{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 不喝可乐的 的文章《OpenCL学习笔记(二):并行编程概念理解》','https://www.xiaopingtou.net/article-81635.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
data/attach/1907/qpktd6e4nbj0h1yvnpwnq82crt8i3lvd.jpgdata/attach/1907/w5t7cev89u5q404j5f9h5pmqo25d71g4.jpgdata/attach/1907/przr0i7x0cvroijl62ljj650o8543hph.jpgdata/attach/1907/tt6815tmaxp2ff09whgucahbjwyu7d42.jpgdata/attach/1907/rrek78iszebgi4zekhwmaqbmwdx17xhb.jpgdata/attach/1907/an255j92cd52dkuhgnrgitbs3qds4b2u.jpg
一般来说,并行编程有两种大类型——分散收集(scatter-gather)与分而治之(divide-and-conquer)。
看一个最简单数据并行实例:![]()
![]()


理想情况是,所有的乘法都可以并行执行,而不是串行执行。 任务并行的示意图:![]()

比如多CPU系统,每个CPU执行不同的线程。还有一类流水线并行,也属于任务并行:![]()

流水线的每一个任务会处理不同的数据,这里不是串行的!而是流水线并行的,数据从一个任务传送到另外一个任务中,同时前一个任务又处理新的数据。
(1)shared memory
当任务要访问同一个数据时,最简单的方法就是共享存储shared memory(很多不同层面与功能的系统都有用到这个方法),大部分多核系统都支持这一模型。shared memory可以用于任务间通信,可以用flag或者互斥锁等方法进行数据保护,它的优缺点:![]()

(2)message passing 数据同步的另外一种模型是消息传递模型,可以在同一器件中,或者多个数量的器件中进行并发任务通信,且只在需要同步时才启动。![]()

OpenCL并行执行内核 opencl可以有很多工作条目work-item,每一个item都有一个id,类似于线程的概念;看下面的例子:
左边是一般的编程写法,对数组元素递增;右边是opencl的写法,建立N个独立的work item,并行执行。这是最典型的opencl编程模型,用于数据并行任务,那么在真实的硬件中,又是如何完成并行任务的呢?实际上,这一块并不由opencl管,因为opencl只是一个编程标准,它提供了统一的编程接口和模型,而真正实现这些并行功能的是硬件支持厂商。比如intel对于CPU,NVIDIA对于GPU,Altera对于FPGA。正是因为有了opencl,才使得跨平台和跨硬件体系结构编程的可移植性成为可能。
由于性能是opencl编程的核心,而不是易用性,因此编程人员需要找到算法本身的并行部分,用kernel的方式来实现它们。工作条目就是一个最小的执行单元,工作条目可以组成工作组(work group)。这样的划分也与存储器有关,在opencl中,存储分为三大类:Global memory,Local memory,以及Private memory。Global是可以让所有的工作组和工作条目都可见,Local是只有当前工作组中的工作条目可见,而Private是只有单独一个工作条目可见。这样的存储访问控制,可以有效利用高速缓存提高效率,而不是每一次数据访问都需要外部DDR。
来简单看看GPU和FPGA的实现架构,GPU的体系结构是高度并行的,高级的GPU有非常多的运算单元,有很高的存储器总线,较高的吞吐量,但是存储访问的延迟也比较大。因此针对GPU的程序设计,存储器的管理和访问是很关键的。GPU一般有小容量高速缓存,并使用PCIe与主机进行通信(当然,现在也有一些新的技术不用PCIe)。见下图:

而FPGA是针对定制硬件进行设计,并行度非常高,现代FPGA通常有上百万个逻辑单元,每一个单元可以实现一个逻辑功能;有数千个片内存储器模块,用于快速访问数据;有数千个专用DSP模块,用于加速计算数学函数(比如浮点乘法)。如下图: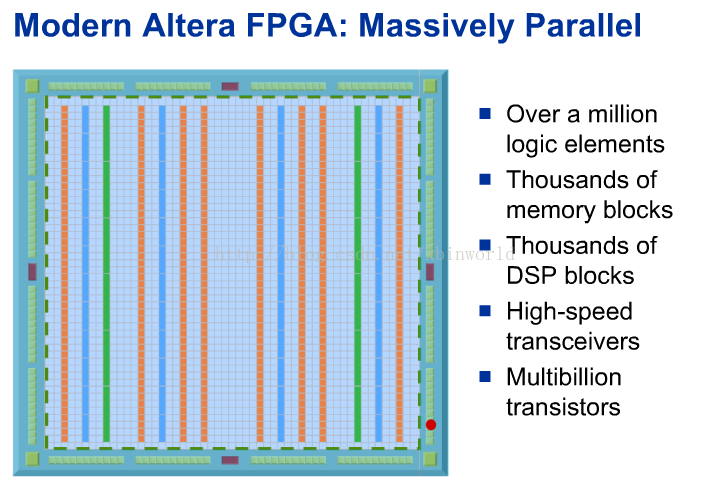
当面向FPGA编译opencl时,执行不受固定数据通路和寄存器限制,实际上是根据运算把逻辑组织到函数单元中,然后将其连接起来形成专用的数据通路,实现特殊的内核功能,如下图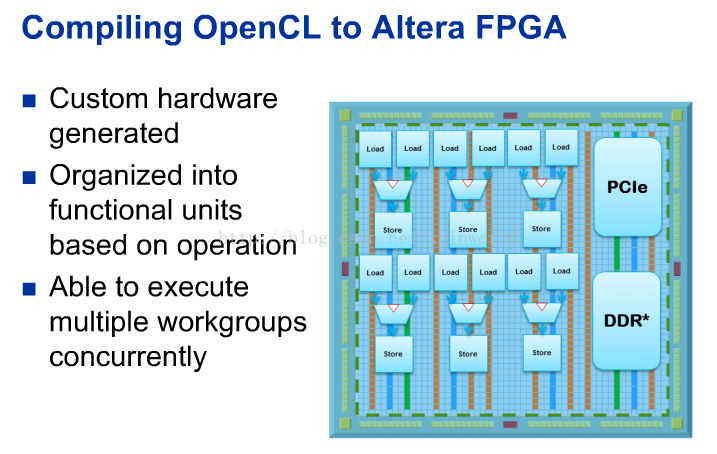
针对FPGA的opencl编程,大致有两种形式,一种是辅助加速器,软件在CPU中实现,使用FPGA来加速某些模块的运算,CPU和FPGA采用PCIe连接;另一种是SOC的方式,CPU是内嵌在FPGA版上的,这样的方式可以减小通信延迟: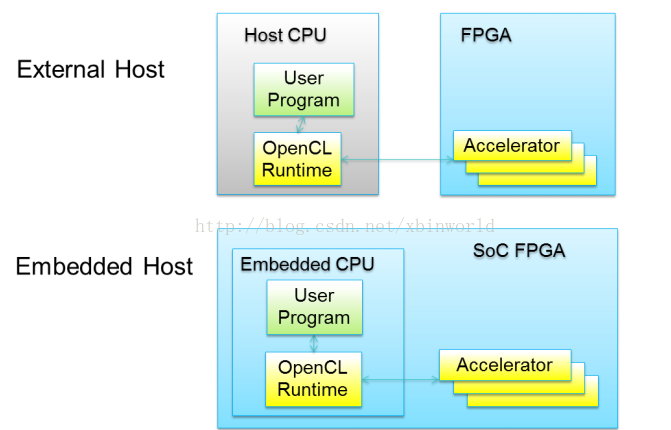
到这里,对于opencl的并行编程大概有个了解了。我们先看一下opencl编程以及运行在FPGA和CPU上的大致流程,具体的过程会在后面的章节中描述,这里看个大概: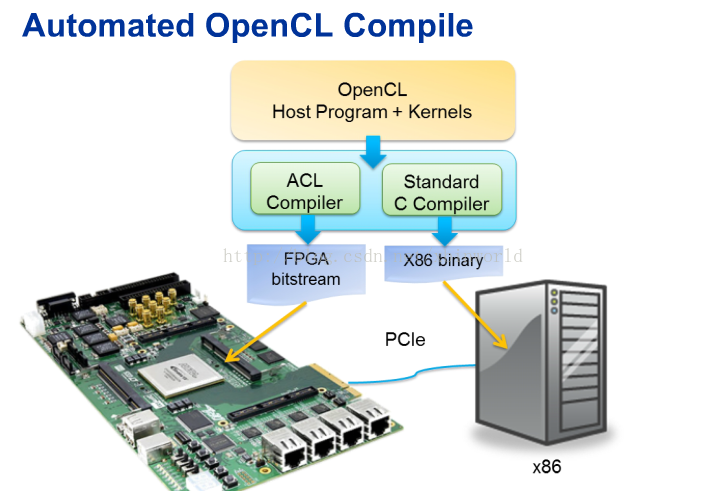
需要有两种编译器,一个是标准的C编译器,一个是opencl的编译器(因为我参考的资料是altera的,所以是altera的opencl编译器)。opencl编译器会生成比特流文件,下载到FPGA板上,然后host程序运行调用,通过PCIe连接在FPGA上启动内核执行。编译器会将整个电路构建完成,包括了算法逻辑,存储器结构,存储器访问控制与通路,内核主机间的通路等。如下图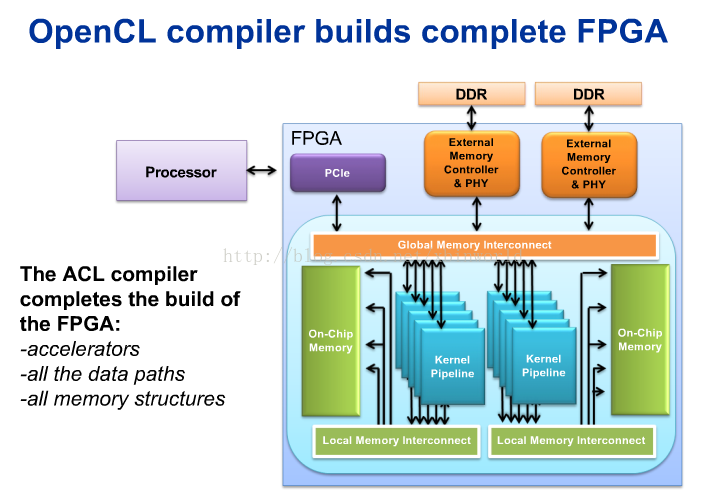
最后比较一下各种硬件形态的开发效率与执行效率,而opencl在FPGA上作用就是绿 {MOD}箭头的方向。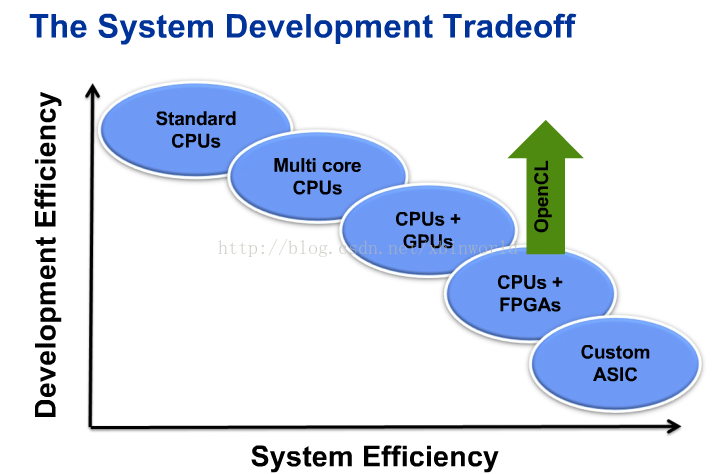
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
并行编程的需求是显而易见的,其最大的难题是找到算法的并行功能,同时必须处理数据的共享和同步。但是,因为每一个算法都是不一样的,很难有通用的并行功能——粒度都有可能是不一样的。OpenCL提供了很多并行的抽象模型,因此算法开发人员可以在不同粒度上开发并行的算法,以及数据的共享和同步。
一般来说,并行编程有两种大类型——分散收集(scatter-gather)与分而治之(divide-and-conquer)。
- 分散收集(scatter-gather):数据被分为子集,发送到不同的并行资源中,然后对结果进行组合,也就是数据并行;
- 分而治之(divide-and-conquer):问题被分为子问题,在并行资源中运行,也就是任务并行。
看一个最简单数据并行实例:
理想情况是,所有的乘法都可以并行执行,而不是串行执行。 任务并行的示意图:
比如多CPU系统,每个CPU执行不同的线程。还有一类流水线并行,也属于任务并行:
流水线的每一个任务会处理不同的数据,这里不是串行的!而是流水线并行的,数据从一个任务传送到另外一个任务中,同时前一个任务又处理新的数据。
数据共享与同步
这个大概是并行编程最难的部分,一般来说,下面两种情况需要有数据的同步:(1)一个子任务的输入依赖于另一个子任务的输出;(2)中间结果需要汇总合并。在OpenCL中,提供了两种数据同步机制(mechanism):- 锁(Locks):在一个资源被访问的时候,禁止其他访问;
- 栅栏(Barriers):在一个运行点中进行等待,直到所有运行任务都完成;(典型的BSP编程模型就是这样)
(1)shared memory
当任务要访问同一个数据时,最简单的方法就是共享存储shared memory(很多不同层面与功能的系统都有用到这个方法),大部分多核系统都支持这一模型。shared memory可以用于任务间通信,可以用flag或者互斥锁等方法进行数据保护,它的优缺点:
- 优点:易于实现,编程人员不用管理数据搬移;
- 缺点:多个任务访问同一个存储器,控制起来就会比较复杂,降低了互联速度,扩展性也比较不好。
(2)message passing 数据同步的另外一种模型是消息传递模型,可以在同一器件中,或者多个数量的器件中进行并发任务通信,且只在需要同步时才启动。
- 优点:理论上可以在任意多的设备中运行,扩展性好;
- 缺点:程序员需要显示地控制通信,开发有一定的难度;发送和接受数据依赖于库方法,因此可移植性差。
OpenCL并行执行内核 opencl可以有很多工作条目work-item,每一个item都有一个id,类似于线程的概念;看下面的例子:
左边是一般的编程写法,对数组元素递增;右边是opencl的写法,建立N个独立的work item,并行执行。这是最典型的opencl编程模型,用于数据并行任务,那么在真实的硬件中,又是如何完成并行任务的呢?实际上,这一块并不由opencl管,因为opencl只是一个编程标准,它提供了统一的编程接口和模型,而真正实现这些并行功能的是硬件支持厂商。比如intel对于CPU,NVIDIA对于GPU,Altera对于FPGA。正是因为有了opencl,才使得跨平台和跨硬件体系结构编程的可移植性成为可能。
由于性能是opencl编程的核心,而不是易用性,因此编程人员需要找到算法本身的并行部分,用kernel的方式来实现它们。工作条目就是一个最小的执行单元,工作条目可以组成工作组(work group)。这样的划分也与存储器有关,在opencl中,存储分为三大类:Global memory,Local memory,以及Private memory。Global是可以让所有的工作组和工作条目都可见,Local是只有当前工作组中的工作条目可见,而Private是只有单独一个工作条目可见。这样的存储访问控制,可以有效利用高速缓存提高效率,而不是每一次数据访问都需要外部DDR。
来简单看看GPU和FPGA的实现架构,GPU的体系结构是高度并行的,高级的GPU有非常多的运算单元,有很高的存储器总线,较高的吞吐量,但是存储访问的延迟也比较大。因此针对GPU的程序设计,存储器的管理和访问是很关键的。GPU一般有小容量高速缓存,并使用PCIe与主机进行通信(当然,现在也有一些新的技术不用PCIe)。见下图:
而FPGA是针对定制硬件进行设计,并行度非常高,现代FPGA通常有上百万个逻辑单元,每一个单元可以实现一个逻辑功能;有数千个片内存储器模块,用于快速访问数据;有数千个专用DSP模块,用于加速计算数学函数(比如浮点乘法)。如下图:
当面向FPGA编译opencl时,执行不受固定数据通路和寄存器限制,实际上是根据运算把逻辑组织到函数单元中,然后将其连接起来形成专用的数据通路,实现特殊的内核功能,如下图
针对FPGA的opencl编程,大致有两种形式,一种是辅助加速器,软件在CPU中实现,使用FPGA来加速某些模块的运算,CPU和FPGA采用PCIe连接;另一种是SOC的方式,CPU是内嵌在FPGA版上的,这样的方式可以减小通信延迟:
到这里,对于opencl的并行编程大概有个了解了。我们先看一下opencl编程以及运行在FPGA和CPU上的大致流程,具体的过程会在后面的章节中描述,这里看个大概:
需要有两种编译器,一个是标准的C编译器,一个是opencl的编译器(因为我参考的资料是altera的,所以是altera的opencl编译器)。opencl编译器会生成比特流文件,下载到FPGA板上,然后host程序运行调用,通过PCIe连接在FPGA上启动内核执行。编译器会将整个电路构建完成,包括了算法逻辑,存储器结构,存储器访问控制与通路,内核主机间的通路等。如下图
最后比较一下各种硬件形态的开发效率与执行效率,而opencl在FPGA上作用就是绿 {MOD}箭头的方向。