{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 守望178 的文章《互联网广告综述之点击率系统》','https://www.xiaopingtou.net/article-82103.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一.互联网广告技术
博文《互联网广告综述之生态圈》论述过互联网广告生态圈的各个平台,大家可以看到,其中的Ad exchange是躺着赚钱的平台,风险并不大。
其中的DSP就承担了比较多的风险,如果向Ad exchange请求的流量太贵,而广告主开价比较低的话,就可能面临亏钱。另外,广告主的需求是变化多样的,有些广告主愿意开一定价钱要求多少次点击,而有些广告主就希望开多少价钱有多少次互动,同时广告主会对效果有所需求。换句话说,评估流量的质量对DSP非常重要。
DSP需要评估流量质量,如果发现一个流量的质量很高,就开高价去竟争这个流量;如果流量质量低,就开低价去竟争。如果评估得太高,出很高的价钱拿到了质量很低的流量,那就达不到广告主的要求,会亏钱;如果评估得太低,一直拿不到流量,没办法赚钱。
所谓评估流量质量,说到底了是预估一个流量的ctr(点击率,也成为点击某广告的可能性),所以对于DSP来说,能否估准ctr是DSP生存的关键。
1.1互联网广告点击率预估做点击率预估需要两方面的数据,一方面是广告的数据,另一方面是用户的数据,对于DSP来说,广告数据它自己有,用户数据可以从DMP获取,它自己的工作是利用这两方面的数据评估用户点击这个广告的可能性(也就是概率)。
1.1.1 预估方法讨论对点击率的预估,做的工作可以用下面的图来描述。
 预估一个人点击一个广告的概率,不可能是一个人在那里看着,来一个广告请求就估计一下,给个决定,这样人累死,估计得也乱七八糟,还效率不高,一天撑死了估计个几十万个请求,不得了了。
预估一个人点击一个广告的概率,不可能是一个人在那里看着,来一个广告请求就估计一下,给个决定,这样人累死,估计得也乱七八糟,还效率不高,一天撑死了估计个几十万个请求,不得了了。
只能用机器来估,但是机器是很笨的,只能进行简单的规则运算,这些规则还必须提前指定。如果人工指定这些规则,如30岁用户点击匹克篮球的广告概率是多少,男性的用户点击匹克篮球的广告的概率是多少,年龄和性别在总的ctr预估里面占多少比重等等,则需要大量的先验知识,而且还不能根据实际情况变化,往往有问题。
这就需要机器学习方法来辅助了,一个是统计方法,一个是模型。
统计方法怎么用呢?如可以统计过去投放过的记录中,30岁的用户点击匹克篮球的广告的点击率是多少,这个数据直接就能根据投放日志统计出来;再统计男性的用户点击匹克篮球的广告的点击率是多少,这样前面的两个东西就得到了。
但是知道这两个点击率,还需要知道这两个点击率在评估这个人点击匹克篮球的广告的概率中分别起什么作用。这两个点击率加起来不行,相减也是不行的,加权累加可能是一种办法,但是这样行吗?为了解决这个事情,需要用模型来解决了。为了描述的方便,我们把这两个点击率称为特征,用一个向量x=(x1,x2)来统一表示,其中x1表示30岁的用户对匹克篮球的广告的点击率,x2男性的用户对匹克篮球的广告的点击率。
利用模型做ctr预估,用数学的方法来描述就是完成上面的图中函数f的形式。
本来这个函数的形式是很复杂的,但是太复杂的模型不利于扩展,就用简单的形式来。经过工业界长期的工作,认为下面的形式是比较有效的。
 其中x是上面的那个x,w也是一个向量,表示的是x的每个特征的权重。这个w每取一个值,对相同的user和ad对就能得到一个预估的ctr,w同时也被称为是模型,因为它能根据x的取值,也就是特征的取值来决定ctr。
其中x是上面的那个x,w也是一个向量,表示的是x的每个特征的权重。这个w每取一个值,对相同的user和ad对就能得到一个预估的ctr,w同时也被称为是模型,因为它能根据x的取值,也就是特征的取值来决定ctr。
权重可以人工指定的,但是上面说过了,需要大量的先验知识,而且特征会特别多,如上面还有地域,职业,学校什么的,可以搞到成千上万的特征,人工指定没办法做到周全。所以这个权重的是要用算法来让机器自己学习到的,这个过程称为训练,这个训练过程还不能只根据一个记录user和ad对来训练,要根据很多对来训练。每个展示记录就是一个对,根据历史的一段时间内的展示记录,能有很多的的数据对可以进行训练。
用什么方法进行训练呢?上面user和ad对可以达到上亿的量级。
机器学习领域的把这个训练过程称为是拟合分布的过程,他们认为一次广告的展示是否被点击(每次展示被点击的概率可能不一样)是一个伯努利试验,对多个用户展示多个广告的过程是一个伯努利过程,总体的历史展示与点击数据符合一个伯努利分布,伯努利试验成功的概率就是上面的f(user,ad)的值。拟合这个伯努利分布的过程就是训练的过程。拟合分布往往用的是极大似然估计的方式去拟合,刚好做的事情就是跟做一个回归问题是一样的,这个回归叫做logistic回归。为了方便描述,改变一下f的写法,用下面的方式表示
 其中y=1表示这个展示被点击了,y=0表示这个展示没有被点击。似然函数和对数似然函数也可以写成下面的形式
其中y=1表示这个展示被点击了,y=0表示这个展示没有被点击。似然函数和对数似然函数也可以写成下面的形式
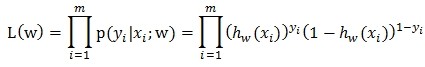
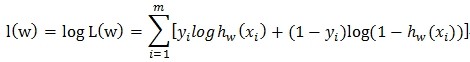 求上面的式子的最大值,就可以得到w的最优解,这个最优解w就表示当前展示数据的伯努利分布是拟合的最好的,用来预估ctr也是最好的。
求上面的式子的最大值,就可以得到w的最优解,这个最优解w就表示当前展示数据的伯努利分布是拟合的最好的,用来预估ctr也是最好的。
有关求解最优化问题的基础可以参看博文《无约束优化方法读书笔记—入门篇》
有关极大似然估计的知识可以参看博客中转载的《从最大似然到EM算法浅解》。
有关逻辑回归及其相关知识的可以参看博文《从广义线性模型到逻辑回归》。有关特征工程的知识可以参看博文《互联网广告综述之点击率特征工程》。
1.1.2 线上应用情况下面的图显示了CTR预估的系统结构。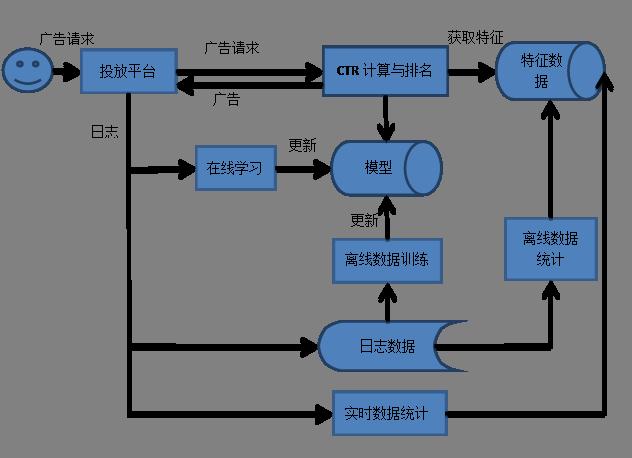 其中投放平台获取到用户的广告请求后,将请求交给CTR计算与排名模块,这个模块会获取用户数据和广告数据,再根据模型计算CTR。得到ctr后,有两种方式使用。一种是对CTR进行排名,返回排名ctr最高的广告,然后DSP就可以根据这个CTR出价了;另一种是将广告的出价与ctr相乘,得到每个广告的收益,根据收益排名,返回收益排名最高的广告。
其中投放平台获取到用户的广告请求后,将请求交给CTR计算与排名模块,这个模块会获取用户数据和广告数据,再根据模型计算CTR。得到ctr后,有两种方式使用。一种是对CTR进行排名,返回排名ctr最高的广告,然后DSP就可以根据这个CTR出价了;另一种是将广告的出价与ctr相乘,得到每个广告的收益,根据收益排名,返回收益排名最高的广告。
投放平台获取这个广告后,根据一些条件,会把广告展示给用户,同时产生投放日志。用户会做出相应的反馈(点击或不点击),产生点击日志。
这些日志会产生三个作用。一种是存到日志数据存储工具。第二种是产生实时统计数据,以方便迅速更新特征。第三种是进行在线学习,不断更新线上的模型。
日志存储工具的日志有两种作用,一种是经过ETL,可以生成训练数据,然后用这些训练数据去训练模型,然后更新线上的模型;另一种是利用统计的方式或者其他方式产生特征。
线上模型有两种更新方式,一种是离线训练的更新方式,一种是在线学习的更新方式。
这两种方式分别用的是两种不同的训练算法。离线训练的更新方式比较慢,频率一般比较低,一般都是一天或者一个星期训练一次,用的方法一般是批量学习方式,就是对数据进行多轮的迭代,获取w的尽可能的最优解。在线学习的方式要求能快速更新线上模型,一般是来一个展示记录,就获取这个展示记录的特征,然后利用这个记录去进行只有一个数据的迭代,得到一个新的模型。
离线训练的方式有多种,其中一种可以参看转载的博文《OWL-QN算法》。
在线学习的方式也有多种,其中一种可以参看博文《在线学习算法FTRL》。
致谢
多位Google、Linkedln公司的研究员无私公开的资料。
多位博主的博客资料。
参考文献
[1] Ad ClickPrediction: a View from the Trenches. H. Brendan McMahan, Gary Holt et al,Google的论文[2] http://blog.csdn.net/zouxy09/article/details/8537620@zouxy09的博客[3] http://www.cnblogs.com/vivounicorn/archive/2012/06/25/2561071.html@Leo Zhang的博客[4] Computational Advertising: The LinkedIn Way. Deepak Agarwal, LinkedIn Corporation CIKM
博文《互联网广告综述之生态圈》论述过互联网广告生态圈的各个平台,大家可以看到,其中的Ad exchange是躺着赚钱的平台,风险并不大。
其中的DSP就承担了比较多的风险,如果向Ad exchange请求的流量太贵,而广告主开价比较低的话,就可能面临亏钱。另外,广告主的需求是变化多样的,有些广告主愿意开一定价钱要求多少次点击,而有些广告主就希望开多少价钱有多少次互动,同时广告主会对效果有所需求。换句话说,评估流量的质量对DSP非常重要。
DSP需要评估流量质量,如果发现一个流量的质量很高,就开高价去竟争这个流量;如果流量质量低,就开低价去竟争。如果评估得太高,出很高的价钱拿到了质量很低的流量,那就达不到广告主的要求,会亏钱;如果评估得太低,一直拿不到流量,没办法赚钱。
所谓评估流量质量,说到底了是预估一个流量的ctr(点击率,也成为点击某广告的可能性),所以对于DSP来说,能否估准ctr是DSP生存的关键。
1.1互联网广告点击率预估做点击率预估需要两方面的数据,一方面是广告的数据,另一方面是用户的数据,对于DSP来说,广告数据它自己有,用户数据可以从DMP获取,它自己的工作是利用这两方面的数据评估用户点击这个广告的可能性(也就是概率)。
1.1.1 预估方法讨论对点击率的预估,做的工作可以用下面的图来描述。
预估一个人点击一个广告的概率,不可能是一个人在那里看着,来一个广告请求就估计一下,给个决定,这样人累死,估计得也乱七八糟,还效率不高,一天撑死了估计个几十万个请求,不得了了。只能用机器来估,但是机器是很笨的,只能进行简单的规则运算,这些规则还必须提前指定。如果人工指定这些规则,如30岁用户点击匹克篮球的广告概率是多少,男性的用户点击匹克篮球的广告的概率是多少,年龄和性别在总的ctr预估里面占多少比重等等,则需要大量的先验知识,而且还不能根据实际情况变化,往往有问题。
这就需要机器学习方法来辅助了,一个是统计方法,一个是模型。
统计方法怎么用呢?如可以统计过去投放过的记录中,30岁的用户点击匹克篮球的广告的点击率是多少,这个数据直接就能根据投放日志统计出来;再统计男性的用户点击匹克篮球的广告的点击率是多少,这样前面的两个东西就得到了。
但是知道这两个点击率,还需要知道这两个点击率在评估这个人点击匹克篮球的广告的概率中分别起什么作用。这两个点击率加起来不行,相减也是不行的,加权累加可能是一种办法,但是这样行吗?为了解决这个事情,需要用模型来解决了。为了描述的方便,我们把这两个点击率称为特征,用一个向量x=(x1,x2)来统一表示,其中x1表示30岁的用户对匹克篮球的广告的点击率,x2男性的用户对匹克篮球的广告的点击率。
利用模型做ctr预估,用数学的方法来描述就是完成上面的图中函数f的形式。
本来这个函数的形式是很复杂的,但是太复杂的模型不利于扩展,就用简单的形式来。经过工业界长期的工作,认为下面的形式是比较有效的。
其中x是上面的那个x,w也是一个向量,表示的是x的每个特征的权重。这个w每取一个值,对相同的user和ad对就能得到一个预估的ctr,w同时也被称为是模型,因为它能根据x的取值,也就是特征的取值来决定ctr。权重可以人工指定的,但是上面说过了,需要大量的先验知识,而且特征会特别多,如上面还有地域,职业,学校什么的,可以搞到成千上万的特征,人工指定没办法做到周全。所以这个权重的是要用算法来让机器自己学习到的,这个过程称为训练,这个训练过程还不能只根据一个记录user和ad对来训练,要根据很多对来训练。每个展示记录就是一个对,根据历史的一段时间内的展示记录,能有很多的的数据对可以进行训练。
用什么方法进行训练呢?上面user和ad对可以达到上亿的量级。
机器学习领域的把这个训练过程称为是拟合分布的过程,他们认为一次广告的展示是否被点击(每次展示被点击的概率可能不一样)是一个伯努利试验,对多个用户展示多个广告的过程是一个伯努利过程,总体的历史展示与点击数据符合一个伯努利分布,伯努利试验成功的概率就是上面的f(user,ad)的值。拟合这个伯努利分布的过程就是训练的过程。拟合分布往往用的是极大似然估计的方式去拟合,刚好做的事情就是跟做一个回归问题是一样的,这个回归叫做logistic回归。为了方便描述,改变一下f的写法,用下面的方式表示
求上面的式子的最大值,就可以得到w的最优解,这个最优解w就表示当前展示数据的伯努利分布是拟合的最好的,用来预估ctr也是最好的。有关求解最优化问题的基础可以参看博文《无约束优化方法读书笔记—入门篇》
有关极大似然估计的知识可以参看博客中转载的《从最大似然到EM算法浅解》。
有关逻辑回归及其相关知识的可以参看博文《从广义线性模型到逻辑回归》。有关特征工程的知识可以参看博文《互联网广告综述之点击率特征工程》。
1.1.2 线上应用情况下面的图显示了CTR预估的系统结构。
其中投放平台获取到用户的广告请求后,将请求交给CTR计算与排名模块,这个模块会获取用户数据和广告数据,再根据模型计算CTR。得到ctr后,有两种方式使用。一种是对CTR进行排名,返回排名ctr最高的广告,然后DSP就可以根据这个CTR出价了;另一种是将广告的出价与ctr相乘,得到每个广告的收益,根据收益排名,返回收益排名最高的广告。投放平台获取这个广告后,根据一些条件,会把广告展示给用户,同时产生投放日志。用户会做出相应的反馈(点击或不点击),产生点击日志。
这些日志会产生三个作用。一种是存到日志数据存储工具。第二种是产生实时统计数据,以方便迅速更新特征。第三种是进行在线学习,不断更新线上的模型。
日志存储工具的日志有两种作用,一种是经过ETL,可以生成训练数据,然后用这些训练数据去训练模型,然后更新线上的模型;另一种是利用统计的方式或者其他方式产生特征。
线上模型有两种更新方式,一种是离线训练的更新方式,一种是在线学习的更新方式。
这两种方式分别用的是两种不同的训练算法。离线训练的更新方式比较慢,频率一般比较低,一般都是一天或者一个星期训练一次,用的方法一般是批量学习方式,就是对数据进行多轮的迭代,获取w的尽可能的最优解。在线学习的方式要求能快速更新线上模型,一般是来一个展示记录,就获取这个展示记录的特征,然后利用这个记录去进行只有一个数据的迭代,得到一个新的模型。
离线训练的方式有多种,其中一种可以参看转载的博文《OWL-QN算法》。
在线学习的方式也有多种,其中一种可以参看博文《在线学习算法FTRL》。
致谢
多位Google、Linkedln公司的研究员无私公开的资料。
多位博主的博客资料。
参考文献
[1] Ad ClickPrediction: a View from the Trenches. H. Brendan McMahan, Gary Holt et al,Google的论文[2] http://blog.csdn.net/zouxy09/article/details/8537620@zouxy09的博客[3] http://www.cnblogs.com/vivounicorn/archive/2012/06/25/2561071.html@Leo Zhang的博客[4] Computational Advertising: The LinkedIn Way. Deepak Agarwal, LinkedIn Corporation CIKM