器,可使整体的并行机制变得更有效率,而可用的状态寄存器数目,又进一步决定了在算法中可多大程度地利用这类并行机制。
数据大小:许多的架构在有关某数据类型占用的位宽方面,只提供了一个有限的子集,例如,一个布尔变量通常只需要一比特位,但在实现中,大小经常至少是一个字节,而一般对CPU来说,这样做会提高效率,因为对一个比特位进行掩码操作所花的代价及性能上的影响,远远要比浪费7个比特位更多;当传递数据给扩展指令,而此时CPU又必须立即剥离和打包这些比特位时,就会损失一部分效率。另外,为节约可编程逻辑资源,寄存器必须能被定义以消除未使用的位。最后,如果未使用的位可在被传递到总线之前就消除,那么总线带宽还是可以充分利用的。理想中的情况是,这些问题应在可编程逻辑之内处理,因为来自CPU所需的操作降低了整体的速率,而此时,CPU通常是可发出扩展指令的。
并行计算
对FIR滤波器硬件实现进行优化的第一步,是决定总线可高效地传给加速硬件的数据点数量。通过一个高速的宽带总线,可同时传输多个数值,例如,一个执行8次乘法和加法(MAC)的扩展指令,将以8为系数减少内部循环迭代的次数,每个流水线扩展指令可在单一周期内高效地执行,因此,整体性能将提高大约8倍。请注意,如果某一特殊的数据集不能被8整除,那么数据集将会被填充零直至为8的倍数,因此,就不一定需要特殊的末端循环指令了。
数据相乘的方法如图2所示,以高亮表示的数据点区域代表了单一扩展指令执行的运算,在扩展指令每次执行时,它都通过适当的系数乘以8个数据,并把乘积累加起来。产生的部分和将存储在局部状态变量中,随后的指令便把这些部分和相加,由此便可消除把部分和传回给CPU,随后再传给扩展指令这个过程。
图1:FIR函数示意图
例1:
void fir(short *X, short *H, short *Y, int N, int T)
{
int n, t, acc;
short *x, *h;
/* 滤波器输入 */
for (n = 0; n < N; n++) {
x = X;
h = H;
acc = (*x--) * (*h++);
for(t = 1; t < T; t++) {
acc += (*x--) * (*h++);
}
*Y = acc >> 14;
X++;
Y++;
}
}
加速的关键性考虑因素
当决定在算法中采用并行措施时,务必要留意架构上固有的一些特性:
总线位宽:数据怎样在CPU和其他部件之间传递,对整体效率和吞吐量都有着重大的影响,因为总线决定了数据可被多快地传递,输入与输出都会受到其影响。位宽太窄或速度太慢,都会成为一个处理上的瓶颈,从而影响扩展指令的执行效率,但如果总线不能被及时地填充数据以充分利用,那么不管扩展指令多有效率,都是无用的。
一般而言,总线的频率决定了扩展指令发出的频密度,而位宽则决定了扩展指令一次能处理多少数据。注意,某些架构提供了CPU与各部件之间的多重总线,由此来进行硬件加速,例如Stretch公司的S5以软件配置的处理器,在应用处理器与可编程部件之间,就有三个读取与两个写入端口,每个均为128位的位宽,并提供每条扩展指令最大读取384位及写入256位的能力。有效地利用这些总线,开发出高效的并行机制并不是件难事。
在带宽计算上,要保证带宽可把结果传回至主CPU并同时处理中间结果,这一点尤其重要。
状态寄存器:为一个复杂算法加速,通常会把算法进行分割,以便用于加速的硬件在每一次迭代中只计算结果的某一部分。因为滤波器是作为一个部分函数执行,也就是说,总体结果中只有一些离散的段是通过扩展指令执行的,而且,经常会有一些中间结果需要传递给下一个函数的调用,例如,在FIR函数最初的C实现中,一个连续的总数或中间结果必须在主算法循环的每一次迭代中都保留。再者,当应用更先进的优化技术时,中间结果的数量也会逐步增加。
为达到加速的目的,必须在每次迭代之间防止产生这些中间结果,因为这些值经常会通过数据总线传回到主CPU,而CPU又会把它们返回给函数,以便进行下一次迭代。此过程不仅消耗有限的总线带宽,而且也浪费了宝贵的CPU时钟周期,降低了整体处理的效率。
为保证效率,在此可使用状态寄存器。状态寄存器提供了一种机制,其可存储函数迭代的中间结果,而又不会涉及到主CPU或在总线上传递数据,因此,利用状态寄存器,可使整体的并行机制变得更有效率,而可用的状态寄存器数目,又进一步决定了在算法中可多大程度地利用这类并行机制。
数据大小:许多的架构在有关某数据类型占用的位宽方面,只提供了一个有限的子集,例如,一个布尔变量通常只需要一比特位,但在实现中,大小经常至少是一个字节,而一般对CPU来说,这样做会提高效率,因为对一个比特位进行掩码操作所花的代价及性能上的影响,远远要比浪费7个比特位更多;当传递数据给扩展指令,而此时CPU又必须立即剥离和打包这些比特位时,就会损失一部分效率。另外,为节约可编程逻辑资源,寄存器必须能被定义以消除未使用的位。最后,如果未使用的位可在被传递到总线之前就消除,那么总线带宽还是可以充分利用的。理想中的情况是,这些问题应在可编程逻辑之内处理,因为来自CPU所需的操作降低了整体的速率,而此时,CPU通常是可发出扩展指令的。
并行计算
对FIR滤波器硬件实现进行优化的第一步,是决定总线可高效地传给加速硬件的数据点数量。通过一个高速的宽带总线,可同时传输多个数值,例如,一个执行8次乘法和加法(MAC)的扩展指令,将以8为系数减少内部循环迭代的次数,每个流水线扩展指令可在单一周期内高效地执行,因此,整体性能将提高大约8倍。请注意,如果某一特殊的数据集不能被8整除,那么数据集将会被填充零直至为8的倍数,因此,就不一定需要特殊的末端循环指令了。
数据相乘的方法如图2所示,以高亮表示的数据点区域代表了单一扩展指令执行的运算,在扩展指令每次执行时,它都通过适当的系数乘以8个数据,并把乘积累加起来。产生的部分和将存储在局部状态变量中,随后的指令便把这些部分和相加,由此便可消除把部分和传回给CPU,随后再传给扩展指令这个过程。
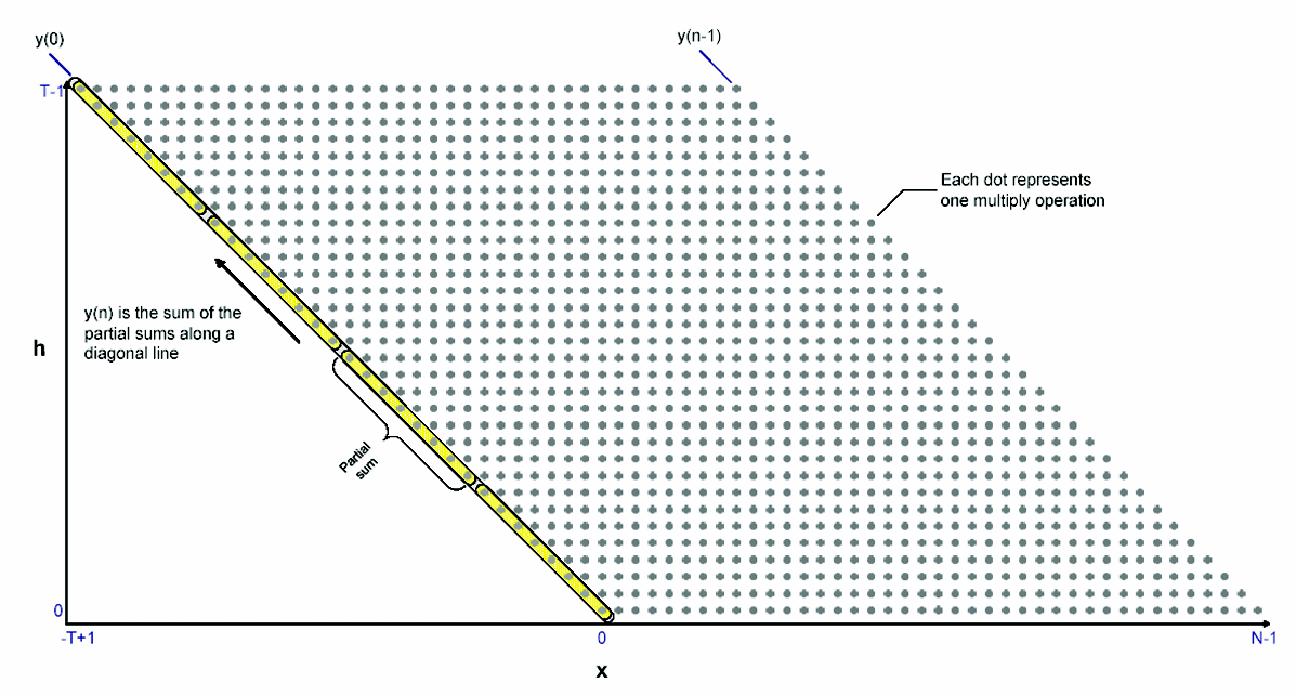 图2:数据相乘的方法
每条扩展指令执行8次MAC,可把执行范例FIR滤波器所需的理论最小周期数降低到1941,与直接用C实现的方法相比,性能上可提高15倍。
可同时运算的最优数量,依赖于可用的可编程资源数量,因为这些资源是在CPU当前访问的各种扩展指令之间共享的,所以,合理地节约使用可编程资源,对最大化提高系统整体性能来说,就显得极其重要,只要可能,就要尽量复用这些资源。
复用的效率可通过使用两条扩展指令来作一演示,分别是FIR_MUL和FIR_MAC(见例2)。
例2:
#include
图2:数据相乘的方法
每条扩展指令执行8次MAC,可把执行范例FIR滤波器所需的理论最小周期数降低到1941,与直接用C实现的方法相比,性能上可提高15倍。
可同时运算的最优数量,依赖于可用的可编程资源数量,因为这些资源是在CPU当前访问的各种扩展指令之间共享的,所以,合理地节约使用可编程资源,对最大化提高系统整体性能来说,就显得极其重要,只要可能,就要尽量复用这些资源。
复用的效率可通过使用两条扩展指令来作一演示,分别是FIR_MUL和FIR_MAC(见例2)。
例2:
#include
static se_sint<32> acc;
/* 执行8路并行MAC */
SE_FUNC void
firFunc(SE_INST FIR_MUL, SE_INST FIR_MAC, WR X, WR H, WR *Y)
{
se_sint<16>x, h
se_sint<32> sum ;
int i ;
sum = 0;
for(i = 0; i < 128; i += 16) {
h = H(i + 15, i);
x = X(127-i, 112-i);
sum += x * h ;
}
acc = FIR_MUL ? sum : se_sint<32>(sum + acc) ;
*Y = acc >> 14 ;
}
在FIR滤波器第一次调用时,部分和状态需要重设,这通常由FIR_MUL处理。在64路滤波器的情况中,将有7个并发的迭代调用FIR_MAC,它们都将使用先前已有的部分和。FIR_MUL与FIR_MAC的主要不同之处在于下面这一行代码:
acc = FIR_MUL ? sum : se_int<32>(sum + acc)
如果扩展指令通过FIR_MUL被调用,上述代码将有效地重设部分和,如果通过FIR_MAC调用,将直接使用部分和。
这种实现的好处就是复用了分配给剩余函数的可编程逻辑,同一可编程资源能被共享,就不需要为了这两条扩展指令,而增加可用资源了。合理地使用这些资源,并有选择性地解决与之相关的延迟,在这种情况下,就不会对性能产生实质性的影响,因而,就有更多的资源可用于实现其他扩展指令或进一步优化当前指令。
好事不怕多
如果要更进一步地优化,就要增加在每条扩展指令执行时处理的数据点数量,因为集成了可编程逻辑,才让灵活的实现变成了可能,所以不需重新设计,就可对扩展指令加以修订,提高执行效率。相比之下,基于ASIC或FPGA的架构就需要彻底改造、调整,并调试修改过的功能。ASIC与FPGA的设计源于独立且明显不同的开发环境,通常需要硬件方面的专门技术,并由第二个开发团队来协助工作,因此,为实现硬件加速而进行的修改或重分配,在结果未被准确评估之前,会遇到人们心理上的抵抗。
当把硬件分离出作为软件时,生成程序代码的同一编译器也能为可编程逻辑生成相应的配置。这样,编译器也能有效地管理资源和依赖性,并使性能达到最优化。另外,因为硬件的实现是由编译器自动生成的,所以只需一个开发团队就行了,这不但降低了把设计移交给另一个团队时的复杂性,而且在不需要投入更多开发时间进行人工优化的前提下,给予了充分的自由来测试和评估多种实现。
举例来说,FIR滤波器就可通过减少调用扩展指令的次数,来进一步地优化,不但减少了调度扩展指令的麻烦,也减少了调用扩展指令时系统整体的开销。
如果把并行MAC的数目增加到16,性能上会有多大提高呢?图3中,需计算一个4×4的数据区域,而计算这些数据点,至少对一个FIR滤波器来说,需要4个系数与7个数据点,与16个系数与16个数据点的实现相比,后者从单一的斜行中就可计算出部分和,这提高了总线带宽的利用率,其使用更少的带宽,却可执行更多的计算,这是通过把4个部分和存储在状态寄存器中,以便扩展指令下一次迭代时使用来达到的。最优化性能,其实就是在优化使用可编程资源之间取得一个平衡。
 图3:一个4×4的数据点区域
每条扩展指令可执行16-MAC,在性能上可比8-MAC的实现提高一倍,所需时钟周期减少至981,对未实现加速的版本来说,性能上提高了30倍。如果要更进一步地提高性能,可能要分配更多的可编程资源以执行32-MAC(见图4)。在这种配置下,扩展指令需要4个系数与11个数据样本,从一条指令到下一条指令,期间需保存8个部分和。关于此实现所需的时钟周期,理论上最小值为501,相对于直接用C的实现,效率大约提高了58倍。
图3:一个4×4的数据点区域
每条扩展指令可执行16-MAC,在性能上可比8-MAC的实现提高一倍,所需时钟周期减少至981,对未实现加速的版本来说,性能上提高了30倍。如果要更进一步地提高性能,可能要分配更多的可编程资源以执行32-MAC(见图4)。在这种配置下,扩展指令需要4个系数与11个数据样本,从一条指令到下一条指令,期间需保存8个部分和。关于此实现所需的时钟周期,理论上最小值为501,相对于直接用C的实现,效率大约提高了58倍。
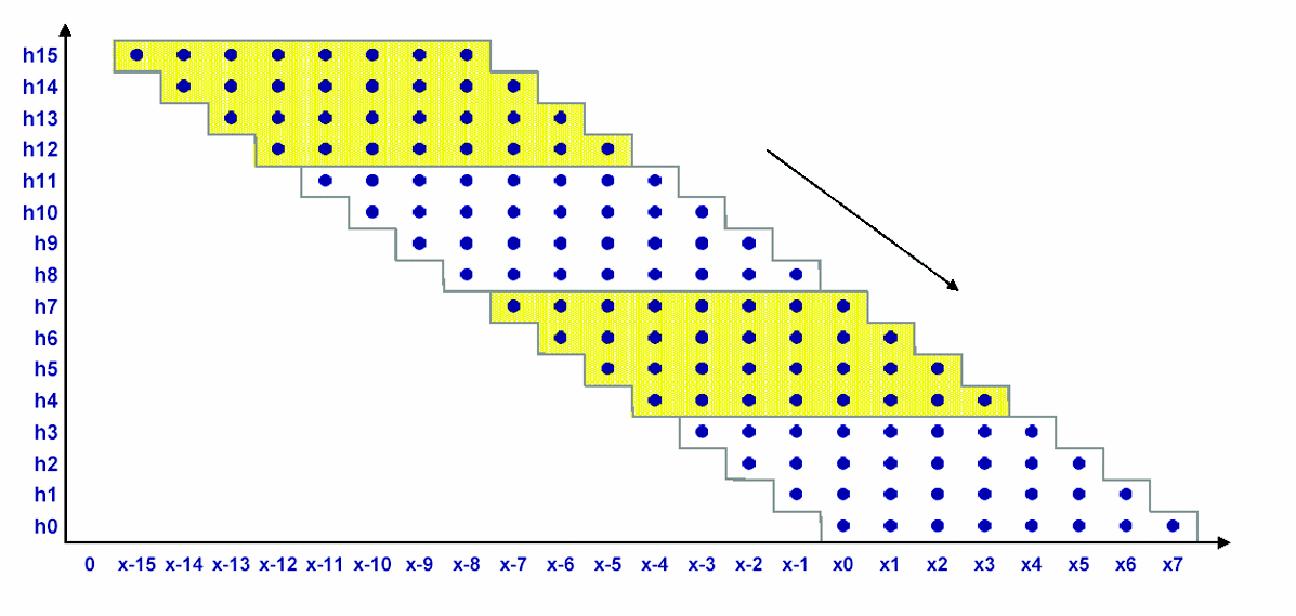 图4:分配更多的可编程资源以执行32-MAC
循环优化
虽然增加并行运算的数量,是提高性能最有效的方法,但通过常规的循环优化,也能对性能达到实质性的改进。举例说明,请看下例可同时执行8次运算的FIR滤波器实现(参见例3),之所以选择这个例子,是因为相对于可同时执行32次运算的例子,它更能保持内部代码简洁,以便更好地演示优化的技巧。
例3:
#include "fir8.h"
#define ST_DECR 1
#define ST_INCR 0
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8;
WR x, h, y;
t8 = T/8;
WRPUTINIT(ST_INCR, Y) ;
for (n = 0; n < N; n++) {
WRGET0INIT(ST_INCR, H) ;
X++ ;
WRGET1INIT(ST_DECR, X) ;
WRGET0I( &h, 16 );
WRGET1I( &x, 16);
FIR_MUL(x, h, &y);
for (t = 1; t < t8; t++) {
WRGET0I(&h, 16);
WRGET1I(&x, 16);
FIR_MAC(x, h, &y);
}
WRPUTI(y, 2) ;
}
WRPUTFLUSH0() ;
WRPUTFLUSH1() ;
}
在这个实现中,扩展指令的使用,对函数fir()的性能,有极大的改善,可从27230个时钟周期降低到5065个时钟周期,而且无需低级汇编代码或对原始C语言算法结构进行较大的修改,然而,仍有浪费掉的时钟周期存在,所以此实现还是不够高效。为特定外部循环迭代而调用最后的FIR_MAC指令之后,处理器在取得结果之前,必须等待与扩展指令延迟相等的一定周期数,浪费掉的周期就由此而产生。
一种弥补的方法是,当在等待前一轮循环输出时,即刻开始下一轮循环的运算。因为完全发送扩展指令所需的处理器周期数,要远远大于等待结果所需的周期数,因此,完全可保证在当前例子发出第一条扩展指令时,处理器已可以使用前一个例子的输出了。
在循环迭代之间,也有进行优化的可能。某一特定外部循环迭代中的内部循环运算,是不依赖于前面或后面外部循环的结果的,如果此时可发出一条新的外部循环迭代,在某种程度上可补偿等待结果的延迟。可以设想这样一种情况,对0层外部循环迭代最后一条FIR_MAC发出后,CPU可即刻开始对1层外部循环迭代中的内部循环进行运算,而不必等待0层外部循环迭代完成后所发出的扩展指令。在此实现中,最后一条FIR_MAC在给出结果之前,将大概需要21个处理器周期。照这样,如果把外部循环中的内部循环运算进行流水线操作,极有可能把每次迭代所需处理器周期降低至18,当然这是除最后一个外部循环迭代之外,因为此时已没有更多的运算量可利用周期了。假定这种情况只会在每次fir()调用时发生一次,那么系统开销几乎可以忽略不计。
基于此技巧的实现(例4),已把每次调用所需的总周期数,从5065减少到3189。这样,对现有代码无需作更多的修改,就能带来超过8倍的性能提升。
例4:
/* 包含特定的扩展指令头文件 */
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
/* 为FIR ISEF 指令调用定义宏 */
#define FIR(H, X, h, x, t8, y) /
{ /
int t8m1 = (t8)-1; /
WRGET0INIT(ST_INCR, (H)) ; /
(X)++ ; /
WRGET1INIT(ST_DECR, (X)) ; /
WRGET0I( &(h), 8 * sizeof(short) ); /
WRGET1I( &(x), 8 * sizeof(short) ); /
FIR_MUL( (x), (h), &(y) ); /
/
for (t = 1; t < (t8m1); t++) /
{ /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
} /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
}
/*
* - 在ISEF中,FIR使用8倍乘法循环优化
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR x, h, y1, y2, y3, y4;
t8 = T/8 ;
WRPUTINIT(ST_INCR, Y) ; /* 起始输出流 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
/* loop ((N/2)-1) times */
n = 0;
do
{
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
} while ( ++n < ((N>>1)-1) );
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
另一个提升性能的技巧是手工解开内部循环。因为内部循环是通过使用一个变量来管理的,而FIR宏又是为通用目的编写的,所以,编译器不能预测到循环将执行的次数,也就是完全取决于内部循环本身。然而,这些条件又反过来影响扩展指令的调度,因为它们将清除(flush)处理器流水线,而处理器又错过了可发出一条扩展指令的周期,延迟就这样产生了。
循环解开优化的实现(例5),意味着只需少许努力,就可大幅提升性能,每次调用所需周期减少至2711,整体系统提升10倍。如果在使用32-MAC扩展指令时,一起使用上述技巧,函数可在687个周期内执行完毕,相对于最初直接用C代码,性能提升超过39倍(见表1)。
例5:
/*包含特定的扩展指令头文件*/
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
#define FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) /
{ /
WRGET0I( &(h1), 8 * sizeof(short) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
WRGET0I( &(h2), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
/
WRGET0I( &(h3), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h2), &(y1) ); /
WRGET0I( &(h4), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET0I( &(h5), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h4), &(y1) ); /
WRGET0I( &(h6), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET0I( &(h7), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h6), &(y1) ); /
WRGET0I( &(h8), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h7), &(y1) ); /
WRGET1INIT(ST_DECR, X); /
FIR_MAC( (x2), (h8), &(y1) ); /
}
#define FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y2) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X); /
FIR_MAC( (x2), (h7), &(y2) ); /
WRGET1INIT1(); /
WRPUTI(y1, 2); /
FIR_MAC( (x1), (h8), &(y2) ); /
}
#define FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y1) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X) ; /
FIR_MAC( (x2), (h7), &(y1) ); /
WRGET1INIT1(); /
WRPUTI(y2, 2); /
FIR_MAC( (x1), (h8), &(y1) ); /
}
/*
* -在ISEF中,FIR使用8倍乘法循环优化 / 手工展开
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR h1, h2, h3, h4, h5, h6, h7, h8 ;
WR x1, x2;
WR y1;
WR y2;
// (these alternative "register" declarations make no difference:)
// register WR y1 SE_REG("wra1") ;
// register WR y2 SE_REG("wra2") ;
WRPUTINIT(ST_INCR, Y); /* 起始输出流 */
WRGET0INIT(ST_INCR, H); /* 起始系数流 */
X++ ;
WRGET1INIT(ST_DECR, X); /* 起始输入流 */
/* compute Y[0] in y1 */
FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) ;
/* loop ((N/2)-1) times */
for (n = 0; n < ((N>>1)-1); n++)
{
/* FIR1 输出前一个(y1)的结果,并计算当前(y2)的结果 */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
/* FIR1 输出前一个(y2)的结果,并计算当前(y1)的结果 */
FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
}
/* 在y2中计算Y[N-1],并从y1中输出Y[N-2] */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
WRPUTI(y2, 2) ; /* 输出U[N-1] */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
图4:分配更多的可编程资源以执行32-MAC
循环优化
虽然增加并行运算的数量,是提高性能最有效的方法,但通过常规的循环优化,也能对性能达到实质性的改进。举例说明,请看下例可同时执行8次运算的FIR滤波器实现(参见例3),之所以选择这个例子,是因为相对于可同时执行32次运算的例子,它更能保持内部代码简洁,以便更好地演示优化的技巧。
例3:
#include "fir8.h"
#define ST_DECR 1
#define ST_INCR 0
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8;
WR x, h, y;
t8 = T/8;
WRPUTINIT(ST_INCR, Y) ;
for (n = 0; n < N; n++) {
WRGET0INIT(ST_INCR, H) ;
X++ ;
WRGET1INIT(ST_DECR, X) ;
WRGET0I( &h, 16 );
WRGET1I( &x, 16);
FIR_MUL(x, h, &y);
for (t = 1; t < t8; t++) {
WRGET0I(&h, 16);
WRGET1I(&x, 16);
FIR_MAC(x, h, &y);
}
WRPUTI(y, 2) ;
}
WRPUTFLUSH0() ;
WRPUTFLUSH1() ;
}
在这个实现中,扩展指令的使用,对函数fir()的性能,有极大的改善,可从27230个时钟周期降低到5065个时钟周期,而且无需低级汇编代码或对原始C语言算法结构进行较大的修改,然而,仍有浪费掉的时钟周期存在,所以此实现还是不够高效。为特定外部循环迭代而调用最后的FIR_MAC指令之后,处理器在取得结果之前,必须等待与扩展指令延迟相等的一定周期数,浪费掉的周期就由此而产生。
一种弥补的方法是,当在等待前一轮循环输出时,即刻开始下一轮循环的运算。因为完全发送扩展指令所需的处理器周期数,要远远大于等待结果所需的周期数,因此,完全可保证在当前例子发出第一条扩展指令时,处理器已可以使用前一个例子的输出了。
在循环迭代之间,也有进行优化的可能。某一特定外部循环迭代中的内部循环运算,是不依赖于前面或后面外部循环的结果的,如果此时可发出一条新的外部循环迭代,在某种程度上可补偿等待结果的延迟。可以设想这样一种情况,对0层外部循环迭代最后一条FIR_MAC发出后,CPU可即刻开始对1层外部循环迭代中的内部循环进行运算,而不必等待0层外部循环迭代完成后所发出的扩展指令。在此实现中,最后一条FIR_MAC在给出结果之前,将大概需要21个处理器周期。照这样,如果把外部循环中的内部循环运算进行流水线操作,极有可能把每次迭代所需处理器周期降低至18,当然这是除最后一个外部循环迭代之外,因为此时已没有更多的运算量可利用周期了。假定这种情况只会在每次fir()调用时发生一次,那么系统开销几乎可以忽略不计。
基于此技巧的实现(例4),已把每次调用所需的总周期数,从5065减少到3189。这样,对现有代码无需作更多的修改,就能带来超过8倍的性能提升。
例4:
/* 包含特定的扩展指令头文件 */
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
/* 为FIR ISEF 指令调用定义宏 */
#define FIR(H, X, h, x, t8, y) /
{ /
int t8m1 = (t8)-1; /
WRGET0INIT(ST_INCR, (H)) ; /
(X)++ ; /
WRGET1INIT(ST_DECR, (X)) ; /
WRGET0I( &(h), 8 * sizeof(short) ); /
WRGET1I( &(x), 8 * sizeof(short) ); /
FIR_MUL( (x), (h), &(y) ); /
/
for (t = 1; t < (t8m1); t++) /
{ /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
} /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
}
/*
* - 在ISEF中,FIR使用8倍乘法循环优化
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR x, h, y1, y2, y3, y4;
t8 = T/8 ;
WRPUTINIT(ST_INCR, Y) ; /* 起始输出流 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
/* loop ((N/2)-1) times */
n = 0;
do
{
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
} while ( ++n < ((N>>1)-1) );
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
另一个提升性能的技巧是手工解开内部循环。因为内部循环是通过使用一个变量来管理的,而FIR宏又是为通用目的编写的,所以,编译器不能预测到循环将执行的次数,也就是完全取决于内部循环本身。然而,这些条件又反过来影响扩展指令的调度,因为它们将清除(flush)处理器流水线,而处理器又错过了可发出一条扩展指令的周期,延迟就这样产生了。
循环解开优化的实现(例5),意味着只需少许努力,就可大幅提升性能,每次调用所需周期减少至2711,整体系统提升10倍。如果在使用32-MAC扩展指令时,一起使用上述技巧,函数可在687个周期内执行完毕,相对于最初直接用C代码,性能提升超过39倍(见表1)。
例5:
/*包含特定的扩展指令头文件*/
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
#define FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) /
{ /
WRGET0I( &(h1), 8 * sizeof(short) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
WRGET0I( &(h2), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
/
WRGET0I( &(h3), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h2), &(y1) ); /
WRGET0I( &(h4), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET0I( &(h5), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h4), &(y1) ); /
WRGET0I( &(h6), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET0I( &(h7), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h6), &(y1) ); /
WRGET0I( &(h8), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h7), &(y1) ); /
WRGET1INIT(ST_DECR, X); /
FIR_MAC( (x2), (h8), &(y1) ); /
}
#define FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y2) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X); /
FIR_MAC( (x2), (h7), &(y2) ); /
WRGET1INIT1(); /
WRPUTI(y1, 2); /
FIR_MAC( (x1), (h8), &(y2) ); /
}
#define FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y1) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X) ; /
FIR_MAC( (x2), (h7), &(y1) ); /
WRGET1INIT1(); /
WRPUTI(y2, 2); /
FIR_MAC( (x1), (h8), &(y1) ); /
}
/*
* -在ISEF中,FIR使用8倍乘法循环优化 / 手工展开
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR h1, h2, h3, h4, h5, h6, h7, h8 ;
WR x1, x2;
WR y1;
WR y2;
// (these alternative "register" declarations make no difference:)
// register WR y1 SE_REG("wra1") ;
// register WR y2 SE_REG("wra2") ;
WRPUTINIT(ST_INCR, Y); /* 起始输出流 */
WRGET0INIT(ST_INCR, H); /* 起始系数流 */
X++ ;
WRGET1INIT(ST_DECR, X); /* 起始输入流 */
/* compute Y[0] in y1 */
FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) ;
/* loop ((N/2)-1) times */
for (n = 0; n < ((N>>1)-1); n++)
{
/* FIR1 输出前一个(y1)的结果,并计算当前(y2)的结果 */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
/* FIR1 输出前一个(y2)的结果,并计算当前(y1)的结果 */
FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
}
/* 在y2中计算Y[N-1],并从y1中输出Y[N-2] */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
WRPUTI(y2, 2) ; /* 输出U[N-1] */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
 表1:
通过在应用型处理器和流水线中集成可编程逻辑,以软件方式配置的架构,只需少许手工优化,在运算密集的算法中,也能提供实质上硬件加速的效果。正是因为可把“硬件设计成软件”,开发者现在能避免在硬件与软件之间,由于算法分割上的实现,而带来的复杂性了,并且编译器处理了实际硬件实现上的复杂性,开发者现在能快速、轻松地设计更复杂的算法,评估各种实现的效率,以最大化地提升性能及控制成本。
表1:
通过在应用型处理器和流水线中集成可编程逻辑,以软件方式配置的架构,只需少许手工优化,在运算密集的算法中,也能提供实质上硬件加速的效果。正是因为可把“硬件设计成软件”,开发者现在能避免在硬件与软件之间,由于算法分割上的实现,而带来的复杂性了,并且编译器处理了实际硬件实现上的复杂性,开发者现在能快速、轻松地设计更复杂的算法,评估各种实现的效率,以最大化地提升性能及控制成本。
图1:FIR函数示意图
例1:
void fir(short *X, short *H, short *Y, int N, int T)
{
int n, t, acc;
short *x, *h;
/* 滤波器输入 */
for (n = 0; n < N; n++) {
x = X;
h = H;
acc = (*x--) * (*h++);
for(t = 1; t < T; t++) {
acc += (*x--) * (*h++);
}
*Y = acc >> 14;
X++;
Y++;
}
}
加速的关键性考虑因素
当决定在算法中采用并行措施时,务必要留意架构上固有的一些特性:
总线位宽:数据怎样在CPU和其他部件之间传递,对整体效率和吞吐量都有着重大的影响,因为总线决定了数据可被多快地传递,输入与输出都会受到其影响。位宽太窄或速度太慢,都会成为一个处理上的瓶颈,从而影响扩展指令的执行效率,但如果总线不能被及时地填充数据以充分利用,那么不管扩展指令多有效率,都是无用的。
一般而言,总线的频率决定了扩展指令发出的频密度,而位宽则决定了扩展指令一次能处理多少数据。注意,某些架构提供了CPU与各部件之间的多重总线,由此来进行硬件加速,例如Stretch公司的S5以软件配置的处理器,在应用处理器与可编程部件之间,就有三个读取与两个写入端口,每个均为128位的位宽,并提供每条扩展指令最大读取384位及写入256位的能力。有效地利用这些总线,开发出高效的并行机制并不是件难事。
在带宽计算上,要保证带宽可把结果传回至主CPU并同时处理中间结果,这一点尤其重要。
状态寄存器:为一个复杂算法加速,通常会把算法进行分割,以便用于加速的硬件在每一次迭代中只计算结果的某一部分。因为滤波器是作为一个部分函数执行,也就是说,总体结果中只有一些离散的段是通过扩展指令执行的,而且,经常会有一些中间结果需要传递给下一个函数的调用,例如,在FIR函数最初的C实现中,一个连续的总数或中间结果必须在主算法循环的每一次迭代中都保留。再者,当应用更先进的优化技术时,中间结果的数量也会逐步增加。
为达到加速的目的,必须在每次迭代之间防止产生这些中间结果,因为这些值经常会通过数据总线传回到主CPU,而CPU又会把它们返回给函数,以便进行下一次迭代。此过程不仅消耗有限的总线带宽,而且也浪费了宝贵的CPU时钟周期,降低了整体处理的效率。
为保证效率,在此可使用状态寄存器。状态寄存器提供了一种机制,其可存储函数迭代的中间结果,而又不会涉及到主CPU或在总线上传递数据,因此,利用状态寄存器,可使整体的并行机制变得更有效率,而可用的状态寄存器数目,又进一步决定了在算法中可多大程度地利用这类并行机制。
数据大小:许多的架构在有关某数据类型占用的位宽方面,只提供了一个有限的子集,例如,一个布尔变量通常只需要一比特位,但在实现中,大小经常至少是一个字节,而一般对CPU来说,这样做会提高效率,因为对一个比特位进行掩码操作所花的代价及性能上的影响,远远要比浪费7个比特位更多;当传递数据给扩展指令,而此时CPU又必须立即剥离和打包这些比特位时,就会损失一部分效率。另外,为节约可编程逻辑资源,寄存器必须能被定义以消除未使用的位。最后,如果未使用的位可在被传递到总线之前就消除,那么总线带宽还是可以充分利用的。理想中的情况是,这些问题应在可编程逻辑之内处理,因为来自CPU所需的操作降低了整体的速率,而此时,CPU通常是可发出扩展指令的。
并行计算
对FIR滤波器硬件实现进行优化的第一步,是决定总线可高效地传给加速硬件的数据点数量。通过一个高速的宽带总线,可同时传输多个数值,例如,一个执行8次乘法和加法(MAC)的扩展指令,将以8为系数减少内部循环迭代的次数,每个流水线扩展指令可在单一周期内高效地执行,因此,整体性能将提高大约8倍。请注意,如果某一特殊的数据集不能被8整除,那么数据集将会被填充零直至为8的倍数,因此,就不一定需要特殊的末端循环指令了。
数据相乘的方法如图2所示,以高亮表示的数据点区域代表了单一扩展指令执行的运算,在扩展指令每次执行时,它都通过适当的系数乘以8个数据,并把乘积累加起来。产生的部分和将存储在局部状态变量中,随后的指令便把这些部分和相加,由此便可消除把部分和传回给CPU,随后再传给扩展指令这个过程。
图2:数据相乘的方法
每条扩展指令执行8次MAC,可把执行范例FIR滤波器所需的理论最小周期数降低到1941,与直接用C实现的方法相比,性能上可提高15倍。
可同时运算的最优数量,依赖于可用的可编程资源数量,因为这些资源是在CPU当前访问的各种扩展指令之间共享的,所以,合理地节约使用可编程资源,对最大化提高系统整体性能来说,就显得极其重要,只要可能,就要尽量复用这些资源。
复用的效率可通过使用两条扩展指令来作一演示,分别是FIR_MUL和FIR_MAC(见例2)。
例2:
#include
图3:一个4×4的数据点区域
每条扩展指令可执行16-MAC,在性能上可比8-MAC的实现提高一倍,所需时钟周期减少至981,对未实现加速的版本来说,性能上提高了30倍。如果要更进一步地提高性能,可能要分配更多的可编程资源以执行32-MAC(见图4)。在这种配置下,扩展指令需要4个系数与11个数据样本,从一条指令到下一条指令,期间需保存8个部分和。关于此实现所需的时钟周期,理论上最小值为501,相对于直接用C的实现,效率大约提高了58倍。
图4:分配更多的可编程资源以执行32-MAC
循环优化
虽然增加并行运算的数量,是提高性能最有效的方法,但通过常规的循环优化,也能对性能达到实质性的改进。举例说明,请看下例可同时执行8次运算的FIR滤波器实现(参见例3),之所以选择这个例子,是因为相对于可同时执行32次运算的例子,它更能保持内部代码简洁,以便更好地演示优化的技巧。
例3:
#include "fir8.h"
#define ST_DECR 1
#define ST_INCR 0
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8;
WR x, h, y;
t8 = T/8;
WRPUTINIT(ST_INCR, Y) ;
for (n = 0; n < N; n++) {
WRGET0INIT(ST_INCR, H) ;
X++ ;
WRGET1INIT(ST_DECR, X) ;
WRGET0I( &h, 16 );
WRGET1I( &x, 16);
FIR_MUL(x, h, &y);
for (t = 1; t < t8; t++) {
WRGET0I(&h, 16);
WRGET1I(&x, 16);
FIR_MAC(x, h, &y);
}
WRPUTI(y, 2) ;
}
WRPUTFLUSH0() ;
WRPUTFLUSH1() ;
}
在这个实现中,扩展指令的使用,对函数fir()的性能,有极大的改善,可从27230个时钟周期降低到5065个时钟周期,而且无需低级汇编代码或对原始C语言算法结构进行较大的修改,然而,仍有浪费掉的时钟周期存在,所以此实现还是不够高效。为特定外部循环迭代而调用最后的FIR_MAC指令之后,处理器在取得结果之前,必须等待与扩展指令延迟相等的一定周期数,浪费掉的周期就由此而产生。
一种弥补的方法是,当在等待前一轮循环输出时,即刻开始下一轮循环的运算。因为完全发送扩展指令所需的处理器周期数,要远远大于等待结果所需的周期数,因此,完全可保证在当前例子发出第一条扩展指令时,处理器已可以使用前一个例子的输出了。
在循环迭代之间,也有进行优化的可能。某一特定外部循环迭代中的内部循环运算,是不依赖于前面或后面外部循环的结果的,如果此时可发出一条新的外部循环迭代,在某种程度上可补偿等待结果的延迟。可以设想这样一种情况,对0层外部循环迭代最后一条FIR_MAC发出后,CPU可即刻开始对1层外部循环迭代中的内部循环进行运算,而不必等待0层外部循环迭代完成后所发出的扩展指令。在此实现中,最后一条FIR_MAC在给出结果之前,将大概需要21个处理器周期。照这样,如果把外部循环中的内部循环运算进行流水线操作,极有可能把每次迭代所需处理器周期降低至18,当然这是除最后一个外部循环迭代之外,因为此时已没有更多的运算量可利用周期了。假定这种情况只会在每次fir()调用时发生一次,那么系统开销几乎可以忽略不计。
基于此技巧的实现(例4),已把每次调用所需的总周期数,从5065减少到3189。这样,对现有代码无需作更多的修改,就能带来超过8倍的性能提升。
例4:
/* 包含特定的扩展指令头文件 */
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
/* 为FIR ISEF 指令调用定义宏 */
#define FIR(H, X, h, x, t8, y) /
{ /
int t8m1 = (t8)-1; /
WRGET0INIT(ST_INCR, (H)) ; /
(X)++ ; /
WRGET1INIT(ST_DECR, (X)) ; /
WRGET0I( &(h), 8 * sizeof(short) ); /
WRGET1I( &(x), 8 * sizeof(short) ); /
FIR_MUL( (x), (h), &(y) ); /
/
for (t = 1; t < (t8m1); t++) /
{ /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
} /
WRGET0I( &(h), 16 ); /
WRGET1I( &(x), 16 ); /
FIR_MAC( (x), (h), &(y) ); /
}
/*
* - 在ISEF中,FIR使用8倍乘法循环优化
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR x, h, y1, y2, y3, y4;
t8 = T/8 ;
WRPUTINIT(ST_INCR, Y) ; /* 起始输出流 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
/* loop ((N/2)-1) times */
n = 0;
do
{
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
FIR (H, X, h, x, t8, y1) ; /* x * h + y => y1 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
} while ( ++n < ((N>>1)-1) );
FIR (H, X, h, x, t8, y2) ; /* x * h + y => y2 */
WRPUTI(y1, 2) ; /* 输出(y1)结果 */
WRPUTI(y2, 2) ; /* 输出(y2)结果 */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
另一个提升性能的技巧是手工解开内部循环。因为内部循环是通过使用一个变量来管理的,而FIR宏又是为通用目的编写的,所以,编译器不能预测到循环将执行的次数,也就是完全取决于内部循环本身。然而,这些条件又反过来影响扩展指令的调度,因为它们将清除(flush)处理器流水线,而处理器又错过了可发出一条扩展指令的周期,延迟就这样产生了。
循环解开优化的实现(例5),意味着只需少许努力,就可大幅提升性能,每次调用所需周期减少至2711,整体系统提升10倍。如果在使用32-MAC扩展指令时,一起使用上述技巧,函数可在687个周期内执行完毕,相对于最初直接用C代码,性能提升超过39倍(见表1)。
例5:
/*包含特定的扩展指令头文件*/
#include "fir8.h"
#define ST_DECR 1 /* 减量指示器 */
#define ST_INCR 0 /* 增量指示器 */
#define FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) /
{ /
WRGET0I( &(h1), 8 * sizeof(short) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
WRGET0I( &(h2), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
/
WRGET0I( &(h3), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h2), &(y1) ); /
WRGET0I( &(h4), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET0I( &(h5), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h4), &(y1) ); /
WRGET0I( &(h6), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET0I( &(h7), 16 ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x2), (h6), &(y1) ); /
WRGET0I( &(h8), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h7), &(y1) ); /
WRGET1INIT(ST_DECR, X); /
FIR_MAC( (x2), (h8), &(y1) ); /
}
#define FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y2) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y2) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y2) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X); /
FIR_MAC( (x2), (h7), &(y2) ); /
WRGET1INIT1(); /
WRPUTI(y1, 2); /
FIR_MAC( (x1), (h8), &(y2) ); /
}
#define FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) /
{ /
WRGET1I( &(x1), 16 ); /
FIR_MUL( (x1), (h1), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h2), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h3), &(y1) ); /
WRGET1I( &(x1), 16 ); /
FIR_MAC( (x1), (h4), &(y1) ); /
WRGET1I( &(x1), 16 ); /
X++ ; /
FIR_MAC( (x1), (h5), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1I( &(x2), 16 ); /
FIR_MAC( (x1), (h6), &(y1) ); /
WRGET1I( &(x1), 16 ); /
WRGET1INIT0(ST_DECR, X) ; /
FIR_MAC( (x2), (h7), &(y1) ); /
WRGET1INIT1(); /
WRPUTI(y2, 2); /
FIR_MAC( (x1), (h8), &(y1) ); /
}
/*
* -在ISEF中,FIR使用8倍乘法循环优化 / 手工展开
*/
void fir(short *X, short *H, short *Y, short N, short T)
{
int n, t, t8 ;
WR h1, h2, h3, h4, h5, h6, h7, h8 ;
WR x1, x2;
WR y1;
WR y2;
// (these alternative "register" declarations make no difference:)
// register WR y1 SE_REG("wra1") ;
// register WR y2 SE_REG("wra2") ;
WRPUTINIT(ST_INCR, Y); /* 起始输出流 */
WRGET0INIT(ST_INCR, H); /* 起始系数流 */
X++ ;
WRGET1INIT(ST_DECR, X); /* 起始输入流 */
/* compute Y[0] in y1 */
FIR(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, X) ;
/* loop ((N/2)-1) times */
for (n = 0; n < ((N>>1)-1); n++)
{
/* FIR1 输出前一个(y1)的结果,并计算当前(y2)的结果 */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
/* FIR1 输出前一个(y2)的结果,并计算当前(y1)的结果 */
FIR2(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
}
/* 在y2中计算Y[N-1],并从y1中输出Y[N-2] */
FIR1(h1, h2, h3, h4, h5, h6, h7, h8, x1, x2, y1, y2, X) ;
WRPUTI(y2, 2) ; /* 输出U[N-1] */
WRPUTFLUSH0() ; /* 清除输出流 */
WRPUTFLUSH1() ; /* 清除输出流 */
}
表1:
通过在应用型处理器和流水线中集成可编程逻辑,以软件方式配置的架构,只需少许手工优化,在运算密集的算法中,也能提供实质上硬件加速的效果。正是因为可把“硬件设计成软件”,开发者现在能避免在硬件与软件之间,由于算法分割上的实现,而带来的复杂性了,并且编译器处理了实际硬件实现上的复杂性,开发者现在能快速、轻松地设计更复杂的算法,评估各种实现的效率,以最大化地提升性能及控制成本。