{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 wei348144881 的文章《OpenCL简介》','https://www.xiaopingtou.net/article-80394.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
#一、渊源
在硕士期间,由于实验室项目需求,本人在GPU上完成了一些医疗成像算法的加速。由于人工智能的爆发,笔者顺利找到了一份GPU优化的工作。如今即将毕业,笔者经过一年多的学习和应用,对于GPU编程有了基本的认识,因此在此编写几篇简单的入门引导博客,帮助更多的人尽快入门,少走弯路。如果总结中存在问题,也希望读者不吝赐教,共同探讨。
这个系列的博客主要介绍OpenCL编程的一些基础知识,通过矩阵相乘的例子,让读者了解OpenCL并行计算的基本编程方法,同时通过几种简单的优化方法比较,让读者了解GPU优化的基本思想,另外也会简单介绍涉及到的GPU架构相关的一些内容。由于旨在入门,本文只介绍简单的基础知识,不进行深入探讨。
在OpenCL的学习过程中笔者遇到过很多的困难,也有很多人给予了笔者很大的帮助。在此对他们表示感谢,感谢猫叔(猫头鹰的翅膀)、长江、Zenny Chen以及OpenCL技术开发群中诸多朋友给予笔者的帮助。
#二、GPU开发语言简介
在GPU开发中,当前的开发语言主要有OpenCL和CUDA。OpenCL和CUDA即是一种开发语言也是一种并行计算架构。CUDA是NIVIDA的并行计算架构,编程语言叫做CUDA C,也就是通常意义上说的CUDA,其语言是基于C语言语法的。CUDA仅用于NIVIDA的GPU设备开发。OpenCL是一种异构并行开发框架,是为异构计算设计的。它所支持的设备有CPU、GPU、FPGA甚至DSP等通用的或者专用的计算设备。因此OpenCL是面向CPU+其他计算设备这样的异构计算平台。同时OpenCL也是一种编程语言,也是基于C语言语法。
当前AMD和NIVIDA是PC端的两大GPU厂商,在移动端有ARM的MaLi,高通的Adreno,Imagination的PowerVR。从语言支持上看,所有的GPU都支持OpenCL,包括N卡和移动端GPU。但是很少有人在NIVIDIA GPU上使用OpenCL进行开发,因为CUDA有很好的生态,同时在N卡上CUDA会后很好的加速效果。CUDA仅支持N卡,不支持其他设备。
在移动端的GPU开发方面,苹果手机使用的是PowerVR的GPU(今年早些时候,苹果宣布停止对PowerVR的使用,讲自己研制GPU),但是它不支持OpenCL,它的开发使用的是苹果的移动端并行开发语言metal,相对于OpenCL,metal更简洁,吸取了OpenCL和CUDA的一些优点,做了一些改进。整体而言三种并行开发语言的思想想通,学会一个其他上手相对容易。
除此之外,还有OpenACC等一些并行API,笔者没有进行深入研究,不做评价。
#三、OpenCL基本知识
OpenCL作为一种异构并行的编程架构,它屏蔽了底层的硬件结构,将其抽象为工作空间、工作组、工作项、全局存储、局部存储以及私有存储等概念。本节主要介绍在GPU编程中,OpenCL关于这些抽象概念的组织结构,以及一些调度原则。关于GPU硬件架构方面的内容会在以后的博文中简单介绍。
首先介绍,工作空间、工作组以及工作项的组织关系。
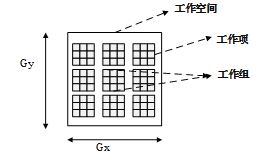
OpenCL的工作空间可以是一维的、二维的、三维的。可以通过OpenCL提供的API进行设置。本文展示了二维的工作空间,每一个工作空间包含若干个工作组,每个工作组又包含若干个工作项。每一个工作组中的工作项有一段共享的内存——局部内存(local memory)。可以通过具体的API查看工作组局部内存的大小。笔者使用的是AMD W7100显卡,局部内存为32KB。每个工作组所包含的工作项的数量可以通过具体的API查到,笔者使用的显卡为256。也就是说,每一个工作组包含256个(至多256,可以小于256)工作项和32KB的局部存储器。32KB的局部内存对于工作组内的所有工作项是可见的,可用于组内数据的交换或者数据缓冲,对于其他工作组的工作项是不可见的。
完成计算的最小单位就是工作项,开发者通过操作每个工作项来完成整个计算任务。举一个简单的例子,假设需要完成两个二维矩阵的加法,矩阵维度为1024×1024。那么可以申请工作空间维度为1024×1024,每个工作项完成一组数据的加法,完成两个矩阵相加。因为每个工作项都有全局索引和局部索引,而矩阵的存储,不同的元素也有不同的索引,可以通过索引来设定每个工作项的计算任务。
接下来介绍存储器的组织形式。

可以看到,这个存储器分为三级,全局存储器、局部存储器和私有存储器。全局存储器对所有的工作项可见,但是访问速度最慢;局部存储器对工作组可见,访问速度较高,超过告诉Cache,因此合理的使用Local,可以有效提升程序性能。除了局部内存外,每个工作项可以申请私有存储,私有存储一般对应的是寄存器,因此访问的速度最快。但是私有存储有限,例如笔者使用的显卡每个SIMD(以后的博客中会详细介绍)含有256个用于逻辑运算的寄存器。
以上是OpenCL中关于计算和存储的基本组织形式。
在硕士期间,由于实验室项目需求,本人在GPU上完成了一些医疗成像算法的加速。由于人工智能的爆发,笔者顺利找到了一份GPU优化的工作。如今即将毕业,笔者经过一年多的学习和应用,对于GPU编程有了基本的认识,因此在此编写几篇简单的入门引导博客,帮助更多的人尽快入门,少走弯路。如果总结中存在问题,也希望读者不吝赐教,共同探讨。
这个系列的博客主要介绍OpenCL编程的一些基础知识,通过矩阵相乘的例子,让读者了解OpenCL并行计算的基本编程方法,同时通过几种简单的优化方法比较,让读者了解GPU优化的基本思想,另外也会简单介绍涉及到的GPU架构相关的一些内容。由于旨在入门,本文只介绍简单的基础知识,不进行深入探讨。
在OpenCL的学习过程中笔者遇到过很多的困难,也有很多人给予了笔者很大的帮助。在此对他们表示感谢,感谢猫叔(猫头鹰的翅膀)、长江、Zenny Chen以及OpenCL技术开发群中诸多朋友给予笔者的帮助。
#二、GPU开发语言简介
在GPU开发中,当前的开发语言主要有OpenCL和CUDA。OpenCL和CUDA即是一种开发语言也是一种并行计算架构。CUDA是NIVIDA的并行计算架构,编程语言叫做CUDA C,也就是通常意义上说的CUDA,其语言是基于C语言语法的。CUDA仅用于NIVIDA的GPU设备开发。OpenCL是一种异构并行开发框架,是为异构计算设计的。它所支持的设备有CPU、GPU、FPGA甚至DSP等通用的或者专用的计算设备。因此OpenCL是面向CPU+其他计算设备这样的异构计算平台。同时OpenCL也是一种编程语言,也是基于C语言语法。
当前AMD和NIVIDA是PC端的两大GPU厂商,在移动端有ARM的MaLi,高通的Adreno,Imagination的PowerVR。从语言支持上看,所有的GPU都支持OpenCL,包括N卡和移动端GPU。但是很少有人在NIVIDIA GPU上使用OpenCL进行开发,因为CUDA有很好的生态,同时在N卡上CUDA会后很好的加速效果。CUDA仅支持N卡,不支持其他设备。
在移动端的GPU开发方面,苹果手机使用的是PowerVR的GPU(今年早些时候,苹果宣布停止对PowerVR的使用,讲自己研制GPU),但是它不支持OpenCL,它的开发使用的是苹果的移动端并行开发语言metal,相对于OpenCL,metal更简洁,吸取了OpenCL和CUDA的一些优点,做了一些改进。整体而言三种并行开发语言的思想想通,学会一个其他上手相对容易。
除此之外,还有OpenACC等一些并行API,笔者没有进行深入研究,不做评价。
#三、OpenCL基本知识
OpenCL作为一种异构并行的编程架构,它屏蔽了底层的硬件结构,将其抽象为工作空间、工作组、工作项、全局存储、局部存储以及私有存储等概念。本节主要介绍在GPU编程中,OpenCL关于这些抽象概念的组织结构,以及一些调度原则。关于GPU硬件架构方面的内容会在以后的博文中简单介绍。
首先介绍,工作空间、工作组以及工作项的组织关系。
OpenCL的工作空间可以是一维的、二维的、三维的。可以通过OpenCL提供的API进行设置。本文展示了二维的工作空间,每一个工作空间包含若干个工作组,每个工作组又包含若干个工作项。每一个工作组中的工作项有一段共享的内存——局部内存(local memory)。可以通过具体的API查看工作组局部内存的大小。笔者使用的是AMD W7100显卡,局部内存为32KB。每个工作组所包含的工作项的数量可以通过具体的API查到,笔者使用的显卡为256。也就是说,每一个工作组包含256个(至多256,可以小于256)工作项和32KB的局部存储器。32KB的局部内存对于工作组内的所有工作项是可见的,可用于组内数据的交换或者数据缓冲,对于其他工作组的工作项是不可见的。
完成计算的最小单位就是工作项,开发者通过操作每个工作项来完成整个计算任务。举一个简单的例子,假设需要完成两个二维矩阵的加法,矩阵维度为1024×1024。那么可以申请工作空间维度为1024×1024,每个工作项完成一组数据的加法,完成两个矩阵相加。因为每个工作项都有全局索引和局部索引,而矩阵的存储,不同的元素也有不同的索引,可以通过索引来设定每个工作项的计算任务。
接下来介绍存储器的组织形式。
可以看到,这个存储器分为三级,全局存储器、局部存储器和私有存储器。全局存储器对所有的工作项可见,但是访问速度最慢;局部存储器对工作组可见,访问速度较高,超过告诉Cache,因此合理的使用Local,可以有效提升程序性能。除了局部内存外,每个工作项可以申请私有存储,私有存储一般对应的是寄存器,因此访问的速度最快。但是私有存储有限,例如笔者使用的显卡每个SIMD(以后的博客中会详细介绍)含有256个用于逻辑运算的寄存器。
以上是OpenCL中关于计算和存储的基本组织形式。
欢迎关注公众号:计算机视觉与高性能计算(to_2know)