{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 猪头哥哥 的文章《基于INTEL FPGA硬浮点DSP实现卷积运算》','https://www.xiaopingtou.net/article-80277.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}

概述 卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波。而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络。本参考设计主要介绍如何基于INTEL 硬浮点的DSP Block实现32位单精度浮点的卷积运算,而针对定点及低精度的浮点运算,则需要对硬浮点DSP Block进行相应的替换即可。 原理分析 设:f(x), g(x)是两个可积函数,作积分:
 随着x的不同取值,该积分定义了一个新的函数h(x),称为函数f(x)与g(x)的卷积,记为h(x)=f(x)*g(x)。
如果卷积的变量是序列x(n)和h(n),则卷积的结果为
随着x的不同取值,该积分定义了一个新的函数h(x),称为函数f(x)与g(x)的卷积,记为h(x)=f(x)*g(x)。
如果卷积的变量是序列x(n)和h(n),则卷积的结果为
 其中*表示卷积。因此两个序列的卷积,实际上就是多项式的乘法,用个例子说明其工作原理。a = [7,5,4]; b = [6,7,9];则实现a和b的卷积,就是把a和b作为一个多项式的系数,按多项式的升幂或降幂排列,即为:
其中*表示卷积。因此两个序列的卷积,实际上就是多项式的乘法,用个例子说明其工作原理。a = [7,5,4]; b = [6,7,9];则实现a和b的卷积,就是把a和b作为一个多项式的系数,按多项式的升幂或降幂排列,即为:
 则[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果即为由a*b得到的多项式的各项系数所组成的序列。令c=a*b,得到
则由多项式c的各阶系数所组成的新的序列[c0,c1,c2, …,c2n-1]即为[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果。则按照高阶多项式计算展开可得到:
则[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果即为由a*b得到的多项式的各项系数所组成的序列。令c=a*b,得到
则由多项式c的各阶系数所组成的新的序列[c0,c1,c2, …,c2n-1]即为[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果。则按照高阶多项式计算展开可得到:
 ┆┆
┆┆
 ┆┆
┆┆
 图1 硬浮点DSPblock架构
硬浮点DSP Block包含硬浮点乘法器,硬浮点加法器,支持乘累加运算,因此采用硬浮点DSPblock实现行列向量相乘是非常好的方式。下面我们针对一个实际的卷积运算,介绍如何基于INTEL硬浮点DSP block实现。假设我们需要求随机数组a=[4,8,9,11]与b=[10,5,7,13]的卷积运算结果,则根据上面的分析,保持数组a顺序不变,而数组b需根据上述分析结果,针对每一个卷积结果产生新的序列。所以整个实现包括数列重组模块和硬浮点乘法器模块及输出处理。下面是实现框图及仿真结果。
图1 硬浮点DSPblock架构
硬浮点DSP Block包含硬浮点乘法器,硬浮点加法器,支持乘累加运算,因此采用硬浮点DSPblock实现行列向量相乘是非常好的方式。下面我们针对一个实际的卷积运算,介绍如何基于INTEL硬浮点DSP block实现。假设我们需要求随机数组a=[4,8,9,11]与b=[10,5,7,13]的卷积运算结果,则根据上面的分析,保持数组a顺序不变,而数组b需根据上述分析结果,针对每一个卷积结果产生新的序列。所以整个实现包括数列重组模块和硬浮点乘法器模块及输出处理。下面是实现框图及仿真结果。
 图2 实现框图
图2 实现框图
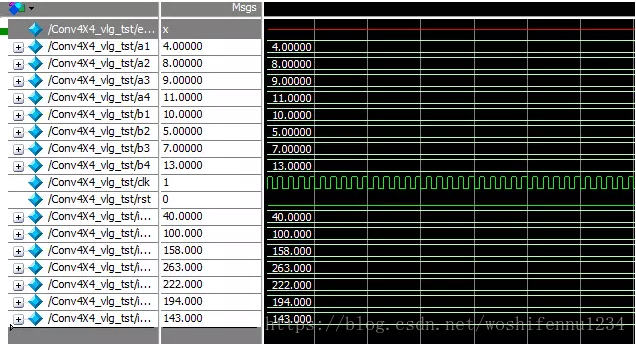 图3 Modelsim仿真结果
仿真结果与Matlab实现结果一致,并且该设计中充分考虑了FPGA并行扩展特性,对于低速率要求的设计可采用DSP Block复用的方式节约DSP block数量。
图3 Modelsim仿真结果
仿真结果与Matlab实现结果一致,并且该设计中充分考虑了FPGA并行扩展特性,对于低速率要求的设计可采用DSP Block复用的方式节约DSP block数量。
版权所有权归卿萃科技 杭州FPGA事业部,转载请注明出处 作者:杭州卿萃科技ALIFPGA 原文地址:杭州卿萃科技FPGA极客空间 微信公众号
 扫描二维码关注杭州卿萃科技FPGA极客空间
扫描二维码关注杭州卿萃科技FPGA极客空间