{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 u011121393 的文章《《大话处理器》笔记摘抄及一点延伸》','https://www.xiaopingtou.net/article-83306.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
指令集(ISA) & 微架构
处理器执行计算任务时都需要遵从一定的规范,程序在被执行前都需要先翻译为处理器可以理解的语言。这种规范或语言就是指令集(ISA,Instruction Set Architecture)。程序被按照某种指令集的规范翻译为CPU可识别的底层代码的过程叫做编译(compile)。ISA常被简称为Architecture(架构),是处理器的一个抽象描述,它的出现是为了实现软件的兼容。将编程所需要了解的硬件信息,从硬件系统中抽象出来,这样软件开发人员就可以面向ISA进行编程,开发出的软件不经过修改,就可以应用在其它相同ISA的系统上。
Microarchitecture(微架构)是ISA在处理器中的设计实现, 描述处理器是怎么实现功能的,它通常可以认为等同于内核(core)。 如常见的代号如Haswell、Cortex-A15等都是微架构的称号。i7-4770的核心是Haswell微架构,这种微架构兼容x86指令集。
处理器公司很多,品牌也很多,而指令集相对稳定。用指令集对处理器公司分类是比较常见的做法。有5种指令集最为常见:
 图1 指令集与使用它们的处理器公司
图1 指令集与使用它们的处理器公司
我们国产的龙芯就是兼容MIPS指令集。 指令集本身的技术含量并不是很高,一般也都是公开的。然而微架构的设计细节是各家厂商绝对保密的,业界认为只有具备独立的微架构研发能力的企业才算具备了CPU研发能力,而是否使用自行研发的指令集无关紧要。微架构的研发也是IT产业技术含量最高的领域之一。
CISC Vs RISC
复杂指令集(CISC)和精简指令集(RISC)的区别用一个简单的例子来描述就是:同样是计算c = a + b,CISC一条指令就完成了整个计算的过程,而RISC是把加法计算拆解为从内存取a和b到寄存器、做加法、将结果返回c内存等多个细分步骤。假设我们还要实现d = e*f,则CISC需要从头设计一个指令来实现整个计算,对于RISC而言只需要增加一个乘法单元,对e和f的取数以及结果写回和前面用的是相同的功能单元。从这个例子中可以看出,CISC的好处是编译后的指令数少。但由于无法实现相同功能操作单元的复用,随着处理器功能的拓展,高功耗与指令样数多等问题随之而来。RISC由于将复杂功能分拆,使之更适合实现流水线的设计,主频可以更高。
在设计上,RISC似乎代表着先进指令集的发展方向。然而事实是,采用CISC的x86指令集一直在市场上占据难以动摇的地位,其性能也一直走在前面。其中一个很重要的原因是x86指令集在前期已经积累了众多的软件支持,为了软件的兼容,Intel只能一条道走到黑,凭借商业上的成功将CISC继续演绎出更加丰富、强大的性能。
现今设计的很多处理器,对属于CISC或是RISC处理器的区分显得越来越模糊。例如,英特尔开始大胆在基于CISC的x86中引入RISC的设计思想,增加了额外的一些“翻译层”。CPU外部依旧是x86,但是内部运行更为类似精简的RISC,于是CPU效能得到极大的提升。与此同时,ARM、TI等公司的高端RISC处理器的指令样数也都达几百条之多,一些更复杂的操作指令被加入进来。
流水线
MIPS指令集被业界看作是最为标准的RISC指令集。MIPS处理器在设计时,将处理器的执行过程划分为5个阶段:IF取指、ID译码、EX执行、MEM内存数据读或写、WB数据写回到通用寄存器中。
图2 MIPS 5级流水线
流水线在实际执行过程中会遇到一些因素导致流水线停顿(stall),这些因素就被称为流水线冒险。
1. 结构冒险 流水线中取指阶段和读写存储器阶段都需要访问存储器,早起处理器中,程序和数据存储器没有分开,IF和MEM操作同时访问存储器导致其中一个操作要等待。现在的处理器一般采用程序存储和数据存储分开的哈弗架构,因此不存在这个问题。
2. 数据冒险 由于从指令取指到数据更新至存储器/寄存器之间具有时钟延迟,当出现某些指令的组合时,可能会导致后面的指令使用了错误的数据。
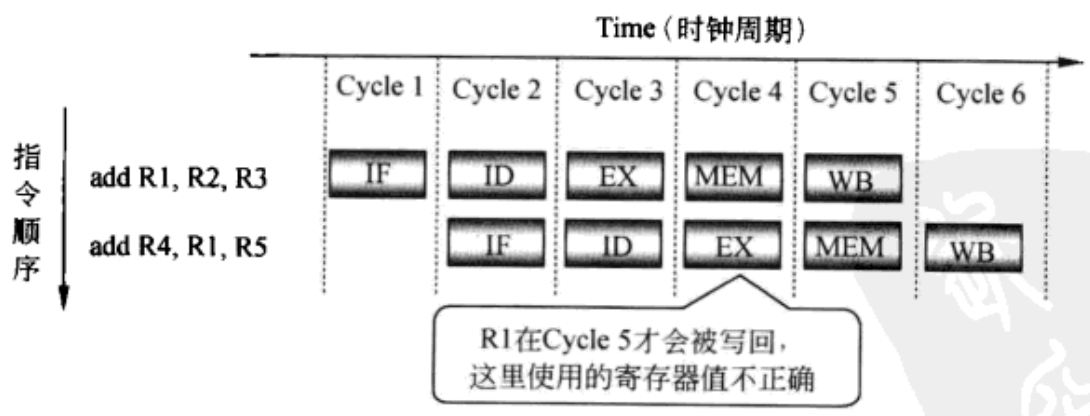
图3 寄存器访问的数据冒险
解决方法一是加入几个cycle的等待,但这影响了执行效率。
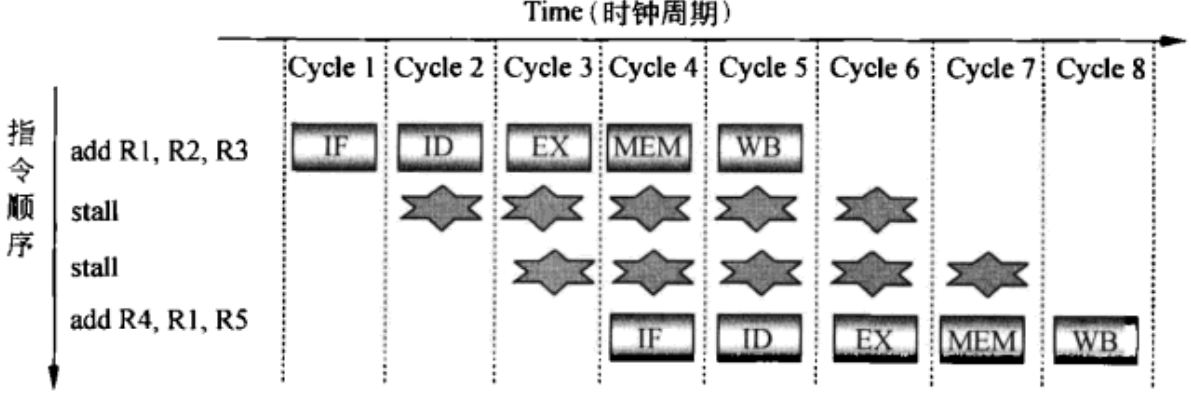
图4 通过增加等待来消除数据冒险
另一种更好的解决办法是使用直通(Forwarding)技术。当硬件检测到当前指令的源操作数正好在EX/MEM流水线寄存器中时,就直接将EX/MEM寄存器的值传递给ALU的输入,而不是从寄存器堆中读数据。
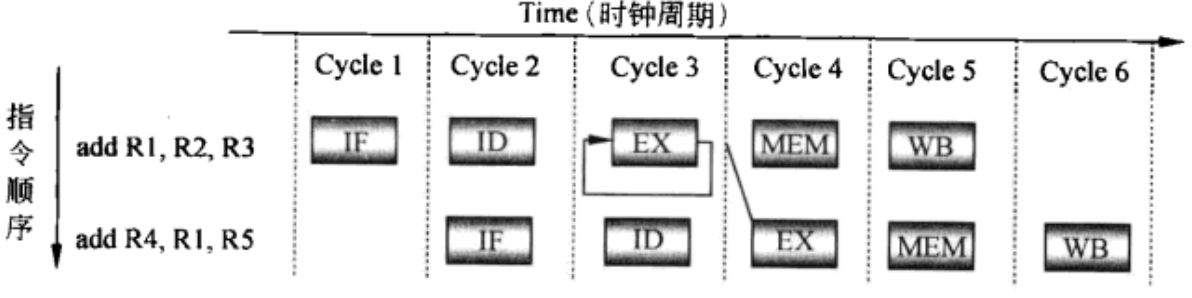
图5 使用Forwarding解决数据冒险
也不是每种数据冒险都能解决,同时又不引起stall。如下面的例子,即使将MEM/WB直通到EX的输入端,也需要延时一个cycle才能使用。
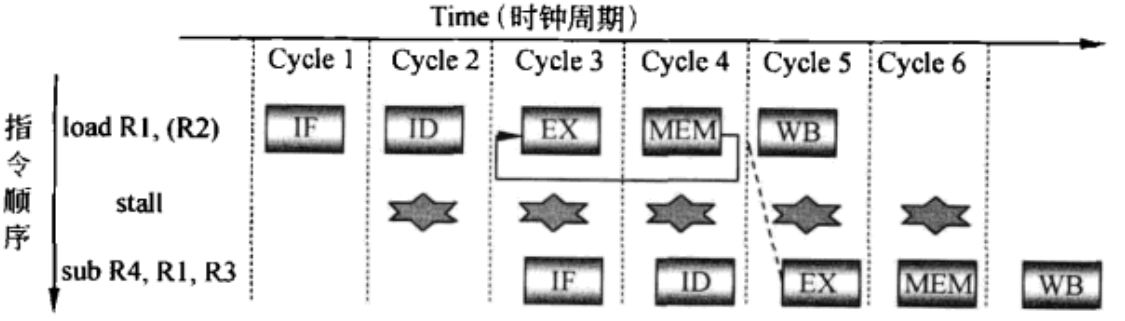
图6 仍然需要stall的直通示例
3. 控制冒险 由于使用流水线操作,在当前指令正在执行时,后面的很多条指令已经完成了取指和译码等步骤。然而,程序中有很多跳转语句,如果程序的实际执行路径是要跳转到其它的地址去执行,那么流水线中已经做的这些取指和译码工作就白做了,这就是流水线的控制冒险。
此时处理器需要排空流水线,跳转到新的地址处重新进入流水线。x86处理器使用硬件冲刷流水线来保证发生跳转时,流水线能正确执行。在TI的DSP中,硬件不处理这些冒险,而是通过软件的方式,在跳转语句后增加5个NOP操作来保证流水线正确,编译器也可以将指令乱序,用有效指令代替NOP指令。
分支预测 流水线的控制冒险将可能引起流水线排空,这对程序性能的损害是巨大的,流水线越深,损害越大。现代的很多处理器采用了分支预测技术来避免跳转带来的损失。
采用分支预测,处理器猜测进入哪个分支,并且基于预测的结果来取指、译码。如果猜测正确,就能节省时间,若果猜测错误,则刷新流水线,在新的地址上取指、译码。因此,分支预测需要有足够的准确性。
介绍两种简单的分支预测算法:
-
1位预测:如果该跳转指令上一次发生跳转,就预测这一次也会跳转,如果上一次没有跳转,就预测这一次也没有跳转。
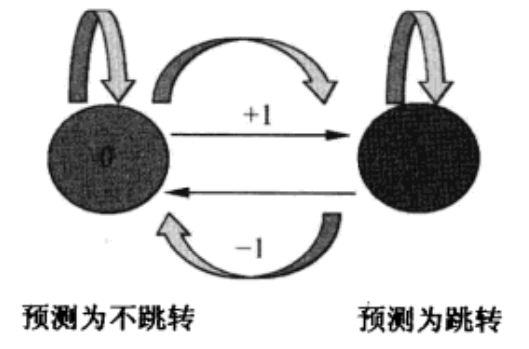
- 2位预测:用2bit计数器保存跳转信息,如果跳转执行就加1,跳转未执行就减1,。当计数器值为0和1时,就预测该分支不执行;当计数器值为2和3时,就预测这个分支执行。
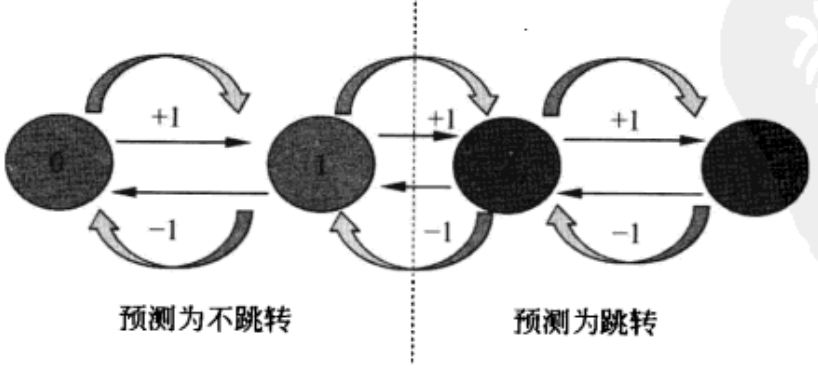
上面两种预测算法需要记录历史信息,有些时候,处理器还会使用静态预测器,通过固定的策略来预测分支是否执行。如对于循环来说,向上的跳转一般意味着循环将继续。静态预测器的通常策略是:向下跳转预测为不跳转,向上跳转预测为跳转。
条件执行
分支预测会消耗大量的资源,很多低功耗处理器没有分支预测,取而代之的是使用条件执行来减少跳转指令,如TI的DSP和ARM的cortex系列内核,等。条件执行使用额外的寄存器或编码来标注一条指令是否需要被执行。对于一些短小的if……else……语句,处理器将预先计算出条件分支的两种结果,然后再根据条件是否满足再从中选一个,这样就避免的跳转的发生。 如下示例:
if(flag) { a = b; } else { a = c; }
TI的DSP汇编表示为:
[B0] ADD .L2 B8, 0, B6 [!B0] ADD .L2 A8, 0, B6
第一条语句在B0非0时执行,第二条语句在B0为0时执行。
当然,条件执行只能用于非常受限制的一些情况,但这些情况还是相当常见的。对于复杂的条件判断,条件执行就无能为力了。
乱序执行(out -of-order execution)
指令在执行时常常因为一些限制而等待,后面的指令都要等待。如果处理器足够智能,就可以先执行后面不依赖该数据的指令,这就是处理器的乱序执行。乱序执行最大的障碍就是指令间的相关性。指令间相关大致有三种情况:寄存器相关,即前后指令使用了相同的寄存器;控制相关,跳转指令之后执行哪些指令需要依赖于跳转的结果;数据相关,即后面指令需要的数据依赖于前面指令的计算结果。
对于寄存器相关,处理器通过“寄存器重命名”技术解决这一问题。相同的ISA寄存器可以映射到不同的物理寄存器,经过映射后,新的指令就可以使用不同的物理寄存器,指令间的相关性也就消除了。
对于控制相关,处理器使用投机执行(通过分支预测)来决定哪些指令将会得到执行。
对于数据相关,这往往是由程序算法特性以及程序的设计共同决定的,它和处理器无关,和程序员以及编译器有关。在很多时候,编程人员可以通过调整代码设计将数据间的相关性降至最小。如下面这段代码:
x = a + b; y = x + c; z = y + d;
可以改写成:
x = a + b; y = c + d; z = x + y;
乱序执行比顺序执行要耗费更多的处理器资源,通常只有高端处理器才会使用。
处理器的并行设计
1. 指令并行 如果发射单元一次能发射多条指令,那么就有更多指令能并行处理了,因此指令并行也称为multi-issue(多发射)。multi-issue又分为两个阵营:superscalar(超标量)和VLIW(Very Long Instruction Word,甚长指令字)。
superscalar结构由处理器对指令进行调度、分配,实现指令的并行化处理。它的代价是处理器内部有不少资源用于将串行的指令序列转换成可以并行的指令序列,这大大增加了处理器的功耗和面积。
VLIW将指令的并行化显式地声明在指令格式中,可以将多条并行执行的指令看作是一条长指令,处理器只是傻乎乎地执行。指令的并行化可由编译器完成,也可由程序员手工写并行汇编代码实现。
早期汇编语言没有单独的字段描述当前指令是否和其它指令并行执行,处理器在发展时,为保证指令集的兼容性,都采用了superscalar结构,如x86、MIPS、ARM等。后来产生的新的指令集的处理器,大都采用了VLIW结构,如Tilera和Tensilica公司的处理器。
单从并行性来说,VLIW更胜一筹,因为它使用了更上层的信息,使之更擅长于数据的密集运算。不过如果发生cache miss、执行路径跳转时,VLIW就无能为力了。superscalar通常会配合乱序执行来提高并行性,能将后面的指令提前来执行,因此superscalar + 乱序更擅长于复杂的控制类应用程序。
2. 数据并行 SIMD(Single Instruction Multiple Data,单指令多数据)指令通过一条语句处理多个数据。在多媒体应用中,通常同一操作会重复处理多个数据,SIMD指令就特别适合处理这一类数据。
不同的处理器厂商给它们的SIMD指令集特有的命名,如Intel从1996年开始增加MMX(Multimedia extensions)指令集(单次处理64bit宽度数据),后来逐步增加SSE(Streaming SIMD Extensions)(单次处理128bit宽度数据) 、AVX(Advanced Vecter Extensions)指令集(单次处理256bit宽度数据)。又如ARM的SIMD扩展结构称为NEON,能单次处理128bit宽的数据。
3. 线程并行 线程并行的方式有类:单核内多线程、多核、多处理器。
单核内多线程通过硬件来实现多线程任务的处理。硬件多线程处理器的指令可以多个线程间轮流发射,也可以多个线程的指令同时发射。同时发射的工作方式就叫做同时多线程(SMT,Simultaneous Multi Threading)。Intel的SMT技术称为超线程(Hyper Thread)。
多核处理器的多个核之间会共用处理器的外设与接口,如内存控制器、PCI-E接口等,通常也会共享一段Cache。核与核之间有时需要交换信息,因此核间连接/通信方式的选取也很关键。下图为常见的几种多核组织结构:
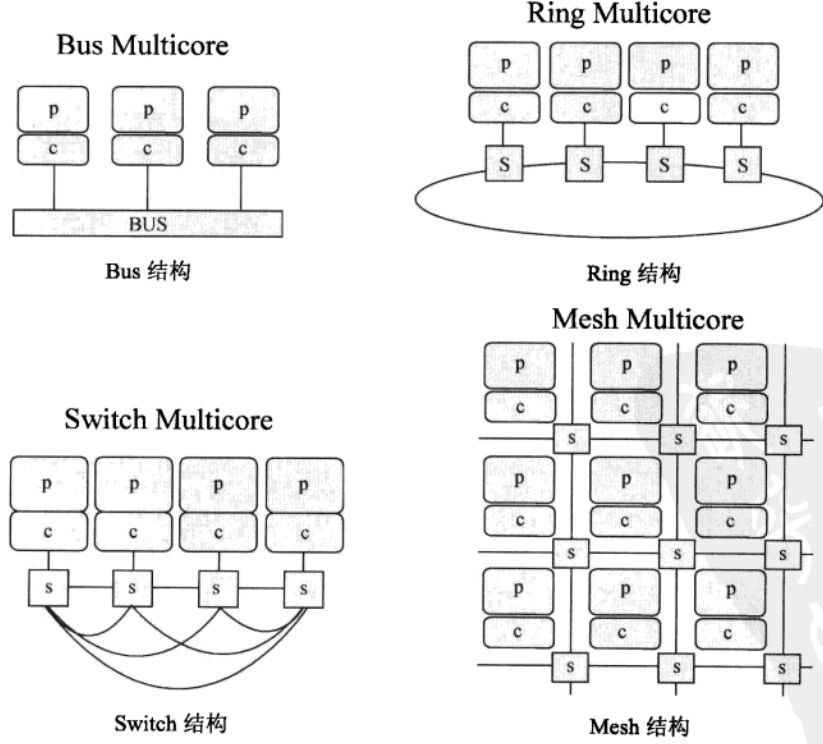
图7 多核组织结构
Bus结构比较简单,缺点是每两个内核通信都要占用总线,导致其它核不能通信,通信效率低。
Switch结构通信效率最高。但如果核太多,这种连接方式需耗费大量的互联资源,通常4个核左右的处理器采用这种方式。
Ring结构介于Bus和Switch结构之间。1和3通信需要经过2,越近的两个核通信效率越高,通信连线并不复杂,实现成本也低。通常8个核左右采用这种方式,Intel的很多处理器采用这种结构。
Mesh结构适用于核数非常多的情况,类似于二维的Ring结构。
因为核间通信会影响内核的运算效率,1个核可以做5件事情,并不代表4个核可以做20件事情,核越多时,数据交换延时越长。
如何评估一款处理器的运算性能?
现代处理器加入了分支预测、乱序执行、并行执行、条件执行等多种技术,我们已经无法简单从主频、功能单元、流水线级数等简单参数上去比较处理器间的运算性能差异。那么,到底该以什么样的标准来评估一款处理器的运算性能呢?目前,通用的做法是使用一个精心设计的基准(benchmark )代码,在相同优化级别的编译器参数下编译后,运行于处理器,然后以单位时间内的运行次数作为对应处理器的运行指标。
在决定采用一款处理器之前,需要考虑定点/浮点运算性能、功耗性能、外设性能等诸多方面,而这些方面一般也都能找到对应的benchmark以及对应参数。在定点运算性能上,最常用的两个benchmark为Dhrystone和Coremark。
Dhrystone benchmark诞生在上个世纪80年代,把这个benchmark在处理器上一跑,然后看看每秒能跑多少次这个程序,然后除以1757作为计算出DMIPS的值。之所以要除以1757是因为这个是拿VAX 11/780来做参考的,VAX 11/780每秒能执行1757次的Dhrystone benchmark。 例如,ARM官方给出的Cortex-A9 的Dhrystone参数为2.50 DMIPS/MHz,说明这个IP每秒能跑1757×2.50xFreq=4392.5xfreq 次的Dhrystone程序。
Coremark 是由EEMBC(嵌入式微处理器基准评测协会 )制定的专用于评估嵌入式处理器流水线性能的基准,而处理器的流水线性能就几乎代表了它的运算性能。相比于Dhrystone,Coremark有以下一些优点:
- Dhrystone的主要代码容易受编译器优化结果的影响,它更像是一个编译器基准而不是硬件基准,使用不同的编译选项给结果的比较带来困难。
- Dhrystone中包含对库函数的调用,这些库调用消耗了基准代码的大部分时间。但由于库代码不是基准的一部分,如果测试使用不同的库,则很难比较结果。
- Dhrystone代码并不模拟实际应用程序中的操作。
- 没有严格的标准要求Dhrystone代码应该如何运行,以及采用何种结果汇报形式。这使得对测试结果进行有意义的比较很困难,除非完全相同的Dhrystone执行代码用来在一个特定的CPU家族进行比较。
- Dhrystone的代码的版本没有官方来源,可能造成测试版本的不一致。
由于处理器厂家往往只对外公布对它有利的性能参数,因此有些处理器给出的是Dhrystone测试结果,而有些则是Coremark测试结果。不过客观上,Coremark的设计上比Dhrystone要更加科学合理。
参考文献
【1】 万木杨. 大话处理器[M].北京:清华大学出版社,2011. 【2】 BRYANT R E, O’HALLARON D R. Computer Systems: A Programmer’s Perspective[M]. 3 edition. Boston: Pearson, 2015.(译名:深入理解计算机系统). 【3】CoreMark FAQ. http://www.eembc.org/coremark/faq.php 【4】关于CPU、指令集、架构、芯片的一些科普--知乎专栏《没有问题的答案》.·END·
想进一步跟踪本博客动态,欢迎关注我的个人微信订阅号:信号君

郑重·专业·有料