{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 jing632 的文章《硬件设计13---什么是回声抵消?》','https://www.xiaopingtou.net/article-83176.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
时间:2018.3.12 作者:Tom 工作:HWE 说明:如需转载,请注明出处。 回声消除(Echo Cancellation )又称回声抑制(Echo Suppression)。是电路电话、移动电话、VOIP等语音设备提升语音质量的一项重要技术。 那什么是回声呢?1.回声 回声本质上是自己的声音经过一段时间后又传回到自己耳朵中,如果回声的时延小于10ms,则称为侧音,时延如果在50ms左右称为合音,无论哪种回声都严重影响通话双方的主观感受,仿佛在空旷的房间里说话。1.1回声分类 从回声产生的角度来说分为两类:声学回声(Acoustic Echo)及线路回声(Line Echo),前者是由于声音从远端的扬声器传至麦克风(免提时尤甚)导致,后者是由于线路上阻抗不匹配引起的信号反馈所产生,具体来说是ADSL Modem和交换机上存在的2-4线转换电路不匹配把一部分信号反馈回来形成了回音。但消除的算法是比较通用的,即处理声学回声的算法也可处理线路回声或是混合回声。1.2声学回声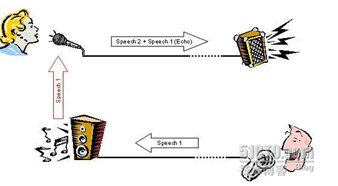 图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。1.3线路回声
图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。1.3线路回声 在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。不管产生的原因如何,对语音通讯终端或者语音中继交换机需要做的事情都一样:在发送时,把不需要的回音从语音流中间去掉总结起来说:声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。不管产生的原因如何,对语音通讯终端或者语音中继交换机需要做的事情都一样:在发送时,把不需要的回音从语音流中间去掉总结起来说:声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);线路回音是由于物理电子线路的二四线匹配耦合引起的(比较难理解)。2.回声消除原理 首先需要知道的是,如果仅仅是一段混合了回音的语音信号,要去掉回音也是不可能的。但是,实际上,除了这个混合信号,我们是可以得到产生回音的原始信号的,虽然不同于回音信号。对应回声的分类,可将回声消除技术分为:声学回声消除(AEC)和线路回声消除(LEC)。但消除的算法是比较通用的,即处理声学回声的算法也可处理线路回声或是混合回声。我们来看下回声消除的原理:
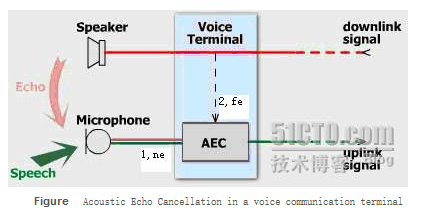 其中,我们可以得到两个信号:
其中,我们可以得到两个信号:一个是蓝 {MOD}和红 {MOD}混合的信号1,也就是实际需要发送的speech和实际不需要的echo混合而成的语音流;另一个就是虚线的信号2,也就是原始的引起回音的语音。那大家会说,哦,原来回声消除这么简单,直接从混合信号1里面把把这个虚线的2减掉不就行了?请注意,拿到的这个虚线信号2和回音echo是有差异的,直接相减会使语音面目全非。我们把混合信号1叫做近端信号ne,虚线信号2叫做远端参考信号fe,如果没有fe这个信号,回声消除就是不可能完成的任务,就像"巧妇难为无米之炊"虽然参考信号fe和echo不完全一样,存在差异,但是二者是高度相关的,这也是echo称之为回音的原因。至少,回音的语音和参考信号是一样的,也还听得懂,但是如果你说一句,马上又听到自己的话回来一句,那是比较难受的。既然fe和echo高度相关,echo又是fe引起的,我们可以把echo表示为fe的数学函数:
echo=F(fe)。函数F被称之为回音路径。在声学回声消除里面,函数F表示声音在墙壁,天花板等表面多次反射的物理过程;在线路回声消除里面,函数F表示电子线路的二四线匹配耦合过程。很显然,我们下面要做的工作就是求解函数F。得到函数F就可以从fe计算得到echo,然后从混合信号1里面减掉echo就实现了回声消除。尽管回声消除是非常复杂的技术,但我们可以简单的描述这种处理方法: 1、房间A的音频会议系统接收到房间B中的声音 2、声音被采样,这一采样被称为回声消除参考 3、随后声音被送到房间A的音箱和声学回声消除器中 4、房间B的声音和房间A的声音一起被房间A的话筒拾取 5、声音被送到声学回声消除器中,与原始的采样进行比较,移除房间B的声音
求解回音路径函数F的过程恐怕就是比较难以表达的数学公式了。鉴于通俗表达数学公式的难度比发现数学公式还难,笔者就不费力解释了。下面这段表达了利用自适应滤波器原理求解函数F的过程。自适应滤波器
自适应滤波器是以输入和输出信号的统计特性的估计为依据,采取特定算法自动地调整滤波器系数,使其达到最佳滤波特性的一种算法或装置。自适应滤波器可以是连续域的或是离散域的。离散域自适应滤波器由一组抽头延迟线、可变加权系数和自动调整系数的机构组成。自适应滤波器应用于通信领域的自动均衡、回声消除、天线阵波束形成,以及其他有关领域信号处理的参数识别、噪声消除、谱估计等方面。对于不同的应用,只是所加输入信号和期望信号不同,基本原理则是相同的。
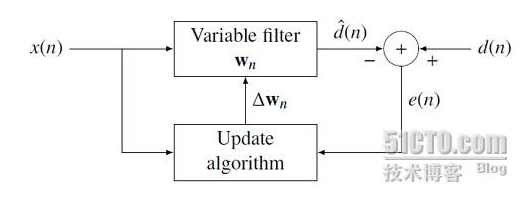 上面这段话表明,需要求解的回音路径函数F就是一个自适应滤波器W(n)收敛的过程。所加输入信号x(n)是fe,期望信号是echo,自适应滤波器收敛后的W(n)就是回音路径函数F。 收敛之后,当实际回音发生,我们把fe通过函数W(n),就可以得到一个很准确的echo,把混合信号直接减去echo,得到实际需要发送的语音speech,完成回声消除任务。值得注意的两点:
上面这段话表明,需要求解的回音路径函数F就是一个自适应滤波器W(n)收敛的过程。所加输入信号x(n)是fe,期望信号是echo,自适应滤波器收敛后的W(n)就是回音路径函数F。 收敛之后,当实际回音发生,我们把fe通过函数W(n),就可以得到一个很准确的echo,把混合信号直接减去echo,得到实际需要发送的语音speech,完成回声消除任务。值得注意的两点:- 自适应滤波器收敛阶段,期望信号是完全的echo,不能混杂有speech。因为speech和fe是没有关系的,会扰乱W(n)的收敛过程。也就是说要求回声消除算法开始运转后收敛要非常快,最好对方还来不及说话,你一说就收敛好了;收敛好之后,如果对方开始说话,也就是有speech混合过来,这个W(n)系数就不要变化了,需要稳定下来。
- 回音路径可能是变化的,一旦出现变化,回声消除算法要能判断出来,因为自适应滤波器学习要重新开始,也就是W(n)需要一个新的收敛过程,以逼近新的回音路径函数F。
声学回声主要又分成以下两种:
1、直接回声:由扬声器产生的声音未经任何反射直接进入麦克风
2、间接回声:由扬声器发出的声音经过多次反射后,再进入Mic
对于第二种回声,拥有多路径、时变性的特点,是比较难处理的。
回声消除有两种方式:
第一种:通过硬件实现,
有很多手机就是这么做的,也有专业的芯片,但是只支持8khz的,
如果要求高质量的音质的话,基本实现不了。
第二种:通过软件实现,
qq,msn,skype很多具有通话功能的软件,现在都具有回声消除的功能(需是比较高版本的,低版本的可能没有),
但是实现代码是不对外的,开源的回声消除代码只有speex和webrtc。
一般常用的开源的AEC有两个:Speex 和 webrtc
webrtc相对比Speex强的多,原因如下:
1,webrtc有回声时延估计算法模块
2,webrtc有neteq模块
3,webrtc核心就是gips,原因你懂的