{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 新人小童鞋 的文章《飞思卡尔处理器K60学习笔记(二)---------Cortex-M内核比较》','https://www.xiaopingtou.net/article-83119.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
本文主要分析Cortex-M系列处理器的异同点,在上一篇的基础上增加对Cortex-M4的认识和了解。所谓无图无真相,直接上图说话。
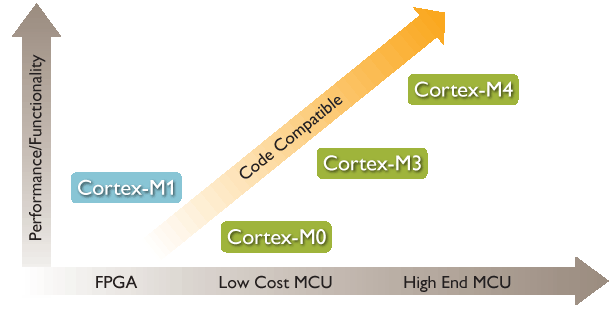
图1:CORTEX-M0/M1------> CORTEX-M3 --------->CORTEX-M4三者内核功能的比较:
 从图上可以看出三者功能上的异同点。它们的不同点也决定了三者的不同应用场合。M4相比较前两者主要的变化在于数字运算能力上的增强,增加了DSP运算指令、SIMD(Single Instruction Multiple Data,单指令多数据流)指令集、FPU(浮点运算单元,可选)。
从图上可以看出三者功能上的异同点。它们的不同点也决定了三者的不同应用场合。M4相比较前两者主要的变化在于数字运算能力上的增强,增加了DSP运算指令、SIMD(Single Instruction Multiple Data,单指令多数据流)指令集、FPU(浮点运算单元,可选)。
图2:CORTEX-M0/M1------> CORTEX-M3 --------->CORTEX-M4 三个内核之间的所支持指令功能的对比。
 从图中足以看出M4内核的强大,同时Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个 Cortex-M 处理器无缝发展到另一个成为可能(图3):
从图中足以看出M4内核的强大,同时Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个 Cortex-M 处理器无缝发展到另一个成为可能(图3):
 下面就增强的三个功能进行说明:
1、DSP指令集
所谓集成DSP功能并不是说M4内核是一个M3+DSP的双核处理器(目前个人知道的这类处理器是TI的达芬奇系列,主要应用于语音、视频图像有关的数字多媒体领域)。而是只是增加了DSP功能的指令集(单周期的运算指令),能在一个周期内完成指令操作。在官方的CMSIS标准工程库中已经集成,可以直接使用(有关内容在以后文章中介绍)。
图表展示了处理器运行在相同的速度下Cortex - M3和Cortex - M4在数字信号处理能力方面的相对性能比较。
下面就增强的三个功能进行说明:
1、DSP指令集
所谓集成DSP功能并不是说M4内核是一个M3+DSP的双核处理器(目前个人知道的这类处理器是TI的达芬奇系列,主要应用于语音、视频图像有关的数字多媒体领域)。而是只是增加了DSP功能的指令集(单周期的运算指令),能在一个周期内完成指令操作。在官方的CMSIS标准工程库中已经集成,可以直接使用(有关内容在以后文章中介绍)。
图表展示了处理器运行在相同的速度下Cortex - M3和Cortex - M4在数字信号处理能力方面的相对性能比较。
在下面的数字,Y轴代表执行给出的计算用的相对的周期数。 因此,循环数越小,性能越好。以Cortex - M3作为参考,Cortex - M4的性能计算,性能比大概为其周期计数的倒数。举例说明,PID功能,Cortex - M4的周期数是与Cortex - M3的约0.7倍,因此相对性能是1/0.7,即1.4倍。
Cortex - M系列16位循环计数功能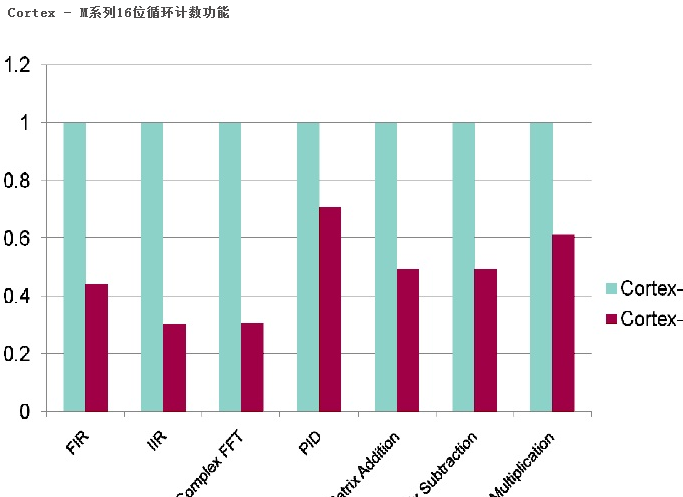
Cortex - M系列32位循环计数功能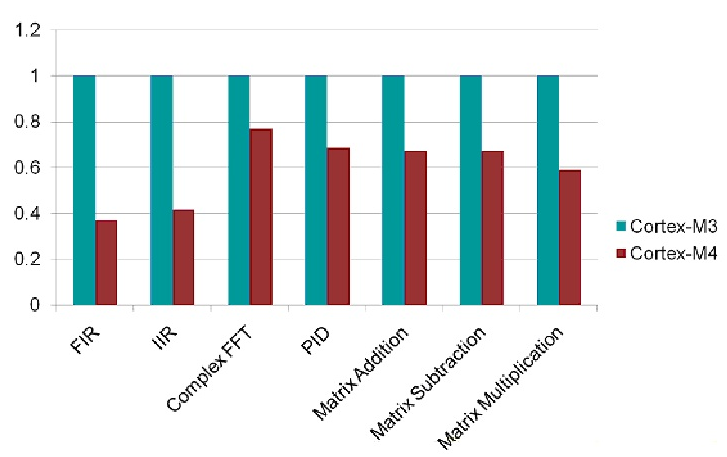 这很清楚的表明,Cortex - M4在数字信号处理方面对比Cortex - M3的16位或32位操作有着很大的优势。
Cortex-M4执行的所有的DSP指令集都可以在一个周期完成,Cortex - M3需要多个指令和多个周期才能完成的等效功能。即使是PID算法——通用DSP运算中最耗费资源的工作,Cortex - M4也能提供了一个1.4倍的性能得改善 。另一个例子,MP3解码在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
2. 32位乘法累加(MAC)
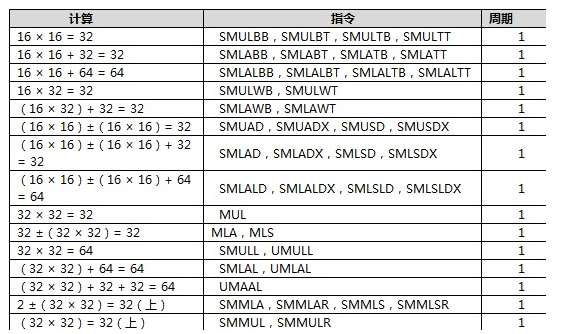
32位乘法累加(MAC)包括新的指令集和针对Cortex - M4硬件执行单元的优化它是能够在单周期内完成一个 32
× 32 + 64 - > 64 的操作 或 两个16 × 16 的操作。如下表列出了这个单元的计算能力。
这很清楚的表明,Cortex - M4在数字信号处理方面对比Cortex - M3的16位或32位操作有着很大的优势。
Cortex-M4执行的所有的DSP指令集都可以在一个周期完成,Cortex - M3需要多个指令和多个周期才能完成的等效功能。即使是PID算法——通用DSP运算中最耗费资源的工作,Cortex - M4也能提供了一个1.4倍的性能得改善 。另一个例子,MP3解码在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
2. 32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和针对Cortex - M4硬件执行单元的优化它是能够在单周期内完成一个 32
× 32 + 64 - > 64 的操作 或 两个16 × 16 的操作。如下表列出了这个单元的计算能力。
3 .SIMD
(Single Instruction Multiple Data,单指令多数据流)能够复制多个操作数,并把它们打包在大型寄存器的一组指令集,例:3DNow!、SSE。以同步方式,在同一时间内执行同一条指令。 SIMD在性能上的优势: 以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。 如:AMD公司引以为豪的3D NOW! 技术实质就是SIMD,这使K6-2、雷鸟、毒龙处理器在音频解码、视频回放、3D游戏等应用中显示出优异的性能。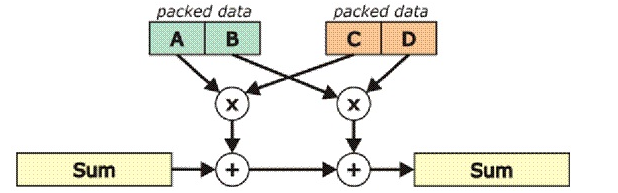
4.FPU
FPU是Cortex - M4浮点运算的可选单元。因此它是一个专用于浮点任务的单元。这个单元通过硬件提升性能,能处理单精度浮点运算,并与IEEE 754标准 兼容。这完成了ARMv7 - M架构单精度变量的浮点扩展。FPU扩展了寄存器的程序模型与包含32个单精度寄存器的寄存器文件。这些可以被看作是: ·16个64位双字寄存器,D0 - D15 ·32个32位单字寄存器,S0 - S31 该FPU提供了三种模式运作,以适应各种应用 ·全兼容模式(在全兼容模式,FPU处理所有的操作都遵循IEEE754的硬件标准) ·Flush-to-zero 冲洗到零模式(设置FZ位浮点状态和控制寄存器FPSCR [24]到flush-to-zero 模式。在此模式下,FPU 在运算中将所有不正常的输入操作数的算术CDP操作当做0.除了当从零操作数的结果是合适的情况。VABS,VNEG,VMOV 不会被当做算术CDP的运算,而且不受flush-to-zero 模式影响。结果是微小的,就像在IEEE 754 标准的描述的那样,在目标精度增加的幅度小于四舍五入后最低正常值,被零取代。IDC的标志位,FPSCR [7],表示当输入Flush时变化。UFC标志位,FPSCR [3],表示当Flush结束时变化) ·默认的NaN模式(DN位的设置,FPSCR [25],会进入NaN的默认模式。在这种模式下,如对任何算术数据处理操作的结果,涉及一个输入NaN,或产生一个NaN结果,会返回默认的NaN。仅当VABS,VNEG,VMOV运算时,分数位增加保持。所有其他的CDP运算会忽略所有输入NaN的小数位的信息)。具体指令请自行查看手册。
PS:本文主要转载于以下文档 1、百度百科SIMD目录 2、CORTEX-M目录 3、博客:古月居:http://blog.csdn.net/hcx25909/article/details/7102689
从图上可以看出三者功能上的异同点。它们的不同点也决定了三者的不同应用场合。M4相比较前两者主要的变化在于数字运算能力上的增强,增加了DSP运算指令、SIMD(Single Instruction Multiple Data,单指令多数据流)指令集、FPU(浮点运算单元,可选)。图2:CORTEX-M0/M1------> CORTEX-M3 --------->CORTEX-M4 三个内核之间的所支持指令功能的对比。
从图中足以看出M4内核的强大,同时Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个 Cortex-M 处理器无缝发展到另一个成为可能(图3):
下面就增强的三个功能进行说明:
1、DSP指令集
所谓集成DSP功能并不是说M4内核是一个M3+DSP的双核处理器(目前个人知道的这类处理器是TI的达芬奇系列,主要应用于语音、视频图像有关的数字多媒体领域)。而是只是增加了DSP功能的指令集(单周期的运算指令),能在一个周期内完成指令操作。在官方的CMSIS标准工程库中已经集成,可以直接使用(有关内容在以后文章中介绍)。
图表展示了处理器运行在相同的速度下Cortex - M3和Cortex - M4在数字信号处理能力方面的相对性能比较。在下面的数字,Y轴代表执行给出的计算用的相对的周期数。 因此,循环数越小,性能越好。以Cortex - M3作为参考,Cortex - M4的性能计算,性能比大概为其周期计数的倒数。举例说明,PID功能,Cortex - M4的周期数是与Cortex - M3的约0.7倍,因此相对性能是1/0.7,即1.4倍。
Cortex - M系列16位循环计数功能
Cortex - M系列32位循环计数功能
这很清楚的表明,Cortex - M4在数字信号处理方面对比Cortex - M3的16位或32位操作有着很大的优势。
Cortex-M4执行的所有的DSP指令集都可以在一个周期完成,Cortex - M3需要多个指令和多个周期才能完成的等效功能。即使是PID算法——通用DSP运算中最耗费资源的工作,Cortex - M4也能提供了一个1.4倍的性能得改善 。另一个例子,MP3解码在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
2. 32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和针对Cortex - M4硬件执行单元的优化它是能够在单周期内完成一个 32
× 32 + 64 - > 64 的操作 或 两个16 × 16 的操作。如下表列出了这个单元的计算能力。
3 .SIMD
(Single Instruction Multiple Data,单指令多数据流)能够复制多个操作数,并把它们打包在大型寄存器的一组指令集,例:3DNow!、SSE。以同步方式,在同一时间内执行同一条指令。 SIMD在性能上的优势: 以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。 如:AMD公司引以为豪的3D NOW! 技术实质就是SIMD,这使K6-2、雷鸟、毒龙处理器在音频解码、视频回放、3D游戏等应用中显示出优异的性能。
4.FPU
FPU是Cortex - M4浮点运算的可选单元。因此它是一个专用于浮点任务的单元。这个单元通过硬件提升性能,能处理单精度浮点运算,并与IEEE 754标准 兼容。这完成了ARMv7 - M架构单精度变量的浮点扩展。FPU扩展了寄存器的程序模型与包含32个单精度寄存器的寄存器文件。这些可以被看作是: ·16个64位双字寄存器,D0 - D15 ·32个32位单字寄存器,S0 - S31 该FPU提供了三种模式运作,以适应各种应用 ·全兼容模式(在全兼容模式,FPU处理所有的操作都遵循IEEE754的硬件标准) ·Flush-to-zero 冲洗到零模式(设置FZ位浮点状态和控制寄存器FPSCR [24]到flush-to-zero 模式。在此模式下,FPU 在运算中将所有不正常的输入操作数的算术CDP操作当做0.除了当从零操作数的结果是合适的情况。VABS,VNEG,VMOV 不会被当做算术CDP的运算,而且不受flush-to-zero 模式影响。结果是微小的,就像在IEEE 754 标准的描述的那样,在目标精度增加的幅度小于四舍五入后最低正常值,被零取代。IDC的标志位,FPSCR [7],表示当输入Flush时变化。UFC标志位,FPSCR [3],表示当Flush结束时变化) ·默认的NaN模式(DN位的设置,FPSCR [25],会进入NaN的默认模式。在这种模式下,如对任何算术数据处理操作的结果,涉及一个输入NaN,或产生一个NaN结果,会返回默认的NaN。仅当VABS,VNEG,VMOV运算时,分数位增加保持。所有其他的CDP运算会忽略所有输入NaN的小数位的信息)。具体指令请自行查看手册。
PS:本文主要转载于以下文档 1、百度百科SIMD目录 2、CORTEX-M目录 3、博客:古月居:http://blog.csdn.net/hcx25909/article/details/7102689