{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 chenzhufly 的文章《基于 DSP 的视频算法系统优化若干策略》','https://www.xiaopingtou.net/article-83200.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
数字视频产品需求近些年出现猛增。主流应用包括视频通信、视频监控与工业自动化,而最热门的要算娱乐应用,如 DVD、HDTV、卫星电视、标清(SD)或高清 (HD) 机顶盒、数码相机与 HD 摄像机、高端显示器(LCD、等离子显示器、DLP)以及个人摄像机等。这些应用都向高质量的视频编解码算法及其标准提出巨大需求,目前主流压缩标准主要有MPEG2、MPEG4和H.264/AVC,而针对这些编解码标准有各种各样的实现方案。本文主要探讨基于TI 的C64系列DSP的视频解码算法标准系统优化过程中需要考虑的若干因素。
TI的C64系列DSP以其强大的处理能力被广泛用于视频处理领域,然而由于大家对C64系列DSP的结构、指令、的理解程度不一样,造成算法实现时的效果有许多的差异。具体体现在实现算法时所使用的CPU的资源上。如实现H.264 MP@D1解码时所占用CPU的资源上,会有所差异,或者是所包含的算法工具子集上,如实现H.264 MP@D1解码时使用CAVLC而不使用CABAC。造成这些差异,主要原因有如下因素:
- 算法关键模块的优化
- 算法系统集成时Memory的管理
- 算法系统集成时的EDMA的资源分配管理
算法关键模块的优化
一般而言,对于目前主流视频解压缩标准都有类似的很消耗DSP CPU的模块,如H.264/AVC、MPEG4、AVS等编码中运动矢量搜索很占用资源,而且这些模块在整个系统实现过程中调用相当频繁,因此我们首先找出这些模块,这点TI的CCS提供了工程剖析工具(Profile),可以很快找到整个工程中占用DSP CPU资源最多的模块;然后对这些模块进行优化。对这些关键算法模块的优化我们分可以分三步进行,如图2所示,先认真分析这部分代码,并进行相应的调整,如尽量减少有判断跳转的代码,特别是for循环中,判断跳转会打断软件流水。使用的方法,可是使用查表或者使用_cmpgtu4、_cmpeq4等Intrinsics来代替比较判断指令,从而巧妙替代判断跳转语句。同时使用TI的CCS中所提供的#pragma提供编译器尽量多的信息,这些信息包括for循环的次数信息、数据对齐信息等。如果经过这部分优化无法满足系统要求,则对这部分模块使用线性汇编实现,线性汇编是介于C和汇编之间的一种语言实现形式,可以控制指令的使用,而不必特别关心寄存器、功能单元(S、D、M、L)的分配和使用,使用线性汇编一般会比使用C语言具有更高的执行效率。如果线性汇编还无法满足要求,则使用汇编实现,要编写出高并行、深软件流水的汇编需要经过画相关图,创建时序表(Scheduling table)等步骤,由于篇幅所限,这里就不熬述。
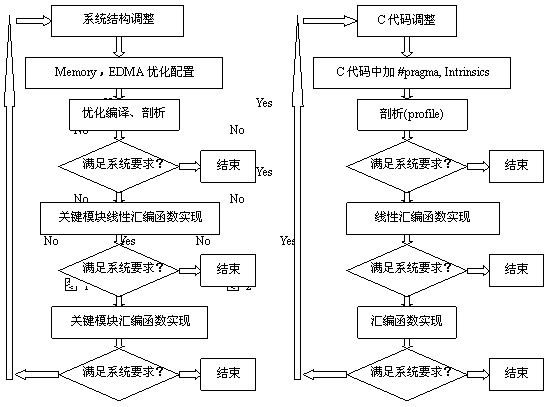
表1 使用方式 周期数 C+Intrinsics 83 线性汇编 74 汇编 57 优化选项:-pm, -o3,基于C64plus内核,C+Instrinsics 是指在C中使用Instrinsics。
表1是运动搜索中所需要的计算16×16宏块SAD值时,不同方式下所消耗的DSP CPU的周期数。由此可见,汇编实现所消耗的CPU的周期数最少,但前提是需要充分了解DSP CPU的结构、指令以及算法模块的结构,从而能够编写出高并行、深软件流水的汇编,否则有可能所写出的汇编还没有线性汇编或者C效率更高。为此一个行之有效的方法是,充分利用TI所提供的算法库中的函数,因为算法库中的函数都是已经充分优化过的算法模块,而且大都提供对对应的C、线性汇编和汇编源代码,并有文档进行API介绍。
算法系统集成时Memory的管理
由于在基于DSP的嵌入式系统开发中,存储资源特别是片内高速存储资源有限,在算法系统集成时Memory的管理对于提高整个系统的优化是非常重要的,这一方面影响数据的读取、搬移速度;另一方面还影响Cache的命中率,下面分程序和数据两方面分析。程序区:最大原则是将经常调度使用的算法模块放片内。为做到这点,TI的CCS中提供了#pragma CODE_SECTION,可以把需要单独控制存放的函数段从.text段中独立出来,从而在.cmd文件中对这些函数段进行单独物理地址映射。还可以使用程序动态的方式,将需要运行的代码段先调度进片内memory,如H.264/AVC中CAVLC和CABAC两个算法模块具有互斥性,因此可以将这两个算法模块放在片外而且对应于片内同一块运行区,在运行其中某一个算法模块之前,先将其调入片内,从而充分利用片内有限的高速存储区。程序区的管理考虑到一级程序Cache(L1 P)的命中率,最好将具有先后执行顺序的函数按地址先后顺序配置在程序空间中,同时对代码比较大的处理函数将其拆分成小函数。
数据区:在视频标准编解码中,由于数据块都很大,如一帧D1 4:2:0的图像有622k大小,而且在编解码中都需要开3~5帧甚至更多的缓冲帧,因此数据基本上无法在片内存放。为此在系统的Memory优化管理中,需要开C64系列DSP的二级Cache(对于TMS320DM642用于视频编解码中二级Cache开64k的情况比较多)。同时最好将放片外的被Cache所映射的视频缓冲区的数据以128 byte对齐,这是因为C64系列的DSP的二级Cache的每行大小为128 byte,以128 byte对齐有利于Cache的刷新和一致性维护。
算法系统集成时的EDMA的资源分配管理
由于在视频处理中,会经常有块数据的搬移,而且C64系列DSP提供了EDMA,逻辑上有64个通道,因此对EDMA的配置使用对优化系统是非常重要的。为此可以使用下述步骤进行充分配置系统的EDMA资源。 1. 统计系统中各种需要使用EDMA的情况及其大概需要占用的EDMA物理总线的时间,如表2所示: 输入视频流 输入音频流 输出码流 视频算法调度QDMA 音频算法调度QDMA TR请求 Video Port McBSP EDMA L2控制器 L2控制器 传输源端口 Video Port McBSP EMIF(SDRAM) L2/EMIF L2/EMIF 传输目的端口 EMIF(SDRAM) EMIF(SDRAM) PCI EMIF/L2 EMIF/L2 传输块大小/TR请求 720 byte 4 byte 32 byte 512 byte 16 byte 请求周期 22.72 uS/TR 34.72 uS/TR 122 uS/TR 最小为4.12 uS/TR 最小为
17.76 uS/TR 注意:该表针对视频通过视频端口(Video Port)(720*480,4:2:0,30Frame/s),音频通过McBSP(采样率为44k)进入DSP,压缩好的数据数率在2Mbps左右,数据通过PCI每488uS输出一个128byte的包(PCI口工作频率为33MHz),外挂SDRAM的时钟频率为133MHz,只做一个参考应用例子。 2. 统计好这些信息后,需要依据系统对各种码流实时性、及其传输数据块大小对各个被使用的EDMA通道进行优先级分配。一般而言,由于音频流传输块小,因此占用EDMA总线的时间短,而视频传输块比较大,占用EDMA总线的时间较长,因此将输入音频所对应的EDMA通道的优先级设定为Q0(urgent),视频的优先级设定为Q2(medium),输出码流所对应的EDMA通道的优先级设定为Q1(high),音视频算法处理中所调度的QDMA的优先级设定为Q3(low)。当然这些设定在真正系统应用中可能还需要调整的。 实际的基于TI DSP视频算法优化集成过程,会是基于图1所示的步骤,先初步配置Memory,并选择相应编译优化选项,如果编译的结果已经可以达到实时性要求之后就结束后面的优化;否则开始优化Memory和EDMA的配置,从而提高对Cache和内部总线的利用率;如果还无法达到要求则通过剖析整个工程确定消耗CPU资源最高的代码段或者函数,对这些关键模块进行优化,采用线性汇编、甚至汇编直到整个系统可以满足要求为止。 参考文献: TMS320C64x/C64x+ DSP CPU and Instruction Set Reference Guide (SPRU732)
TMS320C6000 EDMA IO Scheduling and Performance (SPRAA00)
TMS320C6000 Optimizing Compiler User's Guide (spru187)
TMS320C64x EDMA Architecture (SPRA994)
TMS320C6000 EDMA Controller Reference Guide (SPRU234)
TMS320C64x DSP Two-Level Internal Memory Reference Guide (SPRU610)
Cache Usage in High-Performance DSP Applications With the TMS320C64x (SPRA756)