{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 asdemon235b 的文章《FPGA基础知识(一)UG998相关硬件知识》','https://www.xiaopingtou.net/article-81248.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
本文是我在学习FPGA时学到的相关知识与总结,希望可以帮助同行理解和掌握相关的FPGA知识。可以将本文档当作相应FPGA教程文档UG998的辅助文档学习。转载请注明出处。
Xilinx原版教程文档参见XilinxDocumentation navigator 中对应UG998:Introduction to FPGA Design with Vivado High-Level Synthesis
 可以通过图看出,通过RTL设计语言的FPGA设计较为耗时,但是由于FPGA可以针对特定的应用而设计,因此比x86、GPU和DSP具有更好的性能。
可以通过图看出,通过RTL设计语言的FPGA设计较为耗时,但是由于FPGA可以针对特定的应用而设计,因此比x86、GPU和DSP具有更好的性能。
 针对RTL设计语言过于繁琐和耗时的问题,xilinx推出了一种Xilinx Vivado® High-Level Synthesis (HLS)的编译器,这种编译器可以对高层语言比如c/c++语言进行FPGA的编译,从而加快了FPGA的设计速度。
下面为各个章节内容的介绍。
Chapter 2 什么是FPGA
就FPGA与处理器(processor)进行对比,介绍了FPGA中的运算单元,内存结构,逻辑单元以及这些模块之间如何联系。
Chapter3 硬件设计的基本概念
就FPGA与处理器(processor)的硬件进行对比,介绍了基础的硬件相关知识。
Chapter4 VIvado高层综合(Vivado High-Level Synthesis)
介绍了vivado的高层次综合,如何将c/c++语言为FPGA编译。编译器如何提取出并行处理相应的关系、如何组织内存、如何将多个进程联系起来,从而用于FPGA。
Chapter 5以运算为中心的算法(Computation-Centric Algorithms)
以运算为中心的算法和以设计为中心的算法很大程度上取决于设计平台。本章给出以运算为中心的算法的定义,给出了一些设计实例和相应的设计建议。
Chapter6 以控制为中心的算法(Control-Centric Algorithms)
无论处理器(processor)和FPGA都可以进行以控制为中心的算法。本章给出以控制为中心的算法的实行方法以及一个实例用于UDP(user datagram protocol (UDP))处理,
Chapter7 软件验证和vivado HLS
本章介绍vivado HLS将相应的高层软件语言编译为FPGA的语言。给出了一些典型的编码错误的例子和解决方法。
Chapter8 多进程(mutiple)集成
FPGA可以实现多个进程和模块同时来实现一个相应的应用。本章介绍在FPGA中如何用一个处理器控制多个模块。着重介绍了Xilinx Zynq®-7000型号的FPGA的All Programmable (AP) System on a Chip (SoC)将FPGA fabric 与ARM®Cortex™-A9 处理器结合。并讲解了系统的设计,集成,以及优化中的权衡取舍。
Chapter9 实现一个完整的应用
FPGA中的一个完整的应用需要创建一个硬件系统,这个硬件系统有一个或多个模块,同时要能执行相应的代码。本章给出用FPGA实现应用的相应建议。
针对RTL设计语言过于繁琐和耗时的问题,xilinx推出了一种Xilinx Vivado® High-Level Synthesis (HLS)的编译器,这种编译器可以对高层语言比如c/c++语言进行FPGA的编译,从而加快了FPGA的设计速度。
下面为各个章节内容的介绍。
Chapter 2 什么是FPGA
就FPGA与处理器(processor)进行对比,介绍了FPGA中的运算单元,内存结构,逻辑单元以及这些模块之间如何联系。
Chapter3 硬件设计的基本概念
就FPGA与处理器(processor)的硬件进行对比,介绍了基础的硬件相关知识。
Chapter4 VIvado高层综合(Vivado High-Level Synthesis)
介绍了vivado的高层次综合,如何将c/c++语言为FPGA编译。编译器如何提取出并行处理相应的关系、如何组织内存、如何将多个进程联系起来,从而用于FPGA。
Chapter 5以运算为中心的算法(Computation-Centric Algorithms)
以运算为中心的算法和以设计为中心的算法很大程度上取决于设计平台。本章给出以运算为中心的算法的定义,给出了一些设计实例和相应的设计建议。
Chapter6 以控制为中心的算法(Control-Centric Algorithms)
无论处理器(processor)和FPGA都可以进行以控制为中心的算法。本章给出以控制为中心的算法的实行方法以及一个实例用于UDP(user datagram protocol (UDP))处理,
Chapter7 软件验证和vivado HLS
本章介绍vivado HLS将相应的高层软件语言编译为FPGA的语言。给出了一些典型的编码错误的例子和解决方法。
Chapter8 多进程(mutiple)集成
FPGA可以实现多个进程和模块同时来实现一个相应的应用。本章介绍在FPGA中如何用一个处理器控制多个模块。着重介绍了Xilinx Zynq®-7000型号的FPGA的All Programmable (AP) System on a Chip (SoC)将FPGA fabric 与ARM®Cortex™-A9 处理器结合。并讲解了系统的设计,集成,以及优化中的权衡取舍。
Chapter9 实现一个完整的应用
FPGA中的一个完整的应用需要创建一个硬件系统,这个硬件系统有一个或多个模块,同时要能执行相应的代码。本章给出用FPGA实现应用的相应建议。
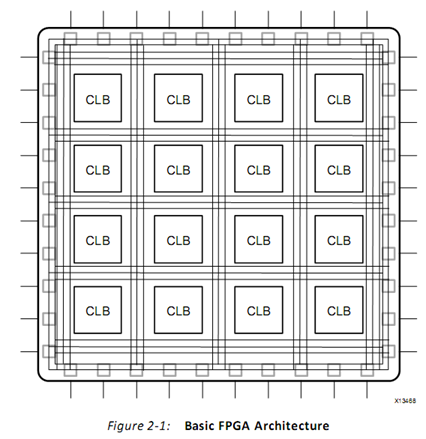 为实现更好的运算和存储能力,提升效率,FPGA还有下面这些模块:
为实现更好的运算和存储能力,提升效率,FPGA还有下面这些模块:
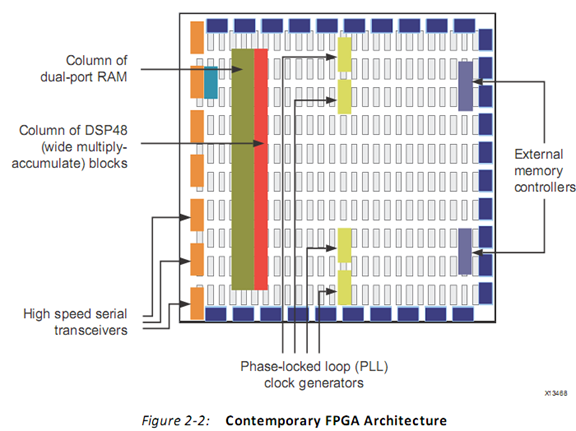


 或者
或者 

 ,图2-9是一种运算架构,方块表示flip-flop块生成的数据寄存器,每一个方块需要一个时钟周期,因此得到结果y需要三个时钟周期,
,图2-9是一种运算架构,方块表示flip-flop块生成的数据寄存器,每一个方块需要一个时钟周期,因此得到结果y需要三个时钟周期,
 图2-10表示一个pipeline架构,深灰 {MOD}的为原始数据,白 {MOD}为运算后的数据,浅灰 {MOD}为输出结果,每一个阶段都需要一系列对应的寄存器,每过一个周期就有一个新结果产生。
图2-10表示一个pipeline架构,深灰 {MOD}的为原始数据,白 {MOD}为运算后的数据,浅灰 {MOD}为输出结果,每一个阶段都需要一系列对应的寄存器,每过一个周期就有一个新结果产生。

 根据表3-1,处理器比FPGA具有更高的时钟频率,许多人会误以为处理器会比FPGA具有更好的处理性能,这是一个误解。因为这两个平台的工作原理是不一样的。处理器的处理需要图3-1的五个步骤。图3-2表示的处理器半并行的结构。
根据表3-1,处理器比FPGA具有更高的时钟频率,许多人会误以为处理器会比FPGA具有更好的处理性能,这是一个误解。因为这两个平台的工作原理是不一样的。处理器的处理需要图3-1的五个步骤。图3-2表示的处理器半并行的结构。

 FPGA并不需要软件在专门的运算平台上进行,而是软件在整个运算电路上运行,因此对应于处理器需要图3-2的处理结构,FPGA只需要像图3-4的并行运算。
FPGA并不需要软件在专门的运算平台上进行,而是软件在整个运算电路上运行,因此对应于处理器需要图3-2的处理结构,FPGA只需要像图3-4的并行运算。

 通常情况下,在进行一些运算密集的应用时,FPGA有比处理器快将近10倍的速度。
通常情况下,在进行一些运算密集的应用时,FPGA有比处理器快将近10倍的速度。
 对于时延和时钟频率等等的关系细节,还有一定的不理解的地方,若是有需要回来再研究,暂时可以粗略有一个概念。
对于时延和时钟频率等等的关系细节,还有一定的不理解的地方,若是有需要回来再研究,暂时可以粗略有一个概念。
 FPGA可能令软件工程师吃惊的地方在于FPGA没有动态的内存分配。FPGA并没有像软件那样用已有的cache,FPGA的HLS编译器会在FPGA中创建一个快速的memory architecture以最好的适应算法中的数据样式(data layout)。因此FPGA可以有相互独立的不同大小的内部存储空间,例如寄存器,移位寄存器,FIFOs和BRAMs。
寄存器:最快的内存结构,集成在在运算单元之中,获取不需要额外的时延。
移位寄存器:可以被当作一个数据序列,每一个数据可以在不同的运算之中被重复使用。将其中所有数据移动到相邻的存储设备中只需要一个时钟周期。
FIFO:只有一个输入和输出,通常被用于循环或循环函数,细节会被HLS编译器处理。
BRAM:集成在FPGA fabric模块中的RAM,每个xilinx的FPGA中集成有多个这样的BRAM。可以被当作有以下特性的cache: 1.不支持像处理器cache中那样的缓存一致性(cache coherency,collision),不支持处理器中的一些逻辑类型。2.只在设备有电时保持内存。3.不同的BRAM块可以同时传输数据。
FPGA可能令软件工程师吃惊的地方在于FPGA没有动态的内存分配。FPGA并没有像软件那样用已有的cache,FPGA的HLS编译器会在FPGA中创建一个快速的memory architecture以最好的适应算法中的数据样式(data layout)。因此FPGA可以有相互独立的不同大小的内部存储空间,例如寄存器,移位寄存器,FIFOs和BRAMs。
寄存器:最快的内存结构,集成在在运算单元之中,获取不需要额外的时延。
移位寄存器:可以被当作一个数据序列,每一个数据可以在不同的运算之中被重复使用。将其中所有数据移动到相邻的存储设备中只需要一个时钟周期。
FIFO:只有一个输入和输出,通常被用于循环或循环函数,细节会被HLS编译器处理。
BRAM:集成在FPGA fabric模块中的RAM,每个xilinx的FPGA中集成有多个这样的BRAM。可以被当作有以下特性的cache: 1.不支持像处理器cache中那样的缓存一致性(cache coherency,collision),不支持处理器中的一些逻辑类型。2.只在设备有电时保持内存。3.不同的BRAM块可以同时传输数据。
0.简介:
UG998文档主要介绍一些基础的关于FPGA和硬件设计相关的知识,例如什么是FPGA,硬件设计的基本概念,vivado软件的高层综合,以运算为中心的算法(Computation-Centric Algorithms),以控制为中心的算法(Control-CentricAlgorithms),软件验证和vivado HLS软件,多程序集成,应用的验证。用于初学者有一个初步的理念。 目录 0.简介: Chapter 1 1.1 Overview 1.2 Programming Model Chapter2 什么是FPGA 2.1 LUT 2.2 Flip-flop(FF) 2.3 DSP48 block 2.4 BRAM和其他存储设施 2.5 FPGA的并行架构与处理器的结构 2.5.1 Scheduling 2.5.2 Pipeline 2.5.3 数据流(dataflow) Chapter3 硬件设计的基本概念 3.1 时钟频率 3.2 时延(latency)与流水线(pipelining) 3.3 吞吐速度(Throughput) 3.4 内存架构与布局Chapter 1
1.1 Overview
软件设计是一切应用的基础,软件工程师在设计软件时需要用到编程技术与相应的硬件运算设施。为取得更好的并行处理(parallelization and concurrency),软件工程师面对着两种选择,ASIC或者FPGA。 ASIC——特定应用集成电路,目前,在集成电路界ASIC被认为是一种为专门目的而设计的集成电路。是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC(application-specific integrated circuit)的特点是面向特定用户的需求,ASIC在批量生产时与通用集成电路相比具有体积更小、功耗更低、可靠性提高、性能提高、保密性增强、成本降低等优点。 FPGA(Field-ProgrammableGate Array),即现场可编程门阵列,一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。 把一个算法设计成特定的硬件实现,主要花费来自于以下两个方面:- 电路制造成本
- 算法设计成相应的硬件所花费的设计成本
1.2 Programming Model
Programming model我理解为编程模型或编程模式。 有许多种的处理器(processors),例如,CPU,GPU(graphicsprocessing unit),DSP(digital signal processor),这些处理器可以执行高层次(High-levellanguage)的语言,比如c语言。处理器(processor)增加处理速度的方法是在处理器中增加多个处理核,软件工程师可以利用多个处理核对算法进行加速。 FPGA与processor不同就在于ProgrammingModel的不同,FPGA用的寄存器级的语言(register-transfer level (RTL) descriptions)这种较为底层的语言,而不是C/C++这种高层次语言。因此,寄存器级的语言来设计FPGA相对较为耗时。
可以通过图看出,通过RTL设计语言的FPGA设计较为耗时,但是由于FPGA可以针对特定的应用而设计,因此比x86、GPU和DSP具有更好的性能。
针对RTL设计语言过于繁琐和耗时的问题,xilinx推出了一种Xilinx Vivado® High-Level Synthesis (HLS)的编译器,这种编译器可以对高层语言比如c/c++语言进行FPGA的编译,从而加快了FPGA的设计速度。
下面为各个章节内容的介绍。
Chapter 2 什么是FPGA
就FPGA与处理器(processor)进行对比,介绍了FPGA中的运算单元,内存结构,逻辑单元以及这些模块之间如何联系。
Chapter3 硬件设计的基本概念
就FPGA与处理器(processor)的硬件进行对比,介绍了基础的硬件相关知识。
Chapter4 VIvado高层综合(Vivado High-Level Synthesis)
介绍了vivado的高层次综合,如何将c/c++语言为FPGA编译。编译器如何提取出并行处理相应的关系、如何组织内存、如何将多个进程联系起来,从而用于FPGA。
Chapter 5以运算为中心的算法(Computation-Centric Algorithms)
以运算为中心的算法和以设计为中心的算法很大程度上取决于设计平台。本章给出以运算为中心的算法的定义,给出了一些设计实例和相应的设计建议。
Chapter6 以控制为中心的算法(Control-Centric Algorithms)
无论处理器(processor)和FPGA都可以进行以控制为中心的算法。本章给出以控制为中心的算法的实行方法以及一个实例用于UDP(user datagram protocol (UDP))处理,
Chapter7 软件验证和vivado HLS
本章介绍vivado HLS将相应的高层软件语言编译为FPGA的语言。给出了一些典型的编码错误的例子和解决方法。
Chapter8 多进程(mutiple)集成
FPGA可以实现多个进程和模块同时来实现一个相应的应用。本章介绍在FPGA中如何用一个处理器控制多个模块。着重介绍了Xilinx Zynq®-7000型号的FPGA的All Programmable (AP) System on a Chip (SoC)将FPGA fabric 与ARM®Cortex™-A9 处理器结合。并讲解了系统的设计,集成,以及优化中的权衡取舍。
Chapter9 实现一个完整的应用
FPGA中的一个完整的应用需要创建一个硬件系统,这个硬件系统有一个或多个模块,同时要能执行相应的代码。本章给出用FPGA实现应用的相应建议。
Chapter2 什么是FPGA
FPGA是一种集成电路,并且经过烧写(fibrication)之后能执行特定的算法。 基本单元:- Look-up table(LUT);用于逻辑运算
- Flip-flop(FF):用于存储LUT产生结果的寄存器
- Wires:连接不同的单元
- Input/Output(I/O)pads:物理接口,用于输入和输出数据
为实现更好的运算和存储能力,提升效率,FPGA还有下面这些模块:
- l 集成内存和数据存储器
- l 锁相环(PLL,Phase-lockloops)用于提供不同的时钟驱动
- l 高速序列接受和发送装置
- l 片外内存控制器
- l 乘法累加块
2.1 LUT
图2-3.LUT可以看作一系列被乘法器链接的存储器,可以被当作一个运算单元或者存储单元。
2.2 Flip-flop(FF)
Flip-flop是FPGA中基础的存储单元,figure2-4通常会配对一个LUT来帮助逻辑运算和数据存储。基础的FF会有数据输入、时钟输入、时钟使能、复位、数据输出组成。通常会由输入会被延迟为下个时钟输出,
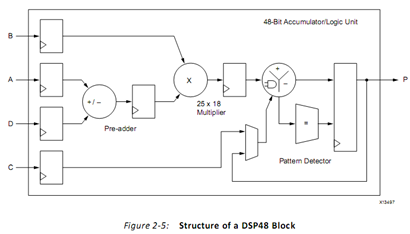
2.3 DSP48 block
最复杂的计算模块就是XilinxFPGA中的DSP48模块,它是一个数学逻辑运算单元(ALU:arithmetic logic unit)。每一个DSP48由一个加/减法单元被一个乘法器连接。结构如figure2-5,因此每一个DSP48单元可以进行下面的操作
或者
2.4 BRAM和其他存储设施
FPGA中包含着集成的内存单元,可以被当作RAM(random-access memory),ROM(read-only memory)或者移位寄存器来用。这些单元是blockRAMs(BRAMs),LUTs和移位寄存器。 BRAM是一个双端口的RAM,它集成在FPGA中用于存储相对大量的数据的,两种BRAM分别可以存储18k和36k的数据。对应于c/c++语言,BRAM可以当作RAM或者ROM来使用,如果被当作RAM来使能的话,数据可以在运行程序时被读和写,若被使能为ROM,则数据不能更改。 刚才提到的LUT也可以被当作小的存储设备使用,LUT相对比较灵活,在FPGA中也是最快的,因为它几乎存在于FPGA中的任何可烧写的部分。 移位寄存器是一系列首尾相连的寄存器,设计移位寄存器的目的就是在运算过程中可以重复使用一系列之前数据,就像延时滤波器一样。Figure2-6是移位寄存器的结构。
2.5 FPGA的并行架构与处理器的结构
当与处理器做对比时候,FPGA具有非常好的并行运算能力。下面通过一些简单的例子说明了FPGA对比于处理器的优点。 在处理器中,编译器需要对相应的程序进行编译,一个简单的加法运算需要将数据读入寄存器,然后寄存器相加,然后写出。如果数据存在cache中则读取过程耗费几个时钟周期,若存在DDR中则耗费上千个时钟周期完成读取,若数据存在硬盘中则耗费更大量的时间去完成。 FPGA的HLS编译器可以将所有的处理器的运行编译为能在FPGA上运行,并且不受cache和单独的存储空间的限制。例如FPGA的加法运算是在LUT中进行,并且FPGA的编译器会将存储设置的尽量离运算设备近,这样就会有很高的内存传输带宽。Xilinx Kintex®-7 410T设备一共有1,590个18k-bit的BRAMs.在传输带宽方面,寄存器级别的传输带宽可以达到0.5M-bits每秒,BRAM层面的传输带宽可以达到23T-bits每秒。2.5.1 Scheduling
Scheduling是确定数据和操作之间的相关性来确定哪个操作会被先执行。传统的FPGA设计中,这个是一个手动设置的过程,将软件算法设置为硬件实现。HLS编译器会分析不同操作之间的相互关系,并且设置相应的并行操作。2.5.2 Pipeline
Pipeline可以最大化的并行处理。例如下面这个运算时,HLS编译器需要一个乘法器和两个加法单元。 ,图2-9是一种运算架构,方块表示flip-flop块生成的数据寄存器,每一个方块需要一个时钟周期,因此得到结果y需要三个时钟周期,
图2-10表示一个pipeline架构,深灰 {MOD}的为原始数据,白 {MOD}为运算后的数据,浅灰 {MOD}为输出结果,每一个阶段都需要一系列对应的寄存器,每过一个周期就有一个新结果产生。
2.5.3 数据流(dataflow)
数据流也是一种设计技巧,与pipeline类似,数据流的目标是在函数级别实现最大化的并行运算。HLS编译器会根据函数的输入输出找出不同的函数之前的通信,然后最大化的并行相应的函数运算。当一个函数为另一个函数提供结果时,这种情况称为一个函数输出结果为另一个函数输入的情境(consumer-producer scenario)。 当出现一个函数输出结果为另一个函数输入时,HLS编译器会提供以下两种模型。一个模型是前体函数完全运算完毕把输出结果存在BRAM中,然后给后面的函数用,这是方法并行性不是很好。另一种模型是后面的函数根据前面函数运行的部分结果来进行运算,前体函数和后面的函数根据一个FIFO的内存电路连接,在一个函数过程中,两个函数同时运行。在HLS的术语中,后一个函数等待的时间称为II(interval or initiation interval)Chapter3 硬件设计的基本概念
FPGA与处理器的不同在于处理器的结构是固定的,编译器的工作就是最好的将软件编译为适应于处理器的结果。软件的性能取决于处理器的性能和处理器需要执行的步骤数量。作为对比,在FPGA中HLS编译器需要自己搭建一种处理架构将FPGA设置为最适宜运行软件的结构。HLS编译器创建最好的处理架构需要基础的硬件设计的知识。 本章介绍最基础的FPGA设计的相关知识以及这些概念之间是如何联系的。本章不介绍具体的FPGA设计的细节,HLS编译器来处理具体的实现细节。3.1 时钟频率
时钟频率是在实现具体算法时候第一个需要考虑的因素。一个普遍的认为是更高的时钟周期就具有更好的性能。
根据表3-1,处理器比FPGA具有更高的时钟频率,许多人会误以为处理器会比FPGA具有更好的处理性能,这是一个误解。因为这两个平台的工作原理是不一样的。处理器的处理需要图3-1的五个步骤。图3-2表示的处理器半并行的结构。
FPGA并不需要软件在专门的运算平台上进行,而是软件在整个运算电路上运行,因此对应于处理器需要图3-2的处理结构,FPGA只需要像图3-4的并行运算。
通常情况下,在进行一些运算密集的应用时,FPGA有比处理器快将近10倍的速度。
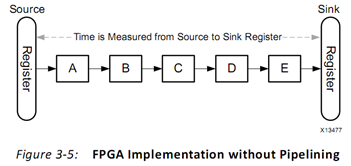
3.2 时延(latency)与流水线(pipelining)
时延是指通过一系列时钟周期之后产生需要的结果所需的时钟周期。例如图3-1中,假如处理器每个指令需要5时钟周期,则一共有5个指令,则时延为25。 在FPGA中,HLS编译器通过寄存器连接不同的运算模块。如图3-5,运行的时间为信号从源寄存器经过一系列运算模块到达目的寄存器的时间。图3-6展示了一个流水线结构。
对于时延和时钟频率等等的关系细节,还有一定的不理解的地方,若是有需要回来再研究,暂时可以粗略有一个概念。
3.3 吞吐速度(Throughput)
吞吐速度是指处理器处理一个样本到接收下一个输入数据样本所需的时钟周期。3.4 内存架构与布局
在处理器(processor)中,memory的速度取决于存储于memory中的数据到达处理器所耗费的时钟周期。软件工程师自己分配相应的数据存储到哪种种类的内存器件中,以使程序达到最好的性能。
FPGA可能令软件工程师吃惊的地方在于FPGA没有动态的内存分配。FPGA并没有像软件那样用已有的cache,FPGA的HLS编译器会在FPGA中创建一个快速的memory architecture以最好的适应算法中的数据样式(data layout)。因此FPGA可以有相互独立的不同大小的内部存储空间,例如寄存器,移位寄存器,FIFOs和BRAMs。
寄存器:最快的内存结构,集成在在运算单元之中,获取不需要额外的时延。
移位寄存器:可以被当作一个数据序列,每一个数据可以在不同的运算之中被重复使用。将其中所有数据移动到相邻的存储设备中只需要一个时钟周期。
FIFO:只有一个输入和输出,通常被用于循环或循环函数,细节会被HLS编译器处理。
BRAM:集成在FPGA fabric模块中的RAM,每个xilinx的FPGA中集成有多个这样的BRAM。可以被当作有以下特性的cache: 1.不支持像处理器cache中那样的缓存一致性(cache coherency,collision),不支持处理器中的一些逻辑类型。2.只在设备有电时保持内存。3.不同的BRAM块可以同时传输数据。