{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 lemontree1945 的文章《MACE源码解析【ARM卷积篇(一) 】1*N和N*1卷积实现》','https://www.xiaopingtou.net/article-83540.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
MACE
Mobile AI Compute Engine (MACE) 是一个专为移动端异构计算平台优化的神经网络计算框架,旨在深度神经网络部署在移动端,是一个SoC上的神经网络实现。主要涉及的硬件资源主要包括CPU、GPU、DSP,对应的技术为ARM NEON、OPEN CL、HVX。项目地址:https://github.com/XiaoMi/mace
关于本系列
本篇主要解析MACE基于ARM NEON的卷积实现,是新手学习神经网络实现以及ARM NEON的绝好材料。基础
本篇需要的基础知识包括:- 卷积神经网络的基础知识
- c++编程
- ARM NEON优化基础知识
NEON初学者
NEON初学者指看过任何一篇介绍过NEON的博客,并初步理解向量化编程思想者。本篇中涉及到NEON intrinsic 函数都会在源码解析中进行简单介绍。
参考代码
本文分析的代码对应的提交号为f423091994bc66ab581f30474d72156242583198 ,若看此文时发现和源码有对不上的 地方,可用git check out 到该提交上。本篇源码都在MACE项目目录
mace/kernels/arm/ 中。本文涉及的代码文件有:
/mace/kernels/arm/conv_2d_neon_1x7.cc
/mace/kernels/arm/conv_2d_neon_7x1.cc
/mace/kernels/arm/conv_2d_neon_1x15.cc
/mace/kernels/arm/conv_2d_neon_15x1.cc
开篇 —— 1*7卷积实现
本文先较为详细的分析一下kernel中的1x7卷积,再推广到另外3个卷积实现中。作为ARM卷积篇的第一文,先介绍一下基本的内存结构。在MACE中,1*7卷积的接口为:// Ho = 1, Wo = 4, Co = 4
void Conv2dNeonK1x7S1(const float *input,
const float *filter,
const index_t *in_shape,
const index_t *out_shape,
float *output);
三个浮点指针input、output、filter分别指向了输入tensor、输出tensor和卷积核kernel。in_shape和out_shape则分别表示输入和输出tensor的维度。一般tensor为4维,每个维度分别表示为 batch size x channel num x image height x image width。举个例子,CNN网络中某一层特征图大小为256x192(宽x高),特征图数目为128,batch大小设置为64.则该tensor的大小可以表示为 64x128x192x256。 而在CNN中,考虑输出层的所有通道的话,卷积核是一个4维的tensor,每个维度分别是
output channel num x input channel num x kernel height x kernel width 。举个例子,CNN网络这里写代码片中C1层有128个特征图吗,C2层有256个特征图。C1到C2用3x3的卷积核做特征提取和映射时,卷积核tensor的大小可以表示为256x128x3x3。了解了这些基本内容后,就可以开始看源码了。
Tensor大小和整体结构
根据上面的介绍,MACE为了索引具体某个batch的某个通道图,先计算出了image size和batch size,如下所示: const index_t in_image_size = in_shape[2] * in_shape[3];
const index_t out_image_size = out_shape[2] * out_shape[3];
const index_t in_batch_size = in_shape[1] * in_image_size;
const index_t out_batch_size = out_shape[1] * out_image_size;
先说明一下循环层次,用伪代码表示:
for batch +1 (源码36行)
for out_channel +4 (源码37行)
for in_channel +1 (源码53行)
for out_height +1 (源码75行)
for out_width +4 (源码76行)
伪代码中最后的+表示循环索引的步长,因为每个输出通道是由所有的输入通道分别做卷积再求和得到的,再加上batch 数,所以是5层循环。
注意一下函数签名前面的注释,该注释表明输出的特征图宽度和通道数的步长都为4。宽度步长为4是因为使用了NEON指令,可以一次处理4个浮点数。输出通道步长为4应该是为了手动循环展开,让编译器可以方便更好的做OOO(Out of Order)。
// Ho = 1, Wo = 4, Co = 4
因此 if (m + 3 < out_channels) 这句是为了保证输出通道不被4整除时,可以有代码去处理不足4的部分。
取卷积核
现在来到第三层循环开始处(56行)这里卷积核还是需要再强调下:
const float *filter_ptr0 = filter + m * in_channels * 7 + c * 7; // 56 行
const float *filter_ptr1 = filter + (m + 1) * in_channels * 7 + c * 7;
const float *filter_ptr2 = filter + (m + 2) * in_channels * 7 + c * 7;
const float *filter_ptr3 = filter + (m + 3) * in_channels * 7 + c * 7;
这里7=kernel height*kernel width=1*7,而 in_channels * 7 则为任意输出通道所对应的卷积参数。因下面开始具体的计算了,在56行上。一次计算了4个filter_ptr,因为要一次输出4个out channel嘛,当然要对应的读4个卷积核(一个输出通道对应一个3维的卷积核)。
/* load filter (4 outch x 1 height x 4 width) */
float32x4_t vf00, vf01; // 62 行
float32x4_t vf10, vf11;
float32x4_t vf20, vf21;
float32x4_t vf30, vf31;
vf00 = vld1q_f32(filter_ptr0);
vf01 = vld1q_f32(filter_ptr0 + 3);
vf10 = vld1q_f32(filter_ptr1);
vf11 = vld1q_f32(filter_ptr1 + 3);
vf20 = vld1q_f32(filter_ptr2);
vf21 = vld1q_f32(filter_ptr2 + 3);
vf30 = vld1q_f32(filter_ptr3);
vf31 = vld1q_f32(filter_ptr3 + 3);
继续看下面,62行取出了卷积核的参数。因为这里做的是1*7卷积,所以每个输入通道都需要一个对应的1*7个卷积核参数做乘加和。NEON内联函数vld1q_f32一次取出4个float放到向量中。如下图所示,把7个标量权重存在了两个向量中。 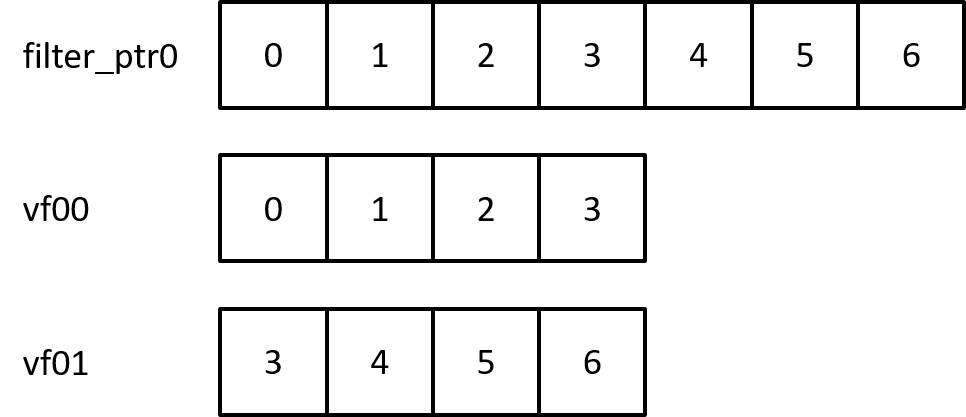 如图所示,把一个输入通道的卷积核存在两个两个1*4的向量中。
如图所示,把一个输入通道的卷积核存在两个两个1*4的向量中。
// load input
vi0 = vld1q_f32(in_ptr_base + in_offset); // 91 行
vi4 = vld1q_f32(in_ptr_base + in_offset + 4);
vi8 = vld1q_f32(in_ptr_base + in_offset + 8);
vi1 = vextq_f32(vi0, vi4, 1);
vi2 = vextq_f32(vi0, vi4, 2);
vi3 = vextq_f32(vi0, vi4, 3);
vi5 = vextq_f32(vi4, vi8, 1);
vi6 = vextq_f32(vi4, vi8, 2);
接着再到91行,看一下输入数据怎么排列在向量中的。依然使用vld1q_f32取出了12个float特征数据。略微不同的是使用了vextq_f32指令拼接出了额外的五个向量。内存排布如下: 
/* outch 0 */
vo0 = vmlaq_lane_f32(vo0, vi0, vget_low_f32(vf00), 0); // 134 行
vo0 = vmlaq_lane_f32(vo0, vi1, vget_low_f32(vf00), 1);
vo0 = vmlaq_lane_f32(vo0, vi2, vget_high_f32(vf00), 0);
vo0 = vmlaq_lane_f32(vo0, vi3, vget_high_f32(vf00), 1);
vo0 = vmlaq_lane_f32(vo0, vi4, vget_low_f32(vf01), 1);
vo0 = vmlaq_lane_f32(vo0, vi5, vget_high_f32(vf01), 0);
vo0 = vmlaq_lane_f32(vo0, vi6, vget_high_f32(vf01), 1);
准备工作都做好了,终于可以做最后的卷积运算了。看134行,vmlaq_lane_f32(a,b,c,i)函数为乘累加和指令。a+b*c[i],其中c[i]为标量,计算过程如图: 
输入向量和权重变量相乘后再累加上一个结果,得到卷积的结果。图中给出了向量vo0第一个通道的结果表达式。
vo1,vo2,vo3同理。这样1*7的卷积就做完了。NEON优化可以把4个浮点乘法放到一条指令中去做,加快了运行速度。这种滑动构造向量的操作也是NEON在图像处理中常用的套路。
vst1q_f32(out_ptr0_base + out_offset, vo0);// 168行
vst1q_f32(out_ptr1_base + out_offset, vo1);
vst1q_f32(out_ptr2_base + out_offset, vo2);
vst1q_f32(out_ptr3_base + out_offset, vo3);
最后再到168行,用vst1q_f32指令一次把4个结果写回输出内存中去。在下一次的in_channels循环中(53行)。 此块内存还会被取出,继续累加新的卷积结果。所以该操作也同时完成了输入层中多通道卷积后的累加过程。MACE并没有把加偏置项和激活放在此类卷积函数中。
7*1卷积的实现
在此基础上,在7*1的卷积实现中只有一些微小的变换。首先循环变为:
for batch +1
for out_channel +4
for in_channel +1
for out_height +4
for out_width +1
因为现在是NEON一次读四行的数据,所以高度的步长改为4。 相应的input_data的数据读取从
vld1q_f32变为:
float32x4_t vi0 = {in_ptr_base[in_offset],
in_ptr_base[in_offset + in_width],
in_ptr_base[in_offset + 2 * in_width],
in_ptr_base[in_offset + 3 * in_width]};
float32x4_t vi4 = {in_ptr_base[in_offset + 4 * in_width],
in_ptr_base[in_offset + 5 * in_width],
in_ptr_base[in_offset + 6 * in_width],
in_ptr_base[in_offset + 7 * in_width]};
float32x4_t vi8 = {in_ptr_base[in_offset + 8 * in_width],
in_ptr_base[in_offset + 9 * in_width]};
输出同理,不多赘述了。
补充和总结
- 需要对输入输出以及卷积核的内存排布非常清楚,并不难在纸上画画就清楚了
- 没有看到边界处理的地方,肯定在调用前补过边了。
- 1*15和15*1基本和1*7一致。但是不知道为什么MACE卷积1*15和15*1的代码对非4倍的高度和宽度没进行处理,那余4的部分结果就是初始值0了。另外也没做展开,所以代码量少了很多。不过核心的东西都是一样的。估计是觉得1*15这种核太小众且非4倍的可能性很小吧。tile_height这个变量也不懂其意义。所以如果在pytorch tensorflow上训练的1*15核在用MACE部署时发现输出结果不一致时,可以具体查一下源码。
关于优化的讨论
- .与caffe等模型不同,没有im2col变成矩阵乘法的操作。首先这种耗内存的工作不适合移动端,另外移动端也没有那么强大的GPU去做并行的矩阵计算。如一块GTX1080的功耗在300W以上,而手机才几W。
- 在最外层循环有此句
#pragma omp parallel for collapse(2),使用了简单的多线程计算——OpenMP。 - 初始化输出的代码MACE也是选择放在外部(应该是memset置0 了)。这个地方思考一下,如果化整为零把初始化0放到卷积函数里去做,而不是整块内存memset 0 。希望可以通过unroll和mutil thread把这个时间cover掉,似乎是可行的。具体点,如果放在out_channels那层循环中,还是需要同时4通道的置0(unroll了);如果初始化放到最内层循环,那就需要标志位,而且这里用到了opemMP,执行顺序是不保证的,也就是不保证先初始化再做累加。所以综合考虑,初始化放的太深虽然可能时间被cover掉,但是要考虑多线程并行。放的太浅没有效果,没其他代码可以跟它乱序。综合一下还是放在外面了。毕竟移动端跑一下推理网络,图也不会太大,batch也不会太大。用自己的小米测了一下,1000*1000的图大概0.2ms。400*500的不到1us,到纳秒级别了。
- ARM上的三大优化法门都用上了:多线程、NEON、循环展开(unroll)。不过多线程用的比较弱,毕竟openMP限制颇多。