{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 random11 的文章《【神经网络与深度学习】卷积神经网络(CNN)》','https://www.xiaopingtou.net/article-81361.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
【神经网络与深度学习】卷积神经网络(CNN)
标签:【神经网络与深度学习】实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次。 说明:以后的总结,还应该以我的认识进行总结,这样比较符合我认知的习惯,而不是单纯的将别的地方的知识复制过来,这样并起不到好的总结效果。相反,如果能够将自己的体会写下来,当有所遗忘时还能顺着当时总结的认识思路,重新“辨识”起来,所以,要总结,而不要搬运知识。起初并不理解卷积神经的卷积与结构是什么,后来通过了一个比较好的例子才对卷积神经网络有了初步的认识,这里对这一阶段的认识进行总结。
首先,一提到卷积,首先想到的是在信号与系统、数字信号处理中所讲的,做一下翻转平移然后再做点积求和,因为这是第一次引入卷积。后来到了数字图像处理的课程中学习了卷积核,实现的是实际上是空域滤波,比如边缘检测技术中常用的sobel算子、梯度算子、laplace算子等。
然后是分析卷积神经网络的结构。可以通过下图所示的一个例子进行分析:

卷积神经网络是一个多层神经网络,图示中包括输入层、卷积层(C1)、子采样层(S2)、卷积层(C3)、子采样层(S4)、卷积层(C5)和输出层。
其工作流程是:输入层有
通过局部感知与参数共享,进一步的降低了自由参数的个数,从而降低了VC维,提高了泛化能力。
- 局部感知
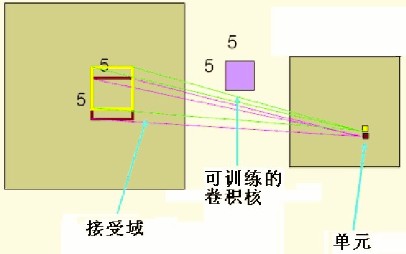
指的是接受域,如下图所示。一般认为人对外界的认知是从局部到全局的,而图像空间联系也是局部像素联系较为紧密,而距离较远的像素相关性较弱。因此,每个神经元没有必要对全局像素进行感知,只需要对局部像素进行感知,然后在更高层将局部信息进行综合得到全局信息。网络部分连通的思想,受启发于生物学的视觉系统结构,视觉皮层神经元就是局部接收信息的(即这些神经元只响应某些特定区域的刺激)。下图左边为全连接,右图为局部连接。假设隐含层的神经元个数与输入图像一样大,为1000×1000 ,那么全连接所需要的参数个数为1000000×1000000 ,实在太大了。而通过指定一个10×10 的接受域,每个hidden层的神经元只与10×10 的像素有连接,这样只需要1000000×100 个参数就可以,相比之下参数个数减少为原来的万分之一。

- 参数共享
指的是局部连接中每个神经元对应着100个像素,也就是100个参数,如果让每个hidden神经元对应的参数都相等,即所有的hidden神经元共享这100个参数,即共享卷积模板,这样参数个数就变为了100个。如下图所示,将卷积操作视为特征提取的方式(比如模板为sobel算子,就是对边缘特征的提取嘛),该方式与位置无关。即图像的一部分统计特性与其他部分是一样的,通过这个共享参数,实现对图像所有位置上的某一特定(与卷积模板有关)特征的提取。

- 多卷积核
只采用一种卷积核只能提取图像的一个局部特征,特征提取不充分,因此,可以添加多个卷积核,比如32个卷积核,学习32种特征,如下图所示的多卷积核:

不同的颜 {MOD}标识不同的卷积核,每个卷积核都将生成另一幅图像,可以看做是一张图象的不同同道。
上面三点内容说明了卷积层所进行的工作,通过8个不同的
下面有卷积层C1到子采样层S2实现的是子抽样和局部平均,将C1层得到的8个
通过卷积获得特征之后,如果直接训练分类器,计算量特别大,而且如此大维度的特征向量对分类器来讲,容易出现过拟合现象。比如对于一个
解决的方法就是降采样,通过某一个区域的特征平均值或最大值等这些概要统计特征来对不同位置上的特征进行聚合统计。具有将低维度和改善结果(不容易过拟合)的作用。这种聚合的操作叫做池化,也称为平均池化或最大池化等。如下图所示:

红 {MOD}区域内的平均值作为该区域的统计特性,实现降采样过程,也就是池化过程。
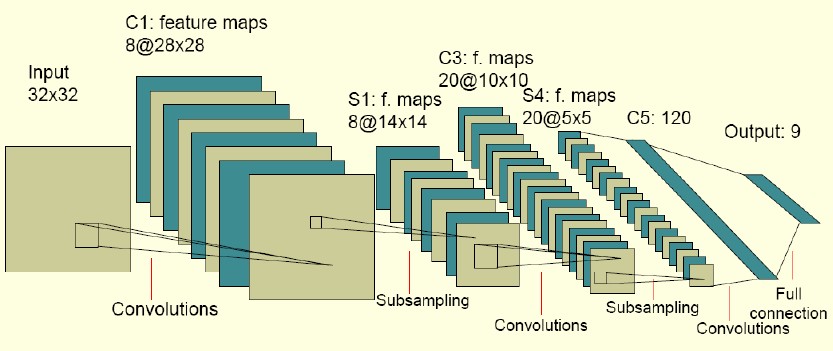
因此,再经过一次卷积层C3和子采样层S4,便得到了较小的特征描述20个
稍微细心一点就能发现,由S2层到C3层,从8个特征映射层到20个特征映射层,并不是整数倍的关系,这说明C3层的每个特征映射并不是将多少个卷积核分别作用在S2层的特征映射上,即需要注意C3中每一个特征map是连接到S2中的所有8个,或者几个特征map上的,表示本层的特征map是上一层提取到的特征map的不同组合,即所谓类似边缘构成形状或者目标的部分等特点。但为什么不让S2中的所有特征map全连结到C3层的特征图上呢?原因有2:一是不完全连接机制将连接的数量保持在合理的范围内;二是破坏网络的对称性,由于不同的特征图有不同的输入,迫使之抽取不同的特征(互补)。这里盗用一张图说明一下组合情况:
比如C3层有16个,S2层有6个,如何map的连接呢,可以参看下图的组合形式:

C3层的0号map由S2层的0-2号map映射而来,以此类推。以C3层的0号特征图获取过程为例,将0号卷积核分别在S2层的前三个map上进行卷积,并求和,之后加入偏移量,通过sigmoid函数进行激发,就可以得到C3层的0号特征图了。卷积之后紧跟着子抽样的思想是受到动物视觉系统的“简单的”细胞后面跟着“复杂的”细胞的想法的启发而产生的。具体意义在上面已经分析过。
最后要将的就是CNN的学习,上面讲的例子的CNN网络结构可以简化为如下:
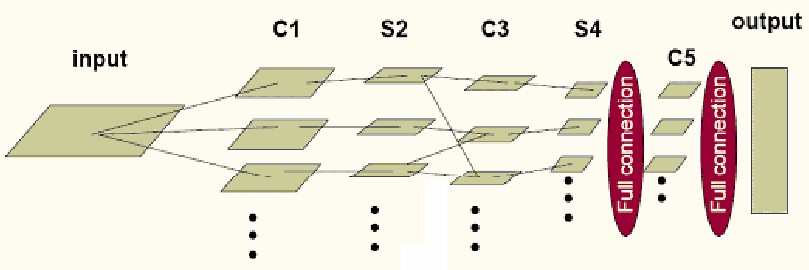
其中input层到C1,S4到C5,C5到output是全连结,C1到S2、C3到S4 是一一对应的连接,而S2到C3为了消除对称性,去掉了部分连接,可以让特征映射具有多样性。需要注意的是C5层卷积核的尺寸要与S4层输出相同,保证输出为1维向量。
卷积层的典型结构如下:
卷积层的前馈输出通过如下的公式进行计算:
ConvolutionLayer::fprop(input,output) {
//取得卷积核的个数
int n=kernel.GetDim(0);
for (int i=0;i
其中,input是 n1×n2×n3 的矩阵,n1是输入层特征映射的个数,n2是输入层特征映射的宽度,n3是输入层特征映射的高度。output, sum, convolution,bias是n1×(n2-kw+1)×(n3-kh+1)的矩阵,kw,kh是卷积核的宽度高度(图中是5×5)。kernel是卷积核矩阵。table是连接表,即如果第a输入和第b个输出之间有连接,table里就会有[a,b]这一项,而且每个连接都对应一个卷积核。
卷积层的反馈运算的核心代码如下:
ConvolutionLayer::bprop(input,output,in_dx,out_dx) {
//梯度通过DSigmoid反传
sum_dx = DSigmoid(out_dx);
//计算bias的梯度
for (i=0;i
其中in_dx,out_dx 的结构和 input,output 相同,代表的是相应点的梯度。
子采样层的学习
自采样层的典型结构如下:

output=sigmoid(采样×权重+偏移量)
其核心代码如下:
SubSamplingLayer::fprop(input,output) {
int n1= input.GetDim(0);
int n2= input.GetDim(1);
int n3= input.GetDim(2);
for (int i=0;i
子采样层的反馈运算的核心代码如下:
SubSamplingLayer::bprop(input,output,in_dx,out_dx) {
//梯度通过DSigmoid反传
sum_dx = DSigmoid(out_dx);
//计算bias和coeff的梯度
for (i=0;i
全连结层实际上就类似BP网络了,具体可以参考BP算法。
关于CNN的完整代码可以参考https://github.com/ibillxia/DeepLearnToolbox/tree/master/CNN中的Matlab代码
主要参考资料:
http://ibillxia.github.io/blog/2013/04/06/Convolutional-Neural-Networks/
http://blog.csdn.net/nan355655600/article/details/17690029
http://www.36dsj.com/archives/24006
2016-9-27 22:40
张朋艺 pyZhangBIT2010@126.com