背景
DSP系统是互联网广告需求方平台,用于承接媒体流量,投放广告。业务特点是并发度高,平均响应低(百毫秒)。
为了能够有效提高DSP系统的性能,美团平台引入了一种带有清退机制的缓存结构LruCache(Least Recently Used Cache),在目前的DSP系统中,使用LruCache + 键值存储数据库的机制将远端数据变为本地缓存数据,不仅能够降低平均获取信息的耗时,而且通过一定的清退机制,也可以维持服务内存占用在安全区间。
本文将会结合实际应用场景,阐述引入LruCache的原因,并会在高QPS下的挑战与解决方案等方面做详细深入的介绍,希望能对DSP感兴趣的同学有所启发。
LruCache简介
LruCache采用的缓存算法为LRU(Least Recently Used),即最近最少使用算法。这一算法的核心思想是当缓存数据达到预设上限后,会优先淘汰近期最少使用的缓存对象。
LruCache内部维护一个双向链表和一个映射表。链表按照使用顺序存储缓存数据,越早使用的数据越靠近链表尾部,越晚使用的数据越靠近链表头部;映射表通过Key-Value结构,提供高效的查找操作,通过键值可以判断某一数据是否缓存,如果缓存直接获取缓存数据所属的链表节点,进一步获取缓存数据。LruCache结构图如下所示,上半部分是双向链表,下半部分是映射表(不一定有序)。双向链表中value_1所处位置为链表头部,value_N所处位置为链表尾部。
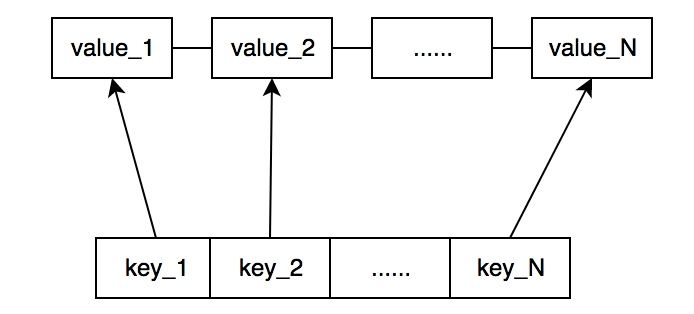
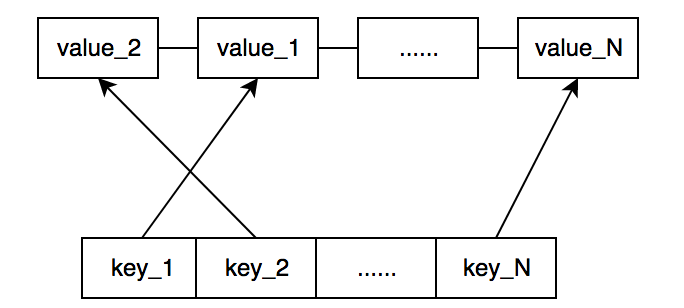
LruCache读操作,通过键值在映射表中查找缓存数据是否存在。如果数据存在,则将缓存数据所处节点从链表中当前位置取出,移动到链表头部;如果不存在,则返回查找失败,等待新数据写入。下图为通过LruCache查找key_2后LruCache结构的变化。
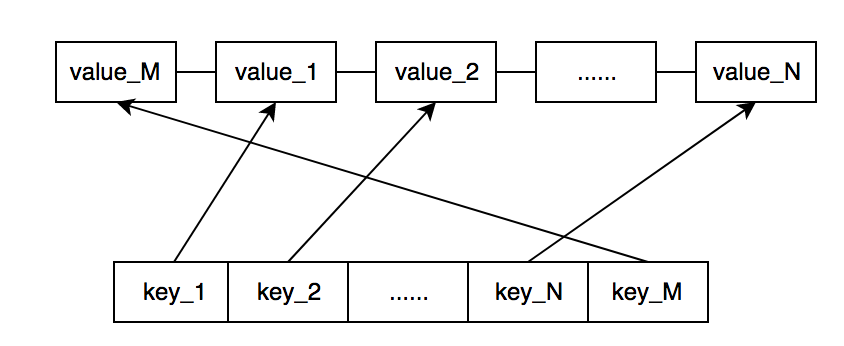
LruCache没有达到预设上限情况下的写操作,直接将缓存数据加入到链表头部,同时将缓存数据键值与缓存数据所处的双链表节点作为键值对插入到映射表中。下图是LruCache预设上限大于N时,将数据M写入后的数据结构。
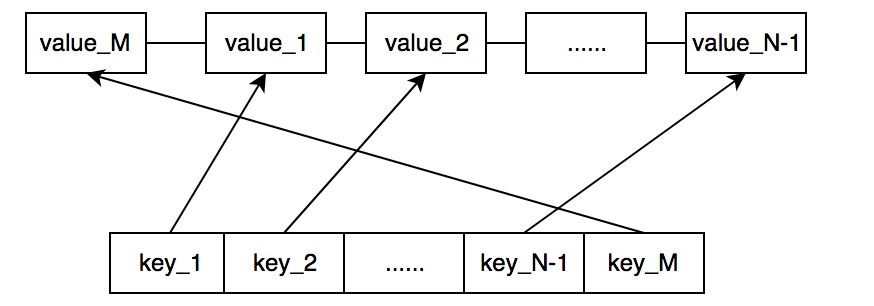
LruCache达到预设上限情况下的写操作,首先将链表尾部的缓存数据在映射表中的键值对删除,并删除链表尾部数据,再将新的数据正常写入到缓存中。下图是LruCache预设上限为N时,将数据M写入后的数据结构。
线程安全的LruCache在读写操作中,全部使用锁做临界区保护,确保缓存使用是线程安全的。
LruCache在美团DSP系统的应用场景
在美团DSP系统中广泛应用键值存储数据库,例如使用Redis存储广告信息,服务可以通过广告ID获取广告信息。每次请求都从远端的键值存储数据库中获取广告信息,请求耗时非常长。随着业务发展,QPS呈现巨大的增长趋势,在这种高并发的应用场景下,将广告信息从远端键值存储数据库中迁移到本地以减少查询耗时是常见解决方案。另外服务本身的内存占用要稳定在一个安全的区间内。面对持续增长的广告信息,引入LruCache + 键值存储数据库的机制来达到提高系统性能,维持内存占用安全、稳定的目标。
LruCache + Redis机制的应用演进
在实际应用中,LruCache + Redis机制实践分别经历了引入LruCache、LruCache增加时效清退机制、HashLruCache满足高QPS应用场景以及零拷贝机制四个阶段。各阶段的测试机器是16核16G机器。
演进一:引入LruCache提高美团DSP系统性能
在较低QPS环境下,直接请求Redis获取广告信息,可以满足场景需求。但是随着单机QPS的增加,直接请求Redis获取广告信息,耗时也会增加,无法满足业务场景的需求。
引入LruCache,将远端存放于Redis的信息本地化存储。LruCache可以预设缓存上限,这个上限可以根据服务所在机器内存与服务本身内存占用来确定,确保增加LruCache后,服务本身内存占用在安全范围内;同时可以根据查询操作统计缓存数据在实际使用中的命中率。
下图是增加LruCache结构前后,且增加LruCache后命中率高于95%的情况下,针对持续增长的QPS得出的数据获取平均耗时(ms)对比图:
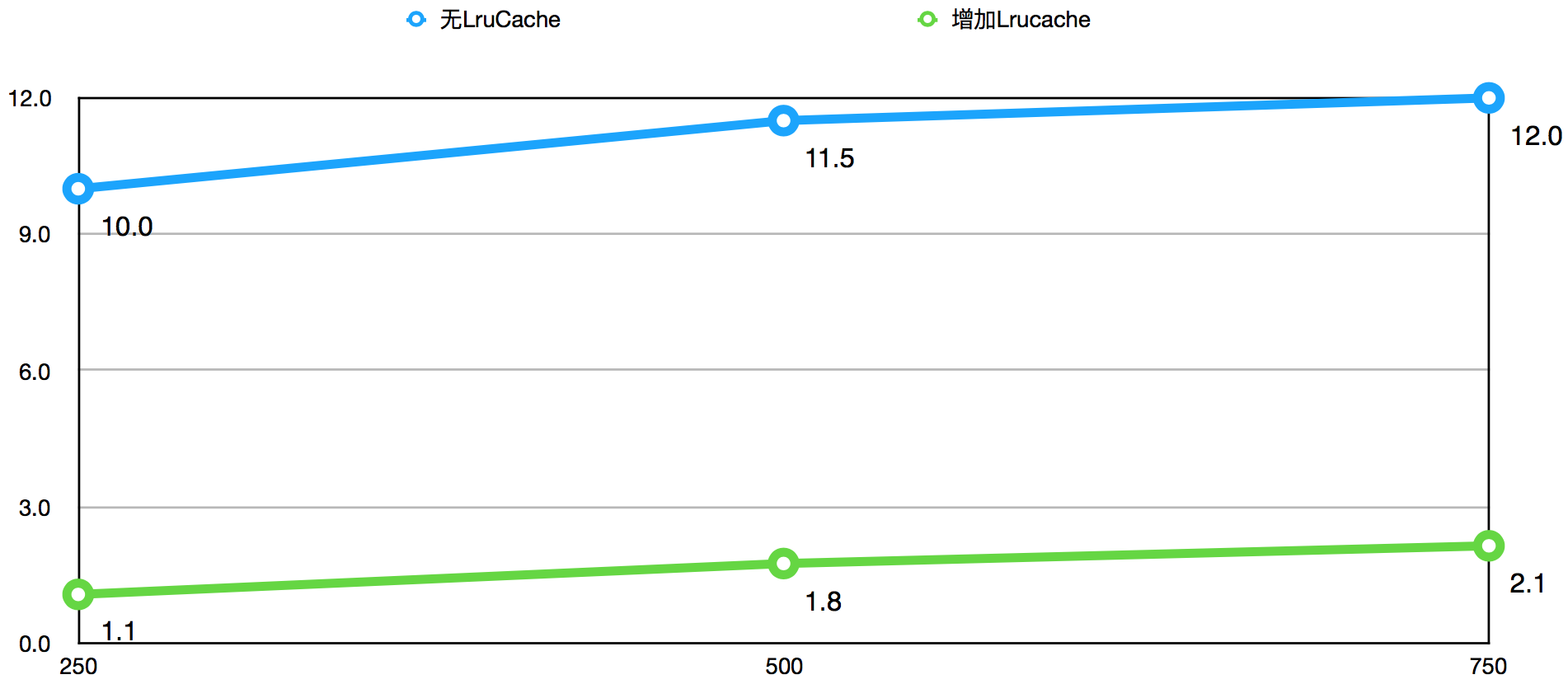
根据平均耗时图显示可以得出结论:
- QPS高于250后,直接请求Redis获取数据的平均耗时达到10ms以上,完全无法满足使用的需求。
- 增加LruCache结构后,耗时下降一个量级。从平均耗时角度看,QPS不高于500的情况下,耗时低于2ms。
下图是增加LruCache结构前后,且增加LruCache后命中率高于95%的情况下,针对持续增长的QPS得出的数据获取Top999耗时(ms)对比图:
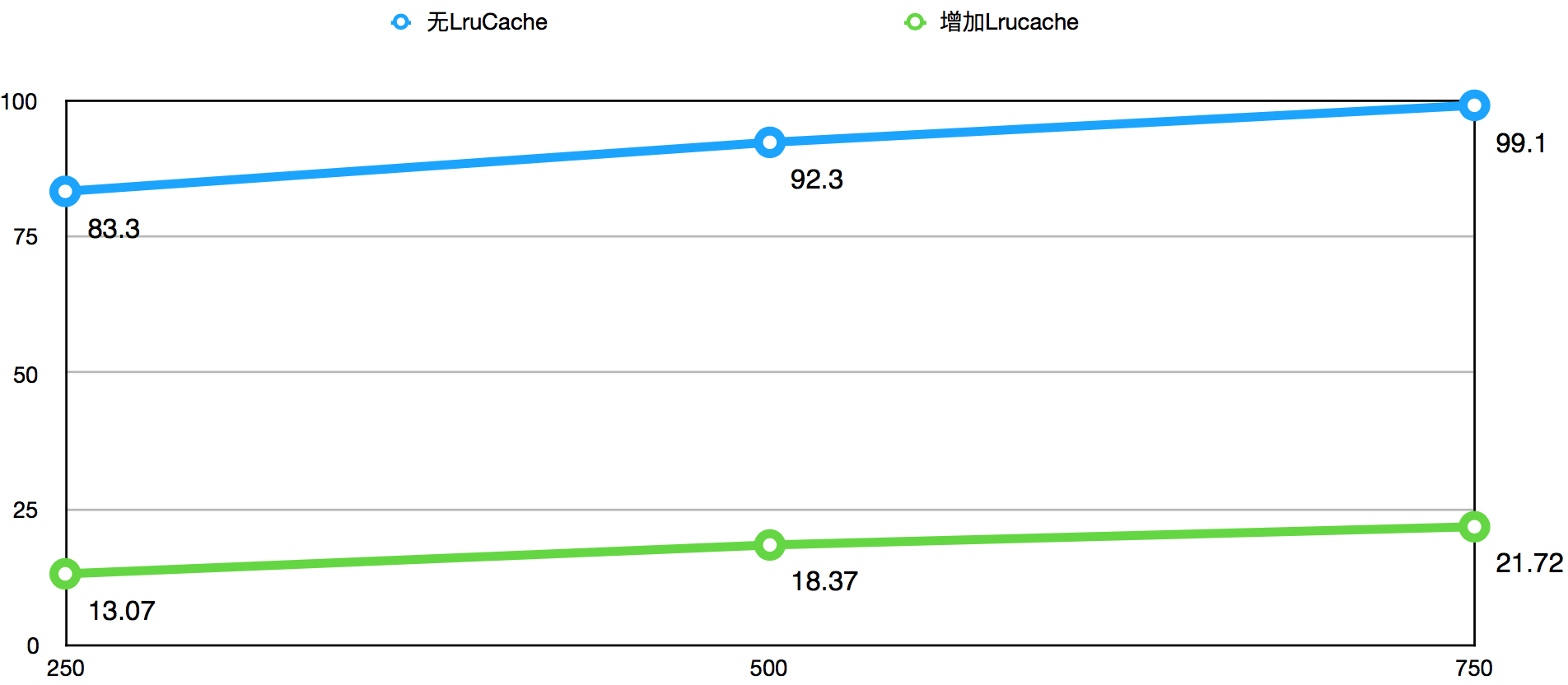
根据Top999耗时图可以得出以下结论:
- 增加LruCache结构后,Top999耗时比平均耗时增长一个数量级。
- 即使是较低的QPS下,使用LruCache结构的Top999耗时也是比较高的。
引入LruCache结构,在实际使用中,在一定的QPS范围内,确实可以有效减少数据获取的耗时。但是QPS超出一定范围后,平均耗时和Top999耗时都很高。所以LruCache在更高的QPS下性能还需要进一步优化。
演进二:LruCache增加时效清退机制
在业务场景中,Redis中的广告数据有可能做修改。服务本身作为数据的使用方,无法感知到数据源的变化。当缓存的命中率较高或者部分数据在较长时间内多次命中,可能出现数据失效的情况。即数据源发生了变化,但服务无法及时更新数据。针对这一业务场景,增加了时效清退机制。
时效清退机制的组成部分有三点:设置缓存数据过期时间,缓存数据单元增加时间戳以及查询中的时效性判断。缓存数据单元将数据进入LruCache的时间戳与数据一起缓存下来。缓存过期时间表示缓存单元缓存的时间上限。查询中的时效性判断表示查询时的时间戳与缓存时间戳的差值超过缓存过期时间,则强制将此数据清空,重新请求Redis获取数据做缓存。
在查询中做时效性判断可以最低程度的减少时效判断对服务的中断。当LruCache预设上限较低时,定期做全量数据清理对于服务本身影响较小。但如果LruCache的预设上限非常高,则一次全量数据清理耗时可能达到秒级甚至分钟级,将严重阻断服务本身的运行。所以将时效性判断加入到查询中,只对单一的缓存单元做时效性判断,在服务性能和数据有效性之间做了折中,满足业务需求。
演进三:高QPS下HashLruCache的应用
LruCache引入美团DSP系统后,在一段时间内较好地支持了业务的发展。随着业务的迭代,单机QPS持续上升。在更高QPS下,LruCache的查询耗时有了明显的提高,逐渐无法适应低平响的业务场景。在这种情况下,引入了HashLruCache机制以解决这个问题。
LruCache在高QPS下的耗时增加原因分析:
线程安全的LruCache中有锁的存在。每次读写操作之前都有加锁操作,完成读写操作之后还有解锁操作。在低QPS下,锁竞争的耗时基本可以忽略;但是在高QPS下,大量的时间消耗在了等待锁的操作上,导致耗时增长。
HashLruCache适应高QPS场景:
针对大量的同步等待操作导致耗时增加的情况,解决方案就是尽量减小临界区。引入Hash机制,对全量数据做分片处理,在原有LruCache的基础上形成HashLruCache,以降低查询耗时。
HashLruCache引入某种哈希算法,将缓存数据分散到N个LruCache上。最简单的哈希算法即使用取模算法,将广告信息按照其ID取模,分散到N个LruCache上。查询时也按照相同的哈希算法,先获取数据可能存在的分片,然后再去对应的分片上查询数据。这样可以增加LruCache的读写操作的并行度,减小同步等待的耗时。
下图是使用16分片的HashLruCache结构前后,且命中率高于95%的情况下,针对持续增长的QPS得出的数据获取平均耗时(ms)对比图:
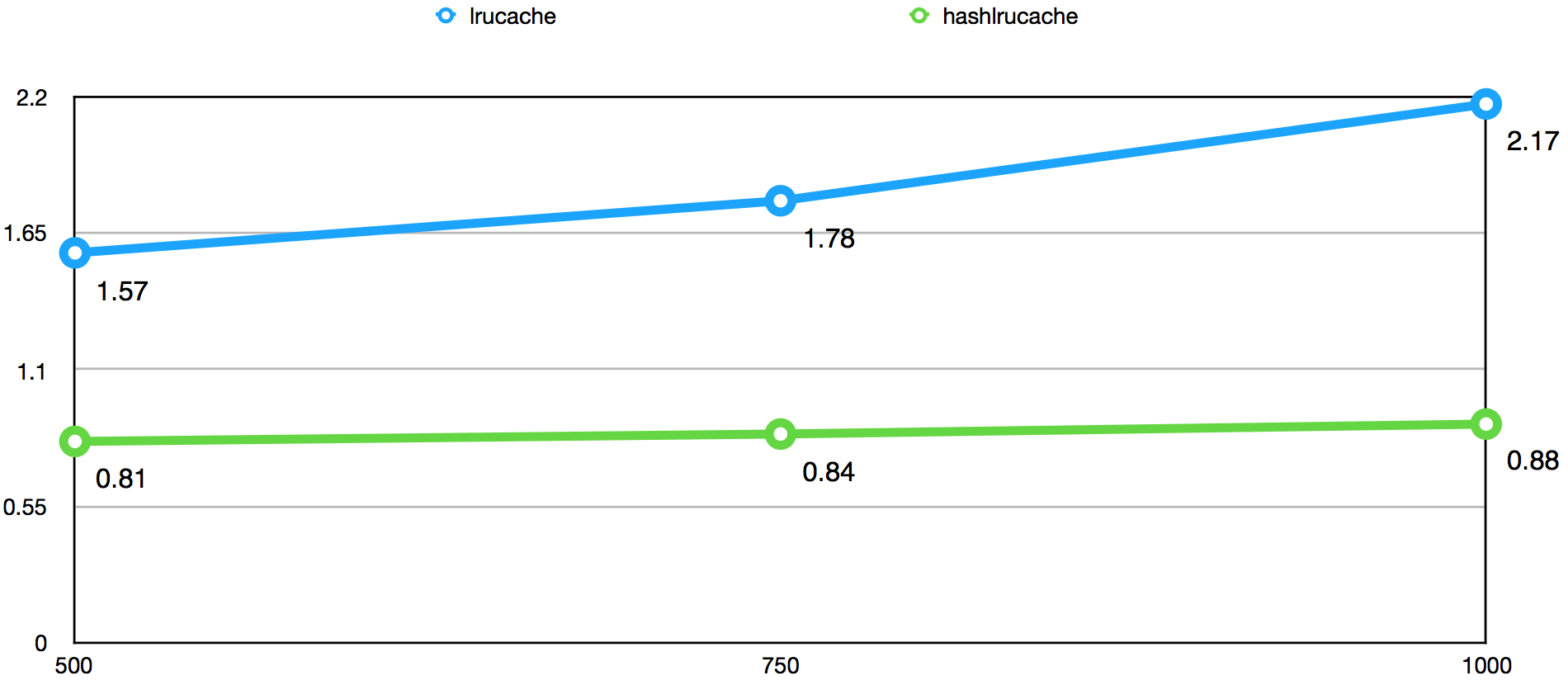
根据平均耗时图可以得出以下结论:
- 使用HashLruCache后,平均耗时减少将近一半,效果比较明显。
- 对比不使用HashLruCache的平均耗时可以发现,使用HashLruCache的平均耗时对QPS的增长不敏感,没有明显增长。
下图是使用16分片的HashLruCache结构前后,且命中率高于95%的情况下,针对持续增长的QPS得出的数据获取Top999耗时(ms)对比图:
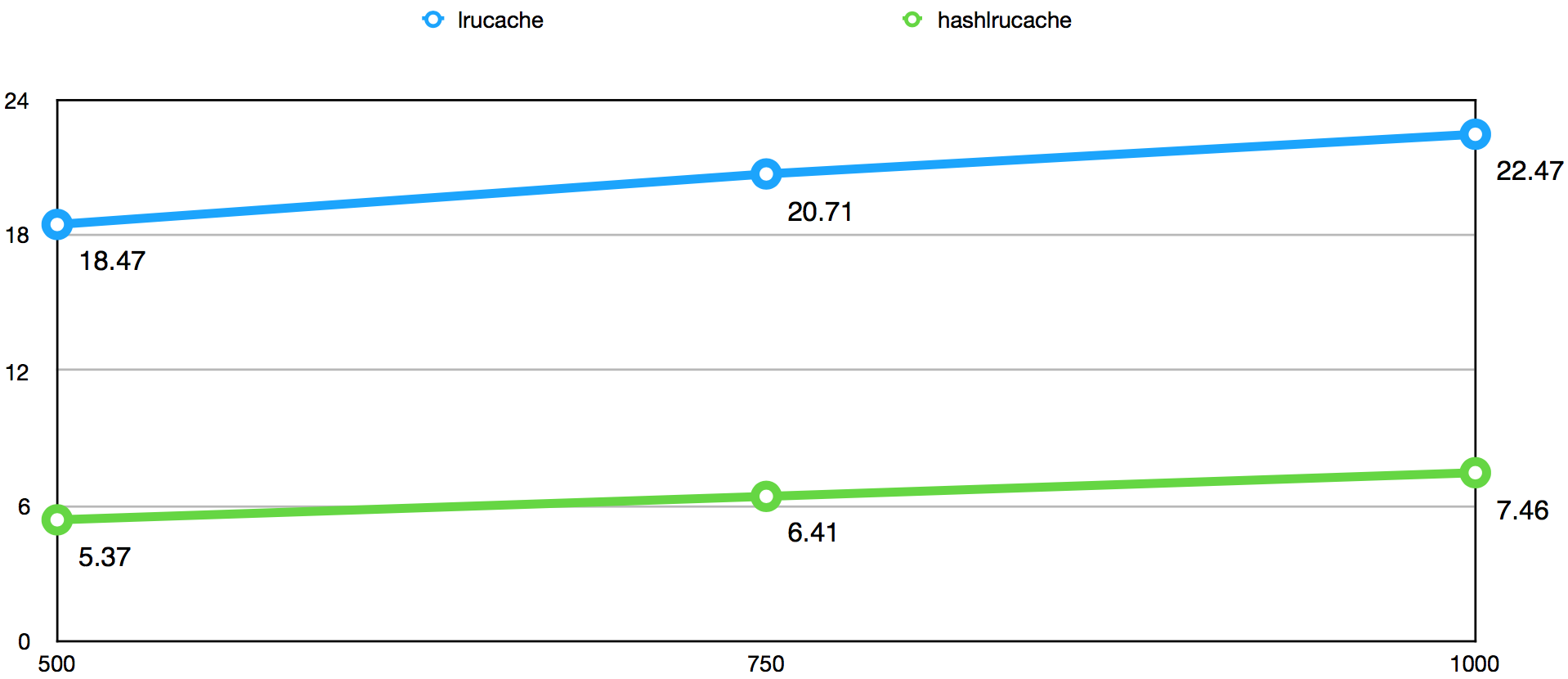
根据Top999耗时图可以得出以下结论:
- 使用HashLruCache后,Top999耗时减少为未使用时的三分之一左右,效果非常明显。
- 使用HashLruCache的Top999耗时随QPS增长明显比不使用的情况慢,相对来说对QPS的增长敏感度更低。
引入HashLruCache结构后,在实际使用中,平均耗时和Top999耗时都有非常明显的下降,效果非常显著。
HashLruCache分片数量确定:
根据以上分析,进一步提高HashLruCache性能的一个方法是确定最合理的分片数量,增加足够的并行度,减少同步等待消耗。所以分片数量可以与CPU数量一致。由于超线程技术的使用,可以将分片数量进一步提高,增加并行性。
下图是使用HashLruCache机制后,命中率高于95%,不同分片数量在不同QPS下得出的数据获取平均耗时(ms)对比图:
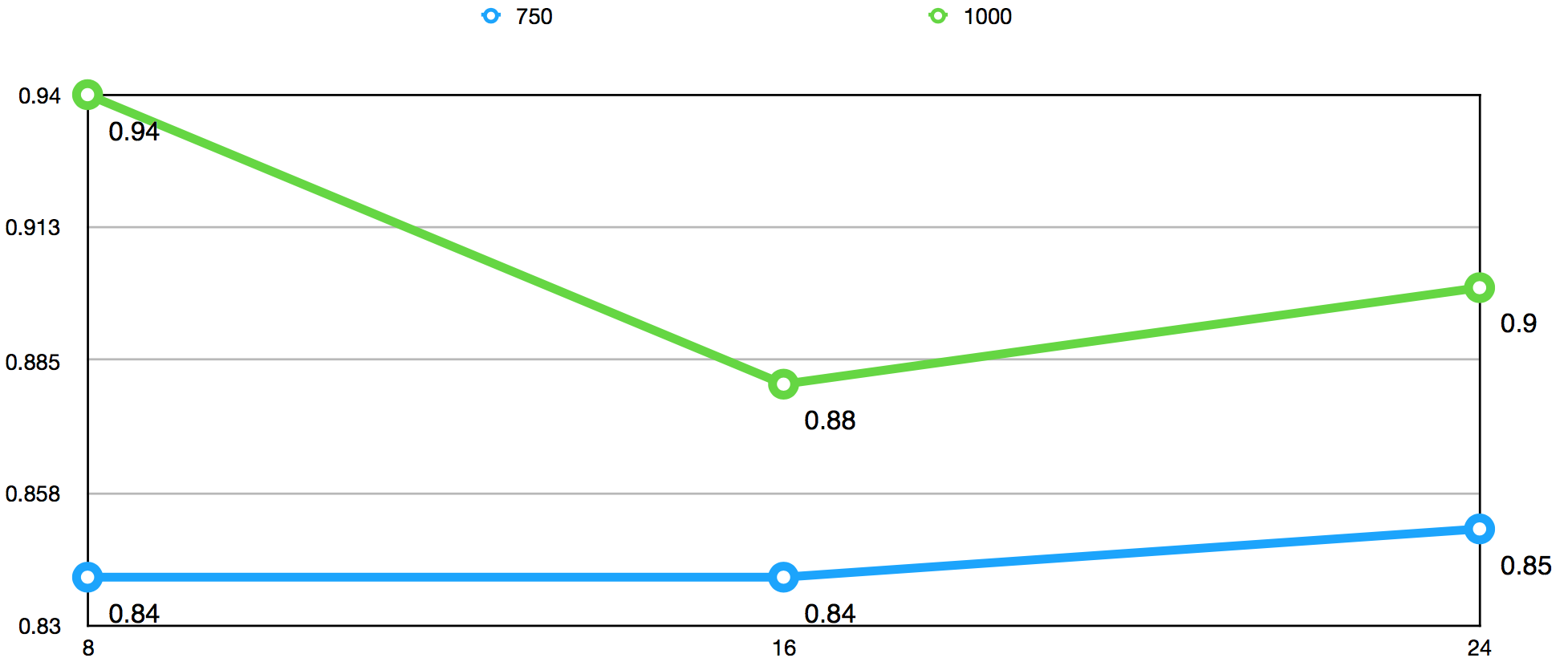
平均耗时图显示,在较高的QPS下,平均耗时并没有随着分片数量的增加而有明显的减少,基本维持稳定的状态。
下图是使用HashLruCache机制后,命中率高于95%,不同分片数量在不同QPS下得出的数据获取Top999耗时(ms)对比图:
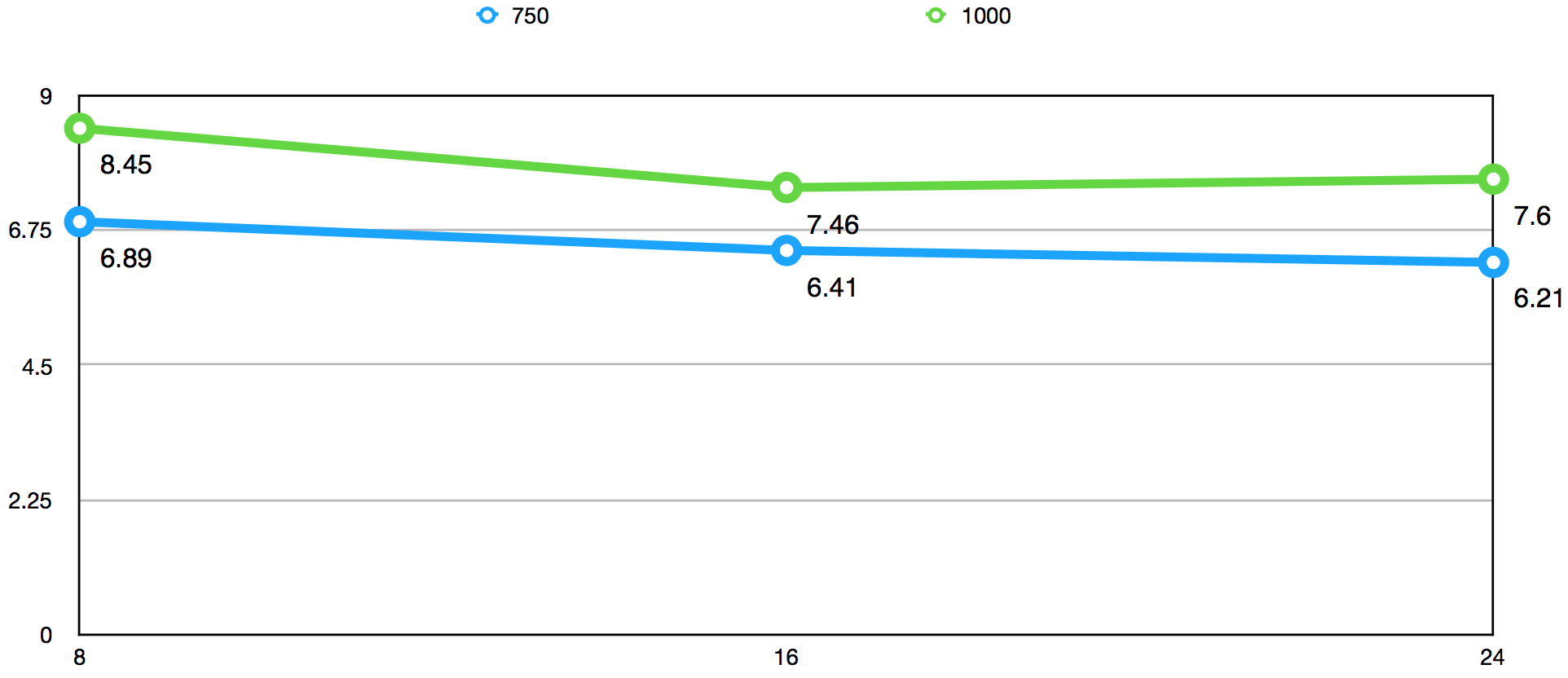
Top999耗时图显示,QPS为750时,分片数量从8增长到16再增长到24时,Top999耗时有一定的下降,并不显著;QPS为1000时,分片数量从8增长到16有明显下降,但是从16增长到24时,基本维持了稳定状态。明显与实际使用的机器CPU数量有较强的相关性。
HashLruCache机制在实际使用中,可以根据机器性能并结合实际场景的QPS来调节分片数量,以达到最好的性能。
演进四:零拷贝机制
线程安全的LruCache内部维护一套数据。对外提供数据时,将对应的数据完整拷贝一份提供给调用方使用。如果存放结构简单的数据,拷贝操作的代价非常小,这一机制不会成为性能瓶颈。但是美团DSP系统的应用场景中,LruCache中存放的数据结构非常复杂,单次的拷贝操作代价很大,导致这一机制变成了性能瓶颈。
理想的情况是LruCache对外仅仅提供数据地址,即数据指针。使用方在业务需要使用的地方通过数据指针获取数据。这样可以将复杂的数据拷贝操作变为简单的地址拷贝,大量减少拷贝操作的性能消耗,即数据的零拷贝机制。直接的零拷贝机制存在安全隐患,即由于LruCache中的时效清退机制,可能会出现某一数据已经过期被删除,但是使用方仍然通过持有失效的数据指针来获取该数据。
进一步分析可以确定,以上问题的核心是存放于LruCache的数据生命周期对于使用方不透明。解决这一问题的方案是为LruCache中存放的数据添加原子变量的引用计数。使用原子变量不仅确保了引用计数的线程安全,使得各个线程读取的引用计数一致,同时保证了并发状态最小的同步性能开销。不论是LruCache中还是使用方,每次获取数据指针时,即将引用计数加1;同理,不再持有数据指针时,引用计数减1。当引用计数为0时,说明数据没有被任何使用方使用,且数据已经过期从LruCache中被删除。这时删除数据的操作是安全的。
下图是使零拷贝机制后,命中率高于95%,不同QPS下得出的数据获取平均耗时(ms)对比图:
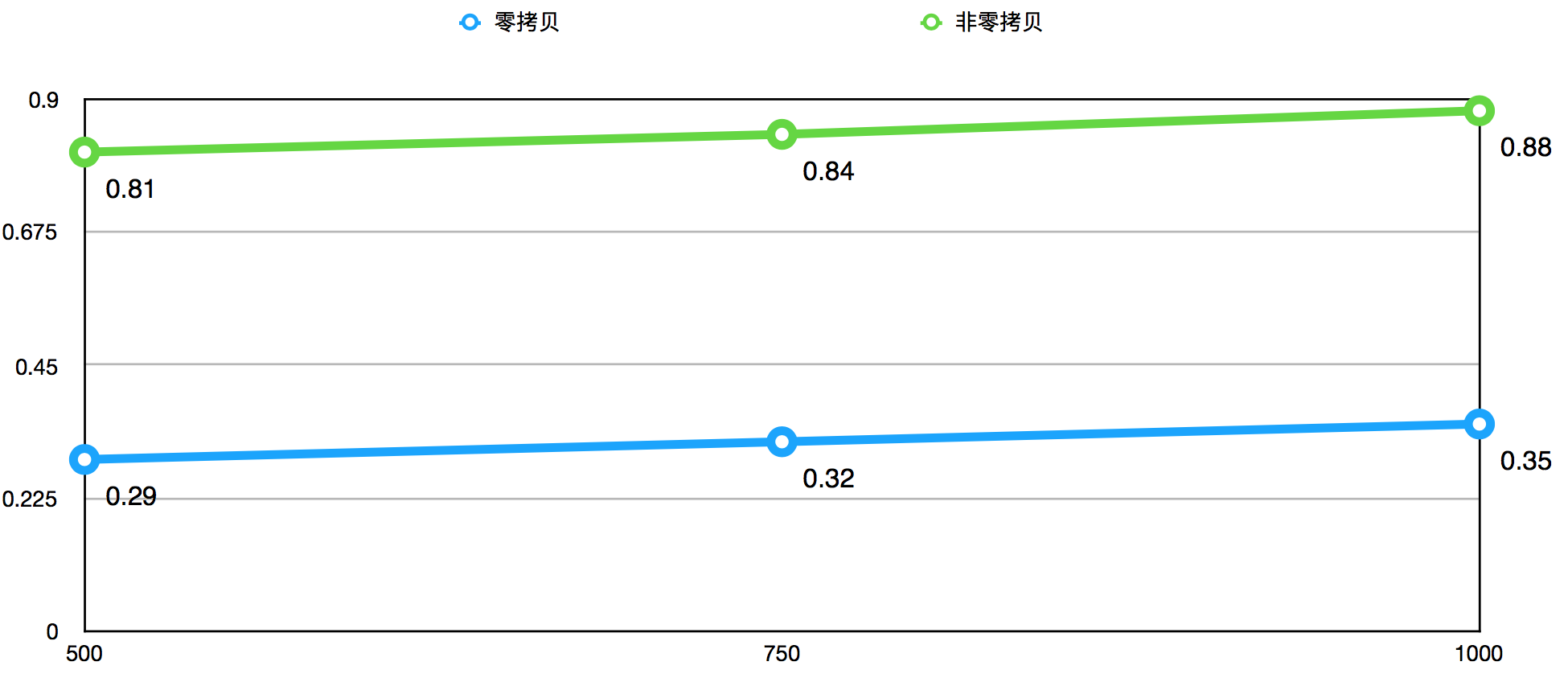
平均耗时图显示,使用零拷贝机制后,平均耗时下降幅度超过60%,效果非常显著。
下图是使零拷贝机制后,命中率高于95%,不同QPS下得出的数据获取Top999耗时(ms)对比图:
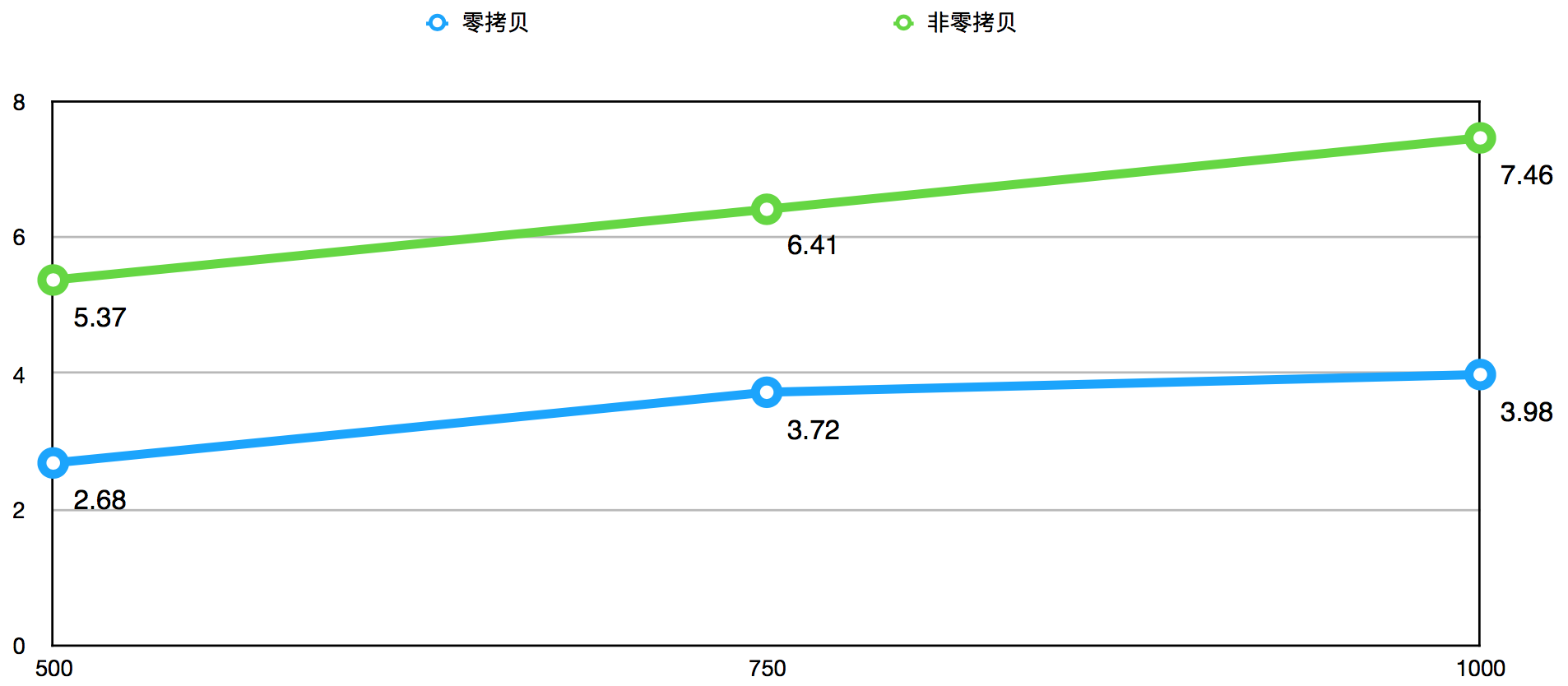
根据Top999耗时图可以得出以下结论:
- 使用零拷贝后,Top999耗时降幅将近50%,效果非常明显。
- 在高QPS下,使用零拷贝机制的Top999耗时随QPS增长明显比不使用的情况慢,相对来说对QPS的增长敏感度更低。
引入零拷贝机制后,通过拷贝指针替换拷贝数据,大量降低了获取复杂业务数据的耗时,同时将临界区减小到最小。线程安全的原子变量自增与自减操作,目前在多个基础库中都有实现,例如C++11就提供了内置的整型原子变量,实现线程安全的自增与自减操作。
在HashLruCache中引入零拷贝机制,可以进一步有效降低平均耗时和Top999耗时,且在高QPS下对于稳定Top999耗时有非常好的效果。
总结
下图是一系列优化措施前后,命中率高于95%,不同QPS下得出的数据获取平均耗时(ms)对比图:
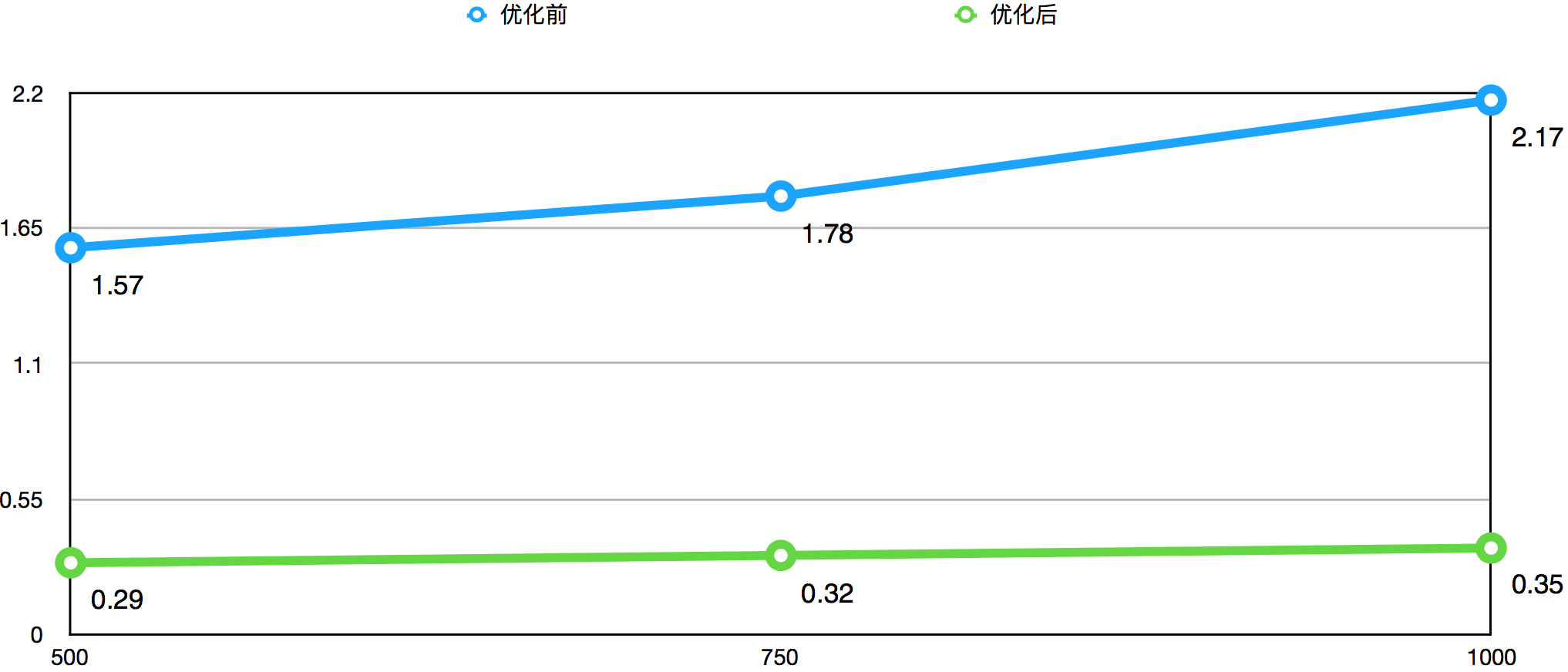
平均耗时图显示,优化后的平均耗时仅为优化前的20%以内,性能提升非常明显。优化后平均耗时对于QPS的增长敏感度更低,更好的支持了高QPS的业务场景。
下图是一系列优化措施前后,命中率高于95%,不同QPS下得出的数据获取Top999耗时(ms)对比图:
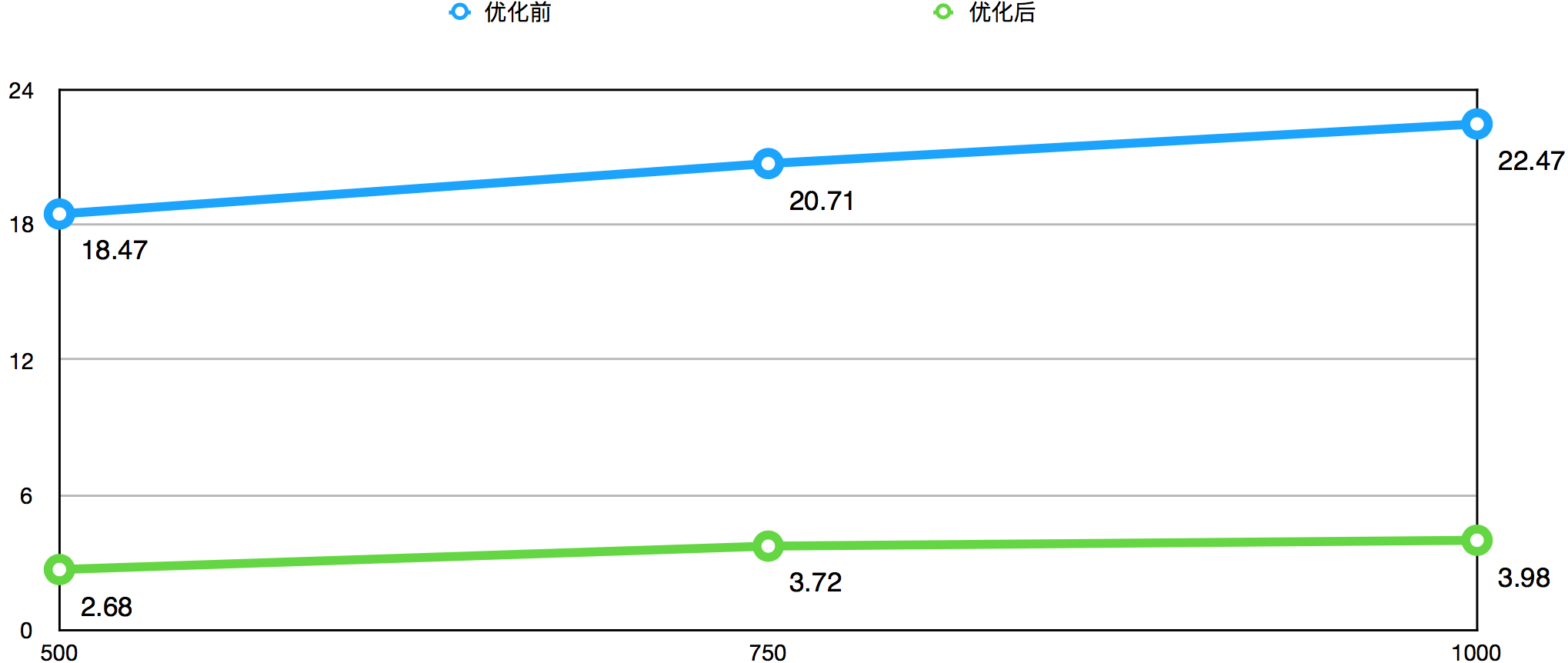
Top999耗时图显示,优化后的Top999耗时仅为优化前的20%以内,对于长尾请求的耗时有非常明显的降低。
LruCache是一个非常常见的数据结构。在美团DSP的高QPS业务场景下,发挥了重要的作用。为了符合业务需要,在原本的清退机制外,补充了时效性强制清退机制。随着业务的发展,针对更高QPS的业务场景,使用HashLruCache机制,降低缓存的查询耗时。针对不同的具体场景,在不同的QPS下,不断尝试更合理的分片数量,不断提高HashLruCache的查询性能。通过引用计数的方案,在HashLruCache中引入零拷贝机制,进一步大幅降低平均耗时和Top999耗时,更好的服务于业务场景的发展。
作者简介
王粲,2018年11月加入美团,任职美团高级工程师,负责美团DSP系统后端基础架构的研发工作。
崔涛,2015年6月加入美团,任职资深广告技术专家,期间一手指导并从0到1搭建美团DSP投放平台,具备丰富的大规模计算引擎的开发和性能优化经验。
霜霜,2015年6月加入美团,任职美团高级工程师,美团DSP系统后端基础架构与机器学习架构负责人,全面负责DSP业务广告召回和排序服务的架构设计与优化。
招聘
美团在线营销DSP团队诚招工程、算法、数据等各方向精英,发送简历至cuitao@meituan.com,共同支持百亿级流量的高可靠系统研发与优化。

{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 ideal716 的文章《LruCache在美团DSP系统中的应用演进》','https://www.xiaopingtou.net/article-80259.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}