{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 wu_chaochao 的文章《float与double的范围和精度》','https://www.xiaopingtou.net/article-83253.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
float与double的范围和精度
1 范围
float和double的范围是由指数的位数来决定的。
float的指数位有8位,而double的指数位有11位,分布如下:
float:
1bit(符号位)
8bits(指数位)
23bits(尾数位)
double:
1bit(符号位)
11bits(指数位)
52bits(尾数位)
在数学中,特别是在计算机相关的数字(浮点数)问题的表述中,有一个基本表达法[1]:
value of floating-point = significand x base ^ exponent , with sign F.1 译为中文表达即为: (浮点)数值 = 尾数×底数^指数,(附加正负号)-------- F.2 于是,float的指数范围为-127~128,而double的指数范围为-1023~1024,并且指数位是按补码的形式来划分的。其中负指数决定了浮点数所能表达的绝对值最小的数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。 float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。 2 精度 float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。 float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字; double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。 单精度类型(float)和双精度类型(double)存储 C 语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范 的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。 无论是单精度还是双精度在存储中都分为三个部分:

而双精度的存储方式为:

R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25* ,而120.5可以表示为:1.205* , 这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数 法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用 二进制的科学计数法表示1000.01可以表示为1.0001* ,1110110.1可以表示为1.1101101* ,任何一个数都的科学计数法表示都为1.xxx* , 尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点, 24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以 指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。 首先看下8.25,用二进制的科学计数法表示为:1.0001* 按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:

而单精度浮点数120.5的存储方式如下图所示:

那 么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存 数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:

根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101* =120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的


但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数 据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如 2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
注意:最后作者对2.25的表示以及2.2 的表示是有误的,如果前面你认真看了,就应该知道哪里有问题
value of floating-point = significand x base ^ exponent , with sign F.1 译为中文表达即为: (浮点)数值 = 尾数×底数^指数,(附加正负号)-------- F.2 于是,float的指数范围为-127~128,而double的指数范围为-1023~1024,并且指数位是按补码的形式来划分的。其中负指数决定了浮点数所能表达的绝对值最小的数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。 float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。 2 精度 float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。 float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字; double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。 单精度类型(float)和双精度类型(double)存储 C 语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范 的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。 无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
而双精度的存储方式为:
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25* ,而120.5可以表示为:1.205* , 这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数 法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用 二进制的科学计数法表示1000.01可以表示为1.0001* ,1110110.1可以表示为1.1101101* ,任何一个数都的科学计数法表示都为1.xxx* , 尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点, 24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以 指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。 首先看下8.25,用二进制的科学计数法表示为:1.0001* 按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:
{kind=link}
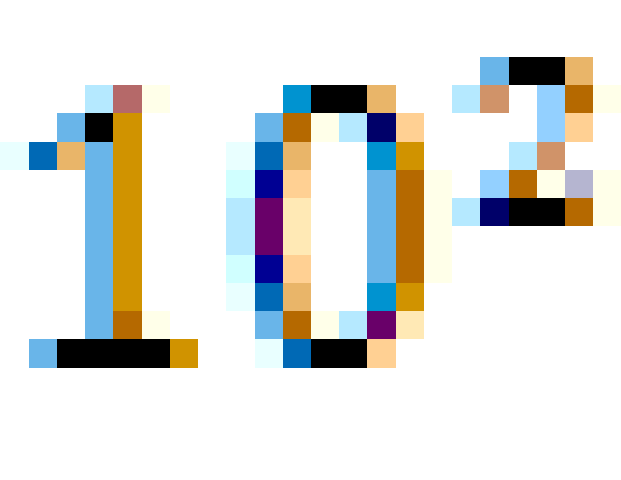{kind=link}
{kind=link}
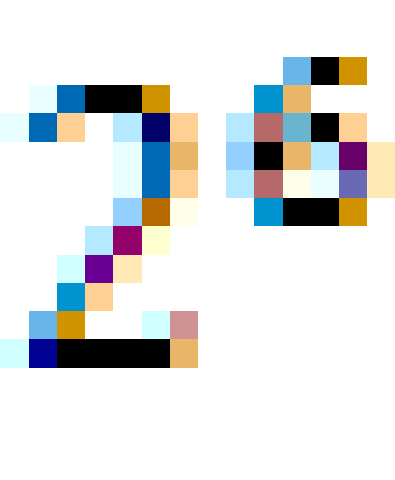{kind=link}
{kind=link}
而单精度浮点数120.5的存储方式如下图所示:
那 么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存 数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:
但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数 据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如 2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
注意:最后作者对2.25的表示以及2.2 的表示是有误的,如果前面你认真看了,就应该知道哪里有问题