{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 destinyz 的文章《CTR点击率预估干货分享》','https://www.xiaopingtou.net/article-80507.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
class="markdown_views prism-atom-one-light">
1.排序指标。排序指标是最基本的指标,它决定了我们有没有能力把最合适的广告找出来去呈现给最合适的用户。这个是变现的基础,从技术上,我们用AUC来度量。 2.数值指标。数值指标是进一步的指标,是竞价环节进一步优化的基础,一般DSP比较看中这个指标。如果我们对CTR普遍低估,我们出价会相对保守,从而使得预算花不出去或是花得太慢;如果我们对CTR普遍高估,我们的出价会相对激进,从而导致CPC太高。从技术上,我们有Facebook的NE(Normalized Entropy)还可以用OE(Observation Over Expectation)。OE=∑i=Ni=1I(user_click_ad_i)∑i=Ni=1(pctr)

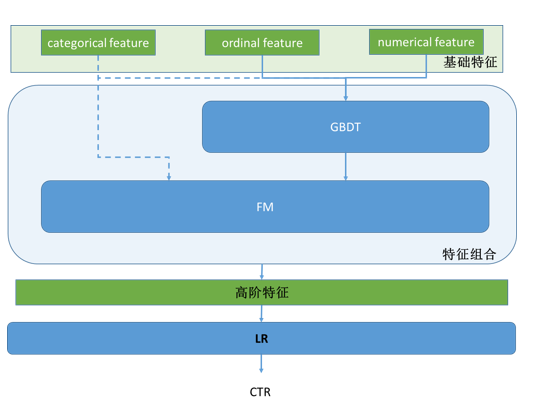
单纯点击率预估算法的框图如下:
1.指标
广告点击率预估是程序化广告交易框架的非常重要的组件,点击率预估主要有两个层次的指标:1.排序指标。排序指标是最基本的指标,它决定了我们有没有能力把最合适的广告找出来去呈现给最合适的用户。这个是变现的基础,从技术上,我们用AUC来度量。 2.数值指标。数值指标是进一步的指标,是竞价环节进一步优化的基础,一般DSP比较看中这个指标。如果我们对CTR普遍低估,我们出价会相对保守,从而使得预算花不出去或是花得太慢;如果我们对CTR普遍高估,我们的出价会相对激进,从而导致CPC太高。从技术上,我们有Facebook的NE(Normalized Entropy)还可以用OE(Observation Over Expectation)。
2.框架
工业界用得比较多的是基于LR的点击率预估策略,我觉得这其中一个重要的原因是可解释性,当出现bad case时越简单的模型越好debug,越可解释,也就越可以有针对性地对这种bad case做改善。但虽然如此,我见到的做广告的算法工程师,很少有利用LR的这种好处做模型改善的,遗憾….. 最近DNN很热,百度宣布DNN做CTR预估相比LR产生了20%的benefit,我不知道比较的benchmark,但就机理上来讲如果说DNN比原本传统的人工feature engineering的LR高20%,我一点也不奇怪。但如果跟现在增加了FM和GBDT的自动高阶特征生成的LR相比,我觉得DNN未必有什么优势。毕竟看透了,DNN用线性组合+非线性函数(tanh/sigmoid etc.)来做高阶特征生成,GBDT + FM用树和FM来做高阶特征生成,最后一层都是非线性变换。从场景上来讲,可能在拟生物的应用上(如视、听觉)上DNN这种高阶特征生成更好,在广告这种情境下,我更倾向于GBDT + FM的方法。 整个CTR预估模块的框架,包含了exploit/explore的逻辑。 单纯点击率预估算法的框图如下:
3.数据探索(data exploration)
主要是基础特征(raw feature/fundamental feature)的粗筛和规整。 展示广告的场景可以表述为”在某场景下,通过某媒体向某用户展示某广告”,因此基础特征就在这四个范围内寻找: 场景 – 当时场景,如何时何地,使用何种设备,使用什么浏览器等 广告 – 包括广告主特征,广告自身的特征如campaign、创意、类型,是否重定向等 媒体 – 包括媒体(网页、app等)的特征、广告位的特征等 用户 – 包括用户画像,用户浏览历史等 单特征选择的方法有下面几种: 1.简单统计方法,统计特征取值的覆盖面和平衡度,对dominant取值现象很显著的特征,要选择性地舍弃该特征或者是归并某些取值集到一个新的值,从而达到平衡的目的。 2.特征选择指标,特征选择主要有两个目的,一是去除冗余的特征,也就是特征之间可能是互相冗余的;二是去无用,有些特征对CTR预估这个任务贡献度很小或没有,对于这类特征选择,要小小地做,宁不足而不过分,因为单特征对任务贡献度小,很有可能后面再组合特征生成时与其他特征组合生成很有效的组合特征,所以做得不能太过。 a) 去冗余。主要是特征间的相关性,如Pearson相关性,或者指数回归(从泰勒定理的角度它可以模拟高阶的多项式特征)。 b) 去无用。主要是信息增益比。4.特征组合
两派方法: FM系列 – 对于categorical feature,一般把他们encode成one hot的形式,特征组合适合用FM。 Tree系列 – 对于numerical feature和ordinal feature, 特征组合可以使用决策树类的,一般用random forest或GBDT。其中GBDT的效果应该更好,因为boosting方法会不断增强对错判样本的区分能力。 对于广告点击率预估,同时拥有这三类特征。所以一个简单的方法就是级联地使用这两个方法,更好地进行特征组合。