{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 yunjie167 的文章《FPGA基础知识3(xilinx CLB资源详解--slice、分布式RAM和Block ram)》','https://www.xiaopingtou.net/article-81496.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
class="markdown_views prism-github-gist">
来源:http://www.eefocus.com/b3574027/blog/15-05/312609_2e5ad.html
以下分析基于xilinx 7系列 CLB是xilinx基本逻辑单元,每个CLB包含两个slices,每个slices由4个(A,B,C,D)6输入LUT和8个寄存器组成。每个Cyclone的基本逻辑单元ALM包含2个LE,每个LE包含1个LUT和1和寄存器, 同一CLB中的两片slices没有直接的线路连接,分属于两个不同的列。每列拥有独立的快速进位链资源。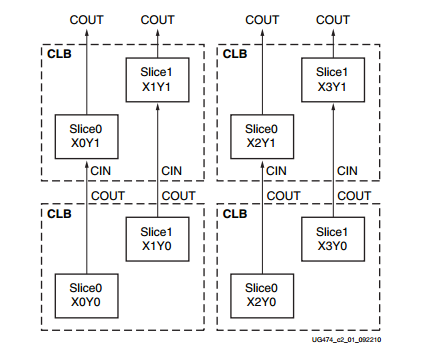 slice分为两种类型 SLICEL, SLICEM . SLICEL可用于产生逻辑,算术,ROM。 SLICEM除以上作用外还可配置成分布式RAM或32位的移位寄存器。每个CLB可包含两个SLICEL或者一个SLICEL与一个SLICEM.
7系列的LUT包含6个输入 A1 -A6 , 两个输出 O5 , O6 .
可配置成6输入查找表,O6此时作为输出。或者两个5输入的查找表,A1-A5作为输入 A6拉高,O5,O6作为输出。
一个LUT包含6个输入,逻辑容量为2^6bit,为实现7输入逻辑需要2^7容量,对于更多输入也一样。每个SLICES有4个LUT,256bit容量能够实现最多8bit输入的逻辑。为了实现此功能,每个SLICES还包括3个MUX(多路选择器)
F7AMUX 用于产生7输入的逻辑功能,用于连接A,B两个LUT
F7BMUX 用于产生7输入的逻辑功能, 用于连接C,D两个LUT
F8MUX 用于产生8输入的逻辑功能, 用于连接4个LUT
对于大于8输入的逻辑需要使用多个SLICES, 会增加逻辑实现的延时。
一个SLICES中的4个寄存器可以连接LUT或者MUX的输出,或者被直接旁路不连接任何逻辑资源。寄存器的置位/复位端为高电平有效。只有CLK端能被设置为两个极性,其他输入若要改变电平需要插入逻辑资源。例如低电平复位需要额外的逻辑资源将rst端输入取反。但设为上升/下降沿触发寄存器不会带来额外消耗。
分布式RAM
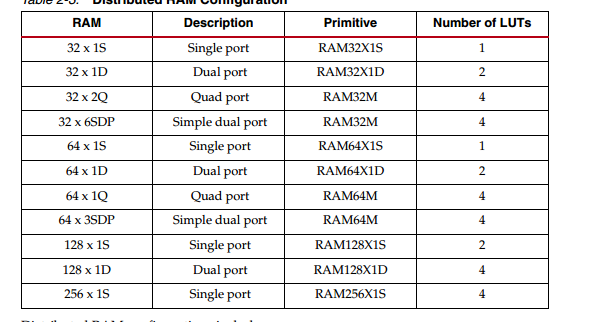
SLICEM可以配置成分布式RAM,一个SLICEM可以配置成以下容量的RAM
slice分为两种类型 SLICEL, SLICEM . SLICEL可用于产生逻辑,算术,ROM。 SLICEM除以上作用外还可配置成分布式RAM或32位的移位寄存器。每个CLB可包含两个SLICEL或者一个SLICEL与一个SLICEM.
7系列的LUT包含6个输入 A1 -A6 , 两个输出 O5 , O6 .
可配置成6输入查找表,O6此时作为输出。或者两个5输入的查找表,A1-A5作为输入 A6拉高,O5,O6作为输出。
一个LUT包含6个输入,逻辑容量为2^6bit,为实现7输入逻辑需要2^7容量,对于更多输入也一样。每个SLICES有4个LUT,256bit容量能够实现最多8bit输入的逻辑。为了实现此功能,每个SLICES还包括3个MUX(多路选择器)
F7AMUX 用于产生7输入的逻辑功能,用于连接A,B两个LUT
F7BMUX 用于产生7输入的逻辑功能, 用于连接C,D两个LUT
F8MUX 用于产生8输入的逻辑功能, 用于连接4个LUT
对于大于8输入的逻辑需要使用多个SLICES, 会增加逻辑实现的延时。
一个SLICES中的4个寄存器可以连接LUT或者MUX的输出,或者被直接旁路不连接任何逻辑资源。寄存器的置位/复位端为高电平有效。只有CLK端能被设置为两个极性,其他输入若要改变电平需要插入逻辑资源。例如低电平复位需要额外的逻辑资源将rst端输入取反。但设为上升/下降沿触发寄存器不会带来额外消耗。
分布式RAM
SLICEM可以配置成分布式RAM,一个SLICEM可以配置成以下容量的RAM
 多bit的情况需要增加相应倍数的LUT进行并联。
分布式RAM和 BLOCK RAM的选择遵循以下方法:
1. 小于或等于64bit容量的的都用分布式实现
2. 深度在64~128之间的,若无额外的block可用分布式RAM。 要求异步读取就使用分布式RAM。数据宽度大于16时用block ram.
3. 分布式RAM有比block ram更好的时序性能。 分布式RAM在逻辑资源CLB中。而BLOCK RAM则在专门的存储器列中,会产 生较大的布线延迟,布局也受制约。
移位寄存器(SLICEM)
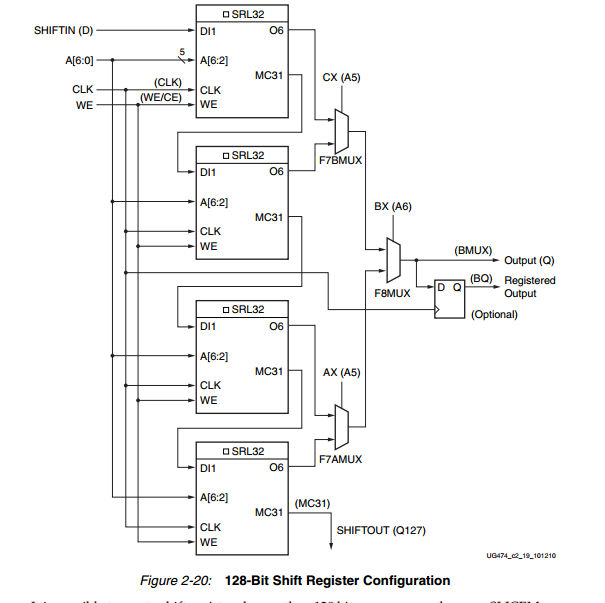
SLICEM中的LUT能在不使用触发器的情况下设置成32bit的移位寄存器, 4个LUT可级联成128bit的移位寄存器。并且能够进行SLICEM间的级联形成更大规模的移位寄存器。
多bit的情况需要增加相应倍数的LUT进行并联。
分布式RAM和 BLOCK RAM的选择遵循以下方法:
1. 小于或等于64bit容量的的都用分布式实现
2. 深度在64~128之间的,若无额外的block可用分布式RAM。 要求异步读取就使用分布式RAM。数据宽度大于16时用block ram.
3. 分布式RAM有比block ram更好的时序性能。 分布式RAM在逻辑资源CLB中。而BLOCK RAM则在专门的存储器列中,会产 生较大的布线延迟,布局也受制约。
移位寄存器(SLICEM)
SLICEM中的LUT能在不使用触发器的情况下设置成32bit的移位寄存器, 4个LUT可级联成128bit的移位寄存器。并且能够进行SLICEM间的级联形成更大规模的移位寄存器。
 MUX
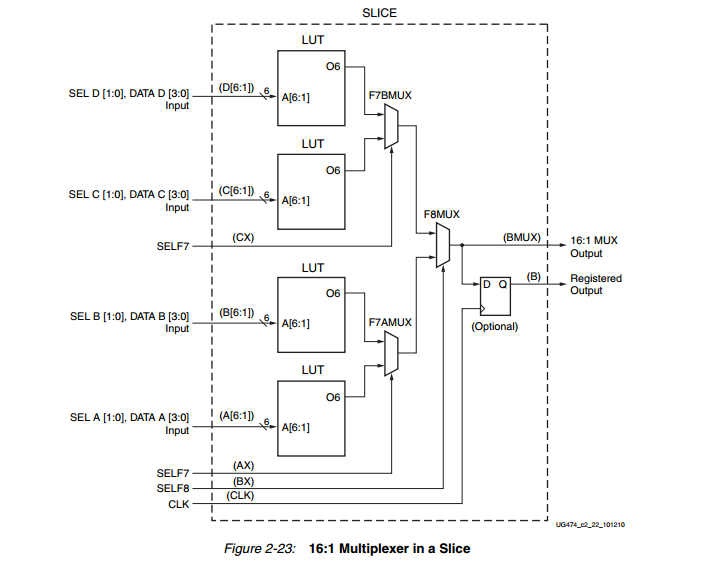
一个LUT可配置成4:1MUX.
两个LUT可配置成最多8:1 MUX
四个LUT可配置成16个MUX
MUX
一个LUT可配置成4:1MUX.
两个LUT可配置成最多8:1 MUX
四个LUT可配置成16个MUX
 同样可以通过连接多个SLICES达成更大规模设计,但是由于SLICE没有直接连线,需要使用布线资源,会增加较大延迟。
进位链
每个SLICE有4bit的进位链。每bit都由一个进位MUX(MUXCY)和一个异或门组成,可在实现加法/减法器时生成进位逻辑。该MUXCY与XOR也可用于产生一般逻辑。
同样可以通过连接多个SLICES达成更大规模设计,但是由于SLICE没有直接连线,需要使用布线资源,会增加较大延迟。
进位链
每个SLICE有4bit的进位链。每bit都由一个进位MUX(MUXCY)和一个异或门组成,可在实现加法/减法器时生成进位逻辑。该MUXCY与XOR也可用于产生一般逻辑。
以下分析基于xilinx 7系列 CLB是xilinx基本逻辑单元,每个CLB包含两个slices,每个slices由4个(A,B,C,D)6输入LUT和8个寄存器组成。每个Cyclone的基本逻辑单元ALM包含2个LE,每个LE包含1个LUT和1和寄存器, 同一CLB中的两片slices没有直接的线路连接,分属于两个不同的列。每列拥有独立的快速进位链资源。
slice分为两种类型 SLICEL, SLICEM . SLICEL可用于产生逻辑,算术,ROM。 SLICEM除以上作用外还可配置成分布式RAM或32位的移位寄存器。每个CLB可包含两个SLICEL或者一个SLICEL与一个SLICEM.
7系列的LUT包含6个输入 A1 -A6 , 两个输出 O5 , O6 .
可配置成6输入查找表,O6此时作为输出。或者两个5输入的查找表,A1-A5作为输入 A6拉高,O5,O6作为输出。
一个LUT包含6个输入,逻辑容量为2^6bit,为实现7输入逻辑需要2^7容量,对于更多输入也一样。每个SLICES有4个LUT,256bit容量能够实现最多8bit输入的逻辑。为了实现此功能,每个SLICES还包括3个MUX(多路选择器)
F7AMUX 用于产生7输入的逻辑功能,用于连接A,B两个LUT
F7BMUX 用于产生7输入的逻辑功能, 用于连接C,D两个LUT
F8MUX 用于产生8输入的逻辑功能, 用于连接4个LUT
对于大于8输入的逻辑需要使用多个SLICES, 会增加逻辑实现的延时。
一个SLICES中的4个寄存器可以连接LUT或者MUX的输出,或者被直接旁路不连接任何逻辑资源。寄存器的置位/复位端为高电平有效。只有CLK端能被设置为两个极性,其他输入若要改变电平需要插入逻辑资源。例如低电平复位需要额外的逻辑资源将rst端输入取反。但设为上升/下降沿触发寄存器不会带来额外消耗。
分布式RAM
SLICEM可以配置成分布式RAM,一个SLICEM可以配置成以下容量的RAM
多bit的情况需要增加相应倍数的LUT进行并联。
分布式RAM和 BLOCK RAM的选择遵循以下方法:
1. 小于或等于64bit容量的的都用分布式实现
2. 深度在64~128之间的,若无额外的block可用分布式RAM。 要求异步读取就使用分布式RAM。数据宽度大于16时用block ram.
3. 分布式RAM有比block ram更好的时序性能。 分布式RAM在逻辑资源CLB中。而BLOCK RAM则在专门的存储器列中,会产 生较大的布线延迟,布局也受制约。
移位寄存器(SLICEM)
SLICEM中的LUT能在不使用触发器的情况下设置成32bit的移位寄存器, 4个LUT可级联成128bit的移位寄存器。并且能够进行SLICEM间的级联形成更大规模的移位寄存器。
MUX
一个LUT可配置成4:1MUX.
两个LUT可配置成最多8:1 MUX
四个LUT可配置成16个MUX
同样可以通过连接多个SLICES达成更大规模设计,但是由于SLICE没有直接连线,需要使用布线资源,会增加较大延迟。
进位链
每个SLICE有4bit的进位链。每bit都由一个进位MUX(MUXCY)和一个异或门组成,可在实现加法/减法器时生成进位逻辑。该MUXCY与XOR也可用于产生一般逻辑。