{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 u010457081 的文章《C6000的C语言优化》','https://www.xiaopingtou.net/article-82056.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
l TMS320C6000处理器介绍
TMS320C6000是TMS320系列产品中的新一代高性能DSP芯片,共分为两大系列。其中定点系列为TMS320C62xx和TMS320C64xx;浮点系列为TMS320C67xx。由于TMS320C6000的开发主要面向数据密集型算法,它有着丰富的内部资源和强大的运算能力,所以被广泛地应用于数字通信和图像处理等领域。
C6000系列CPU中的8个功能单元可以并行操作,并且其中两个功能单元为硬件乘法运算单元,大大地提高了乘法速度。DSP采用具有独立程序总线和数据总线的哈佛总线结构,仅片内程序总线宽度就可达到256位,即每周期可并行执行8条32位指令;片内两套数据总线的宽度分别为32位;此外,DSP还有一套32位DMA专用总线用于传输。灵活的总线结构使得数据瓶颈对系统性能的限制大大缓解。C6000的通用寄存器组能支持32位和40位定点数据操作,另外C67xx和C64xx还分别支持64位双精度数据和64位双字定点数据操作。除了多功能单元外,流水技术是提高DSP程序执行效率的另一主要手段。由于TMS320C6000的特殊结构,功能单元同时执行的各种操作可由VLlW长指令分配模块来同步执行,使8条并行指令同时通过流水线的每个节拍,极大地提高了机器的吞吐量。
2 C6000软件开发流程
图1为C6000的软件开发流程图。图中阴影部分是开发C代码的常规流程,其他部分用于辅助和加速开发讨程.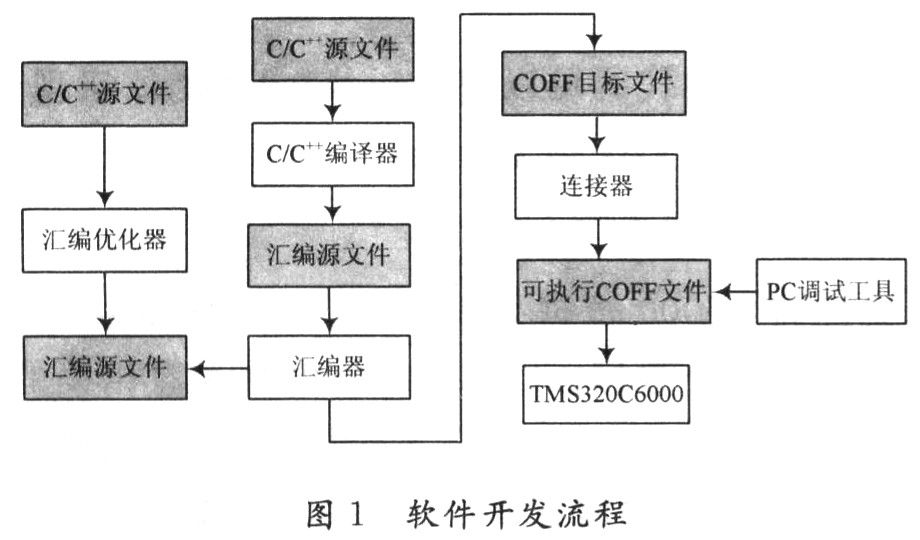 C/C++源文件首先经过C/C++编译器(C/C++cornpiler)转换为C6000汇编源代码。编译器、优化器(optimizer)和交叠工具是C/C++编译器的组成部分。编译器使用户能一步完成编译、汇编和连接;优化器调整合修改代码以提高C程序的效率;交叠工具把C/C++语句和对应的汇编语句交叠列出。
汇编源代码再经过汇编器(Assembier)翻译为机器语言目标文件。机器语言是基于通用目标文件格式(Common Object File Format,COFF)的。
C/C++源文件首先经过C/C++编译器(C/C++cornpiler)转换为C6000汇编源代码。编译器、优化器(optimizer)和交叠工具是C/C++编译器的组成部分。编译器使用户能一步完成编译、汇编和连接;优化器调整合修改代码以提高C程序的效率;交叠工具把C/C++语句和对应的汇编语句交叠列出。
汇编源代码再经过汇编器(Assembier)翻译为机器语言目标文件。机器语言是基于通用目标文件格式(Common Object File Format,COFF)的。
连接器(Linker)连接目标文件,生成一个可执行文件。它要完成地址的重分配(Relocation)和解析外部引用(Resolve External References)。
得到可执行文件之后就可以进行调试。可用软件仿真器(Simulator)在PC机上对指令和运行时间进行精确仿真;用XDS硬件仿真器(Emulator)在目标板上进行调试。
调试通过后即可下载到目标板进行独立运行。
3 程序优化流程及方法
3.1 程序优化阶段
由于DSP应用的复杂度,在用C语言进行DSP软件开发时,一般先在基于通用微处理器的PC机或工作站上对算法进行仿真,仿真通过后再将C程序移植到DSP平台中。
所以,DSP的软件开发与优化流程主要分为3个阶段:C代码开发阶段;C代码优化阶段;手工汇编代码重编写阶段。如图2所示。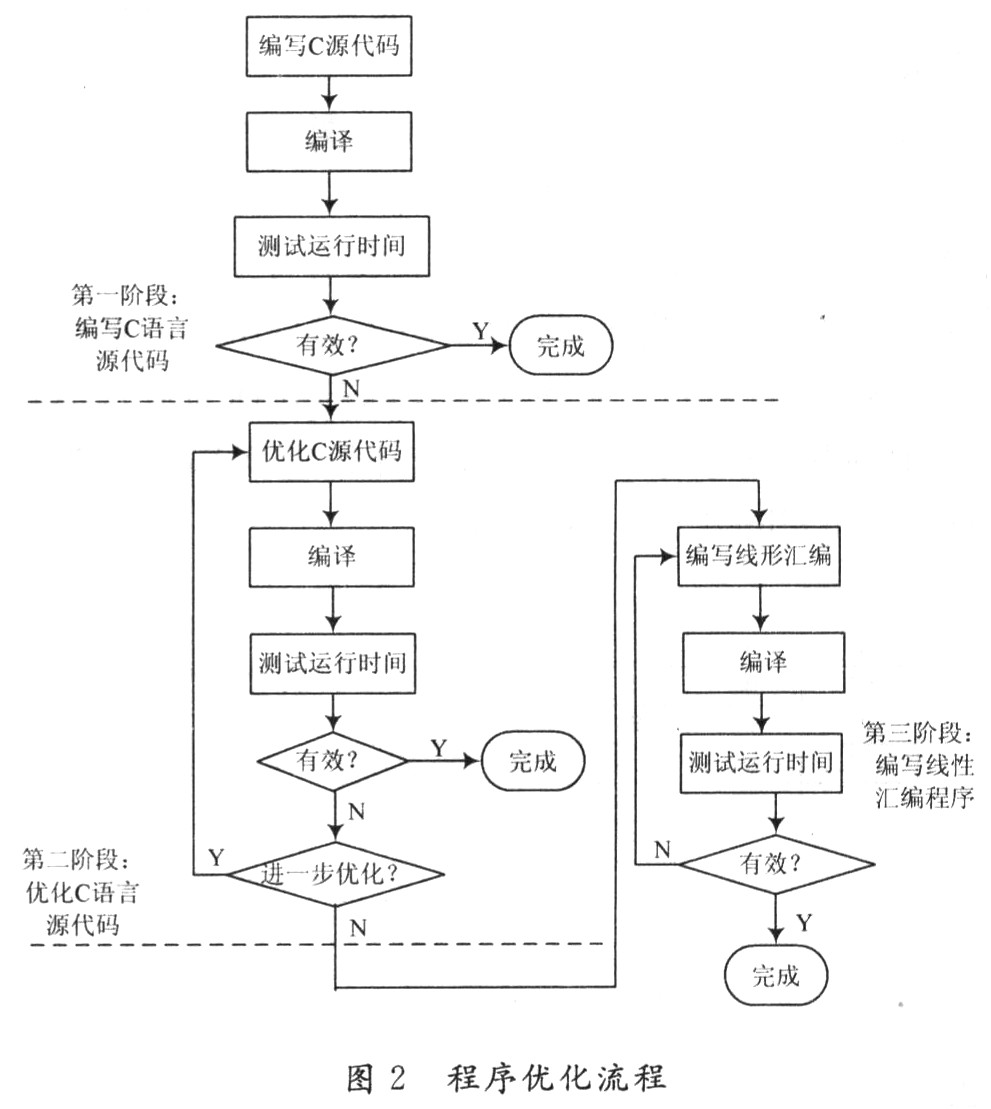 在图2中,第一阶段:没有C6000知识的用户能开发自己的C代码,然后使用CCS中的代码剖析工具,确定C代码中可能存在的低效率段,为进一步代码优化做好准备。第二阶段:C代码优化阶段。在这个阶段,主要利用intrinsics函数以及编译器编译选项来提高代码的性能。优化后利用软件模拟器检查代码的效率,如仍不能达到期望的效率,则进入第三阶段。第三阶段:写线性汇编优化。在这个阶段中,用户把最耗费时间的代码抽取出来,重新用线性汇编写,然后使用汇编优化器优化这些代码。在第一次写线性汇编时,可以不考虑流水线和寄存器分配。然后,提高线性汇编代码性能,往代码中添加更多的细节,如分配寄存器等。由于这一阶段所需的时间要比第二阶段多,所以整个代码的优化尽量放在第二阶段来完成,而少使用线性汇编代码优化。
在图2中,第一阶段:没有C6000知识的用户能开发自己的C代码,然后使用CCS中的代码剖析工具,确定C代码中可能存在的低效率段,为进一步代码优化做好准备。第二阶段:C代码优化阶段。在这个阶段,主要利用intrinsics函数以及编译器编译选项来提高代码的性能。优化后利用软件模拟器检查代码的效率,如仍不能达到期望的效率,则进入第三阶段。第三阶段:写线性汇编优化。在这个阶段中,用户把最耗费时间的代码抽取出来,重新用线性汇编写,然后使用汇编优化器优化这些代码。在第一次写线性汇编时,可以不考虑流水线和寄存器分配。然后,提高线性汇编代码性能,往代码中添加更多的细节,如分配寄存器等。由于这一阶段所需的时间要比第二阶段多,所以整个代码的优化尽量放在第二阶段来完成,而少使用线性汇编代码优化。
3.2 C/C++代码优化方法
为了使C/C++代码获得最好的性能,可以使用编译选项、软件流水、内联函数和循环展开等方法来对代码进行优化,以提高代码执行速度,并减小代码尺寸。
3.2.1 编译器选项优化
C/C++编译器可以对代码进行不同级别的优化。高级优化由专门的优化器完成,低级的和目标DSP有关的优化由代码生成器完成。图3为编译器、优化器和代码生成器的执行图。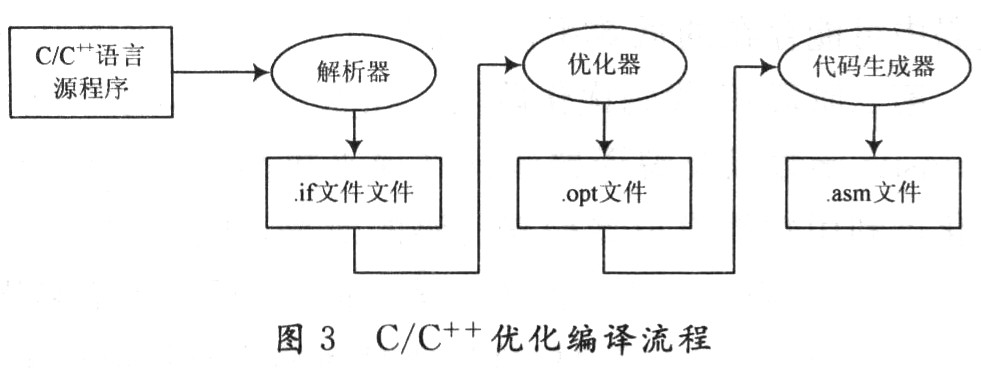 当优化器被激活时,将完成图3所示的过程。C/C++语言源代码首先通过一个完成预处理的解析器(Parser),生成一个中间文件(.if)作为优化器(Optimi-zer)的输入。优化器生成一个优化文件(.opt),这个文件作为完成进一步优化的代码生成器(Code Genera-tor)的输入,最终生成汇编文件(.asm)。
当优化器被激活时,将完成图3所示的过程。C/C++语言源代码首先通过一个完成预处理的解析器(Parser),生成一个中间文件(.if)作为优化器(Optimi-zer)的输入。优化器生成一个优化文件(.opt),这个文件作为完成进一步优化的代码生成器(Code Genera-tor)的输入,最终生成汇编文件(.asm)。
最简单执行优化的方法是采用cl6x编译程序,在命令行设置一On选项即可。n是优化的级别(n为0,1,2,3),它控制优化的类型和程度。
3.2.2 软件流水优化
软件流水是编排循环指令,使循环的多次迭代并行执行的技术。使用一02和一03选项编译C/C++程序时,编译器就从程序中收集信息,尝试对程序循环做软件流水。
图4显示一个软件流水循环。图4中A,B,C,D和E表示1次迭代中的各条指令;A1,A2,A3,A4和A5表示一条指令执行的各阶段。循环中,一个周期最多可并行执行5条指令,即图中阴影部分所示的循环核(Loop Kernel)部分。循环核前面的部分称为流水循环填充(Pipelined Loop Prolog),循环核后面部分称为循环排空(Pipelined Loop Epilog)。 3.2.3 内联函数优化
3.2.3 内联函数优化
通过下面的方法改进C语言程序,可使编译出的代码性能显著提高:
(1)使用intrinsics(内联函数)替代复杂的C/C++代码;
(2)使用字(Word)访问存放在32位寄存器的高16位和低16位字段的数据;
(3)使用双字访问存放在64位寄存器的32位数据(仅指C64xx/C67XX)。
C6000编译器提供了许多内联函数,它们直接对应着C62X/C64X/C67X指令可快速优化C代码。这些内联函数不易用C/C++语言实现其功能。内联函数用前下划线“_”特别标示,其使用方法与调用函数一样。例如C语言的饱和加法只能写为需要多周期的函数:
这段复杂的代码可以用_sadd()内联函数实现,它是一个单周期的C6x指令。
result=_sadd(a,b);
要提高C6000数据处理率,应使一条Load/Store指令能访问多个数据。C6000有与内联函数相关的指令,例如_add2(),_mpyhl(),_mpylh()等,这些操作数以16位数据形式存储在32位寄存器的高位部分和低位部分。当程序需要对一连串短型数据进行操作时,可使用字1次访问2个短型数据,然后使用C6000相应指令来处理数据。相似的在C64x或C67x中,有时需要执行64位的LDDW来访问两个32位数据,4个16位数据,甚至8个8位数据。
3.2.4 循环展开
循环展开是改进性能的另一种,即把小循环的迭代展开,以让循环的每次迭代出现在代码中。这种方法可增加并行执行的指令数。当每次迭代操作没有充分利用C6000结构的所有资源时,可使用循环展开提高性能。
有3种使循环展开的方法:
(1)编译器自动执行循环展开;
(2)在程序中使用UNROLL伪指令建议编译器做循环展开;
(3)用户自己在C/C++代码中展开。
3.3 汇编优化
在对C/C++代码使用了所有的C/C++优化手段之后,如果仍然不满意代码的性能,就可以写线性汇编程序,然后用汇编优化器进行优化,生成高性能的代码。
3.3.1 写线性汇编
使用C6000的剖析工具(Profiling Tools)可以找到代码中最耗费时间的部分,就是这部分需要用线性汇编重写。线性汇编代码与汇编源代码相似,但是,线性汇编代码中没有指令延迟和寄存器使用信息。这样做的目的是由汇编优化器来为自己设定这些信息。
写线性汇编代码时,需要知道:汇编优化器伪指令、影响汇编优化器行为的选项、TMS320C6000指令、线性汇编源语句语法、指定寄存器或寄存器组、指定功能单元、源代码注释等。
3.3.2 汇编优化器优化
汇编优化器的任务主要有:
(1)编排指令,最大限度的利用C6000的并行能力;
(2)确保指令满足C6000的延迟要求(Latency Requirements);
(3)为源代码分配寄存器。
4 结 语
C6000系列的DSP C/c++代码优化比传统的代码优化要方便的多,但要真正发挥其芯片的工作效率还是需要一定的经验和技巧。这不仅要求开发人员熟悉其硬件体系,还要求对编译器的编译原理有一定的理解。另外,在C语言层面上要达到DSP芯片的峰值即8条指令并行是很难的,大多情况下都只能达到6.7条指令并行。在实际开发中,若优化结果已达到6,7条指令并行却还离实时的要求相差很远,再花大量的人力去力求达到8条指令并行是不经济的,此时应该考虑其他的技术改进或策略上的调整以求达到目的。
TMS320C6000是TMS320系列产品中的新一代高性能DSP芯片,共分为两大系列。其中定点系列为TMS320C62xx和TMS320C64xx;浮点系列为TMS320C67xx。由于TMS320C6000的开发主要面向数据密集型算法,它有着丰富的内部资源和强大的运算能力,所以被广泛地应用于数字通信和图像处理等领域。
C6000系列CPU中的8个功能单元可以并行操作,并且其中两个功能单元为硬件乘法运算单元,大大地提高了乘法速度。DSP采用具有独立程序总线和数据总线的哈佛总线结构,仅片内程序总线宽度就可达到256位,即每周期可并行执行8条32位指令;片内两套数据总线的宽度分别为32位;此外,DSP还有一套32位DMA专用总线用于传输。灵活的总线结构使得数据瓶颈对系统性能的限制大大缓解。C6000的通用寄存器组能支持32位和40位定点数据操作,另外C67xx和C64xx还分别支持64位双精度数据和64位双字定点数据操作。除了多功能单元外,流水技术是提高DSP程序执行效率的另一主要手段。由于TMS320C6000的特殊结构,功能单元同时执行的各种操作可由VLlW长指令分配模块来同步执行,使8条并行指令同时通过流水线的每个节拍,极大地提高了机器的吞吐量。
2 C6000软件开发流程
图1为C6000的软件开发流程图。图中阴影部分是开发C代码的常规流程,其他部分用于辅助和加速开发讨程.
C/C++源文件首先经过C/C++编译器(C/C++cornpiler)转换为C6000汇编源代码。编译器、优化器(optimizer)和交叠工具是C/C++编译器的组成部分。编译器使用户能一步完成编译、汇编和连接;优化器调整合修改代码以提高C程序的效率;交叠工具把C/C++语句和对应的汇编语句交叠列出。
汇编源代码再经过汇编器(Assembier)翻译为机器语言目标文件。机器语言是基于通用目标文件格式(Common Object File Format,COFF)的。连接器(Linker)连接目标文件,生成一个可执行文件。它要完成地址的重分配(Relocation)和解析外部引用(Resolve External References)。
得到可执行文件之后就可以进行调试。可用软件仿真器(Simulator)在PC机上对指令和运行时间进行精确仿真;用XDS硬件仿真器(Emulator)在目标板上进行调试。
调试通过后即可下载到目标板进行独立运行。
3 程序优化流程及方法
3.1 程序优化阶段
由于DSP应用的复杂度,在用C语言进行DSP软件开发时,一般先在基于通用微处理器的PC机或工作站上对算法进行仿真,仿真通过后再将C程序移植到DSP平台中。
所以,DSP的软件开发与优化流程主要分为3个阶段:C代码开发阶段;C代码优化阶段;手工汇编代码重编写阶段。如图2所示。
在图2中,第一阶段:没有C6000知识的用户能开发自己的C代码,然后使用CCS中的代码剖析工具,确定C代码中可能存在的低效率段,为进一步代码优化做好准备。第二阶段:C代码优化阶段。在这个阶段,主要利用intrinsics函数以及编译器编译选项来提高代码的性能。优化后利用软件模拟器检查代码的效率,如仍不能达到期望的效率,则进入第三阶段。第三阶段:写线性汇编优化。在这个阶段中,用户把最耗费时间的代码抽取出来,重新用线性汇编写,然后使用汇编优化器优化这些代码。在第一次写线性汇编时,可以不考虑流水线和寄存器分配。然后,提高线性汇编代码性能,往代码中添加更多的细节,如分配寄存器等。由于这一阶段所需的时间要比第二阶段多,所以整个代码的优化尽量放在第二阶段来完成,而少使用线性汇编代码优化。3.2 C/C++代码优化方法
为了使C/C++代码获得最好的性能,可以使用编译选项、软件流水、内联函数和循环展开等方法来对代码进行优化,以提高代码执行速度,并减小代码尺寸。
3.2.1 编译器选项优化
C/C++编译器可以对代码进行不同级别的优化。高级优化由专门的优化器完成,低级的和目标DSP有关的优化由代码生成器完成。图3为编译器、优化器和代码生成器的执行图。
当优化器被激活时,将完成图3所示的过程。C/C++语言源代码首先通过一个完成预处理的解析器(Parser),生成一个中间文件(.if)作为优化器(Optimi-zer)的输入。优化器生成一个优化文件(.opt),这个文件作为完成进一步优化的代码生成器(Code Genera-tor)的输入,最终生成汇编文件(.asm)。最简单执行优化的方法是采用cl6x编译程序,在命令行设置一On选项即可。n是优化的级别(n为0,1,2,3),它控制优化的类型和程度。
3.2.2 软件流水优化
软件流水是编排循环指令,使循环的多次迭代并行执行的技术。使用一02和一03选项编译C/C++程序时,编译器就从程序中收集信息,尝试对程序循环做软件流水。
图4显示一个软件流水循环。图4中A,B,C,D和E表示1次迭代中的各条指令;A1,A2,A3,A4和A5表示一条指令执行的各阶段。循环中,一个周期最多可并行执行5条指令,即图中阴影部分所示的循环核(Loop Kernel)部分。循环核前面的部分称为流水循环填充(Pipelined Loop Prolog),循环核后面部分称为循环排空(Pipelined Loop Epilog)。
3.2.3 内联函数优化通过下面的方法改进C语言程序,可使编译出的代码性能显著提高:
(1)使用intrinsics(内联函数)替代复杂的C/C++代码;
(2)使用字(Word)访问存放在32位寄存器的高16位和低16位字段的数据;
(3)使用双字访问存放在64位寄存器的32位数据(仅指C64xx/C67XX)。
C6000编译器提供了许多内联函数,它们直接对应着C62X/C64X/C67X指令可快速优化C代码。这些内联函数不易用C/C++语言实现其功能。内联函数用前下划线“_”特别标示,其使用方法与调用函数一样。例如C语言的饱和加法只能写为需要多周期的函数:
这段复杂的代码可以用_sadd()内联函数实现,它是一个单周期的C6x指令。
result=_sadd(a,b);
要提高C6000数据处理率,应使一条Load/Store指令能访问多个数据。C6000有与内联函数相关的指令,例如_add2(),_mpyhl(),_mpylh()等,这些操作数以16位数据形式存储在32位寄存器的高位部分和低位部分。当程序需要对一连串短型数据进行操作时,可使用字1次访问2个短型数据,然后使用C6000相应指令来处理数据。相似的在C64x或C67x中,有时需要执行64位的LDDW来访问两个32位数据,4个16位数据,甚至8个8位数据。
3.2.4 循环展开
循环展开是改进性能的另一种,即把小循环的迭代展开,以让循环的每次迭代出现在代码中。这种方法可增加并行执行的指令数。当每次迭代操作没有充分利用C6000结构的所有资源时,可使用循环展开提高性能。
有3种使循环展开的方法:
(1)编译器自动执行循环展开;
(2)在程序中使用UNROLL伪指令建议编译器做循环展开;
(3)用户自己在C/C++代码中展开。
3.3 汇编优化
在对C/C++代码使用了所有的C/C++优化手段之后,如果仍然不满意代码的性能,就可以写线性汇编程序,然后用汇编优化器进行优化,生成高性能的代码。
3.3.1 写线性汇编
使用C6000的剖析工具(Profiling Tools)可以找到代码中最耗费时间的部分,就是这部分需要用线性汇编重写。线性汇编代码与汇编源代码相似,但是,线性汇编代码中没有指令延迟和寄存器使用信息。这样做的目的是由汇编优化器来为自己设定这些信息。
写线性汇编代码时,需要知道:汇编优化器伪指令、影响汇编优化器行为的选项、TMS320C6000指令、线性汇编源语句语法、指定寄存器或寄存器组、指定功能单元、源代码注释等。
3.3.2 汇编优化器优化
汇编优化器的任务主要有:
(1)编排指令,最大限度的利用C6000的并行能力;
(2)确保指令满足C6000的延迟要求(Latency Requirements);
(3)为源代码分配寄存器。
4 结 语
C6000系列的DSP C/c++代码优化比传统的代码优化要方便的多,但要真正发挥其芯片的工作效率还是需要一定的经验和技巧。这不仅要求开发人员熟悉其硬件体系,还要求对编译器的编译原理有一定的理解。另外,在C语言层面上要达到DSP芯片的峰值即8条指令并行是很难的,大多情况下都只能达到6.7条指令并行。在实际开发中,若优化结果已达到6,7条指令并行却还离实时的要求相差很远,再花大量的人力去力求达到8条指令并行是不经济的,此时应该考虑其他的技术改进或策略上的调整以求达到目的。